対象者
C++erを簡易的にレベル分けすることで初心者詐欺を減らそうという試み
でいうC++初心者以上であることが前提です。
また日本の義務教育ないしそれに相当するものを終了していることも条件とします。
Cl、まだチュートリアル以前で
— std::gaccho( ¨̮ ); (@wanotaitei) April 27, 2019
なんのために存在しているのか未だにわかっていません……。
単体テストって1つのソースファイルのみを入れて実行するやつですかね?
— std::gaccho( ¨̮ ); (@wanotaitei) April 27, 2019
(名称をよくわかっていない)
「砂糖ってしょっぱいですよね?」級の発言をしているあなたでも大丈夫!1から、・・・いいえ、0から始めましょう!( @Gaccho 氏へのdisがひどい)
これまであなたはどうやってプログラムを書いてきましたか?
- ちょっとずつプログラムを大きくして
- こまめにコメントアウトしながらmain関数を書き換えながら・・・
- ノリと勢いで
- 目についた不具合があったら都度直して
- なんとなく検索で引っかかるコードをコピペで継ぎ接ぎして
- 気分で関数わけ
- よくわかんないけど、うまくいくようになった
なんてかんじでしょうか?
こういうのを「もぐらたたき開発」なんて言ったりすることがあります。
もぐらたたき開発の限界
もぐらたたき開発でもプロジェクトがごくごく小規模であれば成立してしまったりします。また個人開発しているとなおさらその傾向が強くなります
しかし規模が大きくなるにつれて
- ソフトウェアの世代が変わったときに、一度は枯れたバグが復活している
- 実装の仕様がふらふらしている
- 発生するかもしれない要因に対して予め準備するのではなく、発生してから考える。
- ある作業を実施できる人、対応できる人を1人のままにしている
- バグの調査が難しくなる
- コードが把握しきれなくなる
- 手を出せない魔の領域ができる
- 成果物としてメンテナンスされ続けるドキュメントが明確になっていない
などの問題ができてきて、次第に改修困難になり最終的には破棄処分せざるを得なくなります。
それでも金の力で人月を浪費して無理やり押し切る、なんてケースも有るようですが、とくに趣味開発では自分のモチベが絶対なので、こんなことが起きたらモチベが続かなくなります。
もぐらたたき開発をやめるための武器
もちろんDRY原則を始めとするコーディング上のベストプラクティスの導入なんかも重要なのですが、そういったベストプラクティス導入を動機づける武器があります。
それが単体テストとCIです。
単体テスト
まずはみんな大好きWikipediaの日本語版を見てみましょう。
コンピュータプログラミングにおいて単体テスト(たんたいテスト)あるいはユニットテスト(英語: Unit test)とは、ソースコードの個々のユニット、すなわち、1つ以上のコンピュータプログラムモジュールが使用に適しているかどうかを決定するために、関連する制御データ、使用手順、操作手順とともにテストする手法である[1]。ユニットとはアプリケーションのテスト可能な最小の部品単位である、と直観的にとらえることができる。手続き型プログラミングでは、ユニットは、モジュール全体のこともあるが、より一般的には、個々の関数や手続きである。オブジェクト指向プログラミングでは、ユニットは、クラスなどのインタフェース全体だが、個々のメソッドであることもある[2]。単体テストは開発プロセス中にプログラマー、時にはホワイトボックステスターによって作成される。
いきなりこれ読んで分かるならもうこの記事読まなくて大丈夫です。よい旅路を。
表面的にはユニットに対してなんらかの検査を行うのが単体テストです。
ユニットが何たるかというとC++においては、概ね関数ないしクラスが該当します。つまり関数単位での検査が主になると思います。でもそもそも関数ってなんでしたっけ?
関数とは(義務教育に立ち返って)
日本人が「関数」という単語を初めに習うのは中学2年の数学の時間で1次関数を習うときだと思われます1。手元にあった学校図書から出ている平成17年に教科書検定を通った中学校数学22の教科書では
(前略)ともなって変わる2つの変数x, yがあって、xの値を決めるとそれに対応するyがただ一つ決まるとき、yはxの関数であるといいます。
と書かれていました。懐かしいですね!
