ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽にフォローしてください!
ディープラーニング界の大前提Transformerの論文解説!
自然言語処理の世界では2018年10月にBERTが出てきてとうとうNLPにもブレイクスルーが来たと話題になった。2019年にはそのBERTを超えるXLNetというモデルが出て来たり、危険すぎて公開禁止になったGPT-2が出て来たりと進歩が止まらない。直近(2019年11月)のGLUE Benchmarkのリーダーボードを見ると、いつのまにかNLPでは人間能力を越してしまったT5という強過ぎるモデル も出て来ていて盛り上がっている。
どのモデルも「Transformer」をベースにしている 。
Transformerを知らずしてNLPは語れない、ということでこの記事ではこのTransformerが提案された2017年12月の論文「Attention Is All You Need」を徹底解説。ちなみにTransformerの技術はNLPだけでなく他分野にも使われ高性能を叩き出しているためこれからのディープラーニングにTransformerは必要不可欠。Transformerのイメージは下図。
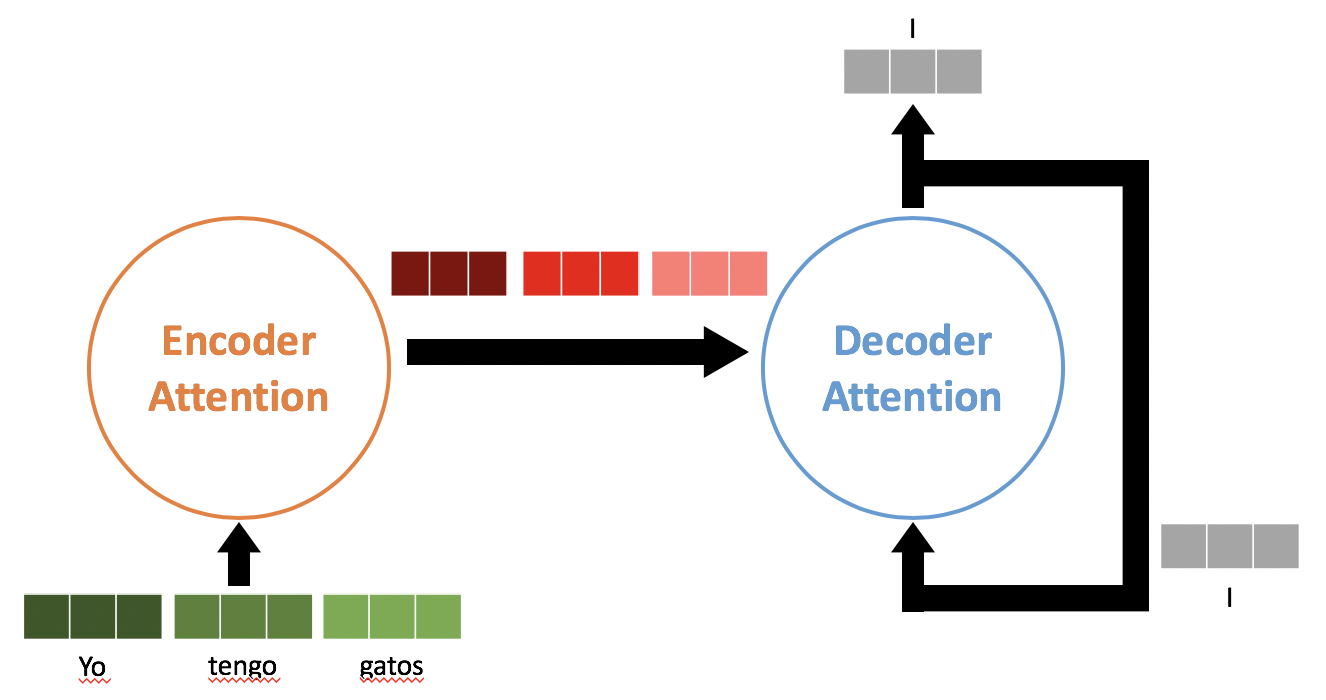
スペイン語-英語の翻訳タスクで英語の"I"を予測するTransformer.
