こんにちは。
2025年4月15日に、AWS東京リージョンのAZ障害が発生しました。
電源と二次電源の遮断が原因と公開されており、午後 4:40 から午後 5:43 (日本時間) の間に、利用しているシステムが影響を受けたという方も多いと思います。
このようなAZ障害が発生した場合に、該当AZへのトラフィックを自動で迂回させる機能である、Application Recovery Controller(以下ARC)を本記事で徹底解説します。
なお、この障害の詳細については、AWS Health Dashboardで公開されています。
対象読者
本記事は、以下の方を対象読者として想定しています。
・AZ障害を自動迂回したい方(手動での迂回も可能)
・レジリエンス(回復力)を高め、AZ障害時の影響を極小化したい方
・ARCについて詳しく知りたい方、設計・実装したい方、提案したい方
・ARCの最新情報(本記事執筆の2025年12月時点)をキャッチアップできていなかった方
なお、ARCはリージョン障害にも対応していますが、本記事ではAZ障害において機能するゾーンシフト、ゾーンオートシフトについて記載します。
ARCのゾーンシフト/ゾーンオートシフトについては料金はかかりません。
なお、マルチリージョンリカバリ機能であるルーティングコントロールを利用する場合は、作成したクラスターごとに時間単位のコストが発生します。
https://docs.aws.amazon.com/ja_jp/r53recovery/latest/dg/introduction-pricing-routing-control.html
ARCのAZ障害リカバリ機能
ARCには、手動でのリカバリ機能としてゾーンシフト、自動でのリカバリ機能としてゾーンオートシフトがあります。
2つの違いは、発動契機が利用者による手動か、AWSによる自動かの点にあります。
なお、ゾーンオートシフトについては、ゾーンシフトを設定したうえで、有効化または無効化が選択できます。
どのような障害で自動発動するのか
AWSが自動で発動させるゾーンオートシフトは、AWSの内部テレメトリー監視によるAZ障害の検出がトリガーとなります。
具体的には、AWS側でネットワーク、EC2、ELBなど、複数のソースからのメトリクスを含む内部テレメトリーを使用してAZの健全性を監視しています。