様々問題はあるものの教科書検定を通り抜けてきた教科書をなめてはいけません。優秀な皆さんはまさか中学校の教科書を捨てる、などという蛮行にはでていないはずなので探せば中学校数学の教科書は見つかるはずですからぜひ自分でも調べてみてください。えっ、捨てちゃった?しょうがないなぁ~、買え。
ちなみに学校で使われる教科書は普通の書店では手に入らず教科書配給会社から買う必要があります。東京都内ならJR中央・総武各駅停車の大久保駅でてすぐ(または新宿駅から徒歩15~20分)の第一教科書で買えます(土日祝休み)。近くの小滝橋通りはラーメン激戦区なのでついでにラーメンも食べていきましょう。古武士はええぞ。
さてその教科書に興味深いことが書かれています。
「関数」ということばは、英語の「function」の訳です。「function」には"機能"とか"働き"という意味があります
「function」の「fun」は中国語の「函」の発音と似ているため、「function」は中国では「函数」という用語を使い、「ファンスウ」と発音しています。
日本でも以前は「函数」と書いていましたが、使用漢字の制限により「関数」と改められました。
「関」には"かかわる"という意味があり、「関数」は数量の関係を表していることばと考えることができます。
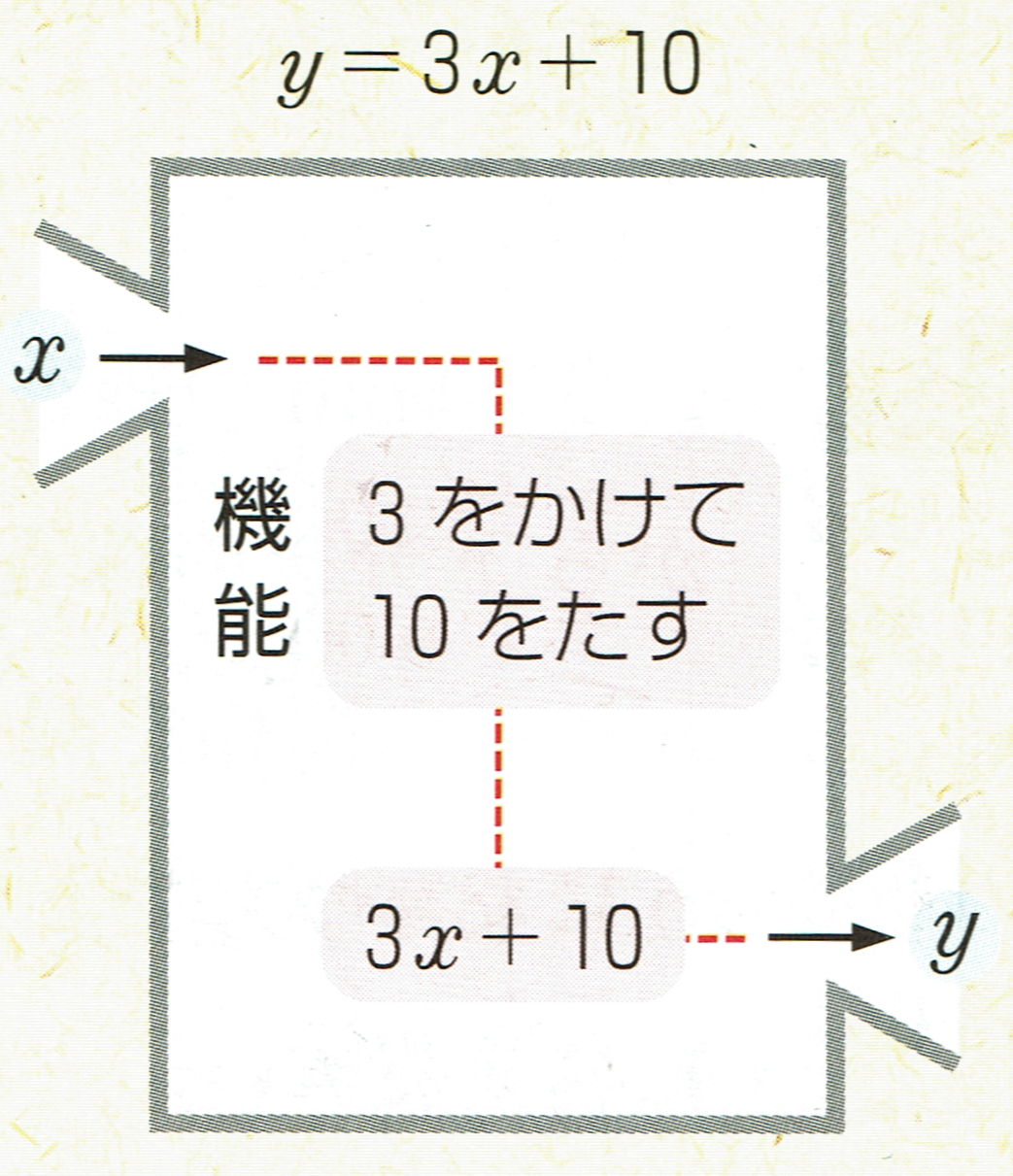
特にこの図に注目してください。入力に対して何らかの変換をし、出力するという機能が関数である、ということがよく分かる図です。この図を書いた人は神か!?まじで教科書検定を通り抜けてきた教科書なめたらあかんで!
