**自然言語処理に前処理は不可欠です。**テキストは文字の羅列であり構造化されていないため、そのままでは処理するのが難しいです。特にWebテキストの中には HTMLタグ や JavaScript のコードといったノイズが含まれています。このようなノイズは前処理して取り除かなければ期待する結果は得られないでしょう。
 出典: [Deep learning for computational biology](http://msb.embopress.org/content/12/7/878)
出典: [Deep learning for computational biology](http://msb.embopress.org/content/12/7/878)
本記事では自然言語処理における前処理の種類とその威力について説明します。説明順序としては、はじめに前処理の種類を説明します。各前処理については、1.どんな処理なのか、2.なぜその処理をするのか、3.実装方法(なるべく) という観点から説明します。種類について説明した後、前処理の威力を測るために前処理をした場合としなかった場合での文書分類の結果を比較します。
前処理の種類と実装
この節では以下に示す5つの前処理について説明します。5つの前処理について、1.どんな処理なのか、2.なぜその処理をするのか、3.実装方法という観点から説明します。

テキストのクリーニング
テキストのクリーニングでは、テキスト内に含まれるノイズを除去します。よくあるノイズとして、JavaScriptのコードやHTMLタグが挙げられます。これらのノイズを除去することで、ノイズがタスクの結果に及ぼす悪影響を抑えることができます。以下のようなイメージです:
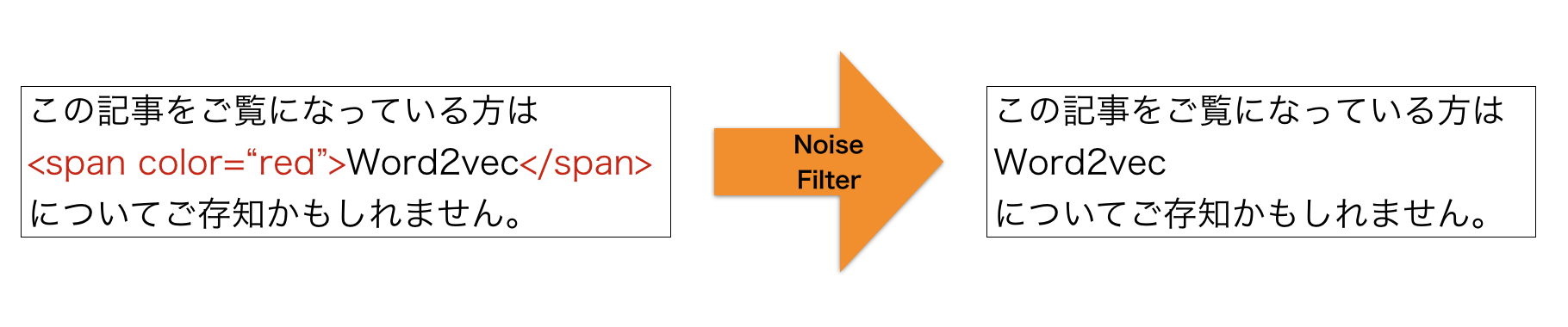
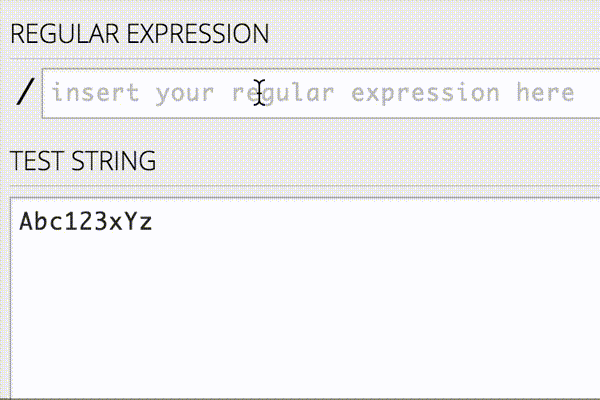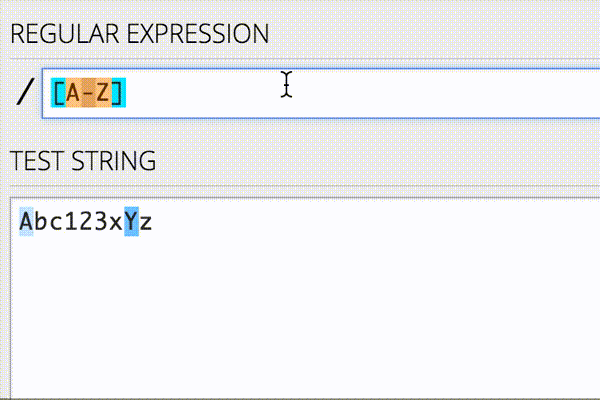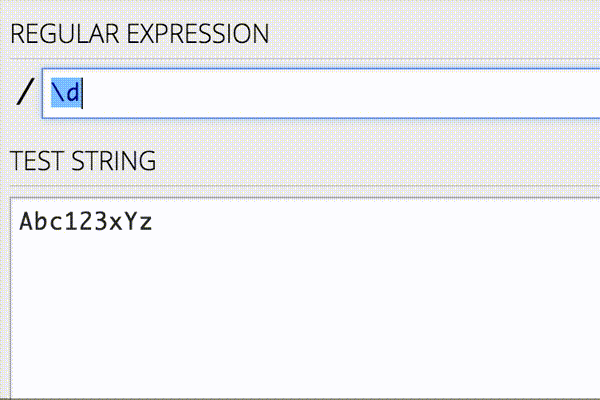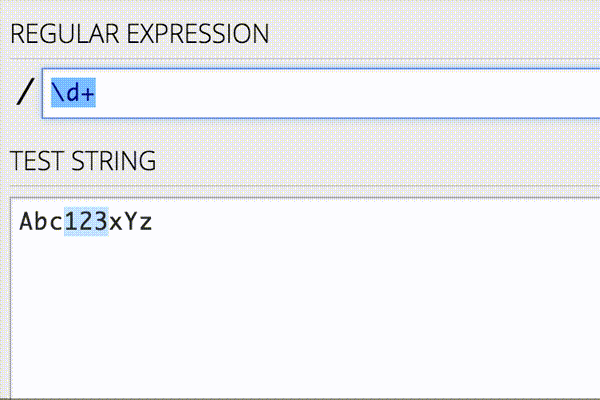
