課題
数年前と比較すると、GKEやECSを始めとするコンテナ実行環境でのアプリケーション運用を行うサービスはかなり増えてきた印象があります。
コンテナを運用する上では、アプリケーションのイベントを追跡する上でログをどう扱うかが課題になります。今までのように古いログを定期的にローテートして別のストレージに転送するといった手法はクラウドネイティブなアーキテクチャには最適とは言えません。
アプリケーション開発の方法論として、Twelve Factor App ではログをイベントストリームとして扱うためのガイドラインが示されていますが、近年のWebアプリケーションではシステムを疎結合に連携するマイクロサービスという考え方が主流になりつつあります。
アプリケーションログはサービスごとにフォーマットを整形した上で、ログ収集サービスに配送。必要に応じてリアルタイム分析や異常データの通知、そしてデータの可視化といった要件が求められます。
ここではメタップスにおいて過去数年に渡って本番環境のコンテナ運用やログ基盤を設計した知見を元に、ベストプラクティスとなるアーキテクチャの一例を紹介します。
従来までの設計
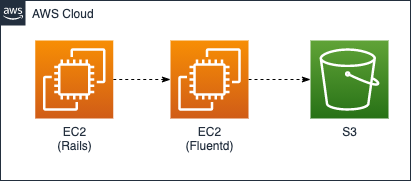
私がメタップスに入社した2015年当初は開発言語にRailsを利用することが多く、アプリケーションサーバにはUnicorn、データベースはMySQLやRedisという一般的な構成が採用されていました。
アプリケーションログはFluentdが収集し、異常データがあればSlackへ通知しつつ、全てのログをS3に保管する仕組みです。メタップスグループの各サービスはこのような仕組みが全般的に採用されていたと思います。
月日は流れ、ソフトウェア開発技法としてマイクロサービスという考え方が一般的になりました。開発環境はVagrantからDockerに移行し、GKEやECS、EKSといったコンテナ実行環境のクラウドサービスが誕生。Rails界隈ではWebpack (er) + APIモードという開発スタイルが生まれ、フロントエンドとバックエンドはサービスを分離する形がイケてる風になりました。
ここで問題となるのがアプリケーションのログ管理です。モノリシックなアプリケーション構成の場合はユーザーのリクエスト単位で関連ログをごっそり送れば良いですが、マイクロサービスでは複数のサービスが非同期に通信するため、S3のログを見るだけではユーザーごとの時系列データを追うことが難しくなります。
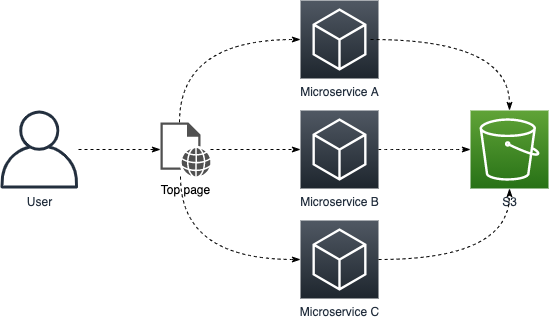
そこで、インフラの構成もマイクロサービスに適した形に再設計することにしました。
マイクロサービスに適した設計
メタップスではAmazon ECSリリース後、いち早く新規サービスへの導入を決めました。ECSに関する知見は ECS運用のノウハウ として公開していますので、興味があれば参考にしてください。