関数とは(C++において)
C++における関数とはなんぞやについては
関数の創世から深淵まで駆け抜ける関数とはなんぞや講座
で解説済みです。
しかし、関数の本質は上で述べた入力に対して何らかの変換をし、出力するという機能であるということはなんら揺らぐものであありません。
明示的な入力と明示的な出力
int f(int n) { return n * 3 + 10; }
という関数を考えてみることにします。
まず入力は何でしょうか?もちろん引数nですよね。
では出力は何でしょうか?もちろん戻り値が出力ですね。
C++では引数経由で値を返すなんてこともとくにC++11より前の時代では盛んに行われていましたし、現代でもstd::error_codeへのlvalue referenceを引数に取ってエラー返却する例もありますね。

( @YukiMiyatake 氏の「BoostAsioで可読性を求めるのは間違っているだろうか 」より)
basic_yield_context operator[](boost::system::error_code & ec) const;
またそもそもC++には例外があるのでこれもまた出力ですよね。
隠れた入力がある例
C++においては関数に値を渡すのはなにも引数だけとは限りません。
- static storageの変数
- thread loacal storageの変数
も入力となりえます。
static int n;
int f() { return n * 3 + 10; }
int g()
{
static int n = 0;
return n++;
}
引数として渡すわけでもないのに関数を呼び出す前に何らかの操作が必要になるような例が隠れた入力であることが多いです。
隠れた出力がある例
隠れた入力と同様にして、隠れた出力が存在します。
public void processNext() {
Message message = InboxQueue.popMessage();
if (message != null) {
process(message);
}
}
この関数は、構文を見るかぎりは何も入力を取らず何も出力を返さないように見えるが、何かに対して明らかに依存しているし、明らかに何かをしている。実は、この関数には入力と出力の組が隠れている。その隠れた入力とは
popMessage()を呼び出す前のInboxQueueの状態だ。そして、隠れた出力とはprocessが引き起こしたあらゆる結果と、それに加えて、処理が終わった後のInboxQueueの状態だ。間違いなく
InboxQueueの状態はこの関数の本物の入力だ。その値を知らなければprocessNextの挙動も分からない。そして、出力の方も本物だ。processNextを呼び出した結果は、InboxQueueの新たな状態を考慮しないと完全に理解することはできない。
関数単位で単体テストを行うとは
ようやく本題。関数とは入力に対して何らかの変換をし、出力するという機能であると前に述べましたが、関数単位で単体テストを行うとは、関数に対して何かしらの入力を与え、出力が想定通りか検査するプログラムを記述することです。
追記: テストしやすい関数とは
ずーっとこの図を探していて見つけられなかったのですが、ふとしたきっかけで見つけたので紹介しておきます。
新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡
にちょうどいい画像があるのでお借りしよう。

隠れた入力や出力がない関数のほうがテストしやすいし、またそういう関数をつくるべきです。
隠れた入力や出力をしたくなったときはそれを明示的な入力や出力に変換するラッパー関数を書いてそれを使うようにすると排除できるように思います。
どのように単体テストを記述するか
単体テストフレームワークの選出
Rustみたいに言語そのものでテストの方法が提供されていれば素晴らしいのですが、残念ながらそのようなことはC++ではないので、誰かが作ったテストフレームワークをまず選ぶところから始めます。
テストフレームワークに求められる必須要件はクロスプラットフォームなxUnitであることです。そうでないものは使い物にならないので使わないでください。
有名なのは
- GoogleTest
- Boost.Test
でしょうか。今回はGoogleTestによく似ていて私が愛用している @srz_zumix 氏作のiutestを利用します。
iutestはヘッダーオンリーなのでincludeするだけで使えます。
単体テストフレームワークの使い方を覚える
C++の単体テストフレームワークは概ねどれもC++言語にリフレクションがないことも相まって、マクロの塊です。