JavaScriptやHTMLタグの除去はよく行われるのですが、実際にはデータに応じて除去したいノイズは変わります。そのような場合に使える手として正規表現があります。正規表現を書く際には以下のようなオンラインエディタを使ってリアルタイムにパターンマッチを確認しながら行うと、作業が捗ります。
Pythonには Beautiful Soup や lxml のようなクリーニングを行うのに便利なライブラリがあります。
BeautifulSoupを用いたテキストのクリーニング例はこちら:
preprocessings/ja/cleaning.py
単語の分割
日本語のように単語の区切りが明らかでない言語に対してまず行われるのが単語の分割処理です。単語を分割する理由として、ほとんどの自然言語処理システムでは入力を単語レベルで扱うことが挙げられます。分割は主に形態素解析器を用いて行います。主な形態素解析器として MeCab や Juman++、 Janome が挙げられます。
イメージとしては以下のように分割します。この際、語彙数を減らすために単語を原形にすることもあります:
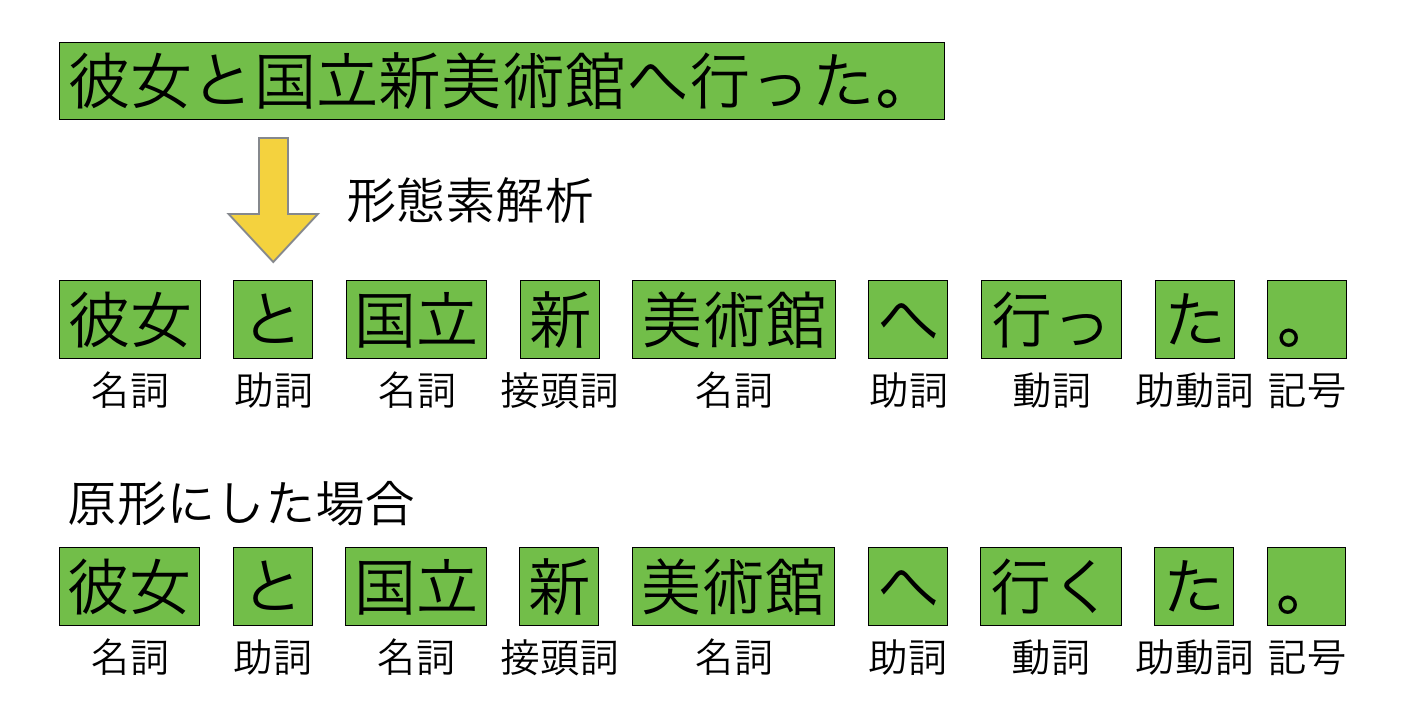
形態素解析する際に問題となるのがデフォルトでは新語の解析に強くない点です。上の例を見ると「国立新美術館」を「国立」「新」「美術館」の3つに分割しています。このような結果になる原因として、解析に使っている辞書に「国立新美術館」が含まれていないことが挙げられます。特にWebには新語が多数含まれているのでこの問題はさらに深刻になります。
この問題は NEologd と呼ばれる辞書を追加することでことである程度解決できます。NEologd には通常の辞書と比べて多くの新語が含まれています。したがって、NEologdを使用することで新語の解析に強くなります。以下は上と同じ文をNEologdを使って解析した結果です:

以上のようにして単語の分割をした後、後続の処理を行なっていきます。以下はPythonによる実装です:
preprocessings/ja/tokenizer.py
単語の正規化
単語の正規化では単語の文字種の統一、つづりや表記揺れの吸収といった単語を置き換える処理をします。この処理を行うことで、全角の「ネコ」と半角の「ネコ」やひらがなの「ねこ」を同じ単語として処理できるようになります。後続の処理における計算量やメモリ使用量の観点から見ても重要な処理です。
単語の正規化には様々な処理がありますが、この記事では以下の3つの処理を紹介します。
- 文字種の統一
- 数字の置き換え
- 辞書を用いた単語の統一
文字種の統一
文字種の統一ではアルファベットの大文字を小文字に変換する、半角文字を全角文字に変換するといった処理を行います。たとえば「Natural」の大文字部分を小文字に変換して「natural」にしたり、「ネコ」を全角に変換して「ネコ」にします。このような処理をすることで、単語を文字種の区別なく同一の単語として扱えるようになります。

数字の置き換え
数字の置き換えではテキスト中に出現する数字を別の記号(たとえば0)に置き換えます。たとえば、あるテキスト中に「2017年1月1日」のような数字が含まれる文字列が出現したとしましょう。数字の置き換えではこの文字列中の数字を「0年0月0日」のように変換してしまいます。
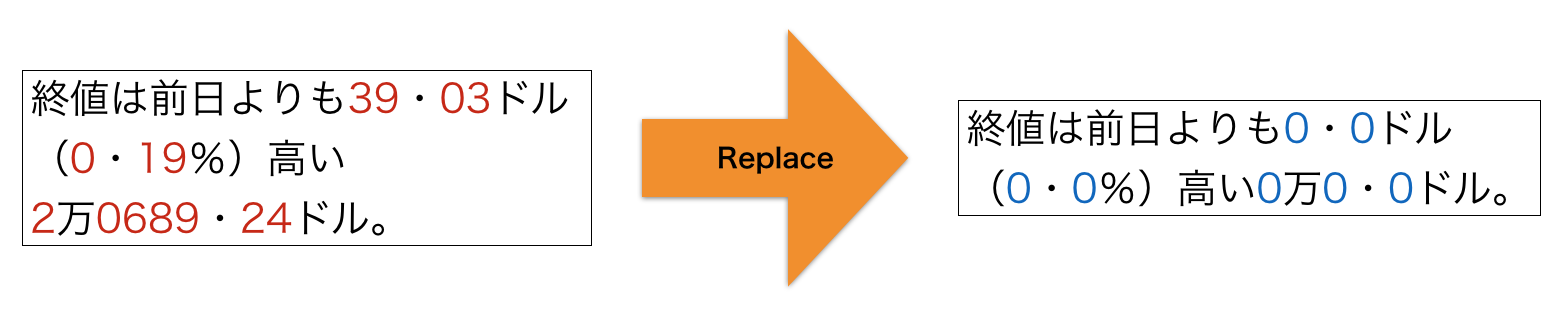
数字の置き換えを行う理由は、数値表現が多様で出現頻度が高い割には自然言語処理のタスクに役に立たないことが多いからです。たとえば、ニュース記事を「スポーツ」や「政治」のようなカテゴリに分類するタスクを考えましょう。この時、記事中には多様な数字表現が出現するでしょうが、カテゴリの分類にはほとんど役に立たないと考えられます。そのため、数字を別の記号に置き換えて語彙数を減らしてしまいます。
そのため、数値表現が重要なタスク(情報抽出とか)では数字の置き換えは行いません。
