すでに 多くの記事 があるので、キャンペーン については割愛。
はじめに
Qiita なのに、
COTOHA API 使いやすい のに、
COTOHA × python の記事ばかり。
立ち上がれ!フロントエンドエンジニア!
ということで、 COTOHA × CSS の記事を書く。
COTOHA API を使って 文章をデコる サービス
「COTOHA DECO」 が作成可能か検証する。
※ 本記事は、 COTOHA × JavaScript で、データの取得から加工まで、
すべてJavaScriptで行っています。
Python 使えなくても COTOHA 使えるよ!!
まずは結果
このテキストのみを入力して、
(出典): https://www.nikkei.com/article/DGXMZO51758280S9A101C1000000/

↓
こうなる

仕様と設計
まずは、API 一覧 からデコる仕様を考える。
- 構文解析 を利用して、単語などの余白を微妙に調整する。
- 固有表現抽出 を利用して、人名・組織・地名・時間などに応じて、文字色やフォントを変える。
- キーワード抽出 を利用して、スコアに応じたドロップキャップする。
- 感情分析 を利用して、ポジティブまたはネガティブなフレーズに下線を引く。
- 要約(β) を利用して、要約文にマーカーをつける。
- 照応解析 を利用して、指示詞や代名詞に対応する先行詞をツールチップ(title)で表示する。
いけそうだ。
課題
タグで囲ってクラスつければいいかと安易に考えたが、
各APIのレスポンスを眺めていると、下記の通り各APIのレスポンスの要素が同じではないことに気付く。
- 構文解析 ⇒ 文節情報(chunk)と形態素情報(token)
- 固有表現抽出 ⇒ 固有表現情報
- 照応解析 ⇒ 文(tokensの要素)と照応解析結果と形態素情報(token)
- キーワード抽出 ⇒ 抽出キーワード
- 感情分析 ⇒ 感情フレーズ(emotional_phrase)
- 要約(β) ⇒ 要約?
なお、各レスポンスがの要素がどの位置(何番目か)についても、、
文字位置で持っていたり、形態素番号で持っていたり、持っていなかったり。。
ついでに、リクエストに渡す引数のキーも、 document と sentence の2つのIFがある。。
(なお、document はstring / array(string), sentence はstringのようだが、要約(β) は document なのにstring ?)
どういう関連があるのか、APIのリファレンスからは読み解きにくい。。
(形態素情報(token)が、文字の次の最小粒度ということは確実だが。。)
(たぶん、単体でのAPIのIFの使いやすさを重視して、組合せた使用を想定していないのかな。。)
...
自然言語処理はフロントエンドエンジニアには敷居が高いのか。。
方針
とにかくタグで囲ってクラスをつければ何とかなると思う。(適当)、
また、今回は、デコることは、人にわかりやすく可視化することを目的としているので、
複数APIの情報を正確にマージできなくても、分かりやすいモデルのほうがいいだろう。
と、いうことで、APIのサンプルや、他の記事や、実際にAPIを叩いて推測した結果から、
以下、 勝手な仮定 をたてて、構造化する。
- すべての 文章(docment) は 文(sentence) で区切れる。
照応解析 もしくは、 キーワード抽出
のリクエストパラメータのdo_segmentにtrueを指定すれば 文(sentence) が得られる。 - すべての 文(sentence) は 文節(chunk) で区切れる。
**構文解析**で 文節(chunk) が得られる。 - 形態素情報(token) が、「冠名詞、名詞、Number」の場合、それに続く「冠名詞, 名詞, 名詞接尾辞, Number, 助数詞, 助助数詞」をつなげて 単語(word) とする。
- 構文解析 で得られた、 形態素情報(token) の**依存先情報(dependency_labels)**のうち、後方に連続してつながっている「助動詞や、非自立の補助用言、コピュラ(auxおよびauxpassおよびcop)」を連結させて フレーズ(phrase) が得られる。
- フレーズ(phrase) は 単語(word) で区切れる。
- キーワード抽出 で得られる キーワード および 感情分析 で得られる 感情フレーズ(emotional_phrase) は フレーズ(phrase) である。
- 固有表現抽出 で得られる 固有表現 は フレーズ(phrase) もしくは フレーズ(phrase) を連結させたものである。
- 要約(β) で得られる要約は、 文(sentence) と一致するか、文に句点等を足したものである。
つまり、入力された文章を、以下の6階層(深さ固定)の木構造にする。
文字が入力されているのは葉となるtokenのみである。
.document(文章)
.sentence(文)
.chunk(文節)
.phrase(フレーズ)
.word(単語)
.token(形態素情報)
APIの結果と要素を比較し、一致する場合にクラスを付与する
実装
特定フォルダ下に、テキストを配置し、
node.jsで実行すると、HTML(with CSS)を生成するスクリプトを書いた。
※ COTOHA APIの認証情報が必要
私の環境では、COTOHA APIの実行結果が安定しなかった
(タイミングしだいで、エラーを返却することもあった)ので、
成功したレスポンスの内容はファイルとして書き出し、
ファイルが存在する場合はAPIを実行しないような工夫(配慮)をしている。
なお、API実行部分は、 @yohwhtさんの
メントスと囲碁の思い出」をCOTOHAさんに要約してもらった結果。COTOHA最速チュートリアル付き - Qiita の COTOHA最速チュートリアルサンプルコード(Python) を
Colaboratory にコピペして疎通してから、
JavaScript用に書き直すことで、スムーズに疎通できた。
マジ感謝ね
const request = require('request');
const fs = require('fs');
// flat Polyfill
if (!Array.prototype.flat) {
Array.prototype.flat = function(depth) {
var flattend = [];
(function flat(array, depth) {
for (let el of array) {
