はじめに
実は1回目のqiita投稿でFaster-rcnnの実装は出したんですが環境やpathの類が扱いずらいものになってしまったのでcolabで誰でも使えるようにしよう!と思って作りました。
とりあえず物体検出をやってみたい!という方に読んでいただけると幸いです。
ちなみに1回目の記事はこちら
諸注意
※本記事はPSCAL VOCフォーマットのデータセット向けです。
私はBDD100KというデータセットをPascalVOCフォーマットに変換して学習を行ったためclassラベルがBDD100Kのものとなっています。
(PSCAL VOCフォーマットであればpathを変えれば独自データの学習も可能です。)
コード&簡易データセット
すべてのコードはgithubに上げます。
データセットの展開後の想定ディレクトリ構造
colab_frcnn-main/
┣Faster-R-CNN.ipynb
┣ smallbdd/
┣test/
┣xml/
┣img/
localで動かす際の環境構築
コードをクローンしたうえで以下のコマンドを入力してください.
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install jupyterlab
pip install -r requirements.txt
その他バージョン
python 3.6
CUDA Toolkit 11.1 Update 1
cuDNN v8.1.1 (Feburary 26th, 2021), for CUDA 11.0,11.1 and 11.2
その1前準備
ドライブのマウント
仮にローカルで動かす場合はこの操作は必要ありません。
from google.colab import drive
drive.mount('/content/drive')
実行すると以下の画面になるので、URL飛んだ先のコードを記入してください。

ハイパーパラメータ、pathの指定
仮にオリジナルデータを使う際はここのコード(path)とclassを変えるだけで動くはず!
マイドライブまでのパスである**'/content/drive/My Drive/'**以降にクローンしたcolab_frcnn-mainのフォルダーまでのパスを入力してください。
#pathの指定(colab_frcnn-main直下まで)
path='/content/drive/My Drive/************'
bdd_xml=path+"/colab_frcnn-main/smallbdd/xml"
bdd_img=path+"/colab_frcnn-main/smallbdd/img"
test_path=path+"/colab_frcnn-main/smallbdd/test"
#datasetのクラス指定
dataset_class=['person', 'traffic light', 'train', 'traffic sign', 'rider', 'car', 'bike', 'motor', 'truck', 'bus']
#表示したいラベルの色の指定
#注意!!一番最初は背景クラスを示すので(0,0,0)にする(それ以外は自由)
colors = ((0,0,0),(255,0,0),(0,255,0),(0,0,255),(100,100,100),(50,50,50),(255,255,0),(255,0,255),(0,255,255),(100,100,0),(0,100,100))
#ハイパーパラメータの指定
epochs=10
batch_size=1
scale=720#画像のスケール設定(縦の大きさを入力)
xmlからデータの読み込み
import numpy as np
import pandas as pd
from PIL import Image
from glob import glob
import xml.etree.ElementTree as ET
import cv2
import torch
import torchvision
from torchvision import transforms
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torch.utils.data import TensorDataset
import os
class xml2list(object):
def __init__(self, classes):
self.classes = classes
def __call__(self, xml_path):
ret = []
xml = ET.parse(xml_path).getroot()
boxes = []
labels = []
zz=0
for zz,obj in enumerate(xml.iter('object')):
label = obj.find('name').text
##指定クラスのみ
if label in self.classes :
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.classes.index(label))
else:
continue
num_objs = zz +1
anno = {'bboxes':boxes, 'labels':labels}
return anno,num_objs
torchのDatasetを作る
class MyDataset(torch.utils.data.Dataset):
def __init__(self,image_dir,xml_paths,scale,classes):
super().__init__()
self.image_dir = image_dir
self.xml_paths = xml_paths
self.image_ids = sorted(glob('{}/*'.format(xml_paths)))
self.scale=scale
self.classes=classes
def __getitem__(self, index):
transform = transforms.Compose([
transforms.ToTensor()
])
# 入力画像の読み込み
image_id=self.image_ids[index].split("/")[-1].split(".")[0]
image = Image.open(f"{self.image_dir}/{image_id}.jpg")
#画像のスケール変換
t_scale_tate=self.scale ##目標のスケール(縦)
#縮小比を計算
ratio=t_scale_tate/image.size[1]
##目標横スケールを計算
t_scale_yoko=image.size[0]*ratio
t_scale_yoko=int(t_scale_yoko)
#print('縮小前:',image.size)
#print('縮小率:',ratio)
#リサイズ
image = image.resize((t_scale_yoko,t_scale_tate))
#print('縮小後:',image.size)
image = transform(image)
transform_anno = xml2list(self.classes)
path_xml=f'{self.xml_paths}/{image_id}.xml'
annotations,obje_num= transform_anno(path_xml)
boxes = torch.as_tensor(annotations['bboxes'], dtype=torch.int64)
labels = torch.as_tensor(annotations['labels'], dtype=torch.int64)
#bboxの縮小