また、ログの配送設計については以前に ECSにおけるログの扱い方 を公開しましたが、運用初期はCloudWatch Logsを使い、記事の後半ではFluentdやElasticsearchを組み合わせたより高度なログ基盤に移行しています。
今でもログ配送に関する基本的な考え方は変わっておらず、アプリケーションを構成する各マイクロサービスがバックエンドのログサービスにデータを配送する仕組みを基本構成としています。
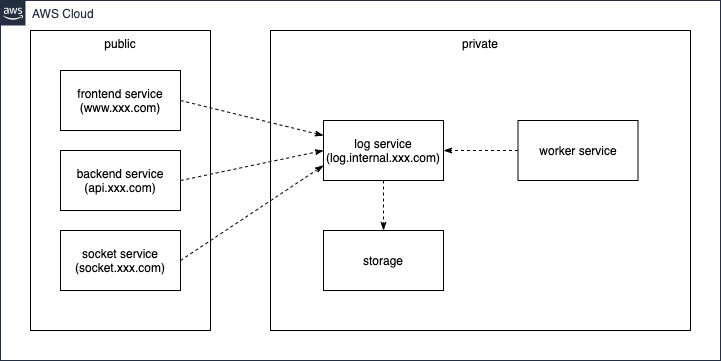
一般的なWebアプリケーションを構築する上で、システムから生成されるログは次の種別に分類することができます。
| ログの種別 | 説明 | 代表的なログの内容 |
|---|---|---|
| アプリケーションログ | アクセスログ・アプリケーションのフレームワークや開発者が意図的に埋め込むログ | ロガーログ (DEBUG、WARN、ERRORなど) |
| システムログ | クラスターや、クラスター基盤となるインフラのログ | Amazon ECSイベントログ・Amazon RDSエラーログ・Amazon VPCフローログ |
| 監査ログ | システムに対し、誰がどのような操作を行ったかを行ったかという証跡。一般的には1〜3年間の保持が求められる | アクセスログ・auditd・AWS Config・AWS CloudTrail |
今回はコンテナ運用に焦点を当てるので、アプリケーションログに関するログの配送パターンを紹介します 1。
ログドライバを用いたログの配送
Dockerには ログドライバ という機能が備わっており、コンテナから出力される標準出力・標準エラーをローカルストレージやAmazon CloudWatch Logs、Fluentdに配送する仕組みが提供されています。
dockerコマンドでログを出力してみる
初めに文字列を出力するプログラムを作成します。
puts 'hello'
次にRubyのイメージを取得してコマンドを実行します。dockerには --log-driver 2 というログの配送先を指定するオプションがありますので、ここでは json-file を指定します。
% docker run -v ${PWD}:/app --log-driver=json-file -w /app ruby:alpine ruby hello.rb
hello
コマンドが実行され、コンソールにも hello が出力されることを確認できました。尚、--log-driver が未指定の場合は json-file がデフォルト形式として扱われます。
続いてログファイルを確認します。docker ps -a を実行すると直前に実行したコンテナが残っているので、docker inspect を使ってログの出力先を確認してみましょう。
% docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
01b164f54437 ruby:alpine "ruby hello.rb" About a minute ago Exited (0) About a minute ago sweet_babbage
% docker inspect 01b164f54437 | grep LogPath
"LogPath": "/var/lib/docker/containers/01b164f54437e80b8e82767775e697876ea1fbe6b5d95e118defea1b8c6bf4a7/01b164f54437e80b8e82767775e697876ea1fbe6b5d95e118defea1b8c6bf4a7-json.log",
LogPath に記述されたパスがログの出力先です。Linux環境であればcatで開くことができますが、Mac (Docker for Mac) 環境では「No such file or directory」といったエラーが出ます。これはDocker for MacがVM (Hyperkit) 上で実行されているためで、VMに接続するには特権ユーザーでコンテナに接続する必要があります。
% docker run -it --rm --privileged --pid=host justincormack/nsenter1
/ # cat /var/lib/docker/containers/01b164f54437e80b8e82767775e697876ea1fbe6b5d95e118defea1b8c6bf4a7/01b164f54437e80b8e82
767775e697876ea1fbe6b5d95e118defea1b8c6bf4a7-json.log
{"log":"hello\n","stream":"stdout","time":"2020-12-25T00:27:10.82632Z"}
LogPath に書かれたパスをcatするとログが出力されていることが確認できました。
ここではdockerコマンド経由でログドライバを指定する方法を紹介しましたが、docker-composeからドライバを指定する場合、docker-compose.ymlに logging パラメータを指定する必要があります。
services:
web:
logging:
driver: json-file
GKE
GKEでは、標準でPodが出力するログをDaemonSetとして動作するFluentdが収集し、Stackdriver Loggingに配送する仕組みが採用されています。
Amazon ECS