if (Array.isArray(el) && depth > 0) {
flat(el, depth - 1);
} else {
flattend.push(el);
}
}
})(this, Math.floor(depth) || 1);
return flattend;
};
}
const DEVELOPER_API_BASE_URL = "https://api.ce-cotoha.com/api/dev/";
const ACCESS_TOKEN_PUBLISH_URL = "https://api.ce-cotoha.com/v1/oauth/accesstokens";
const CLIENT_ID = "ココニアイデイカク";
const CLIENT_SECRET = "ココニシークレットカク";
const main = async () => {
let accessToken = await getAccessToken();
await cotohaMultiParse(accessToken, 'sumomo');
await cotohaMultiParse(accessToken, '外郎売');
await cotohaMultiParse(accessToken, 'kinoko');
}
const cotohaMultiParse = async (accessToken, folderName) => {
console.log(`■${folderName} のフォルダに対する処理を実施します。`);
let document = fs.readFileSync(`${folderName}/00_raw.txt`, 'utf-8');
// 前処理: tokenの区切りがparseとcoreferenceで変わらないように前処理。
document = document.replace(/\s*\n\s*/g, '\n');
fs.writeFileSync(`${folderName}/01_replace.txt`, document);
let parse = await getParse(accessToken, folderName, document);
let ne = await getNe(accessToken, folderName, document);
let coreference = await getCoreference(accessToken, folderName, document);
let summaries = await get3Summary(accessToken, folderName, document);
let keyword = await getKeyword(accessToken, folderName, document);
let sentiment = await getSentiment(accessToken, folderName, document);
let parseChunkIndex = 0;
let parseTokenIndex = 0;
let parseIndex = 0;
let coreferenceSentenceIndex = 0;
let coreferenceTokenIndex = 0;
let phrases = [];
let chunk = { phrases: phrases, classes: [] };
let sentence = { chunks: [ chunk ], classes: [] };
let documentTree = {
sentences: [ sentence ],
chunks: [ chunk ],
phrases: [],
words: [],
tokens: [],
};
let parseEndFlg = false;
let coreferenceEndFlg = false;
let tokenAlert = false;
while (true) { //phrases単位でループする。
let parseChunk = parse[parseChunkIndex];
let parseToken = parseChunk.tokens[parseTokenIndex];
let parseNextFlg = (parseToken == null);
let coreferenceSentence = coreference.tokens[coreferenceSentenceIndex];
let coreferenceToken = coreferenceSentence[coreferenceTokenIndex];
let coreferenceNextFlg = (coreferenceToken == null);
if (coreferenceNextFlg) {
coreferenceSentenceIndex++;
coreferenceTokenIndex = 0;
coreferenceSentence = coreference.tokens[coreferenceSentenceIndex];
if (coreferenceSentence == null) {
coreferenceEndFlg = true;
} else {
coreferenceToken = coreferenceSentence[coreferenceTokenIndex];
if (coreferenceToken == null) {
coreferenceEndFlg = true;
} else {
if (!parseNextFlg) console.log(`警告: 照応解析のsentences(${coreferenceSentence.join(',')})の区切り位置を、構文解析のchunks(${parseChunk.tokens.map(v => v.form).join(',')})の区切り位置が超えています。`);
phrases = [];
chunk = { phrases: phrases, classes: [] };
sentence = { chunks: [ chunk ], classes: [] };
documentTree.sentences.push(sentence);
}
}
}
if (parseNextFlg) {
parseChunkIndex++;
parseTokenIndex = 0;
parseChunk = parse[parseChunkIndex];