この監視でサービスに影響を与える可能性のある障害が検出されると、AWSは自動で、障害が発生したAZから健全なAZへトラフィックをシフトさせます。
AZの一部サービス、機能、ネットワークなどが不安定となる、いわゆる『グレー障害』にも有効です。
グレー障害について詳しく知りたい方は、以下をご確認ください。
ARCを利用できるサービス
本記事執筆時点におけるリカバリ対象サービスは、以下の4つです。
- Application Load Balancer(ALB)
- Network Load Balancer(NLB)
- EC2 Auto Scaling Group(ASG)
- Elastic Kubernetes Service(EKS)
それぞれのサービスでAZ障害をどのように迂回するのかを見ていきましょう。ALBとNLBは同様の動作となるため、まとめて紹介します。
ALB、NLB
ALBやNLBについては、ターゲットの正常性を監視するヘルスチェック機能があります。
ターゲットがダウンするような明確な障害はヘルスチェック機能で検出・切り離しされるため、サービス影響を回避できます。
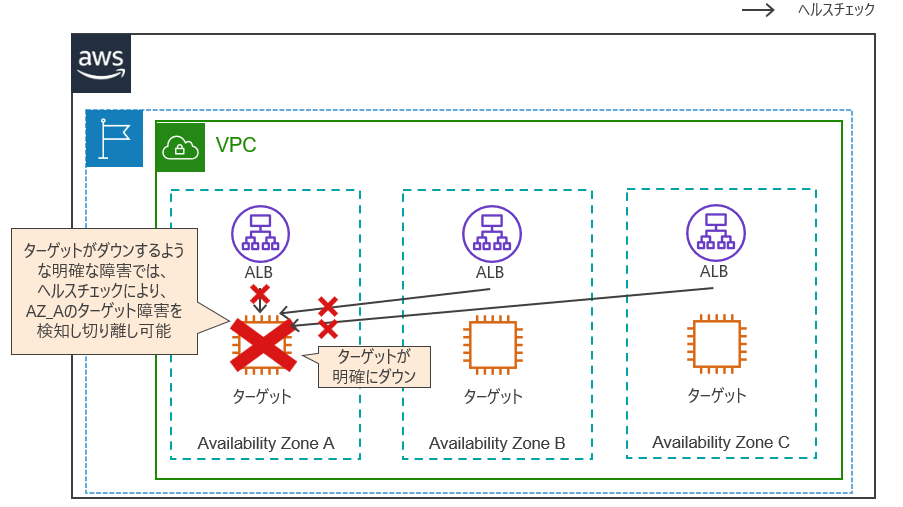
一方、単一AZを経由する通信のみエラーが発生したり、レスポンスが遅くなったりするケースなど、ヘルスチェックが正常と判断される『グレー障害』時には、サービス影響が発生してしまいます。

このようなグレー障害の対策となる機能がARCとなります。では、ARCを有効化している場合の動きを見ていきましょう。
まずは通常時の状態です。
ALBを3AZで運用している場合、DNSの名前解決では、合計3つのIPがレスポンスされ、3AZに跨って通信は行われます。
なお、クロスゾーン負荷分散を有効化している環境では、各ALBから3AZのターゲットに跨って通信が行われますが、下図ではAZ_Aのターゲットのみに通信が行われているように簡略化しています。

クロスゾーン負荷分散を有効化したALB、NLBではゾーンシフト・ゾーンオートシフト機能は当初サポートされていませんでしたが、2024年10月にNLB、2024年11月にALBがサポートされ、クロスゾーン負荷分散を有効化した環境でもゾーンシフト・ゾーンオートシフト機能が利用可能となっています。
ゾーンシフト・オートゾーンシフトによるクロスゾーン負荷分散の使用については、以下のAWSブログ記事もご確認ください。