タスク定義ファイルに logConfiguration 3 を指定することで、--log-driver、--log-opt と同等の動きをします。
ログコレクター
各コンテナからログを収集するサービスとして次のようなツールがあります 4。
| ツール名 | 特徴 | GitHub Watch | GitHub Star | 懸念 |
|---|---|---|---|---|
| Fluentd | * 利用実績が多く、開発も盛んに行わている * プラグインが豊富にあり、ログの出力先ストレージの幅が広い |
348 | 9.8k | ログのバッファー溢れなどによる欠損対策が必要 |
| Fluent Bit | C言語で書かれており高速に動作する | 90 | 2.4k | プラグインが少ない |
| Logstash | * Elastic社が開発 * ドキュメントが整備されている |
831 | 11.9k | JRubyで書かれている (メモリ使用率は高い) |
| Beats | * データの収集に特化 (機能がシンプル) * Golangで書かれており高速に動作する |
635 | 9.5k | * プラグインが少ない * 出力先のサポートが少ない |
| Flume NG | 冗長性が考慮されており、大規模ログ収集に強い | 221 | 2k | * プラグインが少ない * 設定が複雑 |
そのほか、最近ではSaaSとして Datadog Logs やStackdriver Logging といったサービスも提供されており、メタップスではFluentd、あるいはFluentd + Datadog Logsを基盤構成として構築するケースが殆どです。
ストレージの選定
続いてログの保管先を検討します。コンテナを実行するクラウド基盤にもよりますが、AmazonであればS3、GCPであればGoogle BigQueryを選定することが多いかと思います。
ここでは私が実際に利用したストレージごとの選定基準と検討事項をまとめてみました。
| ストレージ | 選定基準 | データの可視化 | ログの監視 (異常検知) | 検討事項 |
|---|---|---|---|---|
| Amazon S3 | * データの保管料が安い * 古いログをAmazon S3 Glacierに移すことで更に料金を抑えることが可能 |
BIツールとの連携 | ☓ | * データ分析にはAWS Glueを用いたスキーマ設計が必要 * データ分析にはAmazon Athenaを利用することで、SQLライクな検索が可能 (料金はスキャンしたデータ量による。コストを抑えるためにはデータのパーティショニング設計やテーブルの更新といった仕組みを作る必要がある) |
| Amazon Redshift | * 標準クエリをサポート * 時間課金 |