Encoderに原文のEmbeddingを一気に入れて、その出力を一気にDecoderに入れる。
あとは推論時はDecoderが通常のSeq2seqのように逐次的に単語を出力していく。
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
(間違いなどもございましたら、ご指摘よろしくお願いします。)
0.忙しい方へのまとめ
- 翻訳タスクにおいて、Seq2seq(RNNベースEncoder-Decoderモデル)よりも早くて精度が高いという優れものだよ。
- RNNもCNNも使わずに Attentionのみを使用 したEncoder-Decoderモデルで計算量も精度も改善したよ。しかも並列計算可能だよ。
- アーキテクチャのポイントは以下の3つだよ。
- エンコーダー-デコーダモデル
- Attention
- 全結合層
- NLPの最近のSoTAたち(BERT,XLNet,GPT-2など)のベースとなるモデル だから理解必須だよ。
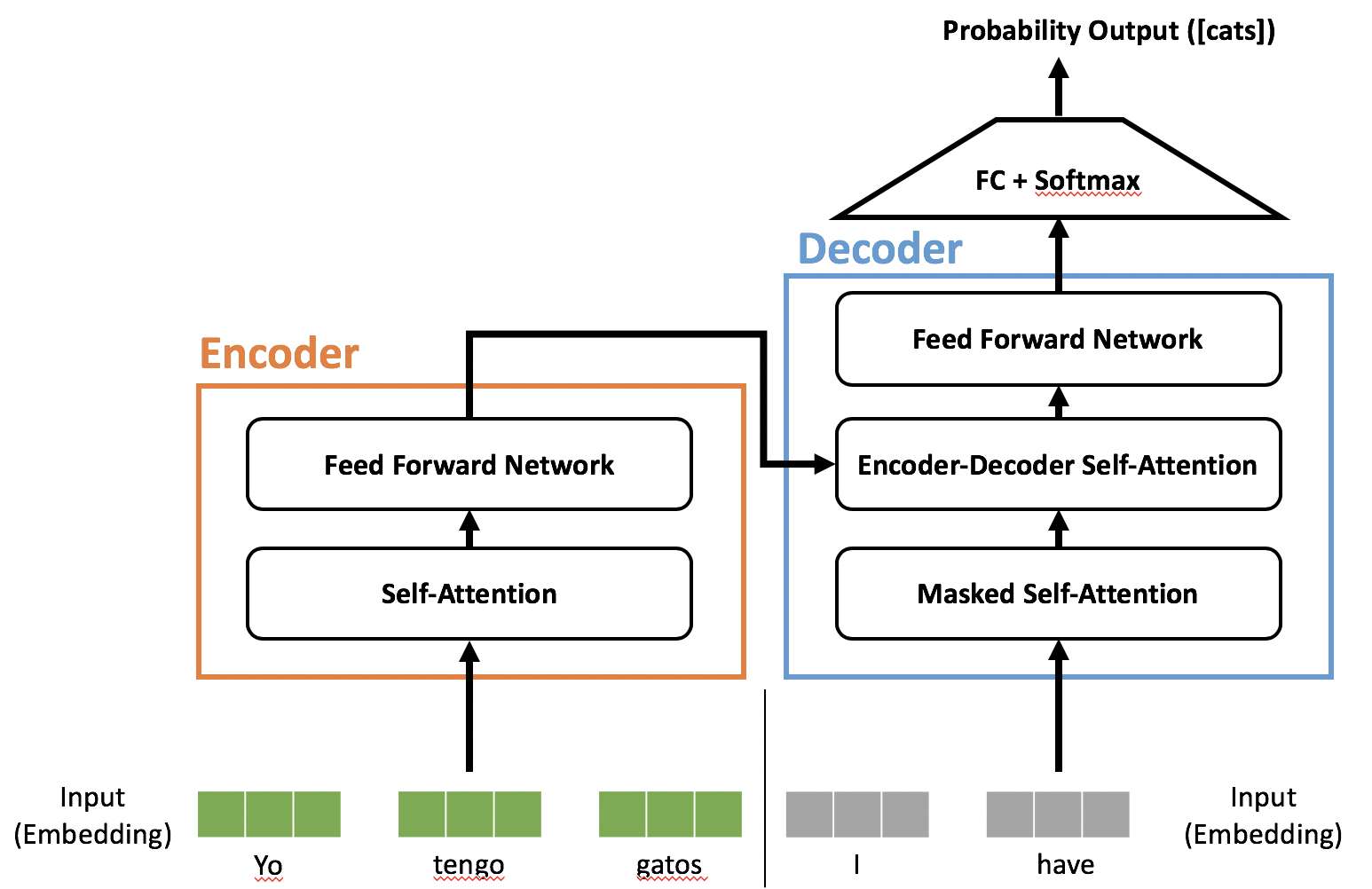
スペイン語-英語の翻訳タスクでcatsを予測するTransformer.