https://aws.amazon.com/jp/blogs/networking-and-content-delivery/using-cross-zone-load-balancing-with-zonal-shift/
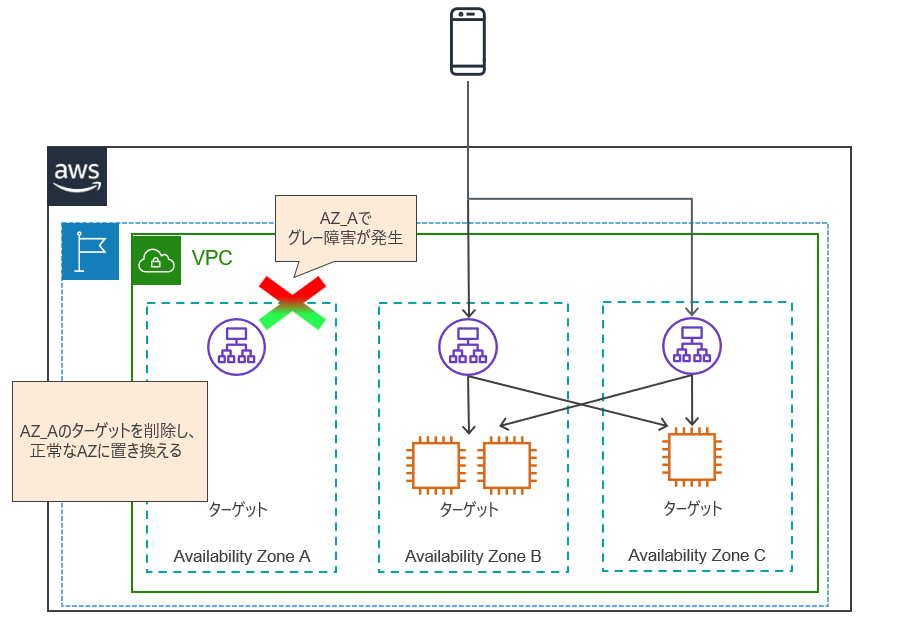
下図は、AZ_Aでグレー障害が発生した状態です。ARCにより、以下の処理が行われます。
- Route53のレスポンスから、AZ_AのALBのIPを削除
- AZ_B、AZ_CのALBから、AZ_Aのターゲットへのトラフィックをブロック
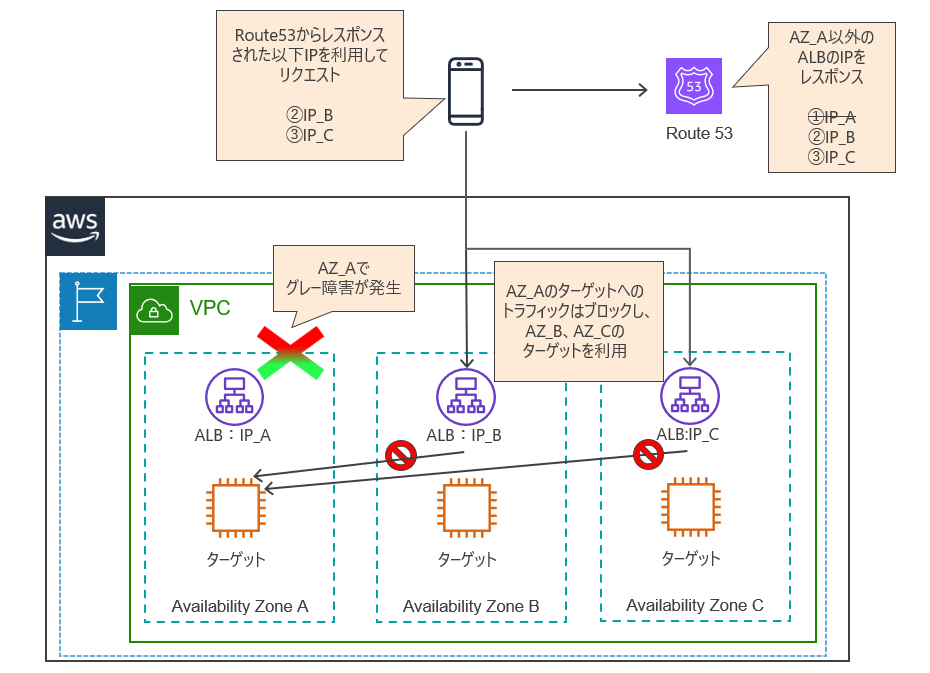
これにより、クライアントからALBへのリクエスト、ALBからターゲットへのリクエスト双方がAZ_Aを迂回した状態になります。
ゾーンオートシフトを有効化している場合は、自動でAZ障害を迂回し、正常な2つのAZでサービス提供を継続することが期待される動作です。
なお、ALBでARCを利用する場合の設計ポイントとして、
- クライアントからALBへの新規のトラフィックを障害AZ(AZ_A)から早めに遠ざけるため、「DNSのTTL」を60秒など小さい値にする
- クライアントからALBへの既存のトラフィックを障害AZ(AZ_A)から早めに遠ざけるため、ALBの「HTTPクライアントのキープアライブ期間」を60秒など小さい値にする
という点に注意が必要です。
特に、ALBの「HTTPクライアントのキープアライブ期間」はデフォルトで3600秒となっており、ゾーンオートシフトが発動しても、このデフォルト値のままでは最大1時間、障害AZ(AZ_A)のALBへ接続し続けることになります。

ARCの有効化と合わせて、これら2つのタイマーを適切な値に設計しましょう。
HTTPキープアライブは、一度確立したTCP接続を複数のHTTPリクエストで再利用することで、接続の確立にかかるオーバーヘッドを削減し、パフォーマンスを向上させる仕組みです。
ALBの「HTTPクライアントのキープアライブ」は、ALBに接続するクライアント側のキープアライブ時間よりも長い値を設定し、以下の関係をもたせる必要があります。
クライアント側のHTTPキープアライブ時間 < ALBのクライアントのキープアライブ期間