辞書を用いた単語の統一
辞書を用いた単語の統一では単語を代表的な表現に置き換えます。たとえば、「ソニー」と「Sony」という表記が入り混じった文章を扱う時に「ソニー」を「Sony」に置き換えてしまいます。これにより、これ以降の処理で2つの単語を同じ単語として扱えるようになります。置き換える際には文脈を考慮して置き換える必要があることには注意する必要があります。

単語正規化の世界は奥深くて、以上で説明した正規化以外にもつづりの揺れ吸収(loooooooooooool -> lol)、省略語の処理(4eva -> forever)、口語表現の代表化(っす -> です)といった正規化もあります。データが大量にあれば後述する単語の分散表現である程度対応できる処理もあるとは思いますが、自分の解きたいタスクに必要な処理をするのが一番良いと思います。
以上で説明した単語の正規化の一部を実装しています:
preprocessings/ja/normalization.py
ストップワードの除去
ストップワードというのは自然言語処理する際に一般的で役に立たない等の理由で処理対象外とする単語のことです。たとえば、助詞や助動詞などの機能語(「は」「の」「です」「ます」など)が挙げられます。これらの単語は出現頻度が高い割に役に立たず、計算量や性能に悪影響を及ぼすため除去されます。
ストップワードの除去には様々な方式がありますが、この記事では以下の2つの方式を紹介します。
- 辞書による方式
- 出現頻度による方式
辞書による方式
辞書による方式では、あらかじめストップワードを辞書に定義しておき、辞書内に含まれる単語をテキストから除去します。辞書は自分で作成してもいいのですが、既に定義済みの辞書が存在しています。ここでは日本語のストップワード辞書の一つである Slothlib の中身を見てみましょう。300語ほどの単語が一行ごとに定義されています:
あそこ
あたり
あちら
あっち
あと
あな
あなた
あれ
いくつ
いつ
いま
いや
いろいろ
...