わかりやすさのためとても簡単に描いてみました。
1.論文解説
1.0 要約
翻訳などの入力文章を別の文章で出力するというモデル(=Sequence Transduction Model)はAttentionを用いたエンコーダー-デコーダ形式のRNNやCNNが主流であった。
本論文ではRNNやCNNを用いずAttentionのみを用いたモデル、Transformerを提案。
Transformerの特徴は以下。
- 再帰も畳み込みも一切使わない。
- 翻訳で今までのアンサンブルモデルも含めたSoTAを超えるBLEUスコア(28.4)を叩き出した。
- なのに並列化がかなりしやすく訓練時間が圧倒的に削減できる。
- それでいてTransformerは他のタスクにも汎用性が高いという優れもの。
これだけ読んでもうすでにすごすぎることがわかるので、全文読むのが楽しみですね。
1.1 導入
RNNとエンコーダ-デコーダモデルがこれまでのNLP界を牽引して来たが、逐次的に単語を処理するがゆえに訓練時に並列処理ができないという大きな欠点があった。また長文に対してはAttentionが使われていたが、そのAttentionはほぼRNNと一緒に使われていた。
この論文では、
RNNを一切使わずにAttentionだけを使うことで、入力と出力の文章同士の広範囲な依存関係を捉えられるモデルTransformerを提案。
1.2 背景
文章の依存関係を掴むための逐次的な計算を減らす という目的のもとRNNの代わりに使われたのがCNNである。
それによって並列処理をある程度可能にしたものの、文章が長くなるとそれに従って $\mathcal{O}(N)$ または $\mathcal{O}(\log{N})$ で計算量が増えてしまい、より長文の依存関係を掴めない という問題が残った。
ここで登場するのがTransformerである。計算量を文章の長さに応じずなんと定数時間 $\mathcal{O}(1)$ に抑えた。
繰り返しになるが、TransformerはCNNや逐次的なRNNを一切使わずAttentionのみを用いた一番最初のトランスダクションモデルである。
- Self-Attention: ある1文の単語たちだけを使って計算された、単語間の関連度スコアのようなもの をいう。**(ちなみに異なる2文の単語たちの関連度を計算するものはSource-Target Attentionと言われる)。**そのスコア(Attention)を使って、文のベクトル表現を獲得する。ある文に出現する単語間の関連度(スコア、Attention)を計算するのにその文に出現する単語だけを使うから、Self-Attentionと言われている。例えば"I have cats"という3単語の各単語の関連度(Attention)を計算する、というのは以下のようなスコアが出てくることである。
| I | have | cats | |
|---|---|---|---|
| I | 0.88 | 0.10 | 0.02 |
| have | 0.08 | 0.80 | 0.12 |
| cats | 0.03 | 0.14 | 0.83 |
この例に関する質問への回答を補足の項に記載しましたので、より良い理解のためにご参照ください。
1.3 モデル構造
トランスダクションモデル(ある文章を他の文章に変換するモデル(翻訳など))において主流なのは以下のようなエンコーダ-デコーダモデルである。
- エンコーダ: 入力の文 $(x_1,\ldots,x_n)$ を $\boldsymbol{z}=(z_1,\ldots,z_n)$ へ変換
-
デコーダ: $\boldsymbol{z}$ から単語 $(y_1,\ldots,y_m)$ を出力。
ただし、1時刻に1単語のみで、前時刻のデコーダの出力を現時刻のデコーダの入力として使う。
Transformerは基本的な大枠はエンコーダ-デコーダモデルでself-attention層とPosition-wise全結合層を使用していることが特徴。
つまり、以下の3つ(+2つ)のことが分かればモデル構造が理解できる ので順に説明していく。
- エンコーダ-デコーダモデル
- Attention
- Position-wise全結合層
- 文字の埋め込みとソフトマックス
- 位置エンコーディング