if (parseChunk == null) {
parseEndFlg = true;
} else {
parseToken = parseChunk.tokens[parseTokenIndex];
if (parseToken == null) {
parseEndFlg = true;
} else {
if (!coreferenceNextFlg) {
phrases = [];
chunk = { phrases: phrases, classes: [] };
sentence.chunks.push(chunk);
documentTree.chunks.push(chunk);
}
}
}
}
if (coreferenceEndFlg || parseEndFlg) {
if (!(coreferenceEndFlg && parseEndFlg)) console.log(`警告: 構文解析と照応解析の終了が同じではないです。coreferenceEndFlg: ${coreferenceEndFlg}, parseEndFlg: ${parseEndFlg}`);
break;
}
if (parseToken.form !== coreferenceToken && !tokenAlert) {
console.log(`警告: 構文解析のtoken(${parseToken.form})と照応解析のtoken(${coreferenceToken})が異なっています。`);
tokenAlert = true;
}
let token = { id: parseToken.id, form: parseToken.form, classes: [] };
documentTree.tokens.push(token);
let word = { tokens: [ token ], classes: [] };
if (['冠名詞', '名詞', 'Number'].includes(parseToken.pos)) {
while(true) {
let tmpParseToken = parseChunk.tokens[parseTokenIndex + 1];
if (tmpParseToken && ['冠名詞', '名詞', '名詞接尾辞', 'Number', '助数詞', '助助数詞'].includes(tmpParseToken.pos)) {
parseTokenIndex++;
coreferenceTokenIndex++;
parseToken = parseChunk.tokens[parseTokenIndex];
coreferenceToken = coreferenceSentence[coreferenceTokenIndex];
if (parseToken.form !== coreferenceToken && !tokenAlert) {
console.log(`警告: 構文解析のtoken(${parseToken.form})と照応解析のtoken(${coreferenceToken})が異なっています。`);
tokenAlert = true;
}
token = { id: parseToken.id, form: parseToken.form, classes: [] };
documentTree.tokens.push(token);
word.tokens.push(token);
} else {
break;
}
}
}
documentTree.words.push(word);
let phrase = { words: [ word ], classes: [] };
let parseBaseToken = parseToken;
let dependencyLabels = parseToken.dependency_labels;
if (dependencyLabels) {
let i = 1;
for(let dependencyLabel of dependencyLabels) {
if (dependencyLabel.token_id !== parseBaseToken.id + i) {
continue;
}
if (parseChunk.tokens[parseTokenIndex + 1] == null || coreferenceSentence[coreferenceTokenIndex + 1] == null){
break;
}
if (!['aux', 'auxpass', 'cop'].includes(dependencyLabel.label)) {
break;
}
parseTokenIndex++;
coreferenceTokenIndex++;
parseToken = parseChunk.tokens[parseTokenIndex];
coreferenceToken = coreferenceSentence[coreferenceTokenIndex];
if (parseToken.form !== coreferenceToken && !tokenAlert) {
console.log(`警告: 構文解析のtoken(${parseToken.form})と照応解析のtoken(${coreferenceToken})が異なっています。`);
tokenAlert = true;
}
token = { id: parseToken.id, form: parseToken.form, classes: [] };
word = { tokens: [ token ], classes: [] };
documentTree.words.push(word);
documentTree.tokens.push(token);
phrase.words.push(word);
i++;
}
}
chunk.phrases.push(phrase);
documentTree.phrases.push(phrase);
parseTokenIndex++;
coreferenceTokenIndex++;
}
documentTree.sentences.forEach( sentence => {
sentence.chunks.forEach( chunk => {
chunk.phrases.forEach( phrase => {
phrase.words.forEach( word => {
word.form = word.tokens.map( token => token.form ).join('');