この辞書内に定義された単語をストップワードとして読み込み、使用します。具体的には読み込んだストップワードが単語に分割されたテキスト内に含まれていれば除去してしまいます。以下のようなイメージです:
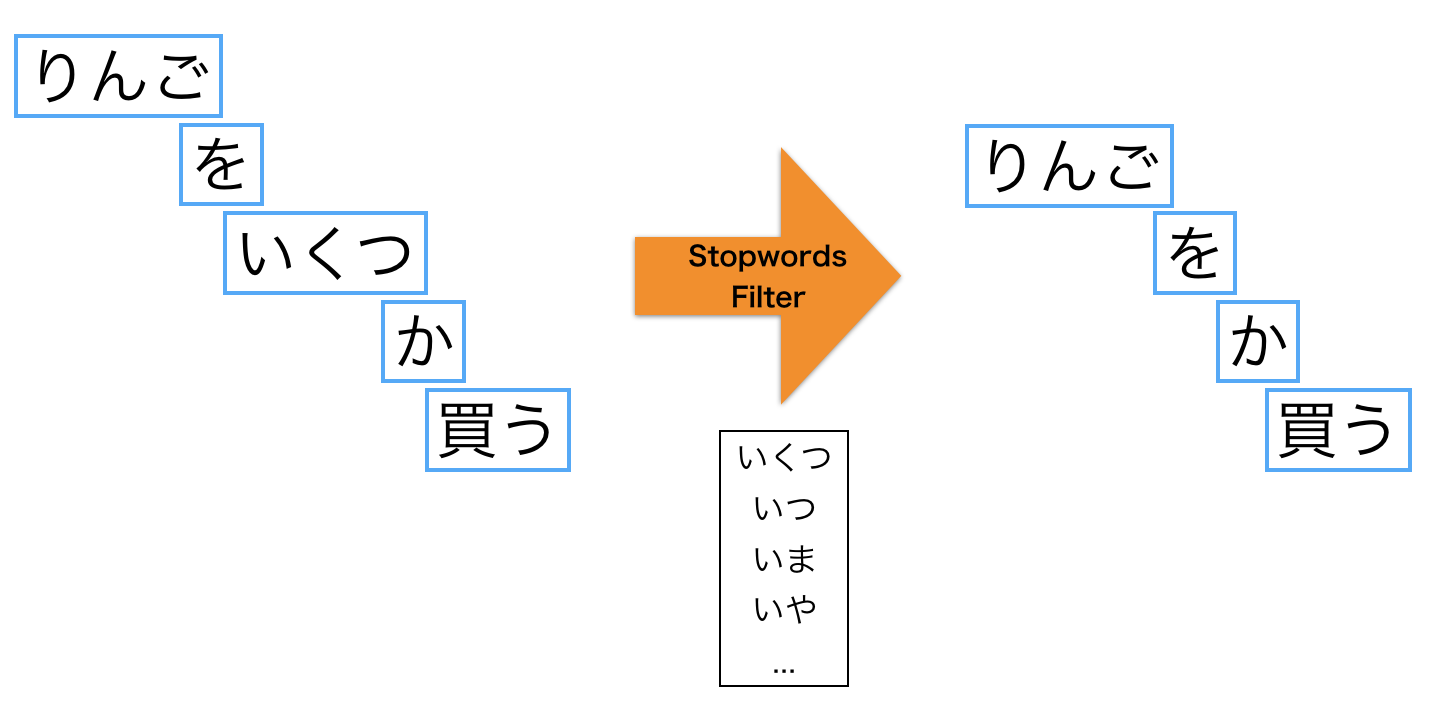
辞書による方法は素朴な方法で簡単ですがいくつか欠点もあります。一つ目は辞書を作るためのコストがかかる点です。もう一つはドメインによっては役に立たない場合がある点です。そのため、自分の対象としているコーパスによって作り変える必要があります。
出現頻度による方式
出現頻度による方式では、テキスト内の単語頻度をカウントし、高頻度(時には低頻度)の単語をテキストから除去します。高頻度の単語を除去するのは、それらの単語がテキスト中で占める割合が高い一方、役に立たないからです。以下の図はある英語の本の最も頻出する50単語の累計頻度をプロットしたものです:
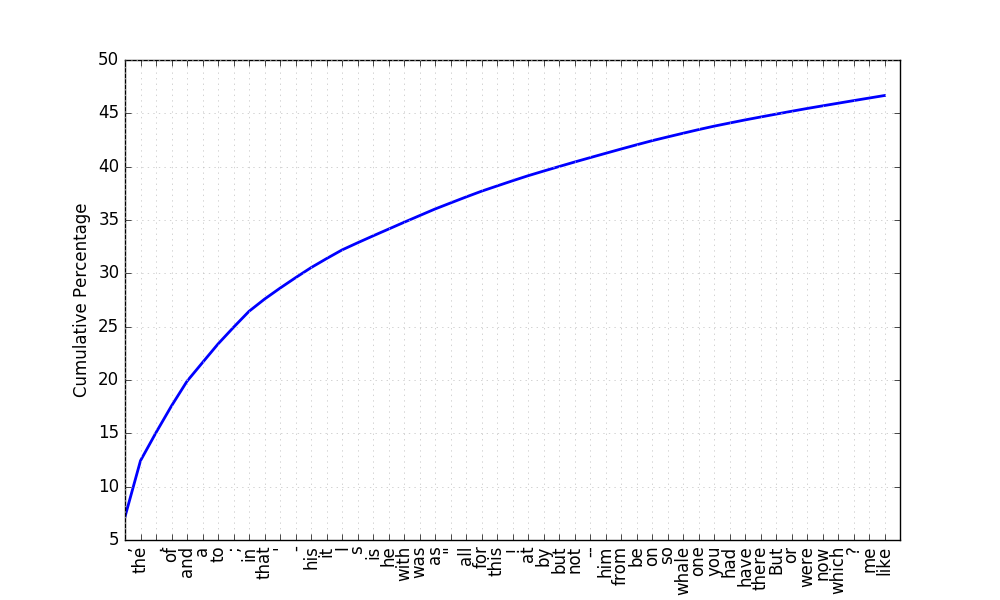
50単語を見てみると、the や of、カンマのような文書分類等に役に立たなさそうな単語がテキストの50%近くを占めていることがわかります。出現頻度による方式ではこれら高頻度語をストップワードとしてテキストから取り除きます。
ストップワードの除去をしている実装はこちら:
preprocessings/ja/stopwords.py
単語のベクトル表現
単語のベクトル表現では、文字列である単語をベクトルに変換する処理を行います。なぜ文字列からベクトルに変換するのかというと、文字列は可変長で扱いにくい、類似度の計算がしにくい等の理由が挙げられます。ベクトル表現するのにも様々な手法が存在するのですが、以下の2つについて紹介します。