1.3.1 エンコーダ-デコーダモデル
まず、Transformerの全体像を示す。

Vaswani, A. et al.(2017) Attention Is All You Need
上図において、左半分がエンコーダ、右半分がデコーダ になっている。
英語からスペイン語に翻訳するようなものであれば、入力(ストップワード削除済み)はそれぞれ
- エンコーダ: I have cats
- デコーダ: Yo tengo gatos
となる。デコーダの入力だが、例えば英語の「cats」のスペイン語を予測するときにデコーダに答えである「gatos」を渡してしまうとデコーダは「gatos」を入力のまま出力するカンニングマシンになってしまうから、gatosをマスク(無視)することでカンニングを防いでいる。
だから名前が Masked Mult-Head Attention となっている。Maskしていること以外は普通のAttentionと同じ。(複数ヘッド(Multi-head)に関しては後述)
-
エンコーダ: $N=6$ 層で構成されていて、6層とも同じ構造。各層は Multi-Head Attention層 と Position-wise全結合層 の2つのサブ層で構成されている。それぞれのサブ層の後には 残差結合 と Layer Normalization(後述) がある。(上図のAdd&Norm)
-
デコーダ: 同じく $N=6$ 層で構成されており、これまた 6層とも同じ構造。ただし、各層はエンコーダの2つのサブ層の間にエンコーダの出力を受け取るMulti-Head Attention層を追加 した形になっている。あとは、デコーダのサブ層の1つ目は上図に書いてある通りMasked Multi-Head Attentionになっており、これはデコーダが現時刻で予測する単語およびそれ以降の単語たちをカンニングできないようにしている。
1.3.2 Attention
Attentionとは簡単に言うと、文中のある単語の意味を理解する時に、文中の単語のどれに注目すれば良いかを表すスコアのこと である。例えば英語でitが出て来たら、その単語だけでは翻訳できない。itを含む文章中のどの単語にどれだけ注目すべきかというスコアを表してくれるのがAttention。
AttentionとはQuery $\boldsymbol{Q}$ とKey $\boldsymbol{K}$ とValue $\boldsymbol{V}$ の3つのベクトルで計算される。各単語がそれぞれのQueryとKeyとValueのベクトルを持っている。より具体的には、Attentionとは $\boldsymbol{V}$ の加重和であり、その加重は $\boldsymbol{Q}$ と $\boldsymbol{K}$ を使って計算される。
QueryとKeyでAttentionスコアを計算し、そのAttentionスコアを使ってValueを加重和すると、Attentionを適用した単語の潜在表現が手に入る。
( $\boldsymbol{Q, K, V}$ の詳細については後述。)
1.3.2.1 縮小付き内積Attention
$\boldsymbol{Q, K, V}$ の正体はEncoderの最初の段であれば、入力単語Embedding $X$ にそれぞれ重み $W^Q, W^K, W^V$ を掛け合わせたもの(つまり、 $XW^Q, XW^K, XW^V$ )。 これがEncoderの2段目以降であれば、前段の出力にその段特有の別の重み $W^Q, W^K, W^V$ を掛けることで手に入れられる。
Attentionは $\boldsymbol{Q, K, V}$ によって計算されると前述したように、縮小付き内積Attentionも同様である。$\boldsymbol{Q}$ と $\boldsymbol{K}$ は次元 $d_k$ を持ち、 $\boldsymbol{V}$ は次元 $d_v$ を持つ。この縮小付き内積Attentionを文章で表すと、 クエリと全キーの内積によりその関連度を計算し、 $\sqrt{d_k}$ で割ったのちに、ソフトマックス関数を適用させる こと。数式は以下。
$$