word.token_id_from = word.tokens[0].id;
word.token_id_to = word.tokens.slice(-1)[0].id;
});
phrase.form = phrase.words.map( word => word.form ).join('');
phrase.token_id_from = phrase.words[0].token_id_from;
phrase.token_id_to = phrase.words.slice(-1)[0].token_id_to;
});
chunk.form = chunk.phrases.map( phrase => phrase.form ).join('');
chunk.token_id_from = chunk.phrases[0].token_id_from;
chunk.token_id_to = chunk.phrases.slice(-1)[0].token_id_to;
});
sentence.form = sentence.chunks.map( phrase => phrase.form ).join('');
sentence.token_id_from = sentence.chunks[0].token_id_from;
sentence.token_id_to = sentence.chunks.slice(-1)[0].token_id_to;
});
let allSentences = documentTree.sentences;
let allChunks = allSentences.map( s => s.chunks ).flat();
let allPhrases = allChunks.map( c => c.phrases ).flat();
let allWords = allPhrases.map( c => c.words ).flat();
let allTokens = allWords.map( p => p.tokens ).flat();
const getEqFormElem = str => {
let ret = [];
documentTree.sentences.forEach( sentence => {
if (sentence.form === str) {
ret.push(sentence);
} else {
sentence.chunks.forEach( chunk => {
if (chunk.form === str) {
ret.push(chunk);
} else {
chunk.phrases.forEach( phrase => {
if (phrase.form === str) {
ret.push(phrase);
} else {
phrase.words.forEach( word => {
if (word.form === str) {
ret.push(word);
} else {
word.tokens.forEach( token => {
if (token.form === str) {
ret.push(word);
}
});
}
});
}
});
}
});
}
});
return ret;
};
sentiment.emotional_phrase.forEach(ePhrase => {
let targets = getEqFormElem(ePhrase.form);
if (targets.length === 0) {
console.log(`警告: emotional_phrase(${ePhrase.form})が存在しません。`);
}
targets.forEach( t => {
if (!t.classes.includes(`emotion`)) t.classes.push(`emotion`);
if (!t.classes.includes(`emotion-${ePhrase.emotion}`)) t.classes.push(`emotion-${ePhrase.emotion}`);
});
});
keyword.forEach((k, i) => {
let targets = getEqFormElem(k.form);
if (targets.length === 0) {
console.log(`警告: keyword(${k.form})が存在しません。`);
}
targets.forEach( t => {
if (!t.classes.includes(`keyword`)) t.classes.push(`keyword`);
if (!t.classes.includes(`keyword-${i + 1}`)) t.classes.push(`keyword-${i + 1}`);
});
});
// begin_pos, end_posを持ってはいるが、文言一致を試す
// ne⇒得点王、word⇒大会得点王等が一致しないが、wordとしては長いほうが適しているため
// ロンゲスト一致のようなもので無理やり表示する方がいいかもしれない。
ne.forEach((n) => {
let targets = getEqFormElem(n.form);
if (targets.length === 0) {
console.log(`警告: ne(${n.form})が存在しません。`);
}
targets.forEach( t => {
if (!t.classes.includes('ne')) t.classes.push('ne');
if (!t.classes.includes(`ne-${n.class}`)) t.classes.push(`ne-${n.class}`);
});
});
// sentenceには前後に空白等が含まれてしまっているため、前後空白を除去して、sentenceのみ比較する
summaries.filter( summary => summary.form.length > 0).forEach( summary => {
let targets = [];
let replaceSummary = summary.form.replace(/。$/, '');
documentTree.sentences.forEach(sentence => {
let tmpSentence = sentence.form.replace(/^\s+/, '').replace(/\s+$/, '');