したがってちょっと癖のある書き方になります。
まず通常と同じくmain関数を・・・と言いたいところですが
#define IUTEST_USE_MAIN 1
#include <iutest.hpp>
しておくことでiutestのヘッダーをincludeしたときにmain関数も定義してくれます。言い換えるとどこか一つの翻訳単位でのみ定義してください(さもないと翻訳単位ごとにmain関数が作られて衝突する)。
ではテストを書いていきます。
int f(int n) { return n * 3 + 10; }
のような関数に対して
IUTEST(MyTest, f)
{
int x = 0;
IUTEST_ASSERT_EQ(10, f(0));
IUTEST_ASSERT_EQ(13, f(1));
}
のように書きます。詳しく見ていきましょう。
まずIUTEST(MyTest, f)ではテストケース名とテスト名を書きます。テスト名は迷ったら対象の関数名にしとけばいいです。テストケース名はとりあえずはテストを束ねたものと思ってもらって構いません。**ただしCamelCaseで書きましょう。より正確には_を使ってはいけません。**これはC++特有の事情によるものです。詳細は
よくある質問 — Google Test ドキュメント日本語訳
に譲りますが、C++では__(アンダースコアの連続)を含む識別名(関数名とか)が予約されているため使ってはいけないことに起因します。
ref: Google Testのテストケース名やテスト名にアンダースコアを使用してはいけない
もしJavascriptの単体テストフレームワークJestなどを使ったことがある人がこの記事を読んでいたらこう思うかもしれません。「テストケース名って一つしか書けないの?階層化できないの?」と。C++の著名な単体テストフレームワークでは今のところないような気がします。
IUTEST_ASSERT_EQは検査の本体部分です。この場合第二引数が(実際の値)が第一引数(想定した値)と等しいことを検査します。
比較系の検査マクロは大体どのフレームワークでも
EQ: ==NE: !=LT: <LE: <=GT: >GE: >=
があります。またiutestにはポインタの検査をするときに、Visual Studioのコード分析を効果的に使えるように専用のマクロがあり
IUTEST_ASSERT_NULLIUTEST_ASSERT_NOTNULL
を使うことで__analysis_assumeを省略できます。
浮動小数点型を比較するとき、同値比較は行うな、という話がよくありますが、自分で誤差を考慮して比較するのは面倒なので
IUTEST_ASSERT_FLOAT_EQIUTEST_ASSERT_DOUBLE_EQ
があります。これは最下位桁単位を使った比較になります。
例外を投げるか検査するにはIUTEST_ASSERT_THROW(与えられた型の例外を投げる)、IUTEST_ASSERT_ANY_THROW(なんか例外を投げる)、IUTEST_ASSERT_NO_THROW(例外を投げない)があります。
C++ではtemplate関数をよく書くと思いますが、これの検査をするときにいちいちそれぞれの型についてテストケースを作るのは面倒です。そこで型パラメータテストを利用します。
template<typename T>
struct StringViewSplit : public ::iutest::Test {};
IUTEST_TYPED_TEST_CASE(StringViewSplit, ::iutest::Types<char, wchar_t, char16_t, char32_t>);
IUTEST_TYPED_TEST(StringViewSplit, chain_front_by_singe_char)
{
}
まず::iutest::Testを継承するクラスを作ります。これがテストケース名になります。
次にIUTEST_TYPED_TEST_CASE(StringViewSplit, ::iutest::Types<char, wchar_t, char16_t, char32_t>);のようにして検査する型をすべて指定します。
あとはIUTESTの代わりにIUTEST_TYPED_TESTにしてテストを書いていきます。
さらに詳しい情報は
iutestのドキュメントを見てください。またiutestはGoogle Testによく似ているので
なんかも参考になります。
こうして書いたテストをコンパイルして普通に実行するとテストが実行されます。実行するときに引数を渡すと特定のテストをskipしたりできるフレームワークもあります。
どんな検査を書けばいいのか?
