
こんにちは。株式会社タイミーでバックエンドエンジニアをしているjinsuです。
Timee Advent Calendar 2025 の15日目の記事になります。
はじめに
本記事では、起動中のサービスで「50万件以上のファイルをS3に保存」と「100万件のレコードの更新」作業を安心・安全に行うために実践したことを共有します。当たり前の内容かもしれませんが、時間がないと見逃しがちだと思うので参考にしていただければと思います。
実行前にさまざまな確認を行いましたが、今回は大きく以下の4つの観点に絞って共有します。観点としてiso25010の中でも、特性 : 信頼性を特に重視しました。重視した副特性と実行方針は以下となります。
- 成熟性 : ユーザーシナリオに基づく異常系の想定とテスト計画
- 可用性 : サービスの停止を絶対にさせないパフォーマンス検証
- 障害許容性 : 実行時の影響範囲を限定させる設計
- 回復性 : 実行計画書作成と事前検死(プレモーテム)と対策の準備
成熟性 : ユーザーシナリオに基づく異常系の想定とテスト計画
保守運用上、必要なバッチ処理のせいでユーザー体験が悪くなることは避けたかったため、テスト設計で主に工夫していたことは「仕様通りにデータを更新するだけでなく、ユーザーに少しでも影響を与えないこと」です。
チームで運用していた仕様書からテストケースを抽出してくれるAI promptがあったため、仕様書をもとにテストケースの叩き台を作った後、チームでレビューを行い、足りないところは追加しました。ただ、AIは渡された情報から想定されるケースを抽出するのは得意だと思いますが、ユーザー体験やイレギュラーケースまでには一定程度は人が考えてフィードバックをしていく必要があると思ったため、追加で行っていたのは以下の2つです。
-
成功ケースだけでなく、失敗した場合のケースが意図通りの処理になるか、再度実行したときに冪等性が担保されているか確認する
-
仕様に関する内容だけでなくユーザーに影響がありそうなユースケースを洗い出し、エラーが発生しそうな箇所がないか確認する
更新処理を行っている途中にユーザーが同じデータを更新するとユーザー体験はどうなる? 処理が失敗した場合、データの整合性は担保される?など少しでも不安が残るケースを表にまとめた後、1つずつ確認を行いました。確認のおかげで安心して実行することができ、エラーなく終わらせることができました!
可用性 : サービスの停止を絶対にさせないパフォーマンス検証
私が所属していたチームでは大量のレコードを更新していた経験がなかったため、大量のレコードを更新するときにどのような影響があるか、どのくらいの量であれば影響なく更新できるかを検証する必要がありました。検証で主に工夫していたことは「要求を満たしつつ、本番のサービスの影響を最小限にする」ことです。
本番環境で安心して実行するために行ったことは2つです。
- 処理時間のシミュレーションと安心して実行できる根拠を持つ
- 確認していた指標をダッシュボードとしてまとめておき、本番環境でも同様に確認できるようにする
最初に行ったことは、1件あたりの非同期処理時間のシミュレーションです。
最初はシミュレーションできる件数を確認するために検証環境で10→100→1,000→10,000件のステップで実行し、処理時間・非同期処理遅延・DB書き込みQPS・S3への保存時間を計測しました。
件数を増やしながら確認を行いましたが、10,000件まで行かずとも1,000件のレコードでも非同期処理が遅延したりパフォーマンスが著しく悪化することがわかったため、1,000件で検証を進めていきました。
