はじめに
タイトルが中二病ですみません。みなさま、ナマステ。さて、この記事のタイトルを見て、「時代・・・サトウキビ・・・忍者・・・うぅ、頭が」となった人は私と趣味が似ています・・・って話はどうでもいいか。
駆け抜けるシリーズ第二弾です。第一弾はC99からC++14を駆け抜けるC++講座という、超速度で情報が押し寄せる疾走感あふれる記事でしたが、今回はのんびりまったりを目指します。
今回のテーマは関数です。CでもC++でも(他の言語でも)ありますが、Re:ゼロから始める異世界生活じゃない、Re:ゼロから始める関数講座をやっていきます。
ありきたりな世界
まあみなさん、一度はありきたりな世界を標準出力に出力するプログラムを書いたことがあると思います。
#include <stdio.h>
int main(void)
{
puts("arikitari_na_world!");
return 0;
}
#include <iostream>
int main()
{
std::cout << "arikitari_na_world!" << std::endl;
}
復習ですが、CでもC++でもmain関数からプログラムは始まるのでした(freestanding environmentを除く)。
関数の宣言と定義
とりあえず、int型の値を受け取り、2で割った値をint型で返す関数fを考えましょう。
まずプロトタイプ宣言があります
int f(int);
//int f(int n);//どっちでもいい
ここで関数の型がint (int)だとわかります。()の中は仮引数です。
次に定義します
int f(int n)
{
return n / 2;
}
ちなみにヘッダーファイルなど、複数の翻訳単位でincludeされるファイルに宣言と定義を書くときは
static inline int f(int n)
{
return n / 2;
}
staticとC99で導入されたinlineをつけましょう。それを忘れると
$ make
Scanning dependencies of target Main
[ 33%] Building C object CMakeFiles/Main.dir/main.c.obj
[ 66%] Building C object CMakeFiles/Main.dir/b.c.obj
[100%] Linking C executable Main.exe
CMakeFiles/Main.dir/objects.a(b.c.obj):b.c:(.text+0x0): multiple definition of `f'
CMakeFiles/Main.dir/objects.a(main.c.obj):main.c:(.text+0x0): first defined here
collect2.exe: error: ld returned 1 exit status
make[2]: *** [CMakeFiles/Main.dir/build.make:122: Main.exe] エラー 1
make[1]: *** [CMakeFiles/Makefile2:68: CMakeFiles/Main.dir/all] エラー 2
make: *** [Makefile:84: all] エラー 2
multiple definition of `f'と怒られます。staticをつけて内部リンゲージにしましょう。
GCCの-std=gnu89で追加されるinlineがなかった頃の独自拡張のinlineについて語ってはいけない。extern inlineしないと行けないんだぜ
cf.)
関数の呼び出し
static int f(int n){ return n / 2; }
int main(void)
{
f(4);
return 0;
}
例えばこんな例を考えましょう。
関数名のあとに()を書き、その中に実引数を書くことで関数を呼び出せるのでした。
関数の戻り値を無視するとは
まあ余談ですが。
#include <stdio.h>
static int f(int n){ return n / 2; }
static int g(int n)
{
return f(n);//関数fの戻り値を利用している
}
int main(void)
{
int a = f(7);//関数fの戻り値を使って変数aを初期化している
a = g(2);//関数gの戻り値を変数aに代入している
f(4);//関数fの戻り値を無視している
printf("%d, %d", f(2), a);//関数fの戻り値をprintf関数の第2引数に渡している
return 0;
}
関数fや関数gは定義から明らかなように戻り値を返しますが、関数の呼び出し側で利用しないことももちろんできます。
なおC++17では、nodiscard attributeというものが導入されまして
[[nodiscard]] int fn() { return 2; }
int main() {
fn(); // warning
}
戻り値を無視するとコンパイラに怒られるようにできるようになりました。ライブラリ側が、エラー処理の関係などで戻り値を無視してほしくない時に使います。
cf.) 久々なのでC++17の情報を集めてみる
関数の型とは何かを関数の呼び出し機構を見ながら
先ほど
ここで関数の型が
int (int)だとわかります。
とあっさり書きましたが、関数の型とはなんでしょうか?