// upperCaeしないと、サマリー側の小文字が大文字になっている場合がある。
if (summary.form.toUpperCase() === tmpSentence.toUpperCase() || replaceSummary.toUpperCase() === tmpSentence.toUpperCase()) {
targets.push(sentence);
}
})
if (targets.length === 0) {
console.log(`警告: summary(${summary.form})が存在しません。`);
}
targets.forEach( t => {
if (!t.classes.includes(`summary-${summary.sent_len}`)) t.classes.push(`summary-${summary.sent_len}`);
});
});
fs.writeFileSync(`${folderName}/90_documentTree_row.json`, JSON.stringify(documentTree, null, ' '));
fs.writeFileSync(`${folderName}/91_documentTree_sentences.json`, allSentences.map(s => s.form).join('\n'));
fs.writeFileSync(`${folderName}/92_documentTree_chunks.json`, allChunks.map(c => c.form).join('\n'));
fs.writeFileSync(`${folderName}/93_documentTree_phrases.json`, allPhrases.map(p => p.form).join('\n'));
fs.writeFileSync(`${folderName}/94_documentTree_words.json`, allWords.map(w => w.form).join('\n'));
fs.writeFileSync(`${folderName}/95_documentTree_tokens.json`, allTokens.map(t => t.form).join('\n'));
const getClassTag = (baseClass, element) => {
return `class="${baseClass} ${element.classes.join(' ')}"`
}
// hmlt作成処理
fs.writeFileSync(`${folderName}/${folderName}.html`, `
<html>
<head>
<meta charset="UTF-8">
<title>${folderName}</title>
<style>
span.sentence {
margin-right: 1em;
}
span.chunk {
margin-right: 0.12em
}
span.phrase {
margin-right: 0.08em
}
span.word {
margin-right: 0.04em
}
</style>
<style>
span.summary-1 {
background:linear-gradient(transparent 20%, rgb(215, 46, 60, 0.3) 70%, transparent 100%);
}
span.summary-2 {
background:linear-gradient(transparent 20%, rgb(230, 73, 18, 0.3) 70%, transparent 100%);
}
span.summary-3 {
background:linear-gradient(transparent 20%, rgb(220, 137, 20, 0.3) 70%, transparent 100%);
}
</style>
<style>
span.ne {
color: rgb(64,64,64);
font-weight: bold;
}
span.ne-ORG, span.ne-PSN { /* 組織名,人名 */
color: rgb(128,64,0);
font-weight: bold;
}
span.ne-LOC { /* 場所 */
color: rgb(0,0,160);
font-weight: bold;
}
span.ne-DAT, span.ne-TIM { /* 日付,時刻 */
color: rgb(128,64,64);
font-weight: bold;
}
span.ne-MNY { /* 金額 */
color: rgb(128,128,64);
font-weight: bold;
}
</style>
<style>
span.phrase,span.word,span.token {
display: inline-block;
}
span.keyword{
line-height: 1;
font-size: 0.9em;
}
span.keyword-1 span.token:first-child::first-letter,span.keyword-1.token::first-letter{
font-size: 1.6em;
}
span.keyword-2 span.token:first-child::first-letter,span.keyword-2.token::first-letter{
font-size: 1.6em;
}
span.keyword-3 span.token:first-child::first-letter,span.keyword-3.token::first-letter{
font-size: 1.6em;
}
span.keyword-4 span.token:first-child::first-letter,span.keyword-4.token::first-letter{
font-size: 1.6em;
}
span.keyword-5 span.token:first-child::first-letter,span.keyword-5.token::first-letter{
font-size: 1.4em;
}
span.keyword-6 span.token:first-child::first-letter,span.keyword-6.token::first-letter{
