プロローグ
※この章は読み飛ばしても構いません
多くの人が挑むも解くことが叶わなかった人類史上の難問といわれるものがいくつかある.
数学界で最も有名な難問といえばおそらく「フェルマーの最終定理」であろう.弁護士であり数学者であったフェルマーが「解答を書くにはこの余白は狭すぎる」と書き残してこの世を去って以来,天才ワイルズが現代数学の成果を結集して証明を完成させるまで300年以上も数学者たちの挑戦を退け続けた.その他にも,京都大学の望月教授が宇宙際タイヒミュラー理論を用いて証明したといわれるABC予想や,7つのうち6つが現在も未解決であるミレニアム懸賞問題などはあまりにも有名である.

一方数学以外でも,例えば宇宙の始まりを巡る議論は多くの人を惹きつけてきた難問であり,アインシュタインやホーキングら天才たちの研究によって徐々にその姿が明らかになってきた.「我々はどこから来たのか,我々は何者か,我々はどこへ行くのか」というゴーギャンの絵が示す問いは,人類にとって答えのない永遠の疑問だ.我々の起源や生きる意味に関する問いは物理学以外にも,考古学,生物学,哲学などから様々なアプローチが可能な,まさに普遍的な命題と言える.

そして,「史上最大の難問とは何か」と問われた時に,我々が真っ先に思い浮かべるであろう,人類史に燦然と輝く挑戦がある.そう,サイゼリヤの間違い探しである.
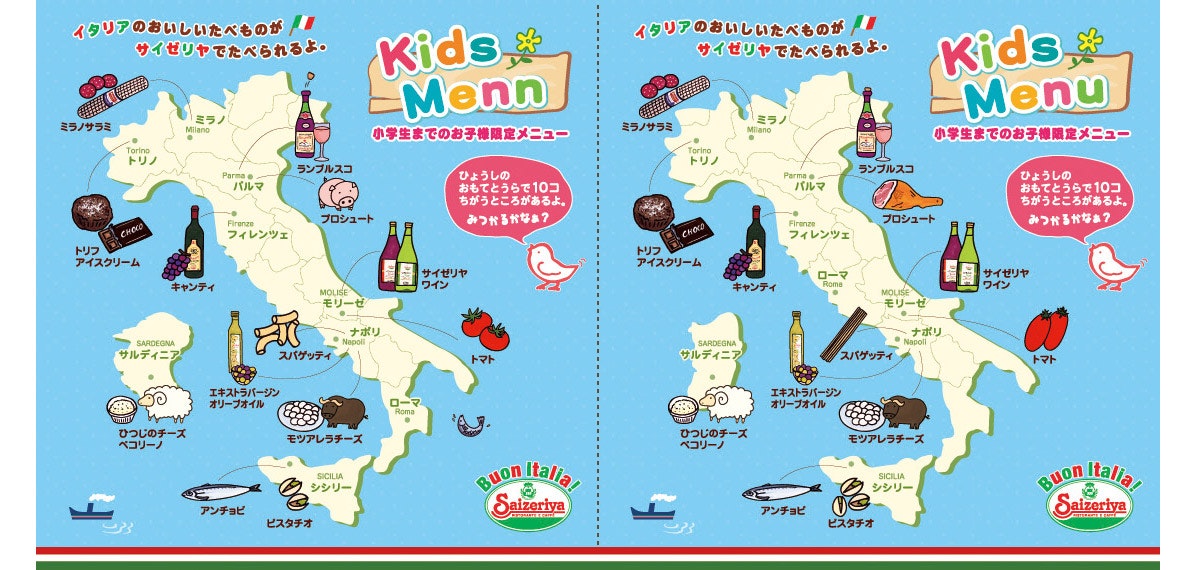
イタリアンレストランチェーンのサイゼリヤに置かれている間違い探しは,見た目はポップで親しみやすい絵柄にも関わらず,その難易度は非常に高く,10個全ての間違いを発見することは不可能に近い.軽い気持ちで挑めば,食事や会話そっちのけで間違い探しに熱中してしまう上に,大抵は7,8個しか見つけることができずモヤモヤしたまま退店を強いられる.その有様は,フェルマーの最終定理に魅せられて数学者人生を棒に振ったかつての研究者たちを彷彿とさせる.
ただ私は無謀にもこのようなことを考えた.「人類の英知を結集すれば,サイゼリヤの間違い探しを片面だけで解くことができるのではないか?」 両面を使っても難しいものを片面だけで解くとなれば,人類最難関の挑戦と銘打っても大げさではないはずだ.もちろん間違い探しは両面があって初めて成立するものであり,片面だけでは異なる箇所を知るすべがない.しかし,これまでの傾向や違和感のあるイラストなどに着目すれば,間違いがありそうな場所を推定することは可能ではないだろうか.
そのようなことは不可能だと考える読者もいるかもしれない.この大きすぎる壁を前にしてそう感じる読者の気持ちは十分に理解できる.しかし我々人類には知恵という最大の武器がある.私はこの難問を解くために,現代科学の大きな成果である機械学習を利用する.機械学習技術はまさにフェルマーの最終定理における谷山志村予想のように,解決のための大きな武器となるであろう.
やること
前置きが長くなったが,要するにこの記事の目標は,サイゼリヤの間違い探しにおいて,片面だけ見て間違いの場所を特定することである.そのために,過去の間違い探しのデータを用いて,深層学習を用いた物体検出モデルを学習する.