BIツールとの連携 | ☓ | 料金が高い |
| Amazon Elasticsearch Service | * Kibanaを用いた直感的な検索・データの可視化が可能 | Kibana | Alerting | * AWSにはフルマネージドのElasticsearch Serviceが提供されている * 可用性を高めるにはマスターノードとデータノードを分ける必要があり、運用コストが上がる (マスターノードがなくても運用はできるが、安定性に欠ける) |
| Amazon CloudWatch Logs | * データの保管料が安い * AWSを利用している場合、他のサービスとの親和性が高い (AWS LambdaやAmazon Elasticsearch Serviceへのログのストリーミングが容易) |
CloudWatch Logs Insights | CloudWatch Alerm | コンソールに難あり |
| Datadog Logs | * 他のDatadog製品との親和性が高い * ログの監視ルールをTerraformでコード管理できる |
Datadog Logs | Log monitor | ログの配送量や保管期間による課金体系 (利用体系によっては運用コストが高い) |
| Google BigQuery | * データロードのパフォーマンスが高い * 標準クエリをサポート * クエリ課金 |
BIツールとの連携 | ☓ | データの可視化にはGoogle Data StudioなどのBIツールと連携が必要 |
Amazon Elasticsearch Service (Kibana) やDatadog Logsはログの検索性・可視化という意味で他のサービスより抜きん出る性能を持ちますが、その反面維持コストが高くなる傾向があります。
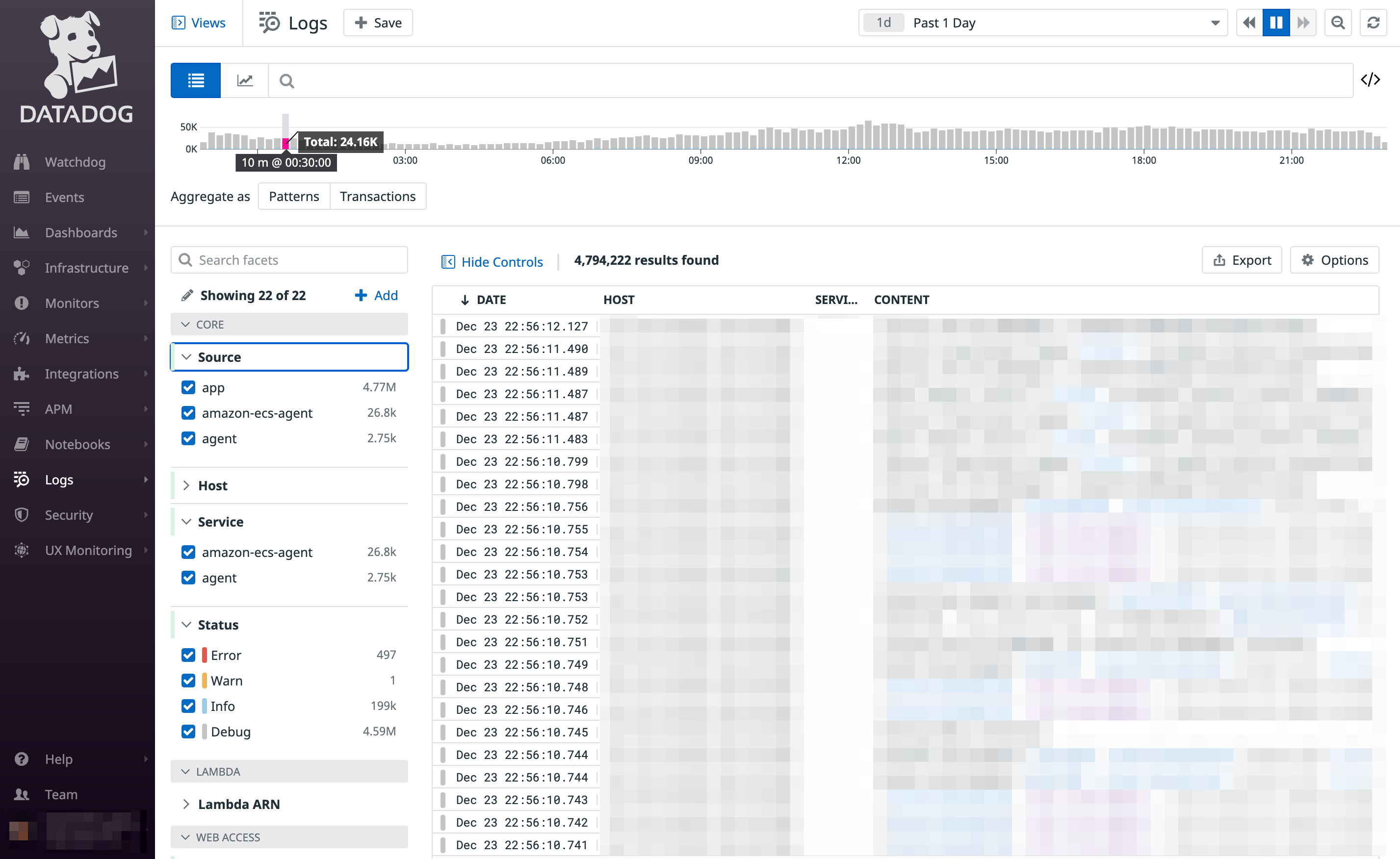
Fluentdはデータの出力先を複数定義できるので、可視化用途で短期間のみElasticsearchにログを格納し、永続的なログは別途永続ストレージ (Amazon S3など) に格納するといった2系統システムを構築するのも手の一つでしょう。
料金面の比較
ログのストレージとしてはAmazon Elasticsearch ServiceやDatadog Logsを選定することが多いので、それぞれの利用料金を比較してみました 5。
- 条件
- 1日辺り300万件のレコードを生成
- 1件辺りのレコードサイズは2KB
- 2KB * 30,000,000records * 30days = 180GB/month
- データ保管期間は1ヶ月とする
- サービス比較
- Amazon Elasticssearch Service
- 条件
- インスタンスタイプ:
m5.large.elasticsearch - 東京リージョン: $0.183/hour