その後、ジョブがどのくらい時間がかかるのか確認しました。1秒で実行するジョブ数を設定できるように実装し、数を変えながら確認しました。最初に主に確認していたのはプロセス利用率(Utilization)と処理時間です。以下の表のように内容をまとめ、記録しながら確認を行いました。
(こちら検証環境の参考値としてみていただければと思います。)
| 時間 | 環境 | 1秒あたり実行する ジョブ数 |
プロセス 数 |
プロセス 利用率 |
処理時間 (秒) |
|---|---|---|---|---|---|
| 15:20~15:22 | 検証環境 | 30 | 20 | 88% | 6.73~25.0 |
| 15:47~15:49 | 検証環境 | 20 | 20 | 40% | 1~15 |
| 15:37~15:40 | 検証環境 | 15 | 20 | 15% | 1~13.3 |
| 16:51~16:54 | 検証環境 | 12 | 20 | 8% | 1~6 |
| 15:57~16:00 | 検証環境 | 10 | 20 | 5% | 1~6 |
| 16:06~16:11 | 検証環境 | 5 | 20 | 1~2% | 1~5 |
| 16:15~16:23 | 検証環境 | 3 | 20 | 1% | 1~5 |
ある程度処理速度のイメージが湧いてきたら、なるべく本番環境と同じスペックに設定し、再度実行を行いました。そのときに主に確認を行ったことは以下の2つです。
- DBのCPU/メモリ
- 他の非同期処理の遅延がないか
順番に各種指標と時間ごとのCPU利用率を確認し、スケジュール計画の案をいくつか出しました。その案の中で二日以内に終わり、かつサービスには影響をほぼ与えないと思う案を選び、進めました。また、確認を行った内容をダッシュボードや調査ログの検索画面にまとめておき、実際に本番で実行したときにすぐ確認できるような仕組みを作っておきました。
(実行計画書で記載していた一部のダッシュボード)
事前確認のおかげで非同期処理の遅延もなく、サービスに影響を与えずにデータ更新を行うことができました。
障害許容性 : 実行時の影響範囲を限定させる設計
バッチ処理を準備しながら意識していたのは「影響範囲を小さくすること」です。
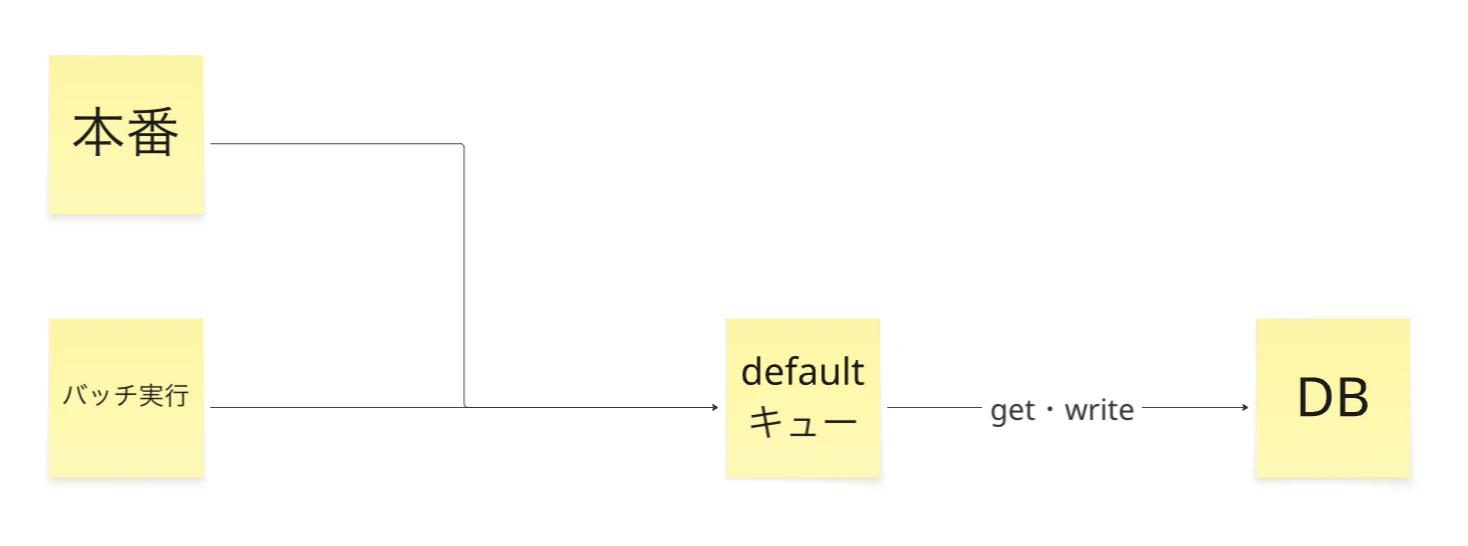
要件定義や実装の段階でもいろいろ工夫を行いましたが、今回の処理でやっておいて良かったと思うことは、非同期処理で使用するキューを分離したことです。
当初は本番環境で使用している default キューにジョブを投入していましたが、同じキューの場合、以下の2つの問題が起きる可能性がありました。
- 既存の非同期処理が遅延する可能性がある
- バッチ処理がサービスに何かしらの影響を与えた場合に中断までラグが発生する
(初期段階での処理の流れ)
問題を解消するために、adhocというキューを新しく追加しました。分けたことで、何かしらの問題が発生した場合でもプロセスを即時に止められる仕組みができ、運用リスクを低減できました。
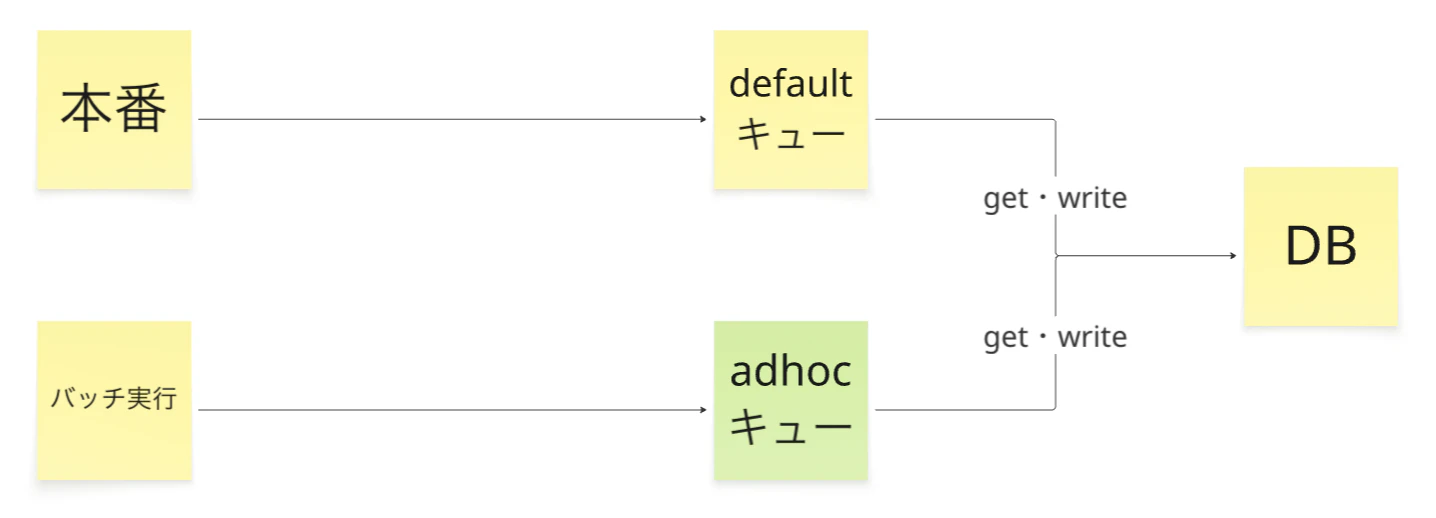
結果的に問題は発生しませんでしたが、何かあったときにすぐ止められるという心理的な安心感があったので、やっておいて損はなかったと思いました。
回復性 : 実行計画書作成と事前検死(プレモーテム)と対策の準備