データセット作り
まず,間違い探しの元画像を手に入れる必要がある.ありがたいことに,サイゼリヤの公式サイトで過去の間違い探しの画像が全て公開されている.
さらに親切なことに,ここには解答も公開されているので,自分でせっせと間違い探しをする必要はない.2006年から開始された間違い探しは,現在で32回分の解答が公開されている.
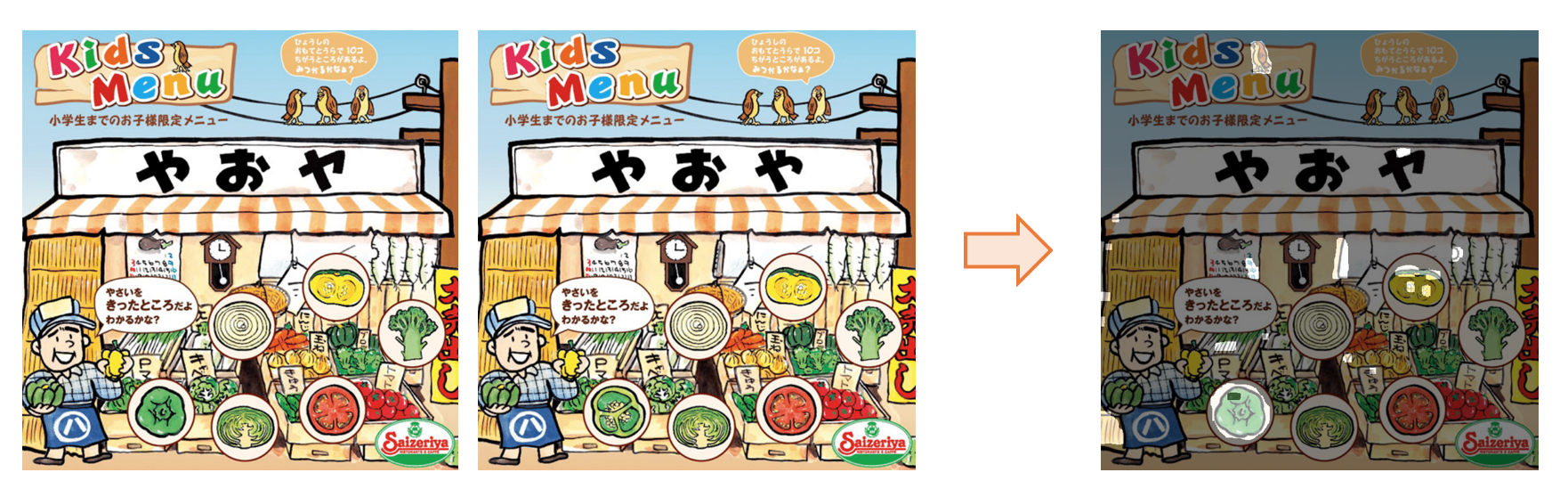
問題は,どのようなデータセットを準備するかということである.機械学習においては基本的に画像と正解データのペアが不可欠だ.画像において検出したい物体の位置を示す方法はいくつかある.始めは左右の画像を比較して間違いの場所を自動的に検出し塗り潰そうと試みた(参考記事).下の画像は両面の画素値の差から計算された間違いの箇所である(右の画像の明るくなっている部分が間違い).様々な前処理,後処理を加えたおかげである程度は正しく検出できているものの,小さな間違いはどうしても検出が難しい.また細かなノイズも見られ,綺麗なマスクが作られていないことがわかる.
次に公式の解答画像を使って間違いの場所を自動的に取得しようとしたが,こちらも処理が煩雑で正確なデータを得るのは困難だった.
どうやら自動で正解データを作るのは難しい.結局,たかだか30枚程度の画像なら自分で全部正解ラベルを与えようという結論になった.ピクセルレベルで間違いの場所を記録するのは労力が大きいため,代わりにBounding box(バウンディングボックス,物体の位置を示す長方形)を与えることにした.Bounding boxを使って学習する方法には**物体検出(Object Detection)**というタスクがある.その手法を活用すれば,用意した画像と正解データを使って学習を回すことが可能なはずだ.
方針は決まった.よってここからは実際に教師データを作成していく.まず公式サイトからダウンロードした画像を左右2つに分けて保存した.その後各画像に対し正解ラベルとなるBounding boxを与えていく.世の中は便利なもので,Bounding boxを与えるための便利なツールは既に世の中にたくさんある.ここでは Microsoftが開発した無料アノテーションツールであるVoTTを使った.
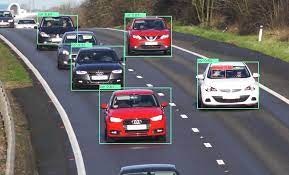
VoTTの詳しい使い方の説明は他の記事(例えばこちら)に譲るが,画像の入ったフォルダを用意しておけば,各画像の任意の場所にBounding Boxとクラス情報を与えることができる.今回検出したいのは間違い部分だけなので,"Item"というカテゴリを一つ作って全てそのクラスとして登録した.アノテーションの結果はPASCAL VOCの形式でxmlファイルに保存した.下の画像は,VoTTを使って右半分のイラストにある間違い箇所を四角く囲っている様子である.