\mathrm{Attention}(Q, K, V)=\mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V
$$
上式で $V$ を除いた、 $\mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})$ の部分が縮小付き内積Attentionのスコアとなる。ここで $\sqrt{d_k}$ がなければ、普通のAttentionのこと。
今回のようにクエリとキーによる掛け算でAttentionを算出する方法を 内積Attention と言い、クエリとキーを入力とした1層の全結合層でAttentionを算出する方法を 加法Attention という。内積Attentionの方が速いため今回は内積Attentionを使った。また、$\sqrt{d_k}$ でスケール(縮小)しているのは内積Attentionは $d_k$ が大きいと加法Attentionよりも性能が劣ってしまうため。
1.3.2.2 複数ヘッドAttention
各単語に対して1組のQuery,Key,Valueを持たせるのではなく、比較的小さいQuery, Key, Valueをヘッドの数分つくり、それぞれのヘッドで潜在表現を計算する。 最終的にそれらを1つのベクトルに落とすことによって獲得された潜在表現をその単語の潜在表現とする。
より具体的には、それぞれのheadの潜在表現たちをConcatし、それを重み $W^O$ で掛け算することで元の次元に戻してその層のOutputとする。この論文ではヘッドの数が8つなので、QueryとKeyとValue用の小さいサイズの重みをそれぞれ8つずつ用意する。計算式で見るとわかりやすい。
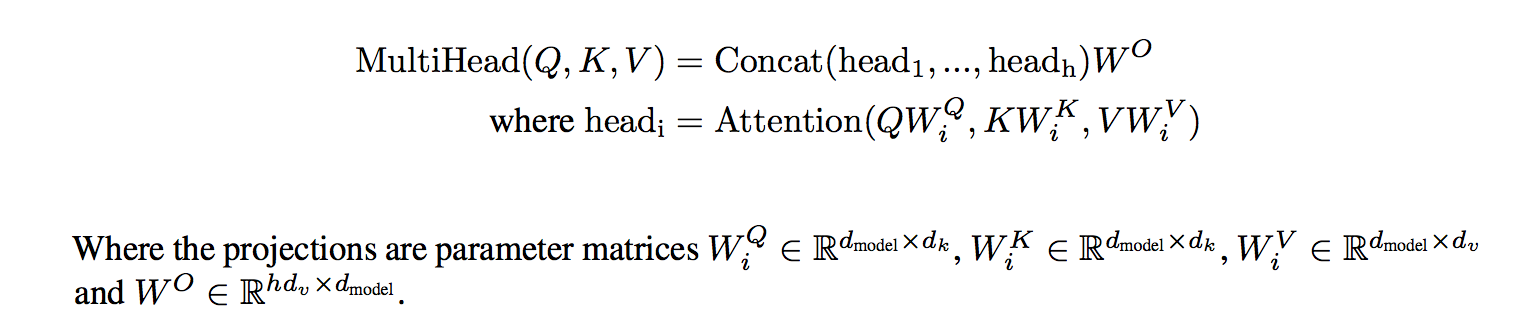
Vaswani, A. et al.(2017) Attention Is All You Need
ヘッドを複数個用意することで、それぞれが異なる潜在表現の空間から有益な情報を取ってきてくれる。
1.3.2.3 このモデルにおけるAttention
このモデルではAttentionは3ヶ所で使われている。
-
エンコーダ-デコーダ Attention :
- Query: デコーダ内前層の出力
- Key, Value: エンコーダの最終出力
-
エンコーダ Self-Attention :
- Query, Key, Value: エンコーダ内の前層出力
-
デコーダ Masked Self-Attention :
- Query, Key, Value: デコーダ内の前層出力(ただし、対象単語より右側にAttentionが加わらないようにしている。翻訳タスクでカンニングを防ぐ。)
1.3.3 Position-wise 順伝播ネットワーク
各ブロックのAttention層のあとに入っているPosition-wise 順伝播ネットワーク。
Position-wiseというのはただ単に、各単語ごとに独立してニューラルネットワークがあるということ(ただし、重みは共有)。 ニューラルネットワーク内では他単語との干渉はない。2層のニューラルネットワークになっている。式は以下。
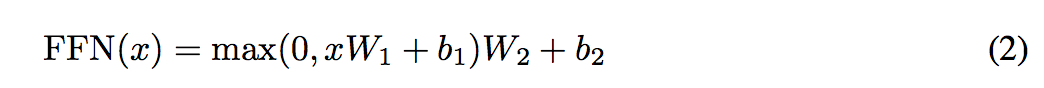
Vaswani, A. et al.(2017) Attention Is All You Need
1.3.4 単語の分散表現とソフトマックス
入力の単語は事前訓練済みの単語分散表現を使ってベクトルに変換 する。また、デコーダの最終出力は、ニューラルネットワークに入力されソフトマックスで一番高い確率を示した単語を出力するが、その ニューラルネットワークに使う重みは一番最初の単語の分散表現を使うときの重みと同じもの を使用する。
1.3.5 位置エンコード
単語の位置関係を捉えられる再帰(recurrence)や畳み込み(convolution)を使っていないため、このままだとTransformerにとって単語の順番は関係なくなってしまっている。極端な話、"I love cats"と "cats love I"は同じものになってしまっている。
そこで登場するのが、位置エンコードという考え方。