- データノード: 2 (Multi-AZ)
- 専用マスターノード: なし
- インスタンスタイプ:
- 料金
- $0.183/hour * 730hours * 2nodes = $267.18/month
- 条件
- Datadog
- 料金
- Ingest (データサイズによる課金)
- データの保管またはスキャン1GB辺り$0.10
- 1ヶ月辺り120GBを保管 (スキャンを除いた金額)
- 180GB ☓ $0.10 = $18/month
- Retain or Rehydrate (データ保管期間による課金)
- 30日保管の場合
- 月間契約: $3.75/100per million
- 3,000,000records/day * 30days / 1,000,000records * $3.75 = $337.5/month
- 年間契約: $2.50/100per million
- 3,000,000records/day * 30days / 1,000,000records * $2.50 = $250/month
- 月間契約: $3.75/100per million
- 30日保管の場合
- Ingest (データサイズによる課金)
- 料金
- Amazon Elasticssearch Service
1ヶ月辺り9,000万レコード生成されるサービスの場合、料金面ではDatadog Log (Ingest) が有利でしたが、ログの保存期間やスキャン回数によってはElasticsearchのほうが有利となることもあるため、一概にどちらが良いとは言い切れません。サービスの特性や要件からどのサービスが選ぶべきか検討が必要となります。
ログの監視
個人的にデータの可視化という意味合いでElasticsearchは好きなのですが、ElasticsearchにはDatadog Logsで言うところのログモニター機能 (検索クエリを用いて特定の条件に一致するアラートを通知する仕組み) がありません。正確にはElastic社が提供するElasticsearchには組み込まれてるのですが、Amazon Elasticsearch Serviceには提供されていません。
と、思っていたらいつの間にかAWS版にもAlerting機能が追加されていました。どうやらOpen Distro for Elasticsearch 6 がリリースされたことで、バージョン6.5からサポートされたようです。試しにアラート機能を使ってみたところ、とても簡単にモニターを追加することができました。以下に手順を記します。
-
Kibanaを開き、左のサイドバーから
Alertingを開く

-
初めにアラートの通知先を登録するので、
Destinationsタブを開き、Add destinationを押す- Destination