(画像に1枚ずつラベルを与えていると,どこかで見たような間違い探しに出会った.そう,これは大学2年生の時,ふらっと入ったサイゼリヤで友人と一緒に解いた間違い探しであった.そこから次々と大学生活のたわいも無い思い出が蘇る... 昔を思い出して感傷的な気分に浸りたい人は,ぜひサイゼリヤの間違い探しに取り組んでみることをお薦めする.)
左右の画像はペアとしてではなく別のデータとして扱うため,32回分のイラストから64データが得られた.最後の1枚である2020年12月分の画像をテストデータとし,それ以外の31組62枚でモデルを学習する.これだけでは深層モデルの学習にはやや心許ないが,一枚にラベルを与えるだけでもかなりの時間を消費してしまったので,今回はこれ以上データを増やすのは諦めた.ネットには似たようなイラストの間違い探しがたくさんあるので,将来的にはそれらを使ってデータを増やすことも可能だと思われる.
Bounding Boxの与え方
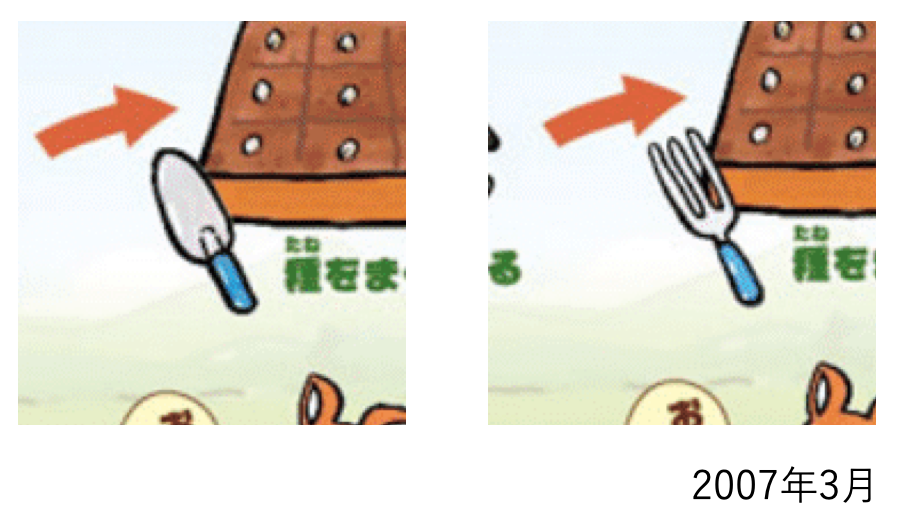
正解データを作る際,どの範囲にBounding Boxを与えるかという難しさがあった.例えば以下のような場合では,Bounding Boxを与える領域が明らかで,スコップ全体を囲えばいいだろう.
しかし以下のような画像では,大根の欠けた部分のみを囲うのか,1本の大根全体を囲うのか,それとも大根4本全てを囲うのかは自明ではない.
さらに以下のような場合,左の画像にある光が右の画像に無い.無いものに印をつけるのはなかなかに難しい.

