はじめに
やること
それぞれ異なるフィールドを持つ2種類のファイルをfilebeat×logstashで読み込みます。logstashやfilebeatの起動はdocker-composeを使用します。
また、それぞれのファイルごとにindexを指定し、kibanaで表示されるか確認します。
やらないこと
logstashを使って複数データの入力を受け付ける際によく使われる"multiple pipeline"は使用しません。
今回は2種類のファイルからのみの入力なので、multiple pipelineは使用せず、tagを利用してファイルを分類する方法で実行します。
環境
ツールバージョン
- logstash:8.5.2
- filebeat:8.5.2
- elasticsearch:8.5.2
- kibana:8.5.2
- docker:20.10.22
- docker-compose:1.29.2
ディレクトリ構成
.
├ docker-compose.yml
├ filebeat
│ ├ conf
│ ├ └ filebeat.yml
│ └ log
│ ├ データファイル1.csv
│ └ データファイル2.csv
├ logstash
│ └ pipeline
│ └ logstash.conf
└ elasticsearch
└ data
使用データ
異なるフィールドを持つ二種類のcsvファイルを用意します。
今回は、ログイン機能のあるウェブページを想定し、以下のようなフィールドを持つ超簡易的なログファイルを使用します。
- log_login.csv
- Date:ログイン日時
- userID:ユーザID
- state:ログイン状態
- log_viewpage.csv
- Date:メッセージ送信日時
- userID:ユーザID
- page:閲覧している画面
それぞれ、"state"と"page"という異なるフィールドを持っています。
手順
以下のような手順でファイルの作成を行います
1.filebeat.ymlを作成
2.logstash.confを作成
3.docker-compose.ymlを作成
4.kibanaで確認
データの流れは以下の通りです。
1.filebeat.ymlを作成
filebeatで収集するファイルに対して、それぞれでタグ付けし、logstashに送信します。
filebeat.inputs:
- type: log
enabled: true
tags: ["LOGIN"]
paths:
- /usr/share/filebeat/log/log_login*.csv
- type: log
enabled: true
tags: ["VIEWPAGE"]
paths:
- /usr/share/filebeat/log/log_viewpage*.csv
output.logstash:
hosts: ["logstash:5044"]
2.logstash.confを作成
filebeatでタグ付けされた各種類のファイルに対して処理を行い、elasticsearchに送信します
input {
# input from Filebeat
beats {
port => 5044
}
}
filter {
# ファイルごとに読み込むfieldを指定
if "LOGIN" in [tags]{
csv {
columns => ["Date","userID","state"]
skip_header => true # ヘッダーの行読み込みを飛ばす
}
}
if "VIEWPAGE" in [tags] {
csv {
columns => ["Date","userID","page"]
skip_header => true # ヘッダーの行読み込みを飛ばす
}
}
date {
match => ["Date", "yyyy-MM-dd HH:mm:ss:SS"] # Dateを@timestampに置換
timezone =>"Asia/Tokyo"
}
mutate{
remove_field => ["input", "@version", "host", "ecs", "agent","tags", "event", "log","source","highlight","Date"]
}
}
output {
# ファイルごとに異なるindexを指定
if "LOGIN" in [tags]{
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "samplelogin_index"
}
}
if "VIEWPAGE" in [tags]{
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "sampleviewpage_index"
}
}
}
3.docker-compose.ymlを作成
filebeat、logstash、elasticsearch、kibanaを構築します。
version: "3"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- ES_JAVA_OPTS=-Xms2g -Xmx2g
- xpack.security.enabled=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
- /var/run/docker.sock:/var/run/docker.sock
restart: always
logstash:
image: docker.elastic.co/logstash/logstash:8.5.2
container_name: logstash
ports:
- 5044:5044
environment:
- LS_JAVA_OPTS=-Xms1g -Xmx1g
volumes:
- ./logstash/pipeline:/usr/share/logstash/pipeline
restart: always
filebeat:
image: docker.elastic.co/beats/filebeat:8.5.2
container_name: filebeat
entrypoint: "filebeat -e -strict.perms=false"
volumes:
- ./filebeat/conf/filebeat.yml:/usr/share/filebeat/filebeat.yml
- ./filebeat/log:/usr/share/filebeat/log
- /var/run/docker.sock:/var/run/docker.sock
restart: always
kibana:
image: docker.elastic.co/kibana/kibana:8.5.2
container_name: kibana
environment:
- ELASTICSEARCH_HOST=https://elasticsearch:9200
- "I18N_LOCALE=ja-JP"
ports:
- 5601:5601
restart: always
4.kibanaで確認
設定 > スタック管理 > インデックス管理から、指定したインデックスで送信されているか見てみます。

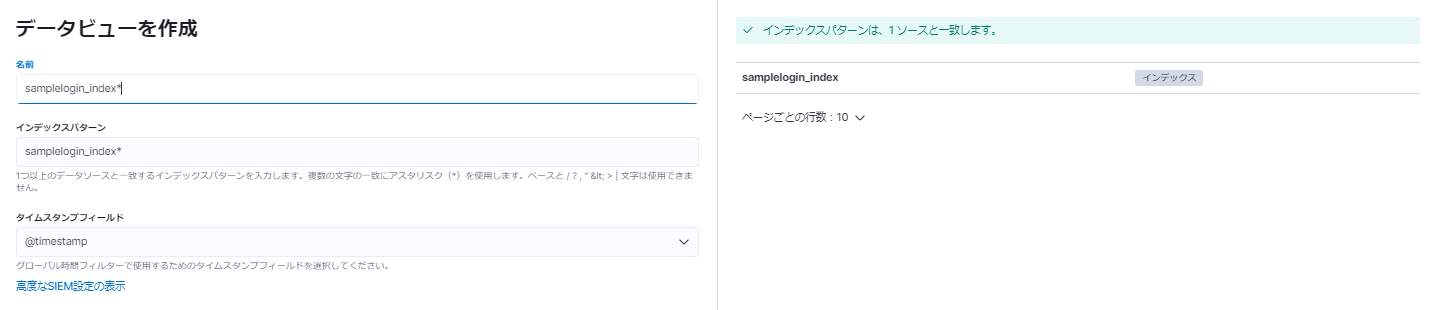
ちゃんとデータが送信されていそうなので、設定 > スタック管理 > データビュー > データビューを作成でindexパターンを指定して保存。
Discoverでログを確認。


どちらも意図通りにログが送れているようです。
おわりに
今回は比較的手軽に試せる方法で、複数のファイルからデータを読み込む方法を紹介しました。
今回は二種類のcsvファイルで試しましたが、csvファイルとjsonファイルなど、異なるファイル形式でも同様の形で入力できると思います。
また、今回はファイルの数が少なかったので良いのですが、より多くの種類のファイルやデータを取り込むとなるとmultiple pipelineを使用したほうが良いと思います。