- one-hot表現
- 分散表現
One-hot表現
単語をベクトルで表現する方法としてまず考えられるのはone-hot表現です。one-hot表現というのはある要素のみが1でその他の要素が0であるような表現方法のことです。各次元に 1 か 0 を設定することで「その単語か否か」を表します。
たとえば、one-hot表現でpythonという単語を表すとしましょう。ここで、単語の集合であるボキャブラリは(nlp, python, word, ruby, one-hot)の5単語とします。そうすると、pythonを表すベクトルは以下のようになります。
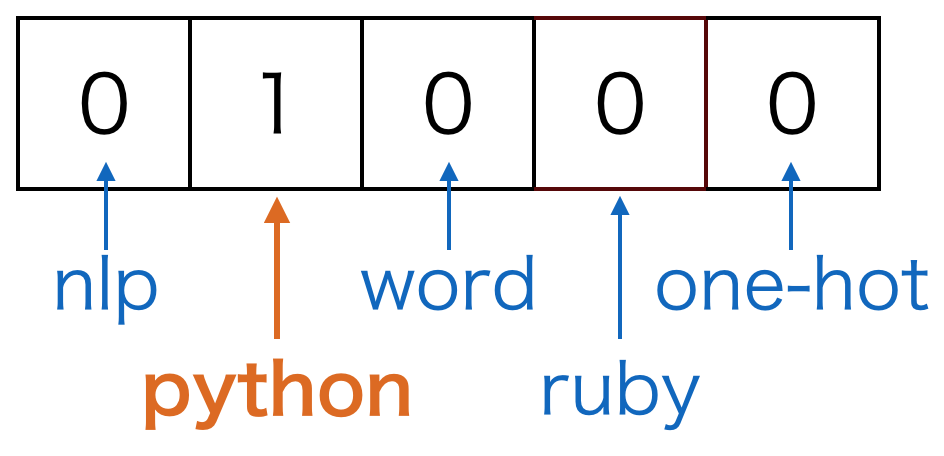
one-hot表現はシンプルですが、ベクトル間の演算で何も意味のある結果を得られないという弱点があります。たとえば、単語間で類似度を計算するために内積を取るとしましょう。one-hot表現では異なる単語は別の箇所に1が立っていてその他の要素は0なので、異なる単語間の内積を取った結果は0になってしまいます。これは望ましい結果とは言えません。また、1単語に1次元を割り当てるので、ボキャブラリ数が増えると非常に高次元になってしまいます。
分散表現
それに対して分散表現は、単語を低次元の実数値ベクトルで表す表現です。だいたい50次元から300次元くらいで表現することが多いです。たとえば、先ほど挙げた単語を分散表現で表すと以下のように表せます。

分散表現を使うことでone-hot表現が抱えていた問題を解決できます。たとえば、ベクトル間の演算で単語間の類似度を計算することができるようになります。上のベクトルを見ると、python と ruby の類似度は python と word の類似度よりも高くなりそうです。また、ボキャブラリ数が増えても各単語の次元数を増やさずに済みます。