囲み方には厳密な正解はないが,今回は迷ったら広めの領域全体を囲うことにした.例えば人の顔の目や口が違っていたら顔全体を囲う,などである.それ以外に困った箇所はかなり主観的にラベル付けを行なっているが,どうか許していただきたい.
間違いの傾向
正解データを作る過程で私は自分で間違い探しを31問解いた(正確には答えを見た).これほど一度にサイゼリヤの間違い探しを解いた人間はあまりいないのではないかと思う.その結果,間違いが含まれやすい場所の傾向が見えてきた.ここではサイゼリヤ間違い探し界の権威として,間違いを含みやすい箇所の一部を紹介する.
1. タイトル
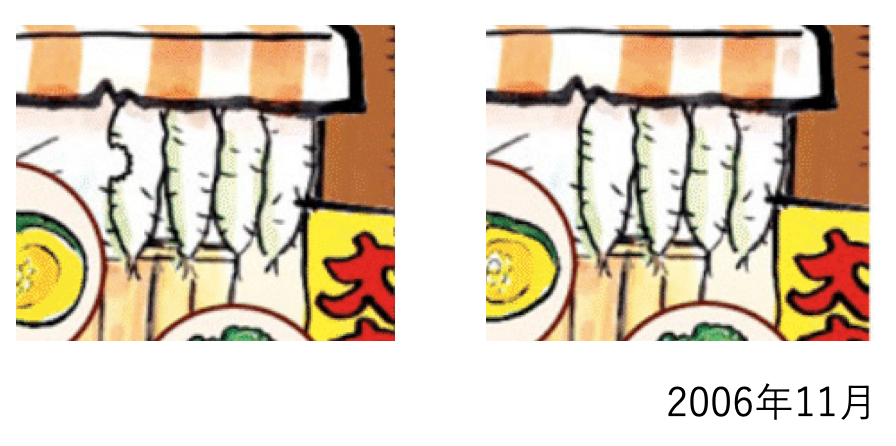
イラストには必ず「Kids Menu」と書いたタイトルが含まれる.タイトル部分の文字に間違いが含まれる回数を数えたところ,なんと31回中15回だった.さらに2006年11月分のように,タイトル部分に連結するイラストが異なる場合も含めると19回にも上る.すなわち2回に1回はタイトル付近に間違いがあると見ていい.

