記事の更新
動かしやすいようにcolab実装版を書きました。
ぜひ以下の記事をご参照ください。
(dataloaderが速くなった)
2022/4/26更新
学習,推論,評価基盤を整えて,バグの修正を行ったコードを公開しました.
実験を行う際はこちらのコードを使用することをお勧めします.
https://github.com/Ryunosuke-Ikeda/Faster-R-CNN-pytorch
はじめに
Faster R-CNNをちゃんとしたデータセットで動かしている記事が少なくてかなり苦労したから備忘録
初めての記事投稿なので至らないところもあるとは思いますが何か間違い等ありましたらご指摘をお願いします。
諸注意
※本記事はPSCAL VOCフォーマットのデータセット向けです。
私はBDD100KというデータセットをPascalVOCフォーマットに変換して学習を行ったためclassラベルがBDD100Kのものとなっています。
コード
すべてのコードはgithubに上げます。
(一応以下のコードすべてコピペしてclass名をデータセットに合わせれば動くはず)
インポート
サクッと
import numpy as np
import pandas as pd
from PIL import Image
from glob import glob
import xml.etree.ElementTree as ET
import torch
import torchvision
from torchvision import transforms
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
#データの場所
xml_paths_train=glob("##########/*.xml")
xml_paths_val=glob("###########/*.xml")
image_dir_train="#############"
image_dir_val="##############"
上2行はxmlファイルの場所
した2行は画像の場所
データの読み込み
class xml2list(object):
def __init__(self, classes):
self.classes = classes
def __call__(self, xml_path):
ret = []
xml = ET.parse(xml_path).getroot()
for size in xml.iter("size"):
width = float(size.find("width").text)
height = float(size.find("height").text)
for obj in xml.iter("object"):
difficult = int(obj.find("difficult").text)
if difficult == 1:
continue
bndbox = [width, height]
name = obj.find("name").text.lower().strip()
bbox = obj.find("bndbox")
pts = ["xmin", "ymin", "xmax", "ymax"]
for pt in pts:
cur_pixel = float(bbox.find(pt).text)
bndbox.append(cur_pixel)
label_idx = self.classes.index(name)
bndbox.append(label_idx)
ret += [bndbox]
return np.array(ret) # [width, height, xmin, ymin, xamx, ymax, label_idx]
アノテーションの読み込み
classesには使用したデータのクラスを入れてください。
#trainのanotationの読み込み
xml_paths=xml_paths_train
classes = [###################################]
transform_anno = xml2list(classes)
df = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df = df.append(tmp, ignore_index=True)
df = df.sort_values(by="image_id", ascending=True)
#valのanotationの読み込み
xml_paths=xml_paths_val
classes = [#######################]
transform_anno = xml2list(classes)
df_val = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df_val = df_val.append(tmp, ignore_index=True)
df_val = df_val.sort_values(by="image_id", ascending=True)
画像の読み込み
#画像の読み込み
# 背景のクラス(0)が必要のため、dog, cat のラベルは1スタートにする
df["class"] = df["class"] + 1
class MyDataset(torch.utils.data.Dataset):
def __init__(self, df, image_dir):
super().__init__()
self.image_ids = df["image_id"].unique()
self.df = df