その前に変数の型を考えましょう。
int main(void)
{
int n;
}
この記事の読者なら、変数nの型がint型だとすぐに分かるはずです。
型の役割は、語弊を恐れずに言えば、メモリー上にどのようにデータを配置するかです。
この場合は自動変数領域にint型ひとつ分のメモリーを確保し、そこにnという名前をつけたわけです。
では関数の型はどうかを見ていきましょう。
で、普通自動変数領域はスタックというデータ構造を使うので、(規格書にはそんなことは書いていないけど)以下その仮定で話を進めます。
static int f(int n){ return n / 2; }
int main(void)
{
f(4);
return 0;
}
もう一度確認すると関数fの型はint(int)型です。main関数内でf(4)とありますが、これはまずf()から関数呼び出しだとわかり、4とあるので引数は一つで型はint型です。
なのでstatic int f(int n){ return n / 2; }が見つかります。
さて関数を呼び出しましょう。もっと実際には複雑ですがそれは後述するとします。
- 戻り値の型はint型ですからstackに戻り値を書き込むためのint型ひとつ分のメモリーを確保します(x86アーキテクチャだとレジスタを使うらしいです)
- 引数を後ろからスタックに積んでいきます。今回は引数は一つでint型なのでint型ひとつ分のメモリーを確保し、4を代入します
- 関数f内に処理が移ります
-
return n / 2とあるので、n / 2の演算結果を1で確保したメモリー領域に代入します - main関数に処理が戻ります
大事な事があります。関数を呼び出すときは呼び出し元のスタックに戻り値を保存する無名の一時的な変数が作られるということです。
関数の型に含まれる情報
さて、なんとなく関数の方の役割がわかったのではないでしょうか?
関数の型に含まれる情報は
- 戻り値の型
- 引数の個数と型
- 関数呼び出し規約
が含まれていて、関数を呼び出すのに不可欠なものです。
(関数呼び出し規約は後述します)
lvalueとrvalue
左辺値とか右辺値とかいう言葉を聞いたことがあるかもしれませんが忘れましょう。Cではいいんですが、C++をやるときに理解を妨げます。
誤解を恐れずにいえば、lvalueとは、明示的に実体のある、名前付きのオブジェクトであり、rvalueとは、一時的に生成される無名のオブジェクトである。
C++struct X{} ; int f() { return 0 ; } int main() { int i = 0 ; i ; // lvalue 0 ; // rvalue X x ; x ; // lvalue X() ; // rvalue f() ; // rvalue }上記のコードを読めば、lvalueとrvalueの違いが、なんとなく分かってくれる事と思う。lvalueはrvalueに変換できるが、その逆、rvalueをlvalueに変換することは出来ない。
先ほど、関数を呼び出すときは呼び出し元のスタックに戻り値を保存する無名の一時的な変数が作られる、と言いましたが、これはrvalueに分類できますね。
[C++]Referenceとは
参照、と言ったほうが聞いたことがあるかもしれません。Referenceとはすでにある値に対し別名をつける機能です。
で、Referenceですが、大きくわけてlvalue referenceとrvalue referenceがあります。
#include <iostream>
int main()
{
int a = 3;
int& a_r = a;//a_rはaの別名
std::cout << a << ',' << a_r << std::endl;// => 3,3
}
で、この2つにどんな差があるのか、ですが、参照できるものの型を除けばなにも違いはありません。よくrvalue referenceはlvalue referenceと全く異なる、と考えて違いを考えすぎるあまり、わけわかめになる人がいますが、Referenceには違いないのです。
| 種類 | 参照できるもの |
|---|---|
| lvalue reference(T&) | lvalue |
| const lvalue rederence(const T&) | なんでも |
| rvalue reference (T&&) | rvalue |
| const rvalue reference(const T&&) | const rvalue |
struct Test{
int e;
};
const Test make_Test(){ return Test(); }
int main()
{
int a = 0;
const int b = 2;
Test t;
int& a_lr = a;
const int& a_clr = a;//OK
//int& b_lr = b;//NG:暗黙にconstは外せない
const int& b_clr = b;//OK
Test& t_lr = t;//OK
Test&& t_rr = Test();//OK
const Test& t_clr = Test();//OK
const Test&& t_crr = make_Test();//OK
const Test& t_clr = make_Test();//OK
return 0;
}
という感じで、const lvalue referenceが無双というか最強なので、rvalue referenceはあまり出番がありません。
もちろん関数の引数にも使えますし、戻り値にも使えます
#include <iostream>
int& f(int& n)
{
++n;
return n;
}
int main()
{
int n = 3;
int n_r = f(n);
std::cout << n << ',' << n_r << std::endl;// => 4,4
}
cf.)