2. 規則性が崩れている場所
一般に,規則的に並んでいるものを1箇所変えるのは間違い探しの常套手段であり,サイゼリヤにもそれは通用する.左のイラストでは,下に並んだ丸い飾りのうち一つだけ四角くなっている.右のイラストでは,音楽隊の中で一人だけ麦わら帽子をかぶっている.このような変化はたとえ片面しかなくても間違いを見抜ける可能性が高い.

3. 羊
通称「サイゼリヤの羊」は2018年4月から本格的に出現し,それ以降合わせて9回描かれているが,この羊は片面にしか登場しない場合が非常に多い.なんと9回中8回で片面のみに現れるという間違いを担当しており,残りの1回(2020年3月)もリュックを背負っているかいないかという間違いがあった.つまり,羊を見たらそこに間違いがある確率が非常に高いのである.

4. コップ
特に近年の間違い探しでは食卓の様子が描かれることが増えた.食卓を含むイラスト8回のうち,コップに間違いがあったのはなんと5回であった.例えば以下の画像では,中身のジュースの色が違っていたり,ストローの長さが違ったりしている.コップ以外でもフォークやナイフなどの食器類には注意が必要である.

なお,これらの特徴は深層学習モデルでも学習できることが期待される.このような傾向を過去のデータから自動で学習することで,未知の間違い探しイラストに対しても片面だけで予測できるようになるのである.
物体検出モデルの学習
画像とBounding Boxのデータが集まれば,これを使って物体検出のモデルを学習する.ここでは物体検出に広く用いられているFaster-RCNNを使った.Faster-RCNNは2015年にMicrosoftが発表した物体検出のモデルで,深層学習を用いたEnd-to-endなパイプラインを実現した画期的な手法である.発表から5年経った今でも,「物体検出ならとりあえずFaster-RCNN」と真っ先に候補に上がるモデルとなっている(詳細はこちら等を参照).
Faster-RCNNはあまりにも有名なため,Pytorchなどの深層学習フレームワークでは既に一般画像でPre-trainされたモデルをインポートすることができる.今回はこちらの記事などを参考にしながらモデルを構築した.
コードはGithubにあげているので興味があれば参照していただきたい.
Dataloader
$xml2list()$関数はPASCAL VOC形式のファイルを読み込む関数であり,画像とアノテーションの情報を返す$MyDataset$クラスを定義する.
def xml2list(xml_path, classes):
xml = ET.parse(xml_path).getroot()
boxes, labels = [], []
for obj in xml.iter('object'):
label = obj.find('name').text
if label in classes:
# 各Bounding Boxの座標とラベルを取得
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text.split(".")[0])
ymin = int(bndbox.find('ymin').text.split(".")[0])
xmax = int(bndbox.find('xmax').text.split(".")[0])
ymax = int(bndbox.find('ymax').text.split(".")[0])
boxes.append([xmin, ymin, xmax, ymax])
labels.append(classes.index(label))
anno = {'bboxes': boxes, 'labels': labels}
return anno, len(boxes)
class MyDataset(torch.utils.data.Dataset):
def __init__(self, image_dir, xml_paths, classes):
super().__init__()
self.image_dir = image_dir
self.xml_paths = xml_paths
self.image_ids = sorted(glob('{}/*'.format(xml_paths)))
self.classes = classes
self.transform = transforms.Compose([
transforms.ToTensor()
])
def __getitem__(self, index):
image_id = self.image_ids[index].split("/")[-1].split(".")[0]
# 画像の読み込み
image = Image.open(f"{self.image_dir}/{image_id}.png")
image = self.transform(image)
image = image[:3, :, :]
# 正解データの読み込み
path_xml = f'{self.xml_paths}/{image_id}.xml'
annotations, obje_num = xml2list(path_xml, self.classes)
boxes = torch.as_tensor(annotations['bboxes'], dtype=torch.int64)
labels = torch.as_tensor(annotations['labels'], dtype=torch.int64)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
iscrowd = torch.zeros((obje_num,), dtype=torch.int64)
target = dict()
target["boxes"] = boxes
target["labels"] = labels + 1
target["image_id"] = torch.tensor([index])
target["area"] = area
target["iscrowd"] = iscrowd
return image, target, image_id
def __len__(self):
return len(self.image_ids)