self.image_dir = image_dir
def __getitem__(self, index):
transform = transforms.Compose([
transforms.ToTensor()
])
# 入力画像の読み込み
image_id = self.image_ids[index]
image = Image.open(f"{self.image_dir}/{image_id}.jpg")
image = transform(image)
# アノテーションデータの読み込み
records = self.df[self.df["image_id"] == image_id]
boxes = torch.tensor(records[["xmin", "ymin", "xmax", "ymax"]].values, dtype=torch.float32)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
labels = torch.tensor(records["class"].values, dtype=torch.int64)
iscrowd = torch.zeros((records.shape[0], ), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"]= labels
target["image_id"] = torch.tensor([index])
target["area"] = area
target["iscrowd"] = iscrowd
return image, target, image_id
def __len__(self):
return self.image_ids.shape[0]
image_dir1=image_dir_train
dataset = MyDataset(df, image_dir1)
image_dir2=image_dir_val
dataset_val = MyDataset(df_val, image_dir2)
DataLoaderの作成
#データのロード
torch.manual_seed(2020)
train=dataset
val=dataset_val
def collate_fn(batch):
return tuple(zip(*batch))
train_dataloader = torch.utils.data.DataLoader(train, batch_size=1, shuffle=True, collate_fn=collate_fn)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2, shuffle=False, collate_fn=collate_fn)
僕が回したときはすぐGPUのメモリがあふれたからbatch_sizeは小さめ
モデルの定義
少ない学習枚数でも精度出したいんだったらmodel1.pyをおすすめします。
ただ自分である程度モデルもいじりたい!って方はmodel2.pyを使ってください。
(model2の方は解説記事無いに等しく、しかもtorchvisionのチュートリアルのソースコード間違ってるせいで永遠と悩みました。)
※注意num_classesは分類したいクラス数+1にしないと動きません。
(+1というのは背景も分類対象だから)
model1は普通にresnet50で学習済みモデルをバックボーンにしてる
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False)####True
##注意 クラス数+1
num_classes = (len(classes)) + 1
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model2はこんな感じ(チュートリアルにバグが潜んでるとは、、、)
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
backbone.out_channels = 1280
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
#チュートリアルパクるとここでエラー吐く。([0]を['0']にすれば動く)
'''
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
'''
#デフォ
roi_pooler =torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0','1','2','3'],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=(len(classes)) + 1,###注意
rpn_anchor_generator=anchor_generator)
#box_roi_pool=roi_pooler)
FasterRCNN関数にはいろんな引数がありかなりモデルをいじれます。
詳しくは こちら
学習
自動微分ってすばらしいよね
##学習
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
num_epochs = 5
#GPUのキャッシュクリア
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
##model.cuda()
model.train()#学習モードに移行
for epoch in range(num_epochs):