演算子を関数のように解釈してみよう
これをやると純粋なC使いの皆さんから「C++を持ち込むんじゃねー」とまさかりを投げられるのですが、まあやってみましょう。
前置の単項演算子
前置の単項演算子といえば前置のoperator++ですね。
int a = 3;
++a;
前置の単項演算子は引数が一つの関数と考えることができます。
試しにC++のoperator overload風味に書いてみましょう。言うまでもなくコンパイルは通らない擬似コードです。
int& operator++ (int& n)
{
n = n + 1;
return n;
}
第一引数はint&型ですから、nは先の用例で言えば変数aの別名です。n = n + 1によってnが1加算され、その実体であるaも1加算されています。
戻り値の型もint&型ですから、戻り値は変数nの別名つまり変数aの別名です。
今回の場合、この演算子の呼出し場所では++aとしているだけで、戻り値を利用していないので演算子の戻り値を無視していることになります。
後置の単項演算子
後置の単項演算子といえば後置のoperator++か後置のoperator--しかないですね。
int a = 3;
a++;
後置の単項演算子は事実上引数が一つの関数と考えることができます。というのはC++のoperator overloadの文法上、2つ目の引数がありますが、その情報は使わないからです。
これも試しにC++のoperator overload風味に書いてみましょう。念の為に言いますが、コンパイルは通らない擬似コードです。
const int operator++ (int& n, int /*前置のopeartorと区別するためのただのフラグ*/)
{
const int buf = n;
n = n + 1;
return buf;
}
第一引数はint&型ですから、nは先の用例で言えば変数aの別名です。n = n + 1によってnが1加算され、その実体であるaも1加算されています。
戻り値の型はconst int型ですから、戻り値は変数nつまり変数aをコピーしたものです。
今回の場合、この演算子の呼出し場所ではa++としているだけで、戻り値を利用していないので演算子の戻り値を無視していることになります。
二項演算子
二項演算子といえばoperator+=でしょうか。
int a = 3;
a += 2;
演算子の左辺が第一引数、右辺が第二引数になります。
これも試しにC++のoperator overload風味に書いてみましょう。念の為に言いますが、コンパイルは通らない擬似コードです。
int& operator+= (int& l, int r)
{
l = l + r;
return l;
}
第一引数はint&型ですから、nは先の用例で言えば変数aの別名です。n = n + 1によってnが1加算され、その実体であるaも1加算されています。
戻り値の型もint&型ですから、戻り値は変数lの別名つまり変数aの別名です。
今回の場合、この演算子の呼出し場所ではa++としているだけで、戻り値を利用していないので演算子の戻り値を無視していることになります。
前置/後置のoperator++/operator--
どんな入門書にも載っている話ですが、operator++/operator--が前置と後置で挙動が変わる時があります。
結論から言うと、挙動が変わるのは演算子の戻り値を無視しなかった場合です
@Iruyan_Zak 氏提供のコードを見てみましょう。
#include<stdio.h>
int main(void){
int i;
int a = 10;
for(i=0; i<10; ++i){
printf("%d ", a++);
}
// => 10 11 12 13 14 15 16 17 18 19
printf("\na = %d\n", a);// => a = 20
a = 10;
for(i=0; i<10; ++i){
printf("%d ", ++a);
}
// => 11 12 13 14 15 16 17 18 19 20
printf("\na = %d\n", a);// => a = 20
a = 10;
for(i=0; i<10; i++){
printf("%d ", a++);
}
// => 10 11 12 13 14 15 16 17 18 19
printf("\na = %d\n", a);// => a = 20
a = 10;
for(i=0; i<10; i++){
printf("%d ", ++a);
}
// => 11 12 13 14 15 16 17 18 19 20
printf("\na = %d\n", a);// => a = 20
return 0;
}
for文のインクリメントを前置(1つ目と2つ目のfor文)後置(3つ目と4つ目のfor文)の2パターンありますが、出力結果が変わっていないことからもわかるように差は出ません。これは演算子の戻り値を利用していないからです。
一方、1・3つ目のfor文と2・4つ目のfor文では出力結果が違います。この時演算子の戻り値をprintf関数の第2引数に渡しています。
//前置
int& operator++ (int& n)
{
n = n + 1;
return n;
}
//後置
const int operator++ (int& n, int /*前置のopeartorと区別するためのただのフラグ*/)
{
const int buf = n;
n = n + 1;
return buf;
}
このため挙動が変わりました。
関数ポインタを学ぶためにポインタを復習する
ポインタがなんとなくわかっている前提で以下話が進みます。
C言語のポインタといえば
int* p1, p2;//p2の型はint型!
に代表されるように変態的な文法を持ち初見殺しで有名です。
#define __STDC_FORMAT_MACROS
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <inttypes.h>
int main(void)
{
int n = 3;
int* n_p = &n;
++n_p[0];
printf("%d, %d\n", n, *n_p);// => 4, 4
static const size_t size = 10;
uint64_t* p = calloc(size, sizeof(uint64_t));
p[0] = 4u;
for(size_t i = 1; i < size; ++i){
p[i] = p[i - 1] * p[i - 1] / i;
}
for(size_t i = 0; i < size; ++i) printf("%"PRIu64",", p[i]);
// => 4,16,128,5461,7455630,11117283739380,131881619452552216,1047648503559532041,2037216899616901002,953656708591683993,
putchar('\n');
free(p);
return 0;
}
callocの戻り値をなんでキャストしてないんだ?と思う人はあなたの脳内コンパイラがC89で止まっています。C99からvoid*型は他のポインタ型に暗黙変換されるようになりました。言うまでもなくC++では許容されません。
上の例では、ポインタ変数n_pは変数nを指し示しています。
ポインタ変数pはcalloc関数によって確保されたメモリー領域の先頭を指し示しています。
型を考えてみます。
ポインタ変数n_pの型はint*型です。int型のメモリー領域を指しているのだから当たり前ですね。基本型がintでそこから派生するからint*になります。
ポインタ変数pの型はuint64_t*型です。基本型がuint64_tでそこから派生するからuint64_t*になります。
ポインタは常に基本型から派生してできるわけですね。
ポインタの型はポインタ演算をするのに必要になります。御存知の通り、p[i]は*(p + i)と等価ですが、p + iをするために必要な情報は何でしょうか?