モデル
モデルはPyTorch事前訓練されたFasterRCNNをでインポートした.モデルの中身をあれこれと変更する必要はないが,出力クラスの数だけ調整する必要がある.
def FasterRCNN(num_classes):
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
訓練
データセットとモデルを作成して訓練する.画像データと正解xmlファイルを入れるフォルダをあらかじめ作成しておく必要がある.ここでは20epoch学習し,毎回テストを行なっている.
def train():
# パラメータ
num_epochs = 20
batch_size = 1
base_path = '****************' # rootフォルダを入れてください
xml_dir = base_path + "data/label" # 正解データのパス
img_dir = base_path + "data/img" # 学習画像のパス
test_dir = base_path + "data/test" # テスト画像のパス
save_path = base_path + "result" # 結果保存フォルダのパス
dataset_class = ['Item'] # カテゴリ(ここでは一種類のみ)
colors = ((0, 0, 0), (255, 0, 0))
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
dataset = MyDataset(img_dir, xml_dir, dataset_class)
train_dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn)
model = FasterRCNN(num_classes=len(dataset_class)+1).to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
for epoch in range(num_epochs):
# 訓練
model.train()
train_loss = 0
for i, batch in enumerate(train_dataloader):
images, targets, image_ids = batch
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
train_loss += losses.item()*len(images)
optimizer.zero_grad()
losses.backward()
optimizer.step()
print(f"epoch {epoch+1} loss: {train_loss / len(train_dataloader.dataset)}")
torch.save(model, 'model.pt')
test(model, dataset_class, colors, test_dir, save_path, device)
テスト
テスト用の画像を入れたディレクトリから各画像を読み取り,確信度の高い上位10個のBounding boxを出力する.
def test(model, dataset_class, colors, test_dir, save_path, device):
model.eval()
test_classes = ['__background__'] + dataset_class
for imgfile in sorted(glob(test_dir + '/*')):
# テスト
img = cv2.imread(imgfile)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image_tensor = torchvision.transforms.functional.to_tensor(img)
with torch.no_grad():
prediction = model([image_tensor.to(device)])
# 結果の描画
for i, box in enumerate(prediction[0]['boxes'][:10]):
score = prediction[0]['scores'][i].cpu().numpy()
score = round(float(score), 2)
cat = prediction[0]['labels'][i].cpu().numpy()
txt = '{} {}'.format(test_classes[int(cat)], str(score))
font = cv2.FONT_HERSHEY_SIMPLEX
cat_size = cv2.getTextSize(txt, font, 0.5, 2)[0]
c = colors[int(cat)]
box = box.cpu().numpy().astype('int')
cv2.rectangle(img, (box[0], box[1]), (box[2], box[3]), c, 2)
cv2.rectangle(img, (box[0], box[1] - cat_size[1] - 2), (box[0] + cat_size[0], box[1] - 2), c, -1)
cv2.putText(img, txt, (box[0], box[1] - 2), font, 0.5, (0, 0, 0), thickness=1, lineType=cv2.LINE_AA)
# 結果の保存
file_name = imgfile.split("/")[-1].split(".")[0]
pil_img = Image.fromarray(img)
pil_img.save(save_path + f"/{file_name}_result.png")
実際の学習は,誰でも手軽に機械学習を動かせることで有名なGoogle Colabで行なった.画像の枚数がそこまで多くなかったので,学習は数分で完了した.
実際に間違い探しを解かせてみる
いよいよ学習後のモデルを使って,片面の画像のみから間違いの位置を予測してみる.予測するのは2020年12月分のイラストである.