font-size: 1.4em;
}
span.keyword-7 span.token:first-child::first-letter,span.keyword-7.token::first-letter{
font-size: 1.4em;
}
span.keyword-8 span.token:first-child::first-letter,span.keyword-8.token::first-letter{
font-size: 1.4em;
}
</style>
<style>
span.emotion {
}
span.emotion-P {
border-bottom: dashed 2px red;
}
span.emotion-PN {
border-bottom: dashed 2px gray;
}
span.emotion-N {
border-bottom: dashed 2px blue;
}
</style>
</head>
<body>
${documentTree.sentences.map( s => '<span ' + getClassTag('sentence', s) + '>' +
s.chunks.map( c => '<span ' + getClassTag('chunk', c) + '>' +
c.phrases.map( p => '<span ' + getClassTag('phrase', p) + '>' +
p.words.map( w => '<span ' + getClassTag('word', w) + '>' +
w.tokens.map( t => '<span ' + getClassTag('token', t) + '>' +
t.form +
'</span>').join('') +
'</span>').join('') +
'</span>').join('') +
'</span>').join('') +
'</br></span>').join('')}
</body>
</html>
`);
return documentTree;
}
const getAccessToken = () => {
return new Promise((resolve, reject) => {
request(
{
url: ACCESS_TOKEN_PUBLISH_URL,
method: 'POST',
headers: { 'Content-Type': 'application/json' },
json: {
grantType: "client_credentials",
clientId: CLIENT_ID,
clientSecret: CLIENT_SECRET,
},
},
(error, response, body) => {
if (!error && (response.statusCode === 200 || response.statusCode === 201)) {
if (typeof body !== 'object') body = JSON.parse(body);
resolve(body.access_token);
} else {
if (error) {
console.log(`request fail. error: ${error}`);
} else {
console.log(`request fail. response.statusCode: ${response.statusCode}, ${body}`);
}
reject(body);
}
},
);
});
}
const getCommonRequest = (url ,fileName, getRequestJsonFunc) => (accessToken, folderName, document) => {
let promise;
promise = new Promise((resolve, reject) => {
let filePath = `${folderName}/${fileName}`;
if (fs.existsSync(filePath)) {
resolve(JSON.parse(fs.readFileSync(filePath, 'utf-8')));
} else {
request(
{
url: `${DEVELOPER_API_BASE_URL}${url}`,
method: 'POST',
headers: { 'Content-Type': 'application/json;charset=UTF-8', Authorization: `Bearer ${accessToken}`},
json: getRequestJsonFunc(document),
},
(error, response, body) => {
if (!error && (response.statusCode === 200 || response.statusCode === 201)) {
if (typeof body !== 'object') body = JSON.parse(body);
if (body.status === 0) {
fs.writeFileSync(`${filePath}`, JSON.stringify(body.result, null, ' '));
resolve(body.result);
} else {
console.log(`request coreference fail. error: ${body.message}`);
reject(body);
}
} else {
if (error) {
console.log(`request ${url} fail. error: ${error}`);
} else {
msg = (typeof body !== 'object') ? body : JSON.stringify(body);
console.log(`request ${url} fail. response.statusCode: ${response.statusCode}, ${msg}`);
}
reject(body);
}
}
);
}
});
return promise;
}
const getParse = (accessToken, folderName, document) => {
return getCommonRequest('nlp/v1/parse', '10_parse_row.json', document => {