今回の場合、callocで確保したメモリー領域をsizeof(uint64_t)ずつに区切って認識します。なので例えばp + 1はpが指す場所からsizeof(uint64_t)バイトずらした場所を返します。
つまり、ポインタ演算をするためのメモリー領域の区切り単位を知るために型が必要なわけです。
よく箱が連なった絵で説明されますが、あの箱の大きさを決めるわけですね。
改めまして関数について
前にざっくりと説明しましたが、もうすこし説明します。
関数とは、処理の集合です。C/C++では、すべてのプログラムは必ず1つ以上の関数が含まれています。
これまで見てきたmain関数も関数の一つです。C言語においてとにかく大事なものです。そのくせ独習Cの説明は十分とは言えません、あれで説明してるつもりなんですかね。
関数の一般的な書き方は
戻り値の型 (関数呼び出し規約opt) 関数名(仮引数リスト){
//処理
}
です。戻り値の型がvoid以外の時は、必ず戻り値を返さなければなりません。
//これは誤り
int do_something(void){
//do something
}
//これは正しい
int do_something2(void){
//do something
return 0;
}
関数の呼び出し規約は省略することが多いですが(その場合__cdeclになる)、Win32APIを使うならお世話になるだろし、C++のクラスのメンバー関数は呼び出し規約が更に異なります。
詳しくはx86アセンブリ言語での関数コールを参照してみてください。
#include <stdio.h>
double calc_volume(double si, double s2, double s3);
int main(void){
const double vertical = 15.5;//縦
const double horizontal = 7.2;//横
const double height = 2.0;//高さ
const double result = calc_volume(vertical, horizontal, height);
printf("体積は%fです", result);
return 0;
}
double calc_volume(const double s1, const double s2, const double s3){
return s1 * s2 * s3;
}
このコードを例に、関数の呼びだし前後のスタックの様子について解説します。もちろんスタックなんて言葉はC規格書に出てきませんが、抽象的な話ばかりしても仕方ないので。
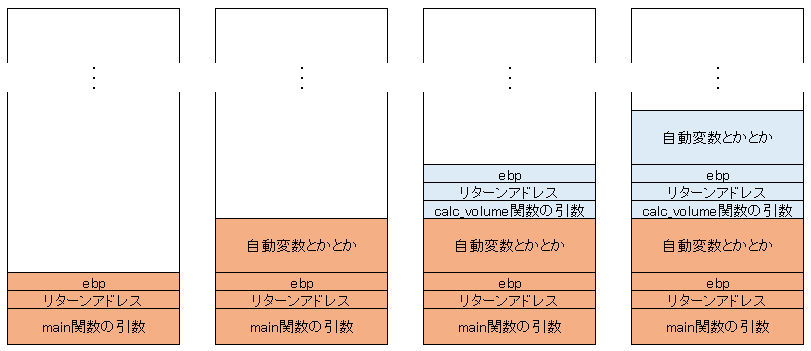
関数呼び出しは関数呼び出し規約にもよりますが、C/C++で一般的な__cdeclやC++のクラスメンバー関数で使われる__thiscallやWin32APIでよく見る__stdcallでは
- main関数が呼ばれるとき、スタック領域を確保する
- 引数を後ろから順に書き込む
- 復帰情報(リターンアドレスなど)を書き込む
- 関数の処理が始まって、変数が確保されたりする
のように処理が行われます。
さて、リターンアドレスとは何でしょうか。
関数だってメモリー上にあるんだからポインタもあるでしょ
さて、そもそもどうやってプログラムは実行されるのかというお話があります。
コンピュータが出た当初は、回路を組み替えて動作を変えていました。ハードウェアでプログラミングするんですね。
その後、幾つかの基本的な命令の並び順で動作を変えるという現代よく見るものが出てきました。この時この命令の順序はメモリーからloadするようになりました。
つまりですね、プログラムの実体はメモリー上にあるわけです。メモリー上にあるんだから、普通の変数と何ら変わることなくポインタを取れます。

これは一般的な処理系のメモリーの様子を表したものです。メモリーの様子といっても「プログラムから見える」メモリーです。実際にはOSとCPUが連携してL1~L3キャッシュ、RAM、ページファイルに分散しています。
#include <stdio.h>
#include <stdlib.h>
typedef struct {
char name[20];
int age;
} Animal;
static Animal a1 = { { 0 }, 0 };
Animal a2 = { { 0 }, 0 };
static const int b = 33;
int main(void){
Animal a3 = { { 0 }, 0 };
int a = 32;
Animal* a4 = malloc(1 * sizeof(Animal));
printf("a1:%p, a2:%p, a3:%p, a4:%p, a:%p, b:%p\n",
(void*)&a1, (void*)&a2, (void*)&a3, (void*)a4, (void*)&a, (void*)&b
);
free(a4);
printf("puts:%p\n", puts);