単体テストフレームワークの使い方はわかっても何を検査すれば良いんだろう?というのは大きな悩みです。
テストの書き方のコツってありますか
— uint256_t (@uint256_t) 2018年7月21日
単体テストフレームワークの作り方やテスト駆動開発の方法は山のように紹介されているのにテストの書き方そのものってあまり見ない。
— yumetodo-鳥の氷河から逃げる (@yumetodo) 2018年7月21日
俺たちは雰囲気とノリと勘と気分でテストを書いている(あかん https://t.co/1aEmZcz9kz
俺たちは雰囲気とノリと勘と気分でテストを書いている(あかん
・・・気を取り直して、どんな検査を書けば良いのか?(あるいは書かないべきか)ですが、
- すべての条件分岐を通るように検査する: 特定のルートだけ検査したのでは不十分
- 例外が投げられる入力を与える検査をする: 意図した例外を投げているかは調べ忘れやすい
- 未定義動作を起こす検査をしない: 未定義動作を検知する方法はないのでそういう入力を与えない
- 条件分岐の境界値になるような入力を与える検査をする: 「以下」と「未満」を間違えたりド・モルガンの法則をど忘れするのはよくあるミスなので境界値を与えることで効率よくバグが見つかる
- (型パラメータテストで)結果がportableにならない型は
if constexprで検査を弾く: →C++17のif constexprがあると嬉しかったシーンを具体的に - 時間がかかりすぎる検査は可能ならば避ける: 時間がかかるテストは誰も実行しない
が挙げられると個人的には思っています。多分もっとあるけど。
関数への入力に乱数を与えるのは一般にはテスト時間を長引かせるので本当に必要か考える必要があります。
https://blog.goo.ne.jp/xmldtp/e/1d54a33d0bef7481f18907aef2ffd548
単体テストのテストケースは(つまり、分岐・条件網羅のみを考えた場合)、
分岐条件がなければ、1つの戻り値しか取れないので、1つの同値ケースとなり、
1個のテストしか、しないでよい(このとき、このケースは正常系)。
我々がプログラムを書くときに普通条件分岐がでてきますが、この条件分岐を書く動機がなんだったか振り返ると
https://blog.goo.ne.jp/xmldtp/e/1d54a33d0bef7481f18907aef2ffd548
- 分岐チェックする変数の値は、システムが扱うべき値であり、扱い方が異なるので、分岐が起きている
大人と子供で料金が異なるというようなケース。
同値ケースは別れ、それぞれテストする必要がある - 分岐チェックする変数の値は、システムが扱うべき値の範囲外である
大人が0、子供が1とコード化されているところにー1が入ってきたような場合
範囲外の値をエラーとし、エラー処理を行う。
その後、どうなるかは、仕様による - 分岐チェックを行いたいが、そもそも、行える状態にない
大人が1、子供が0というコード体系は、DBから拾ってくるが、そのDBにアクセスできない
というもの。エラー、ないしは異常終了する
その後、どうなるかは、仕様による
のように分類されます。この内1は一般に正常系と呼ばれます。2,3は異常系と呼ばれたり、2はワーニング系と呼ばれたり、3は例外系と呼ばれたりします。
20220418追記: デシジョンテーブル
複雑な条件分岐がある場合、テストケースが漏れてしまうことが考えられます。予めデシジョンテーブルを用いることで、すべてのパターンを洗い出しておき、それをテストにしていくことで、漏れがなくなり、またレビュワーの人もレビューしやすくなるでしょう。
もっともあまりにも複雑で組合せ爆発する場合はペアワイズ法の適用が必要になるかもしれませんがそこはケース・バイ・ケースということで・・・。
単体テストをいつ書くのか
テスト駆動開発という考え方があります。
- 作りたい機能を定める
- 機能を検証するテストを書く
- テストが落ちることを確認する
- テストが通るように実装する
というステップで開発していくわけですね。
これの利点は
- 単体テストしやすく実装することが指標になるのでテストしづらい隠れた入力・出力がある実装が少なくなる
- 行き当たりばったりな関数分けが減りコードの見通しが良くなる
- なんでもやる関数が減る
- 仕様が明確になるのでドキュメントを書きやすくなる
などがあります。
単体テストが機能していることを調べるにはどうしたら良いか