return { sentence: document };
})(accessToken, folderName, document);
}
const getNe = (accessToken, folderName, document) => {
return getCommonRequest('nlp/v1/ne', '20_ne_row.json', document => {
return { sentence: document };
})(accessToken, folderName, document);
}
const getCoreference = (accessToken, folderName, document) => {
return getCommonRequest('nlp/v1/coreference', '30_coreference_row.json', document => {
return {
document: document,
do_segment: true,
};
})(accessToken, folderName, document);
}
const getKeyword = (accessToken, folderName, document) => {
return getCommonRequest('nlp/v1/keyword', '50_keyword_row.json', document => {
return {
document: document,
max_keyword_num: 8,
};
})(accessToken, folderName, document);
}
const getSentiment = (accessToken, folderName, document) => {
return getCommonRequest('nlp/v1/sentiment', '60_sentiment_row.json', document => {
return { sentence: document };
})(accessToken, folderName, document);
}
const get3Summary = async (accessToken, folderName, document) => {
let summary1 = await getSummary(accessToken, folderName, document, 1);
let summary2 = await getSummary(accessToken, folderName, document, 2);
let summary3 = await getSummary(accessToken, folderName, document, 3);
let summary2Part = summary2.replace(summary1, '');
let summary2Array = summary2Part.split('。').filter(v => v.length > 0).map(v => v + '。');
let summary3Part = summary3.replace(summary1, '');
summary2Array.forEach(s => {
summary3Part = summary3Part.replace(s, '');
});
let summary3Array = summary3Part.split('。').filter(v => v.length > 0).map(v => v + '。');
// summary1と、summary2とsummary3は。で区切られた、1文、2文、3文にはなっているが、
// summary2にsummary1が含まれないこともある。
return [ [ { form: summary1, sent_len: 1 } ] , summary2Array.map(s => { return { form: s, sent_len: 2}; } ), summary3Array.map(s => { return { form: s, sent_len: 3}; } )].flat();
}
const getSummary = (accessToken, folderName, document, i) => {
return getCommonRequest('nlp/beta/summary', `40_summary_${i}_row.json`, document => {
return {
document: document,
sent_len: i,
};
})(accessToken, folderName, document);
}
main();
結果
すもももももももものうち
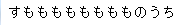
↓

外郎売

↓

「たけのこの里」を「きのこの山」に『正しく』自動で修正して差し上げるプログラム
(出典): 「たけのこの里」を「きのこの山」に『正しく』自動で修正して差し上げるプログラム - Qiita
※ COTOHA APIの複数のAPIを使うため、文字数や文数で適当なサンプルを見つけるのに苦戦する中、丁寧な説明と、ネガ/ポジも含んだ文章として利用させていただきました。 マジ感謝ね

↓

感想
記事では触れていないが、前処理での正規化に対応するなど、
結果を見ながらトライ&エラー繰り返した。
結果、自然言語処理 素人が、
無理やり複数の結果をマージしたため、
1割程度は、作成した木構造とAPIの結果が一致せずに、
結果を捨てている
また、本来はCodePen等で入力結果をパースし、
照応解析を利用して先行詞をツールチップ(title)で表示するなど、
動的な対応も入れたかったが、疲れた諦めた。
CSSのスタイルも、もう少し工夫すれば格段と見栄えはよくなると思う。
よくフロントエンドエンジニアと名乗れたレベル
この記事がお蔵入りしなかったのは、
- COTOHA APIが簡単に触れた
- CSS や JavaScript タグでCOTOHA APIの記事がなかった
-
複数API の組合せて利用している記事が少なかった。
一方で、自然言語処理の難しさを垣間見た - キャンペーン をやっているから
であり、このような キャンペーン を実施している運営様にも マジ感謝ね
本物の フロントエンドエンジニア による COTOHA APIの記事が書かれることを望む。