return 0;
}
a1:0x601068, a2:0x601050, a3:0x7ffce6a823e0, a4:0x7ff010, a:0x7ffce6a823dc, b:0x400860
puts:0x400530
関数ポインタのvoid*へのキャストはエラーになる環境もあるかもしれません(言語仕様上は関数ポインタはvoid*よりも大きい幅である可能性がある)。
関数ポインタが指し示すのはプログラムの実体があるメモリー領域です。
ここで抑えておかないといけないことがあります。
関数、つまりその処理の手順ももちろんメモリー上にあるのですが、処理過程でつかう変数とは明確にべつの領域にあります。
もう一度言います、コードとデータは別です。
ここで思い出して欲しいのがこの図です。
関数を呼ぶときは、引数、returnアドレス、ebpがスタックに積まれ、そのあと関数が実行され適宜関数内の自動変数がスタックに積まれるのでした。
returnアドレスとは他でもなくコード領域へのポインタです。もう少し言うと関数を呼び出し実行が終わったあと実行する命令があるコード領域のアドレスです。
cf.)
関数ポインタ
極めて変態的な文法の理解が必要な関数ポインタですが、C++11の力を借りればいくらかわかりやすくなります。
まず関数ポインタは関数型から派生してできるので当然関数ポインタにも型があります。
C標準関数であるputs関数を見てみましょう。
puts関数のプロトタイプ宣言は
int puts ( const char * str );
です。型はint(const char*)ですね。さてそれへのポインタ型なのでint(*)(const char*)になります。int*(const char*)ではないですよ?それはconst char*を受け取りint*を返す関数型ですからね。では利便性のためにtypedefしましょう
typedef int(*puts_t)(const char*);
まるでわからん。
using puts_t = int(*)(const char*);
わかりやすい。
#include <stdio.h>
//int puts ( const char * str );//型はint(const char*)
typedef int(*puts_t1)(const char*);
using puts_t2 = int(*)(const char*);//C++11:alias declaration
int main(){
int (*f1)(const char*) = puts;
puts_t1 f2 = puts;
puts_t2 f3 = puts;
f1("f1");
f2("f2");
f3("f3");
return 0;
}
あなたはこの型を答えられるか
さて、なんとなくわかってきたところで、ちょっとクイズをしましょう。
第一問
第1引数が
void*型、第2引数がbool型でvoid*型を返す呼び出し規約が__stdcallの関数へのポインタ型
C++11のalias declarationで答えを書くと
using f = void* (__stdcall *) (void*, bool);
となります。ちなみにtypedefで書くと
typedef void* (__stdcall * f) (void*, bool);
うーむ。
第二問
第1引数が
const char*型、第2引数がsize_t型、第3引数が、第一引数char型、第2引数にsize_t型を受け取りbool型を返す関数へのポインタ型で、const char*型を返す関数へのポインタ型の要素数3の配列の要素数2の配列型
C++11のalias declarationを使いながらちょっと解釈していきましょう。
まず、
第一引数
char型、第2引数にsize_t型を受け取りbool型を返す関数へのポインタ型
は
using f1 = bool (*)(char, size_t);
こうですね。次に
第1引数が
const char*型、第2引数がsize_t型、第3引数が、第一引数char型、第2引数にsize_t型を受け取りbool型を返す関数へのポインタ型で、const char*型を返す関数へのポインタ型
は
using f1 = bool (*)(char, size_t);
using f2 = const char* (*)(const char*, size_t, f1);
ですね。最後に
第1引数が
const char*型、第2引数がsize_t型、第3引数が、第一引数char型、第2引数にsize_t型を受け取りbool型を返す関数へのポインタ型で、const char*型を返す関数へのポインタ型の要素数3の配列の要素数2の配列型
は
using f1 = bool (*)(char, size_t);
using f2 = const char* (*)(const char*, size_t, f1);
using a1 = f2[3][2];
ですね。さて、alias declarationを使わないで表せそうですか?