原理は単純で、一番最初にこのモデルに単語の分散表現を入力するときに単語位置に一意の値を各分散表現に加算するだけ。 単語に一意な値を出力するような関数を使ってあげることで実現できる。Transformerではsin関数とcos関数を使っている。Transformerは単語の位置に一意の値を与えてくれるsin関数とcos関数のパターンもしっかりと学習してくれるため、結果として位置の依存関係を学んでくれているという算段になっている。 このモデルで使われている位置エンコードの式は以下。$pos$は位置、$i$は次元。
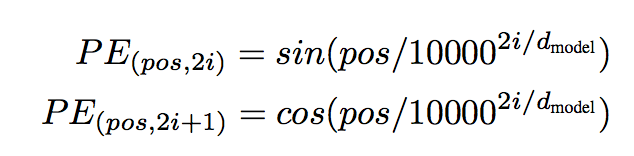
Vaswani, A. et al.(2017) Attention Is All You Need
1.4 Self-Attentionを使う理由
理由は4つある。
- 計算量が小さい。(再帰や畳み込み(Separable Convolution)よりも。)
- 並列計算可能
- 広範囲の依存関係を学習可能
- 高い解釈可能性
特に計算量に関しては以下表。ここで $n, d$ はそれぞれ1文の単語数とdは1単語の次元数である。通常、$n<<d$ となるため、Self-Attentionの計算量が一番小さい ことがわかる。 Self-Attention(restricted) はAttentionがかかる範囲を文の全体ではなく特定の単語周辺$r$のみにかかるようにしたもの。

Vaswani, A. et al.(2017) Attention Is All You Need
1.5 学習
1.5.1 データセットとバッチ
データセットは以下。
各バッチは約25,000のソース(翻訳元)・ターゲット(翻訳先)ペアを持っている。
| データセット | ペア数 | トークン数 |
|---|---|---|
| WMT2014英独 | 4.5 M | 37,000 |
| WMT2014英仏 | 36 M | 32,000 |
1.5.2 ハードウェアと訓練時間
- NVIDIA P100 GPUsを8個使用
- ベースモデルでは0.4秒かかる1ステップを合計100,000ステップ(12時間)行なった。
- 大きいモデルでは1.0秒かかる1ステップを合計300,000ステップ(3.5日間)行なった。
1.5.3 最適化関数
Adamを使って、学習が進むにつれて学習率が変化するようにした。
1.5.4 正則化
過学習を防ぐための正則化として以下の2つの手法を用いた。
- ドロップアウト: 各サブレイヤーの出力と、エンコーダおよびデコーダへの分散表現入力直前 に適用。
- ラベルスムージング: 精度とBLEUスコア向上に貢献。(パープレキシティは下がった。)
1.6 実験結果
1.6.1 機械翻訳
英独および英仏の翻訳タスクでいずれもSoTAを叩き出した。
特に 英仏の翻訳タスクでは学習時の計算コストを1/4 に抑えることもできた。
詳細は以下の表。
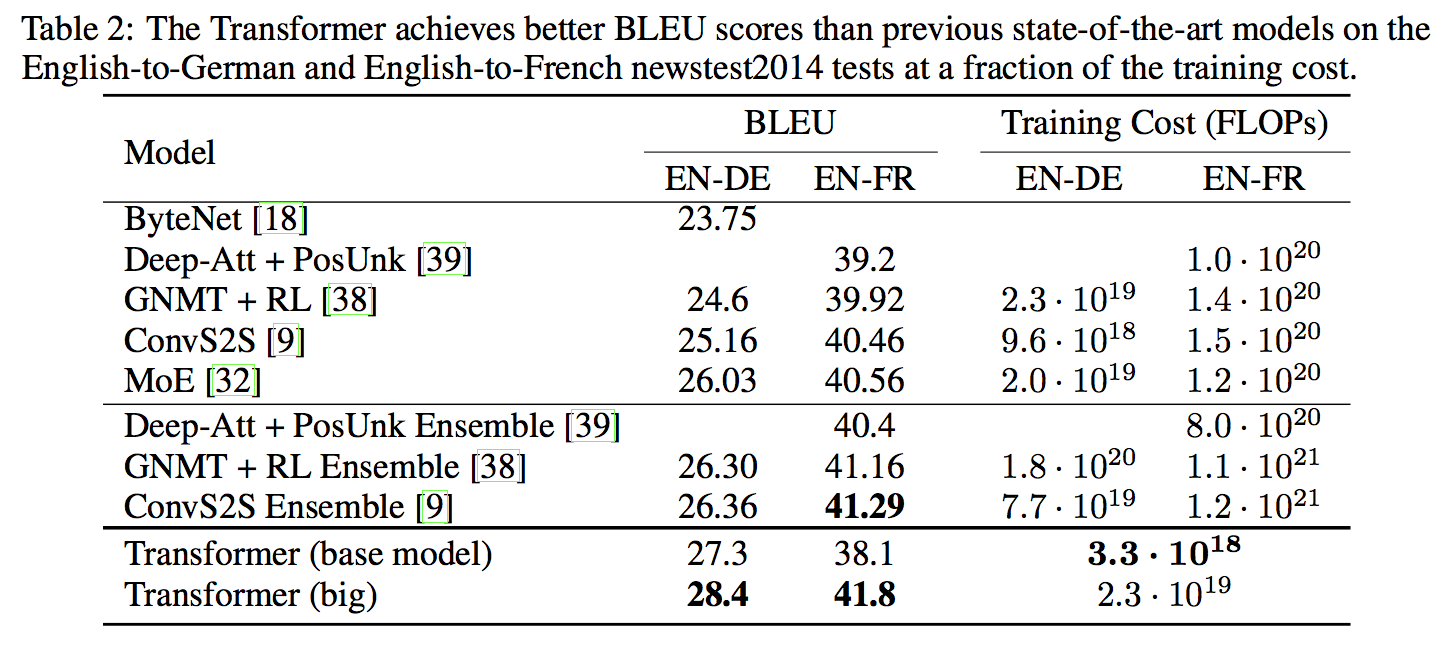
Vaswani, A. et al.(2017) Attention Is All You Need
1.6.2 モデルの構造
モデルの複数ヘッドの数やドロップアウト率などあらゆる構造のTransformerを試してその性能の違いをみてみる。
ここで得られたことは以下の5つ。
- ヘッドが1つの時より複数ヘッドの方が良いが、ヘッド数が多すぎても逆に性能劣化
- KeyとValueの次元を下げると性能劣化
- モデルサイズが大きいと性能向上
- ドロップアウトやラベルスムージングは有効
- 位置エンコードの代わりに位置を考慮したエンベディングを使っても性能は変わらなかった。
1.6.3 英語の文章構造を捉えているか
特別な修正を加えなくても、Transformerが英語の文章構造をしっかりと捉えていることがわかった。Transformerは文章構造をしっかりと捉えられているため、翻訳以外の英語タスクにも適用できることが期待される。
1.7 結論
この論文ではAttentionだけを使った翻訳モデル(sequence transduction model)、Transformerを提案。Transformerは驚異的なスピードで学習することができ、SoTAも達成。文章だけでなく、画像や音声、動画など 他のタスクにもTransformerを使うことができる と考えている。