単体テストを書いたとしてどのくらい単体テストが機能しているのか調べるにはどうしたら良いでしょうか?全部のテストをじっくり眺める?もうちょっと客観的で機械的な判断基準がほしいところです。さもないとテストの品質がわかりません。
テストの品質はテストの網羅率を測る=カバレッジ(coverage)を取ることで調べるのが一般的です。
網羅率の測定方法は
https://www.techmatrix.co.jp/t/quality/coverage.html
にあるようにいろいろありますが最もよく使われるのは行カバレッジです。これは変数宣言などの処理でない部分は除いて、処理部分のある行全体に対して実行された行が何行あるかの割合を求めるものです。
この割合ですが一般に80%を超えるようにテストを書きましょうと言われています。100%にすることにこだわることはありません。
gccでは-coverageをコンパイルオプションにつけてコンパイルし、実行することで.gcnoという拡張子のファイルが生成されます。このままでは人間が読むには辛いので
https://github.com/linux-test-project/lcov
を用いて、変換してさらにgenhtmlを用いると読みやすいHTMLファイルに変換してくれます。
またgenhtmlには掛けずに、
のようなサービスに送信することで
カバレッジを公開することができます。このあと説明するCIを掛けるときに同時にカバレッジも測定してこうしたサービスに送信すると良いでしょう。
CMakeからカバレッジを取る作業をある程度自動化するには
if(STRING_SPLIT_ENABLE_COVERAGE)
message("coverage enabled")
include(CodeCoverage)
APPEND_COVERAGE_COMPILER_FLAGS()
set(COVERAGE_EXCLUDES "*gcc*" "*iutest*" "*/usr/include/*" "*mingw*")
SETUP_TARGET_FOR_COVERAGE(
NAME test_coverage # New target name
EXECUTABLE basic_test # Executable in PROJECT_BINARY_DIR
DEPENDENCIES basic_test # Dependencies to build first
)
option(STRING_SPLIT_ENABLE_COVERAGE_HTML "enable coverage result to html" TRUE)
if(STRING_SPLIT_ENABLE_COVERAGE_HTML)
message("coverage result to html enabled")
SETUP_TARGET_FOR_COVERAGE_TO_HTML(
NAME test_coverage_to_html # New target name
INFO_FILE_NAME test_coverage.info.cleaned # coverage task result file name
DEPENDENCIES test_coverage # Dependencies(coverage task, etc...)
)
endif()
endif()
のように書くことで(かなり省略してしまいましたが)カバレッジを取れます。(includeしているファイルは省略してます)
詳しくは
https://github.com/yumetodo/string_split
を覗いてみてください。
.travis.ymlをみると分かると思いますが
- mkdir build_release
- mkdir build_debug
- cd build_release
- cmake -DCMAKE_BUILD_TYPE=Release ..
- make ci
- cd ../build_debug
- cmake -DSTRING_SPLIT_ENABLE_COVERAGE="${USE_COVERALLS}" -DCMAKE_BUILD_TYPE=Debug ..
- make ci
だけでカバレッジ有効でビルドして実行して変換して後はcoveralls.ioに送信するだけになるようにcmakeを書いています。
このようにカバレッジについてみてきましたが、行カバレッジは本当に品質を表しているか?という話もあって
コードの行数で図るのは全く意味をなさない。しかしやはり数で捉えたいものだ。テストの数ならどうだろう?
— 173210 (@173210) 2016年10月23日
のような話が聞こえたりしてきます。
CI/CD
CIって何?