答えは
const char* (*[3][2])(const char*, size_t, bool (*)(char, size_t))
でした。まあそこまで難しくはないですね。
第三問
より。
int を引数に取り、char を返す関数へのポインタ型の要素3の配列型へのポインタ型
C++11のalias declarationを使いながらちょっと解釈していきましょう。
まず
int を引数に取り、char を返す関数へのポインタ型
は
using f = char (*)(int);
ですね。次に
int を引数に取り、char を返す関数へのポインタ型の要素3の配列型
は
using f = char (*)(int);
using a = f[3];
ですね。最後に
int を引数に取り、char を返す関数へのポインタ型の要素3の配列型へのポインタ型
は
using f = char (*)(int);
using a = f[3];
using r = a*;
ですね。さて、alias declarationを使わないで表せそうですか?
答えは
char(*(*)[3])(int)
でした。えげつねぇ。
Clockwise/Spiral Ruleで型を読む
"Clockwise/Spiral Rule''を使ってC言語の「例の宣言」に挑む
という記事で詳しく解説されています。これを使えば
void (*(*f[])())();
のような宣言も読み解けますね!
[C++]3つ(実は2つ)ある関数の仲間
関数の引数に関数を渡したいということはままあるわけですが、Cではそういう時関数ポインタを使いました。qsort関数が有名ではないでしょうか。
C++においては選択肢が3つになります
- 関数ポインタ
- 関数オブジェクト(function-like class)
- lambda
実はlambdaは関数オブジェクトとほぼ同じだったりするんですが一応分けておきます。
[C++]関数オブジェクトとは
ご存知の通りC++にはクラスがあり、またoperator overlaodがあるわけですが、こんなクラスを考えてみましょう
struct F{
int operator()()
{
return 3;
}
};
これは
#include <iostream>
struct F{
int operator()()
{
return 3;
}
};
int main()
{
F f;
auto r = f();// int型
std::cout << r << ',' << F{}() << std::endl;// => 3,3
}
のように使用します。
上で
関数名のあとに
()を書き、その中に実引数を書くことで関数を呼び出せるのでした。
と書きましたが、opoerator()はこれを実現できるものです。おなじ書き方でopoerator()を呼ぶことができるので関数オブジェクトないし、function-like classと呼ばれます。
#include <utility>
#include <iostream>
#include <numeric>
#include <string>
#include <stdexcept>
#include <cstdint>
struct accumulate_impl{
std::pair<int, int> operator()(const std::pair<int, int>& s, const char& e)
{
return {s.first + (e - '0') * ((5 < s.second) ? s.second - 4 : s.second + 2), s.second + 1};
}
};
std::uint8_t calc_check_digit(const std::string& n) noexcept(false) {
if (11 != n.size()) throw std::runtime_error("n.digit must be 11");
for(auto e : n) if(e < '0' || '9' < e) { throw std::runtime_error("in function calc_check_digit_yumetodo : iregal charactor detect.(" + n + ')'); }
const std::uint8_t r = std::accumulate(n.rbegin(), n.rend(), std::pair<int, int>{}, accumulate_impl()).first % 11;
return (0 == r || 1 == r) ? 0 : 11 - r;
}
int main()
{
std::cout << static_cast<int>(calc_check_digit("12345678901")) << std::endl;// => 8
}
[C++11]lambda式
他の言語でも最近lambda式と言われるものを導入するのが流行りらしいですが、C++におけるlambda式とは、先ほど紹介した関数オブジェクトを自動生成させるシンタックスシュガーです。
#include <utility>
#include <iostream>
#include <numeric>
#include <string>
#include <stdexcept>
#include <cstdint>
std::uint8_t calc_check_digit(const std::string& n) noexcept(false) {
if (11 != n.size()) throw std::runtime_error("n.digit must be 11");
for(auto e : n) if(e < '0' || '9' < e) { throw std::runtime_error("in function calc_check_digit_yumetodo : iregal charactor detect.(" + n + ')'); }
const std::uint8_t r = std::accumulate(n.rbegin(), n.rend(), std::pair<int, int>{}, [](const std::pair<int, int>& s, const char& e) -> std::pair<int, int> {
return {s.first + (e - '0') * ((5 < s.second) ? s.second - 4 : s.second + 2), s.second + 1};
}).first % 11;