これは、ALBのキープアライブ期間が先に終了した場合、クライアントがその接続を使って新たなリクエストを送ろうとすると、ALBが既にその接続を閉じてしまっていることで発生するエラーを防止するため、が理由となります。
ALBの「HTTPクライアントのキープアライブ期間」を60秒などに短縮する場合、クライアント側のHTTPキープアライブ時間の変更も必要になる可能性がありますので、注意しましょう。
NLBでは、HTTPクライアントのキープアライブ期間の設定はできません。キープアライブではありませんが、TCPのアイドルタイムアウトについては、2024年9月のアップデートにより、60~6000秒の任意の値に変更が可能となっています。一方、UDPのアイドルタイムアウトは120秒に固定されており、変更ができません。
次に、ALBでARCを有効化する手順を紹介します。ALB側では、ALBの属性の編集から、デフォルトで無効になっているARCを有効化するのみです。
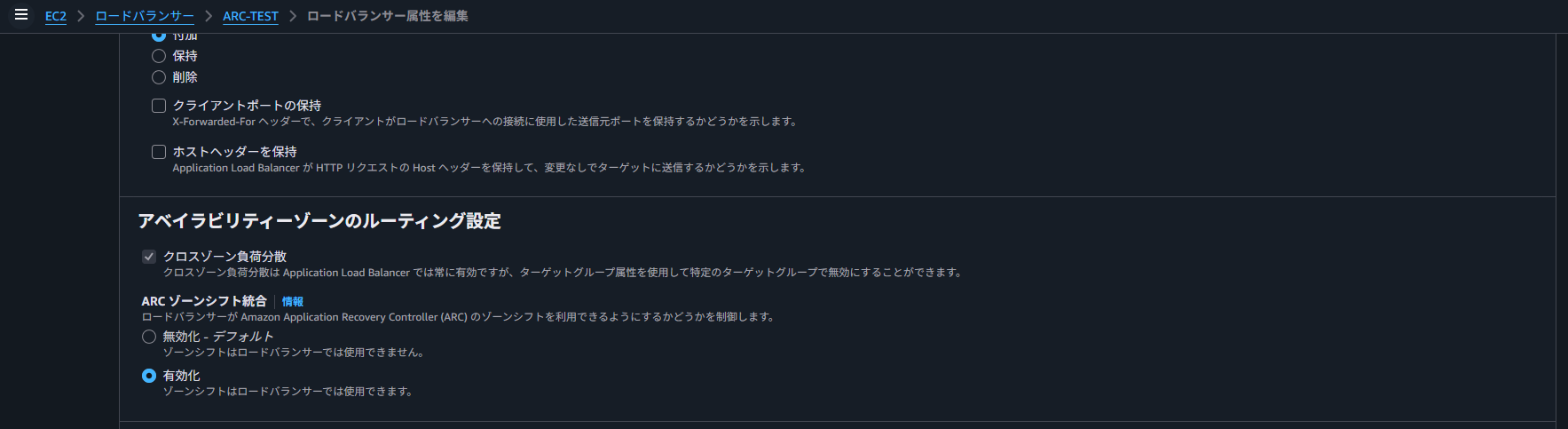
これにより、ALBがARCのゾーンシフト設定対象リソースとして登録され、ゾーンシフトの設定が可能になります。
下記は、ALBがリソースとして登録された後のマネジメントコンソールのARCの設定画面となります。ゾーンシフトの設定については後述します。
EC2 Auto Scaling Group(ASG)
次に、ASGでARCを有効化している場合の動きを見ていきましょう。
まず、ARCを有効化すると、ゾーンシフト発動中は正常なAZでのみリソースが起動されるようになります。
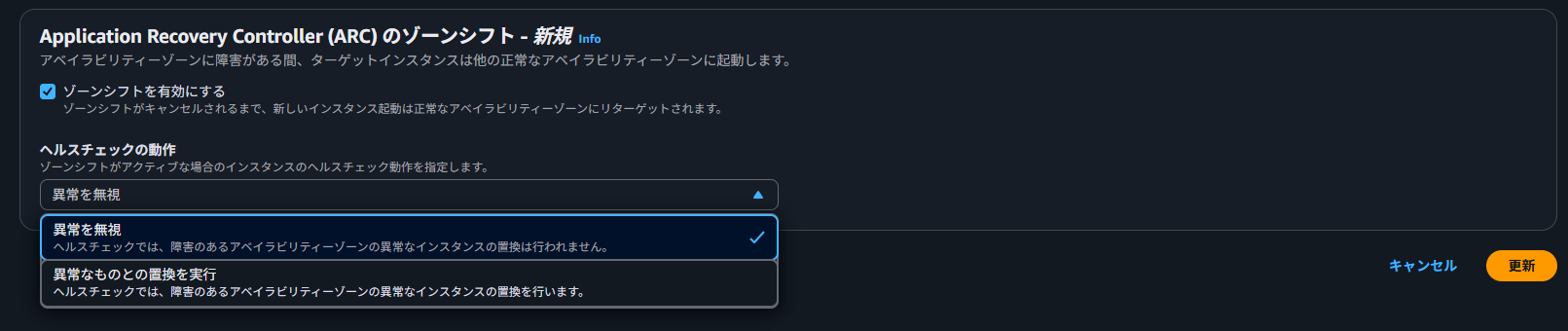
また、「ヘルスチェックの動作」設定では、以下の2種類の動作から選択します。
- 異常を無視
- 異常のものとの置換を実行
設定は、ASGの統合設定からARCを選択する形で行います。
ARC(ゾーンシフト)を有効化すると、ASGもALBと同様にARCのゾーンシフト設定対象リソースとして登録され、ゾーンシフトの設定が可能になります。
次に、それぞれの動作の違いを見ていきましょう。
1.異常を無視
障害のあるAZのリソースは置き換えられず、正常なAZのリソースを増加させることなく動作を継続します。