またしても日本語版Wikipediaから引っ張ってきましょう。
継続的インテグレーション、CI(英: continuous integration)とは、主にプログラマーのアプリケーション作成時の品質改善や納期の短縮のための習慣のことである。エクストリーム・プログラミング (XP) のプラクティスの一つで、狭義にはビルドやテスト、インスペクションなどを継続的に実行していくことを意味する[1]。特に、1990年代後半以降の開発においては、継続的インテグレーションをサポートするソフトウェアを使用する傾向が強まってきた。
もうすこし具体的には、gitを使った開発を前提として、commitがpushされるたびに、ビルド・テストの実行を行うことを自動化する、ということがCIと聞くとイメージされます。
ビルドをするとかテストをするとかそういう作業は面倒極まりないので、単にcommitしてpushするだけで完結するようにしたいものです。そうすることで開発速度が上がるというメリットがあります。
CDとは
コンパクトディスクのことではありません(キリッ
continuous delivery(継続的デリバリー)の略だったりcontinuous deploy(継続的デプロイ)の略だったりしますが、実質的にはほぼ同じことを指すので厳密な違いを理解することに意味はありません。
つまるところ、CIの延長線で、せっかくCIでビルド自動化したのだから、ビルド・テストが成功していて、git tagが打たれていたらRelease作業も自動化してしまおうというものです。リリース作業も面倒ですからgit tag打つだけでやってくれたら楽ですよね?
ビルド成果物をGithub Releaseに投げたり、どっかのサーバーにSSH経由で投げたりするのが一般的です。
CDのこともまとめてCIと呼んだりもします。
C++開発でCI/CDが必要な理由
もちろん他の言語でもCI/CDは必要ですが、C++ではより重要です。
C++は言語処理系が複数ある
C++は言語処理系がgcc, clang, msvc, etc...と複数あります。
処理系依存の処理が書かれていたり、他の処理系でまだ実装されていない機能を使っているとそのライブラリは使いにくいものになってしまいます。特定環境に特化したライブラリというのもあるでしょうが、可能なら多くの環境で自分が作ったライブラリが動いてほしいですよね?
ところが手元で複数の言語処理系をしかも複数のバージョンでビルドが通るか検証するのは非常に手間です。現実的にはいずれか単一の処理系だけで開発してしまうのではないでしょうか?
CIを組むことで複数の言語処理系での検証というのが現実的なコストになります。
また、各言語処理系は完全ではないので、複数の言語処理系でクロスチェックすることでC++規格に準拠したコードが書けている可能性が高くなります。
メンテナンスされたビルド方法のドキュメントになる
C++は言語公式でパッケージマネージャーを提供していませんし、もっといえば統一的なビルド方法も用意されていません。すべては開発者に委ねられています。
するとライブラリごとにビルド方法が異なる、という事態が現実に発生しています。もちろんビルド方法をきちんとドキュメント化すれば良いのでしょうが、ドキュメント化されたビルド方法でビルドできない、なんてことはしばしばあるのが現実です。
CIを組んでおけばCIを動かすビルドスクリプトはCIが通っていれば有効なビルド方法であることが保証できます。
コード分析ツールを使いやすくなる
例えばWindowsではgcc/clangが提供するサニタイザーの類は動きませんし、逆にmsvcのコード分析機能はWindowsじゃないと動きません。
鼻から悪魔が召喚されると噂の未定義動作や、メモリーリーク、不正なアドレスへのアクセスなどなどC++の開発には落とし穴がいっぱいありますから、コード分析ツールはフル活用したいものです。
先日もTwitterで
世にも奇妙なソースコードが出てきたので紹介
— std::gaccho( ¨̮ ); (@wanotaitei) April 27, 2019
・乱数等は一切使っていないので出力すると毎回同じものが出力されるはずが毎回違うものが出力される。
・3週間前は正常に動作していたが、今使ってみると全く正常に動作しない。
・上記は外部ライブラリ等を使用していない状態でも起こる。
怖い……。
なんて話があったのですが、clangが提供するAddressSanitizerは一発で原因を教えてくれました。
CIでこうした分析ツールを掛けるようにしていれば一発で洗い出せましたね。
どのようにCIを組むか
CIツール・サービスの選定
昔は猫も杓子もJenkinsでやっていたらしいのですが(ほんとに?)、Jenkinsはメンテナンスが大変らしく(ほんとに?)、Jenkins専属おじさんが発生していたそうです。せっかく自動化したのにそれ専任の人が必要になるんだったら意味がなくね?