for i, batch in enumerate(train_dataloader):
images, targets, image_ids = batch##### batchはそのミニバッジのimage、tagets,image_idsが入ってる
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
##学習モードでは画像とターゲット(ground-truth)を入力する
##返り値はdict[tensor]でlossが入ってる。(RPNとRCNN両方のloss)
loss_dict= model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
if (i+1) % 20 == 0:
print(f"epoch #{epoch+1} Iteration #{i+1} loss: {loss_value}")
結果の表示
注意 ここでのctegoryを記入例に従って使用データのラベルを記入してください。
#結果の表示
def show(val_dataloader):
import matplotlib.pyplot as plt
from PIL import ImageDraw, ImageFont
from PIL import Image
#GPUのキャッシュクリア
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
#device = torch.device('cpu')
model.to(device)
model.eval()#推論モードへ
images, targets, image_ids = next(iter(val_dataloader))
images = list(img.to(device) for img in images)
#推論時は予測を返す
'''
- boxes (FloatTensor[N, 4]): the predicted boxes in [x1, y1, x2, y2] format, with values of x
between 0 and W and values of y between 0 and H
- labels (Int64Tensor[N]): the predicted labels for each image
- scores (Tensor[N]): the scores or each prediction
'''
outputs = model(images)
for i, image in enumerate(images):
image = image.permute(1, 2, 0).cpu().numpy()
image = Image.fromarray((image * 255).astype(np.uint8))
boxes = outputs[i]["boxes"].data.cpu().numpy()
scores = outputs[i]["scores"].data.cpu().numpy()
labels = outputs[i]["labels"].data.cpu().numpy()
category={0: 'background',##################}
#categoryの記入例
#category={0: 'background',1:'person', 2:'traffic light',3: 'train',4: 'traffic sign', 5:'rider', 6:'car', 7:'bike',8: 'motor', 9:'truck', 10:'bus'}
boxes = boxes[scores >= 0.5].astype(np.int32)
scores = scores[scores >= 0.5]
image_id = image_ids[i]
for i, box in enumerate(boxes):
draw = ImageDraw.Draw(image)
label = category[labels[i]]
draw.rectangle([(box[0], box[1]), (box[2], box[3])], outline="red", width=3)
# ラベルの表示
from PIL import Image, ImageDraw, ImageFont
#fnt = ImageFont.truetype('/content/mplus-1c-black.ttf', 20)
fnt = ImageFont.truetype("arial.ttf", 10)#40
text_w, text_h = fnt.getsize(label)
draw.rectangle([box[0], box[1], box[0]+text_w, box[1]+text_h], fill="red")
draw.text((box[0], box[1]), label, font=fnt, fill='white')
#画像を保存したい時用
#image.save(f"resample_test{str(i)}.png")
fig, ax = plt.subplots(1, 1)
ax.imshow(np.array(image))
plt.show()
show(val_dataloader)
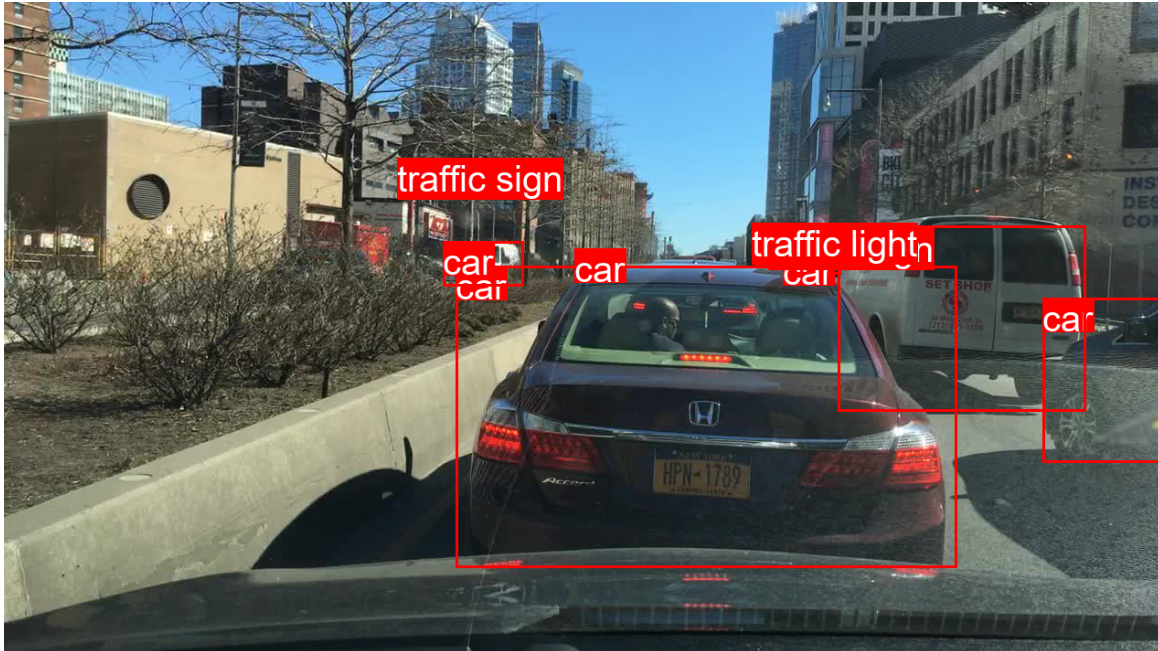
こんな感じで表示されるはず
最後に
- 初めて記事書きました。ただソースコードを貼っただけに近いですが参考にしていただけると幸いです。
- 論文解説とかもやってみたいなぁ
参考文献
-
torchvisionのチュートリアルはこちら