2. まとめと所感
最近のNLP界隈で発表される 最新モデル(BERT, XLNet, BPT-2など)はどれもTransformerをベース であり、そのTransformerの提案論文である 本論文はNLPの動向を理解するには必須の論文。ただ筆者はそもそもAttentionへの理解が不足していたため、Transformerを理解するのには本論文だけでなく多くの参考文献をあたった。
これでNLPの最新論文を読めるようになったので、いろいろと読んでいきたい。
面白い論文は需要があればまた別記事で紹介していきたいと思いますのでよろしくお願いします。
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
3. 用語と補足
3.1 BLEUスコア
機械翻訳による文章を人間による文章たちと比べて、どれだけ人間の文章に近いかを表したスコア。 0から1の範囲で、1に近ければ近いほど良い。
利点は以下の5つ。
- 計算量が小さい
- 理解しやすい
- どの言語にも使える
- 人間による評価を加味している
- 広く使われている
ここでは直感的な理解にとどめ、より詳しい数式などは後述の参考リンクをみてください。
3.2 Layer Normalization
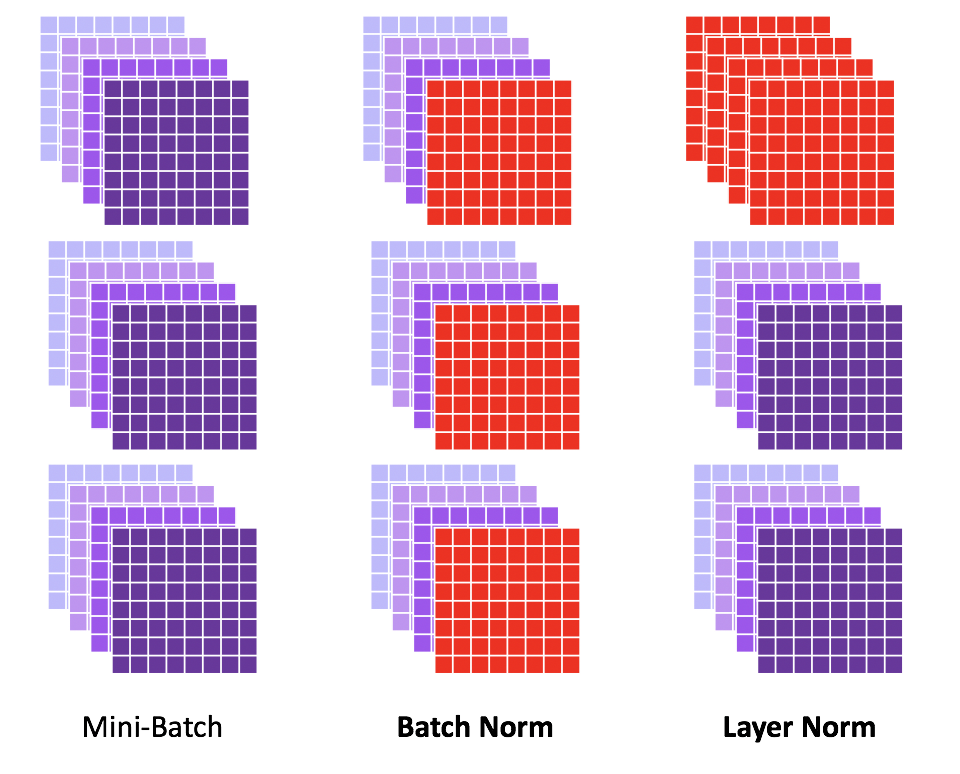
上図左のようなミニバッチ(チャネル数4のデータが3つで1バッチ、画像のFeaturesみたいな感じのデータ)があった時、Batch Normalization(上図真ん中)は同一チャネルをミニバッチに跨って正規化する。これをチャネル毎に行う。赤色になっているところがBatch Normalizationされている場所で、一番手前のチャネルをミニバッチ全体に及んで正規化している。(これは各チャネルに行われる。)
Layer Normalizationはミニバッチ全体に及んで正規化するのではなく、
各データそれぞれで正規化する。
Transformerでいうとミニバッチ内の各データというのは各文章に対応する。Transformerの場合は一回のinputに例えば10文ぐらい入れるとしたら(つまりミニバッチのサイズが10)、1文例えば256単語あるとしたらその256単語に跨って正規化する、という感じ。
3.3 Label Smoothing
すごく感覚的に言うと、正解ラベルに少し優しさを与えること。
これではさすがにわからないので、具体例で言う。
例えば、クラスが
[リンゴ バナナ オレンジ]
のクラス数3の画像分類モデルがあるとする。
ここで正解ラベルがone-hotで
[0 0 1]の画像(オレンジ)
があるとすると、モデルの予測値も[0.01 0 0.99]のようになるべくオレンジが1に近づいてほしい。
ここまでは至って普通の画像分類モデル。
Label Smoothingでは正解ラベルを代わりに
[0.1 0.1 0.8]
として、普通のone-hotの正解ラベルよりも多少間違えても損失が大きくなりすぎないようするもの のこと。優しさが見えますね。
正解ラベルにモデルがものすごく忠実すぎると過学習を起こしかねない。そういう過学習を抑えるために上記のように導入されるのがLabel Smoothing、という解釈。式で表すと以下のようになる。
$$
\textrm{new_onehot} = (1 - \epsilon) * \textrm{onehot} + \frac{\epsilon}{N}
$$
ここで $\epsilon, N$ はそれぞれスムージング係数([0,1])とクラス数。
先ほどの例は $\epsilon=0.3, N=3$ であることがわかる。(代入して計算してみてください。)
上式はこの論文中のLabel Smoothingについてですが、厳密なLabel Smoothingでは上式の第2項が $\frac{1}{N}$ のような一様分布ではなく、任意の分布をとるようです。
もっと知りたい方は参考リンクをみてください。
3.4 Self-Attentionに関する質問への回答
コメント欄の以下の2つの質問についてお答えいたします。
Self-Attentionの「I have cats」の例に関して、
- 前知識なく、この3語だけで関連度を計算するということでしょうか?