現代では主にDockerを技術的な背景としてビルド環境をDockerのコンテナとして作っておき、その上でビルドをできるようにするというサービスを複数の会社が提供しています。
DockerなのでOSはLinuxになることがほとんどです。ただデフォルトのdockerイメージ以外だと速度が遅くなる傾向があるように思います。
ただしDockerでいきなり動かずにオプションとしてDockerで動くようなもの(Github Actionsなど)もあります。なにがいいかというと、Dockerの中でDocker動かすの面倒問題に直面せずに済むということです。C++ではあんま遭遇しなさそうだけど。
また多くのCIサービスがWindows/Mac/Linuxで動くようになってきつつあるので、かつてのAppVeyor一強時代は終了したようです。
- AppVeyor
- Azure Pipelines
- Bitrise
- buildkite
- Buddy
- Circle CI
- Cirrus CI: FreeBSDでも使える
- Codacy
- Codefresh
- Codeship
- Drone Cloud
- GitHub Actions
- Pekaflow
- Scrutinizer
- Semaphore
- Shippable
- Travis CI: CPU アーキテクチャが選べるように
- Wercker
OSSプロジェクトは無料で使えることが多いですが、ビルドが並列化できない、遅いことが多く、速度を上げるにはカネの力で殴るのが有効な解決策となります。狂気的な別解としては、たくさんのサービスで分散させて並列化するとかですかね。その分メンテコストが上がるわけですが。
CIサービス大本命、Github Actionsが登場したことでCI導入に躊躇していたプロジェクトもCIをつけるようになりつつある気がします。一方でGithub Actionsに対抗できる体力がないサービスは潰れていきそうです。
たくさん紹介しましたが、迷ったらTravis CIかGithub Actionsを使っとけば良い気がします。
ただWindowsで動かせるCIサービスはめっちゃ少ないのでみんながこのサービスを使うもんだからめっちゃビルドが遅いです。branch絞って普段頻繁にいじるbranchは外すとかしたほうがいいかも・・・
前はtea-ciなんてのもあったんですがmsys2のprojectでそれを無効化しているところを見るに動かんのでしょうね・・・。
そういえばGitのサーバーとして有名なBitbucketはCIも持ってますね。結構高速に動くのでよい。
まあCI業界は統廃合されたり新しく参入したりで日進月歩なので年に1回位は調べてみるといいです。
なんかもいい記事だと思います。
CMakeできるようにする
べつに必ずCMakeしないといけないわけではないのですが、CMakeを使ってビルドするのが徐々にデファクトスタンダートになりつつあるので、CMakeできるようにすると良いと思います。
方法は割愛しますが、add_custom_target/add_dependenciesを駆使して
- テスト実行までできるようにする
- カバレッジを取れるようにする
- サニタイザーを有効にしてビルド・実行できるようにする
のようにすると良いと思います。
CIを設定する
CIサービスごとに手順が違いすぎて解説するには余白が足りません。ただ基本方針としては
- ビルドはwandboxにやらせてCIはそこへ投げるだけにする: iutest付属のiuwandbox.pyやCranberries Build Toolを使って投げる
- ビルドをCI上で行う
- aptコマンドなどを叩いてコンパイラや必要なライブラリを入れてからビルド
- Dockerイメージを作っておいてビルド
のようになると思います。
各CIサービスのドキュメントとにらめっこしつつ、先人たちがどうCIを使っているか設定ファイルを覗いてみると良いと思います。
iutestは頭がおかしいほどたくさんのCIサービスを利用しているので(上に上げたサービスのほぼ全部)いろんなサービスの設定の書き方が参考になると思います。
CIのバッジをREADME.mdに貼ってアピールする
CIサービスはほとんどがCIの通過状況を小さな画像(バッジ)で提供してくれます。



























こういうのをREADME.mdに貼っておくとアピールになるでしょう。
結局ライブラリ作者はなにをするべきか
- 単体テストを書く
- CIを組む
- ビルドする
- テストを動かす
- カバレッジを取る
- コード分析ツールを動かす
リンク集
この記事を読み終わったらぜひ読んでほしいQiita記事です。特に @nonbiri15 氏の記事はここに上げた以外にも参考になる記事が多く上がっています。
- スピード感重視なのでテストは書かない。テストはなぜ開発を遅くするか
- 仕様変更に弱いからテストは書かない……?(´・ω・`)<仕様変更を想定するならテストを書いてくれ頼む
- モグラたたき開発を卒業しよう
- モグラたたき開発を卒業しよう 対策編
- 継続的インテグレーション(デリバリー)サービスを利用しないという罪悪
- 若手エンジニアを不幸にしないための開発の「べからず」集 テスト編
License
CC BY-SA 3.0