分散表現のベクトルを得るための実装はこちら:
preprocessings/ja/word_vector.py
前処理の威力
この説では前処理にどれほどの効果があるのか検証します。具体的には文書分類タスクに前処理を適用した場合としていない場合で分類性能と実行時間を比較しました。結果として、前処理をすることで分類性能が向上し、実行時間は半分ほどになりました。
文書分類に使用したコーパス
文書分類のデータセットとして livedoor ニュースコーパスを使いました。livedoor ニュースコーパスは livedoor ニュースの記事を収集し、HTMLタグを取り除いて作成されたものです。このデータセットには以下に挙げる9つのクラスが含まれています:
- トピックニュース
- Sports Watch
- ITライフハック
- 家電チャンネル
- MOVIE ENTER
- 独女通信
- エスマックス
- livedoor HOMME
- Peachy
使用する前処理の種類
この節では前処理する場合の前処理の種類について簡単に述べておきます。
前処理しない場合は文章を形態素解析(ipadic)した後、BoWに変換しTF-IDFで重み付けしています。
それに対して、前処理した場合はまず文章に対してクリーニングを行います。行った処理は以下の3つです:
- URLの除去
- メンションの除去
- いくつかの記号の除去
クリーニングした後は形態素解析の辞書に NEologd を使って文章を分かち書きします。そして分かち書きした単語に対してテキストの正規化を行っています。処理としては以下の2つを行っています:
- 文字種の統一
- 数字の置き換え