- また、"I"-"have" と "have"-"I" の関連度が異なるのは前後関係を反映しているのでしょうか?
1. 前知識なく、この3語だけで関連度を計算するということでしょうか?
まず1.についてですが、「前知識を使っている」と言える かと思います。
というのも、関連度を出すときに本文中では
クエリと全キーの内積によりその関連度を計算し、
と申し上げましたが、このクエリとキーは各単語のベクトル表現に重み $W^Q, W^K$ を掛けて出しており、
この $W^Q, W^K$ は学習されるパラメータだから です。(バリューを出すための $W^V$ も同様に学習されるパラメータです。)
2. また、"I"-"have" と "have"-"I" の関連度が異なるのは前後関係を反映しているのでしょうか?
続けて2.についてですが、関連度が異なる理由はおっしゃる通りで、より正確には**「前後関係以上の関係を反映している」** かと思います。
$W^Q, W^K, W^V$ によって各単語のクエリ、キー、バリューの3つのベクトルが計算されます。
I have catsを例に少し考えて見ましょう。
それぞれがクエリ、キー、バリューを持つのでテーブルでまとめると、
| query | key | value | |
|---|---|---|---|
| I | $q_1$ | $k_1$ | $v_1$ |
| have | $q_2$ | $k_2$ | $v_2$ |
| cats | $q_3$ | $k_3$ | $v_3$ |
これを使って本題であるSelf-Attentionを表しましょう。
Self-Attentionは各単語のクエリとキーの内積(にソフトマックス関数を適用したもの)なので、関連度を表すと、
| I | have | cats | |
|---|---|---|---|
| I | $q_1\cdot k_1$ | $\boldsymbol{q_1\cdot k_2}$ | $q_1\cdot k_3$ |
| have | $\boldsymbol{q_2\cdot k_1}$ | $q_2\cdot k_2$ | $q_2\cdot k_3$ |
| cats | $q_3\cdot k_1$ | $q_3\cdot k_2$ | $q_3\cdot k_3$ |
ここでは横の行が縦の列の単語に対しての関連度を表しています。
I-haveとhave-Iを見てみるとわかりますが、それぞれ計算されているのが$q_1\cdot k_2$と$q_2\cdot k_1$を使って計算されています。つまり、違う値になることがわかります。
これは前後関係も考慮しているでしょうし、それ以上の複雑な係り結びなどの関係も捉えた上での値だと思っています。
この回答で疑問が解ければ幸いです!
4. 参考リンク
-
The Illustrated Transformer
(英語)Transformerに関して果てしなくわかりやすい記事。 -
Sequence Transduction with Recurrent Neural Networks
(論文)sequence transduction modelの説明がAbstractに記載されている。 -
Complexity of transformer attention network
(英語)Self-AttentionやMulti-Head Self-Attentionの計算量を解説しているReddit。
(AxB)(BxC)の行列内積のTime ComplexityはABCであることが分かれば、
計算しやすい。 -
Label Smoothing: An ingredient of higher model accuracy
(英語)Label Smoothingについてわかりやすい記事。(Mediumの課金記事) -
モデルの評価
GoogleによるBLEUスコアの解説記事。数式など書いてあります。 -
A Gentle Introduction to Calculating the BLEU Score for Text in Python
(英語)BLEUスコアについての解説記事。計算方法は書いてないが利点と使い方が書いてある。 -
Batch Normalizationとその派生の整理
Layer Normalizationについても書いてある。 -
Label Smoothing
(英語)Label Smoothingについての詳しい説明。