return (0 == r || 1 == r) ? 0 : 11 - r;
}
int main()
{
std::cout << static_cast<int>(calc_check_digit("12345678901")) << std::endl;// => 8
}
#include <utility>
#include <iostream>
#include <numeric>
#include <string>
#include <stdexcept>
#include <cstdint>
std::uint8_t calc_check_digit(const std::string& n) noexcept(false) {
if (11 != n.size()) throw std::runtime_error("n.digit must be 11");
for(auto e : n) if(e < '0' || '9' < e) { throw std::runtime_error("in function calc_check_digit_yumetodo : iregal charactor detect.(" + n + ')'); }
const std::uint8_t r = std::accumulate(n.rbegin(), n.rend(), std::pair<int, int>{}, [](const auto& s, const char& e) -> std::pair<int, int> {
return {s.first + (e - '0') * ((5 < s.second) ? s.second - 4 : s.second + 2), s.second + 1};
}).first % 11;
return (0 == r || 1 == r) ? 0 : 11 - r;
}
int main()
{
std::cout << static_cast<int>(calc_check_digit("12345678901")) << std::endl;// => 8
}
std::accumulateの第4引数に渡しているのがlambdaです。関数オブジェクトの処理内容を別の場所に書く必要がなくなるため、処理の流れの一覧性があがり、可読性が向上します。
その詳細は、C++界隈では有名な江添さんががっつり記事を書いているので
- lambda 完全解説 | 本の虫
- シンタックスシュガーとしてのlambdaの解説 | 本の虫
- C++14の新機能: ジェネリックlambda | 本の虫
- C++14の新機能: 初期化lambdaキャプチャー | 本の虫
を全部読んでいただくとして、簡単に触れます。
lambdaの文法解説
では、詳しい解説をして行きたいと思う。int main() { [] // [ lambda-capture ] () // ( parameter-declaration-clause ) {} // compound-statement () // Function call expression ; }まず、一番始めの[]は、lambda-introducerという。[]のなかには、lambda-captureを記述できる。これについては、後に解説する。
二番目は、関数の引数の定義である。通常の関数で、void f(int a, int b) などと書く引数と、まったく同じである。
三番目は、関数の本体である。通常の関数と同じく、実際のコードはこの中に書く。
四番目は、関数呼び出しである。これも、通常の関数とまったく変わらない。
先程も言ったようにlambdaは関数オブジェクトを自動生成させるシンタックスシュガーに過ぎないので、lambda式が書かれているスコープで有効な自動変数はそのままではlambda式内では使えません。逆に言えば関数の外で有効な変数、例えば関数の外で宣言・定義されているstatic変数とかは使えるわけですが。
で、lambda式が書かれているスコープで有効な自動変数をlambda式内で使うためには、lambda-captureというものを使います。
#include <iostream>
//struct F1{ int operator()(){ return a; } };//error:aは未定義
class F1_copy{
private:
int a;
public:
F1_copy() = delete;
F1_copy(int copy) : a(copy) {}
F1_copy(const F1_copy&) = default;
F1_copy(F1_copy&&) = default;
F1_copy& operator=(const F1_copy&) = delete;
F1_copy& operator=(F1_copy&&) = delete;
int operator()(){ return a; }
};
class F1_ref{
private:
int& a;
public:
F1_ref() = delete;
F1_ref(int& ref) : a(ref) {}
F1_ref(const F1_ref&) = default;
F1_ref(F1_ref&&) = default;
F1_ref& operator=(const F1_ref&) = delete;
F1_ref& operator=(F1_ref&&) = delete;
int operator()(){ return a; }
};
static int b = 2;
struct F2{ int operator()(){ return b; } };//OK
int main()
{
int a = 3;
int c = 4;
//int r1_1 = F1{}();//error
//int r1_2 = [](){ return a; }();//error:aは未定義
int r2_1 = F1_copy{ a }();//OK
int r2_2 = [a](){ return a; }();//OK:copy caputure
int r3_1 = F1_ref{ a }();//OK
int r3_2 = [&a](){ return a; }();//OK:reference caputure
int r4 = [=](){ return a; }();//OK:自動変数のうち、odr-usedになったもの全てがcopy caputureされる
int r5 = [&](){ return a; }();//OK:自動変数のうち、odr-usedになったもの全てがreference caputureされる