正規化した単語に対して出現頻度ベースでストップワードの除去を行い、最終的にはBoWにTF-IDFで重み付けしたベクトルを用いて分類を行います。分類には RandomForest を用いています。
結果
結果については分類性能と実行時間を比較してみます。まずは分類性能(accuracy)についてみてみます。
| 前処理あり | 前処理なし |
|---|---|
| 0.917 | 0.898 |
分類性能については前処理した場合としなかった場合でほとんど変化しませんでした。予想では性能向上すると思っていたのですが・・・。この辺はさらなる考察が必要です。
実装のミスを修正したところ、前処理した場合としなかった場合で 1.9ポイント差がつきました。この性能での1.9ポイント差なのでそれなりの差ではないでしょうか。
実行時間を比較したところ以下のような結果になりました。前処理しない場合は600秒程度かかっているのに対して、前処理した場合はだいたいその半分の時間で計算が終了しています。これはクリーニングや正規化、そして特にストップワードの除去で語彙数を減らしたことが実行時間の削減につながったと考えられます。
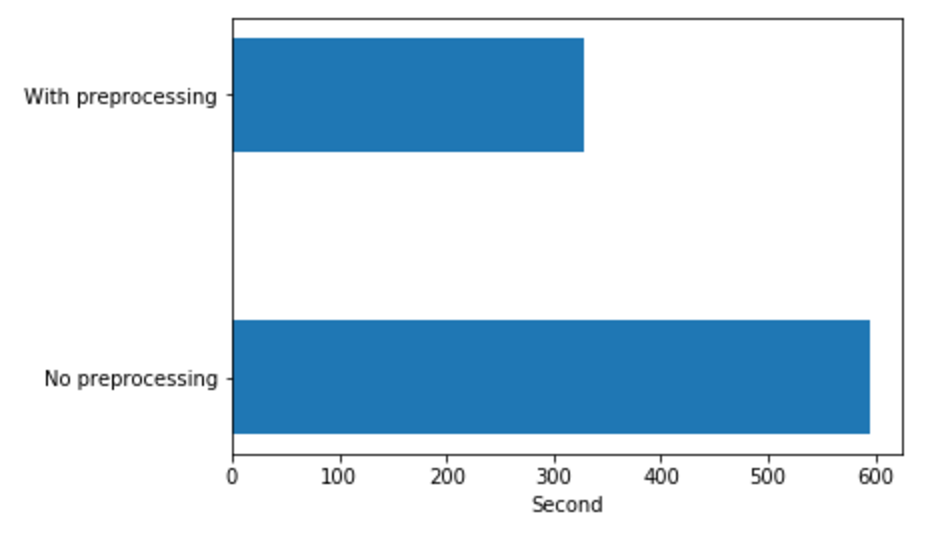
※前処理時間を含む
notebooks/document_classification.ipynb
おわりに
前処理は自然言語処理には欠かせない処理です。自然言語をコンピュータで扱うためには様々な処理が必要です。本記事ではそのうちのいくつかを紹介しました。この記事が皆様のお役に立てば幸いです。
私のTwitterアカウントでも機械学習や自然言語処理に関する情報をつぶやいています。
@Hironsan
この分野にご興味のある方のフォローをお待ちしています。