最後に本番環境で実行する前に工夫していたことは「問題が発生したときに誰でも即時対応できるようにする」ことです。そのために行ったことは以下の2つです。
1. 実行計画書を作成
バッチ実行にあたっての実行計画書を作成しました。主に考慮していたのは以下の3つと実際に利用したものを本ブログ掲載用にした表です。
- 各時間帯にやることを誰が見てもわかるように明確に記載
- 何かあったときに迅速に対応を行うために連絡する人を複数人指定しておいたり、バッチ処理をすぐ止められるコマンドを記載
- 明確な締め切り制約があったため、予測通りに進行しているか確認するために時間帯ごとに更新されるべきデータ数を記載
| 時間 | アクション | 待機メンバー | 合計 (予測) |
合計 (結果) |
|---|---|---|---|---|
| 10:00 | 実行前に計画書 最終確認設計書リンク:xxx |
開発者A 開発者B DevPFの人C |
||
| 10:10 | バッチ処理を実行する ターミナルで実行するコマンド:xxx バッチ停止コマンド:xxx |
開発者A 開発者B DevPFの人C |
||
| 10:15 | 本番で正しく反映されているか確認する | 開発者A 開発者B DevPFの人C |
||
| 10:20 | 関連チャンネルに開始共有を行う 共有内容: これからバッチ実行を行います! |
開発者A 開発者B DevPFの人C |
||
| 10:30 | 負荷がないかDatadogを確認する Datadog: DatadogURL |
開発者A 開発者B DevPFの人C |
||
| 12:00 | 進捗を確認する 確認するクエリ:クエリリンク |
開発者A 開発者B |
50,000 | 48,000 |
| 14:00 | 進捗を確認する 確認するクエリ:クエリリンク |
開発者A 開発者B |
122,000 | 120,000 |
2. 何か問題が起きた場合の対応シナリオを考えておく
その後、実行中に発生する可能性があるあらゆるケースを洗い出しました。その後、各ケースごとにどういう対応を行うべきかを作成し、誰でも対応ができるようにドキュメントを作成しました。例えば、「パフォーマンスに問題がある場合」は管理画面でキューを一時停止する、「作成したファイルに問題がある場合」は事前に準備しておいたRollback用のスクリプトを実行するなどです。
ドキュメントを作成した後、主に対応を行う人が集まり計画書を読み合わせる時間を設け、抜けている観点がないかやもっと考慮すべき点について話し合いました。関係するステークホルダーには、非同期での共有ではなく、関係者が多く参加する場でレビューを行い、なるべく認識を揃えておくようにしました。
さまざまな確認や対策を行った結果、要求を満たすことはもちろん、安心・安全にバッチを実行することができました。以下は一切問題がなかった実行結果です!
- 処理件数:100万レコードの更新、50万件のファイルS3保存
- エラー:0件
- ユーザーからの問い合わせ:0件
- DB負荷:問題なし
まとめ
大量のレコードのバッチ処理を安心・安全に行うために行ったことを4つに絞って書いてみました。今回共有した項目以外でも確認する観点が多くあるかと思いますが、バッチ処理を安全に行うための参考資料としてみていただけると嬉しいです!
また、24時間動いているサービスで障害なく安全にリリースするためにいろいろ工夫している組織の中で働きたいと思う方、ご興味があればぜひお話ししましょう!