モデルから計算された複数のBounding Boxのうち,予測の確信度が高い上位10個を選んで表示する.学習は20epoch回したが,Bounding boxの予測スコアのうち上から10番目の値(つまり検出のボーダーライン)が最も高くなったのが3epoch目だったのでその出力を結果として使う.
ついに人類の夢に挑む時.その心持ちはまさに最後の審判を迎えた時のようであろうか.
まず,右側の画像を入力した時の結果がこちらだ.

間違いと疑われる上位10個の領域が赤枠で囲まれている.添えられている数字は予測の確信度(0が最小,1が最大)である.
当然これだけでは我々も正誤を判定できない.よって,公式ページにある正解と照らし合わせてみる.

お?
流石に全部綺麗に当たっているというわけにはいかない.しかし,
- 左側中央にいる「サイゼリヤの羊」の服
- 中央やや左下で肉を食っている少年
- 右上の窓枠(正確には中央の棒の位置)
の3つは当たっている.どうやら「サイゼリヤの羊がいるところに間違いあり」という経験則を,モデルがきちんと学習していたようだ.
さて,左側の画像はどうか?

先ほどとは少し違う結果になっている.よく見ると,
- 右上隅の木の高さ
- 右下の男の子のサンタ帽
- 左下の男性の顔(正確には口元)
が当たっているではないか!また,場所は多少ずれているものの,サイゼリヤの羊もきちんと認識している.結果として,右と左両面合わせると10個中6つの間違いを発見することができた.正直私は「全然検出できませんでした〜」というオチを予想していたのだが,半分以上当たっているならばこの挑戦は十分成功したと言えるだろう.
なお,さらなる改善点として以下のようなものが挙げられる.
- データを増やす.サイゼリヤのイラストと似たスタイルの画像をデータセットに加えることで性能を向上させる.
- データに重み付けをする.間違い探しの特徴は時期によって変化しているため,最近のデータの方がより予測に役立つ情報を持っている.よって損失関数を重み付けし,最近の画像を重視するように学習させる.
- モデルを変更する.現在はFaster-RCNNより性能が良いと報告されているモデルや,少ないデータ量でも高い性能を示すモデルが提案されているので,それらを使ってみる.
- 常識を考慮する.1箇所だけ規則性が崩れている場所や常識的におかしい箇所は間違いとなる可能性が高い.よってそういった場所を発見できるような学習の損失を加える.
これらの手法を駆使すれば正解できる確率は上がっていくかもしれない.しかしサイゼリヤ側も我々の挑戦を手をこまねいて見ているわけではなく,前例に無い新たな間違いを生み出していくだろう.人類の挑戦はまだ終わらない.
終わりに
最後に,まだ正解が明らかになっていない2021年3月分の間違い探しの予測結果を載せておく.

私はまだ自分で解いて確認をしていないので,ぜひ皆さんの目で結果を確かめていただきたい (公式サイト).
しかし,たとえこれが全問正解していようが,全く正解していなかろうが,変わらないことが一つある.それは,どれだけ科学が発展したとしても,次に我々がまたサイゼリヤに行った時には,今までと変わらず童心に帰って間違い探しを楽しむに違いないということである.