int r6_1 = [](){ return b; }();//OK:captureは不要
int r6_2 = F2{}();//OK
using std::endl;
std::cout
<< "a:" << a << endl// => 3
<< "b:" << b << endl// => 3
<< "c:" << c << endl// => 4
<< "r2_1:" << r2_1 << endl// => 3
<< "r2_2:" << r2_2 << endl// => 3
<< "r3_1:" << r3_1 << endl// => 3
<< "r3_2:" << r3_2 << endl// => 3
<< "r4 :" << r4 << endl// => 3
<< "r5 :" << r5 << endl// => 3
<< "r6_1:" << r6_1 << endl// => 2
<< "r6_2:" << r6_2 << endl;// => 2
}
lambda-captureにはよく使うものとして参照キャプチャとコピーキャプチャがありますが、上の例で違いはわかっていただけるかなと思います。
[=]や[&]は自動変数のうち、odr-usedになったもの全てを対象とするキャプチャですが、そもそもodr-usedの説明が面倒な上に、個人的にlamdaでキャプチャしている自動変数は明示したほうが可読性が上がると思っているので、私は一個一個lambda-captureに書くようにしています。
odr-usedについては
リンク時に関連するルールの話 - ここは匣
を見てください。
[C++]なぜC++erは関数ポインタではなく関数オブジェクトを使うか
結論から言うと関数ポインタは重いからです。
関数ポインタは関数の命令開始位置のアドレスを保持するものでしたが、このアドレスは実行時にしかわかりません。コンパイル時にどの関数を使うか見抜き、関数をinline展開する最適化をするのは、極めて難易度が高く、現存する殆どのコンパイラはほとんどの関数ポインタをinline展開しません。
これに対して関数オブジェクトは一つ一つが別のクラスです。lambdaの場合も一つ一つすべて固有の名前のクラスになります。なのでその関数オブジェクトかの区別は型レベルでわかるので、コンパイル時にわかります。つまりコンパイラは関数オブジェクトをinline展開しやすくなります。
前にも見たように関数を呼び出すというのはいろいろな手順を経て呼び出されるので時間がかかります。inline展開するかはコンパイラが実行速度と実行ファイルの大きさのトレードオフで決定しますが、inline展開されれば一般にその分高速化できます。
故にC++erは関数ポインタより関数オブジェクトを好むわけです。
[C++]std::functionはなぜあまり使われないか
C++で関数といえば
- 関数ポインタ
- 関数オブジェクト(function-like class)
- lambda
の3つ(実は2つ)あると話しましたが、これを統一的に扱いたいことがあります。そこで登場するのがstd::functionです。
使い方はただでさえ長いこの記事をこれ以上肥大化させても仕方ないので
function - cpprefjp C++日本語リファレンス
関数ポインタよりもstd::functionを使おう - ぷろみん
にまるなげします。
で、こいつ重いです。
C++11 autoはstd::functionより高速 – Hossy
なぜかというと、統一的に扱うために内部でキャストを多用して型消去しているからです。
Boost.Functionの実装技術(1) - Type Erasure - Faith and Brave - C++で遊ぼう
Boost.Functionの実装技術(2) - タグディスパッチ - Faith and Brave - C++で遊ぼう
に実装例が出ていますが、なんかすごいですね(小並感)。
前節で解説したとおり、関数オブジェクトは型レベルで関数を区別していたのでコンパイル時にどの関数かわかりコンパイラはinline展開しやすかったので高速化に繋がるのでした。
型消去してしまってはその利点は消え去ってしまいます。
で、そんなstd::functionですが、出番が無いかというとそんなことはなく、例えば関数の配列を作るようなときは、まあstd::tupleでもしかしたら頑張れるのかもしれませんが、こいつを使うほうがはるかに楽に可読性も高く実装できます。
[C++11]constexpr関数は市民の義務です
というタイトルで書こうと思ったんですが、constexpr関数の解説なんて私にできるわけもない。
解説には岡山の陶芸家(中3女子)が必要やろ!
というわけで参考リンクだけ貼っておきます
- constexpr - cpprefjp C++日本語リファレンス
- constexprの制限緩和 - cpprefjp C++日本語リファレンス
- constexpr関数はコンパイル時処理。これはいい。実行時が霞んで見える。cpuの嬌声が聞こえてきそうだ
- 本の虫: 最新のconstexpr
- リテラル型クラスの条件、および「中3女子でもわかる constexpr」の訂正 - ボレロ村上 - ENiyGmaA Code
- C++11の糞仕様と戦ってアクセッサをconstexprにする - ボレロ村上 - ENiyGmaA Code
- コンパイル時Brainfuckコンパイラ ――C++14 constexpr の進歩と限界―― - ボレロ村上 - ENiyGmaA Code
終わりに
はじめはC言語初心者向けに記事を書いていたのだが、そもそも関数は初心者向けの機能ではなかったことを思い出し、初心者向けに書くのを諦めた。
結果どういうわけかすごく長い記事になった。
ここでこの記事の冒頭を見よう
今回はのんびりまったりを目指します。
無理でした。途中まではまったり書いていたけど途中から指数関数的に疾走する記事になりました。
この記事を書くきっかけをくれたリーマ氏といるやん氏に感謝しつつこの記事を終わることにする。
反響
引数の後ろからスタックに積んでいくあたりでマサカリに手が伸びたが、標準でレジスタ渡しな環境がーとか言ってると収集付かなくなるのは分かってるのでそっと戻し。
— yoh2 (@yoh2_sdj) 2016年9月10日
うん、まあね、抽象的なことばっか言っても始まらんしね。
深淵までって書いてあるからHaskellとかScalaとかElixirとかに話が飛ぶかと思ったけどC++までだった https://t.co/s4S3PyFBb4
— 白山風露 (@kazatsuyu) 2016年9月10日
Haskellについては
自称C++中級者がHaskell初心者になってみる話
へどうぞ