- Name: 通知先の名前
- Type: 通知先のタイプ。
Amazon SNS、Amazon Chime、Slack、Custom webhookから指定
- Settings
- Typeに応じた通知先の設定を追加したら
Createを押す
- Typeに応じた通知先の設定を追加したら
- Destination
-
Monitorsタブを開き、Create monitorを押す- Configure monitor
- Monitor name: 監視ルール名
- Define monitor
- Method of definition: 条件式をどのように指定するか。初めはGUIからクエリを指定可能な
Define using visual graphを選択 - Index: 監視対象のインデックス名を指定。
access-log-*のようにパターン指定も可能 - Time field: インデックス上の日付フィールドを指定
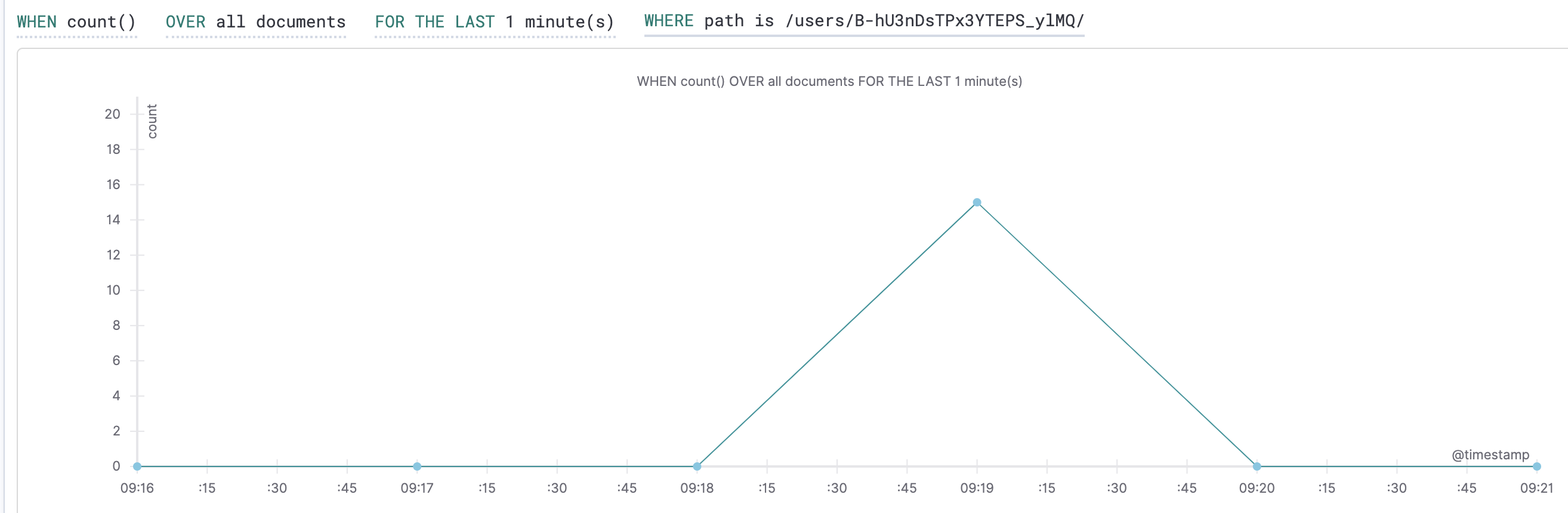
- Create a monitor for: アラート条件となるクエリを作成
- 次の指定は
/users/B-hU3nDsTPx3YTEPS_ylMQ/にアクセスのあった1分辺りのリクエスト数という意味になる
- 次の指定は
-
Createを押す
- Method of definition: 条件式をどのように指定するか。初めはGUIからクエリを指定可能な
- Configure monitor
-
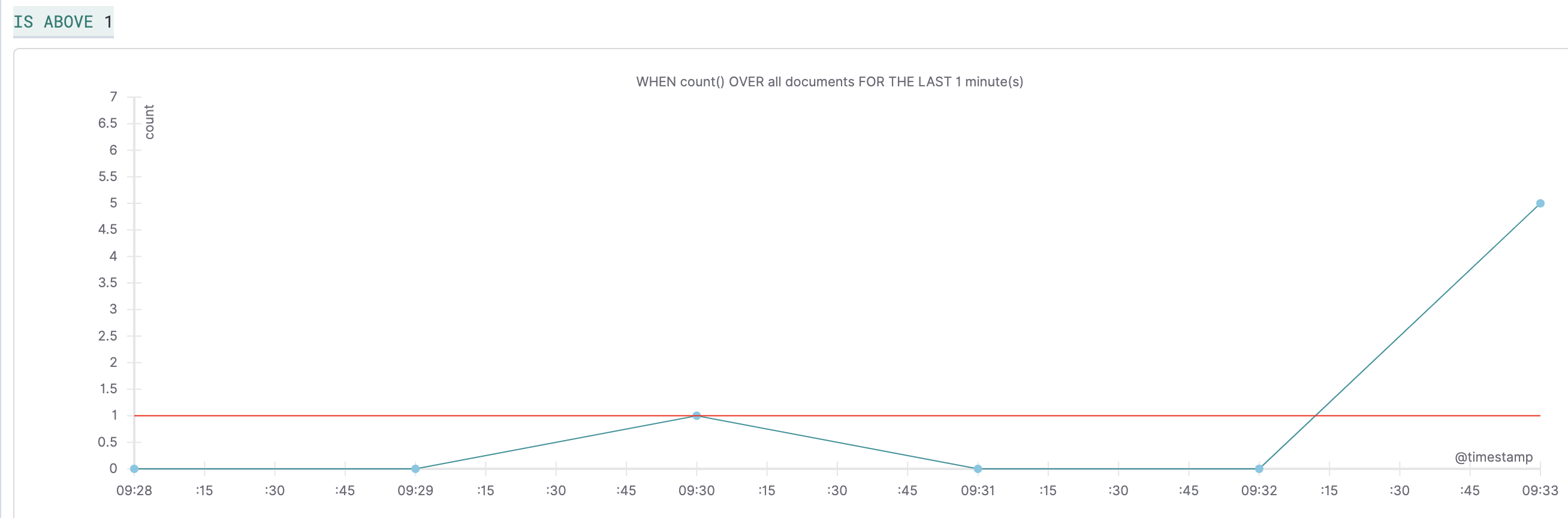
Create triggerが開く。ここではモニターで設定した監視条件を元にアラートを通知する条件を設定- Define trigger
- Trigger name: トリガー名
- Trigger condition: モニターで設定した条件の閾値を設定。以下の設定は「1回以上リクエストが発生した場合」という意味
- Configure actions
-
Add actionを押して、閾値を超えた場合のアクションを設定- Action name: アクション名
- Destination: 先ほど登録したアラートの通知先を指定
- Message subject: アラート名
-
Createを押下
-
- Define trigger
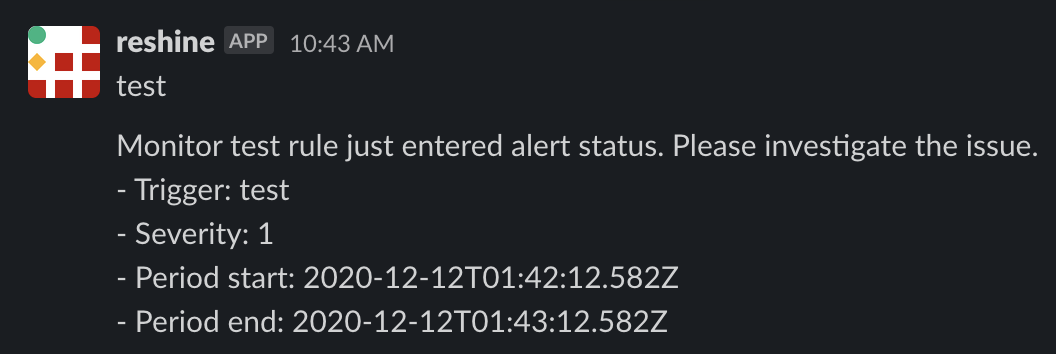
以上で設定は完了です。閾値を超えるリクエストを発生させるとこのような通知が飛ぶことが確認できました。
Open Distro for Elasticsearchは Alerting API を公開しているので、モニタールールをコードで管理することも簡単に出来そうです。