#print('縮小前:',boxes)
boxes=boxes*ratio
#print('縮小後:',boxes)
area = (boxes[:, 3]-boxes[:, 1]) * (boxes[:, 2]-boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
iscrowd = torch.zeros((obje_num,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels+1
target["image_id"] = torch.tensor([index])
target["area"] = area
target["iscrowd"] = iscrowd
return image, target,image_id
def __len__(self):
return len(self.image_ids)
Dataloaderの作成
def dataloader (data,dataset_class,batch_size,scale=720):
xml_paths=data[0]
image_dir1=data[1]
dataset = MyDataset(image_dir1,xml_paths,scale,dataset_class)
#データのロード
torch.manual_seed(2020)
def collate_fn(batch):
return tuple(zip(*batch))
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True,collate_fn=collate_fn)
return train_dataloader
その2modelの定義
resnet50で学習済みのものを用います。
もしほかのモデルを試したい場合は1回目の記事のmodel構築部分のmodel2を参考にしてください。
def model ():
#モデルの定義
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes=len(dataset_class)+1
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
その3学習
学習後に学習済みモデルを/colab_frcnn直下にmodel.ptとして保存します。
data_ALL=[bdd_xml,bdd_img]
train_dataloader=dataloader(data_ALL,dataset_class,batch_size,scale)
model=model()
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
num_epochs = epochs
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.cuda()
model.train()#学習モードに移行
loss_list=[]
for epoch in range(num_epochs):
loss_epo=[]
for i, batch in enumerate(train_dataloader):
images, targets, image_ids = batch##### batchはそのミニバッジのimage、tagets,image_idsが入ってる
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
##学習モードでは画像とターゲット(ground-truth)を入力する
##返り値はdict[tensor]でlossが入ってる。(RPNとRCNN両方のloss)
loss_dict= model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
#lossの保存
loss_epo.append(loss_value)
if (i+1) % 10== 0:
print(f"epoch #{epoch+1} Iteration #{i+1} loss: {loss_value}")
#Epochごとのlossの保存
loss_list.append(np.mean(loss_epo))
torch.save(model, path+'/colab_frcnn-main/model.pt')
その4テスト
保存済みの学習済みモデルを使用したい場合は一番下のコメントアウトを外して、一番最初のその1前処理の部分とこれ以降のセルを実行することで、学習部分を実行しなくてもテストが可能です。
import cv2
import glob
import matplotlib.pyplot as plt
data_class=dataset_class
data_class.insert(0, "__background__")
classes = tuple(data_class)
#学習済みモデルで推論する場合
#model=torch.load(path+'/colab_frcnn-main/model.pt')
結果の表示
model.to(device)
model.eval()
for imgfile in sorted(glob.glob(test_path+'/*')):
img = cv2.imread(imgfile)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image_tensor = torchvision.transforms.functional.to_tensor(img)
with torch.no_grad():
prediction = model([image_tensor.to(device)])
for i,box in enumerate(prediction[0]['boxes']):
score = prediction[0]['scores'][i].cpu().numpy()
if score > 0.5:
score = round(float(score),2)
cat = prediction[0]['labels'][i].cpu().numpy()
txt = '{} {}'.format(classes[int(cat)], str(score))
font = cv2.FONT_HERSHEY_SIMPLEX
cat_size = cv2.getTextSize(txt, font, 0.5, 2)[0]
c = colors[int(cat)]
box=box.cpu().numpy().astype('int')
cv2.rectangle(img, (box[0], box[1]), (box[2], box[3]), c , 2)
cv2.rectangle(img,(box[0], box[1] - cat_size[1] - 2),(box[0] + cat_size[0], box[1] - 2), c, -1)
cv2.putText(img, txt, (box[0], box[1] - 2), font, 0.5, (0, 0, 0), thickness=1, lineType=cv2.LINE_AA)
plt.figure(figsize=(15,10))
plt.imshow(img)
plt.show()
##結果
こんな画像が出力されるはず
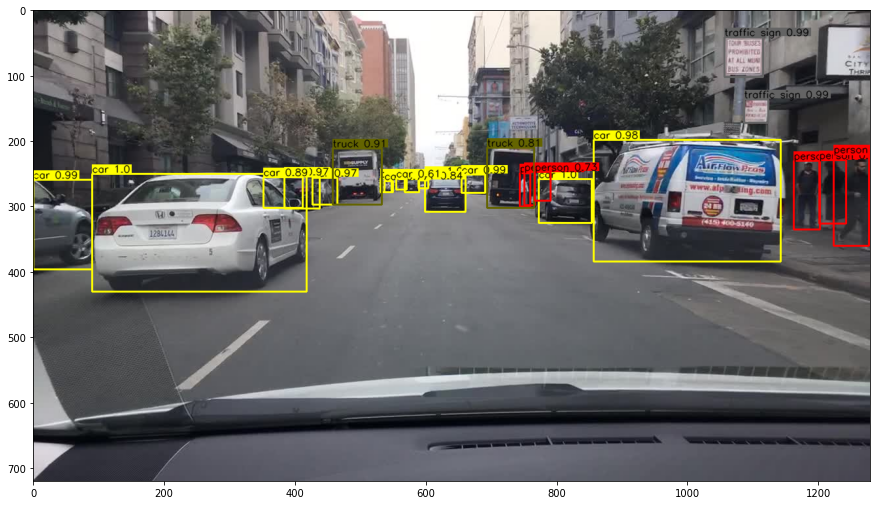
##終わりに
いかがだったでしょうかこれを使えばcolabで簡単に実行ができた(はず)です。
またpathを変えればオリジナルデータセット(PASCAL VOCフォーマット)での学習も簡単にできます。
Faster-R-CNNの実装に苦しんでいる、実際に使ってみたかっ方の参考になれば幸いです。