これは、事前に2AZ(または1AZ)で十分なキャパシティを保有している場合の選択肢です。障害AZでもリソースは起動したままとなるため、復旧後には安全かつ早期に正常なAZ分散状態へ戻れるとされています。

2.異常のものとの置換を実行:障害のあるAZのリソースを別のAZに置き換えます。具体的には、正常なAZのリソースをスケールアウトさせ、必要なキャパシティを確保します。
これは、コスト削減などを優先し、2AZ(または1AZ)で十分なキャパシティを保有していない場合の選択肢です。ただし、リソースの置き換えが常に正常に行われるとは限らないリスクがあるとされています。静的安定性を考慮するなら、前者の「異常を無視」が推奨となるでしょう。
AWSにおける静的安定性とは、障害が発生したり利用できなくなったりしても、追加の変更を加える必要がなく、システムは通常どおり動作し続ける、つまり静的な状態で動作するという状態を指します。
EC2コントロールプレーンに依存して新しいEC2インスタンスを起動する代わりに、必要な容量を事前にプロビジョニングしておくことで、静的安定性を実現できるとされています。
EKS
EKSでARCを有効化している場合の動きを見ていきましょう。
EKSでは、ARCを有効化すると、ゾーンシフト発動時に以下の4つの処理が行われるようになります
- Kubernetesスケジューラが、障害AZに新規Podをスケジュールしなくなる
- EndpointSliceコントローラは、障害AZ内のすべてのPodを検出し、関連するEndpointSliceから削除することで、正常なAZ内のPodのみが利用されるようにする
- 障害AZのノードとPodは、復旧時に障害AZをフルキャパシティで安全に戻すため、削除まではされない
- マネージドノードグループを使用している場合は、新規ノードは正常なAZでのみ起動される
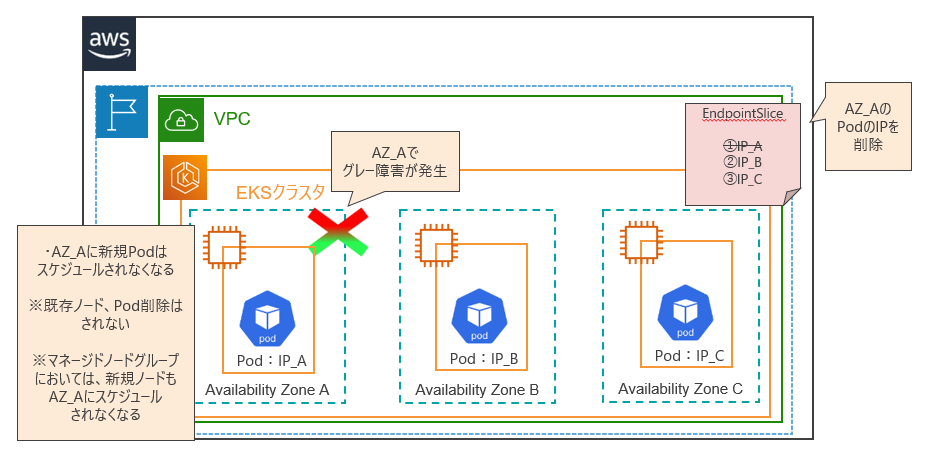
EndpointSliceは、KubernetesのAPIリソースの一種で、Serviceに関連付けられたバックエンドエンドポイント(通常はPod)のIPアドレスとポートを追跡し保持しています。EndpointSliceから障害の発生しているPodのIP情報が削除されることで、正常なAZのPodのみに通信がルーティングされるようになります。
設定はEKSクラスター単位となり、EKSクラスターの概要設定からARCを選択し有効化します。
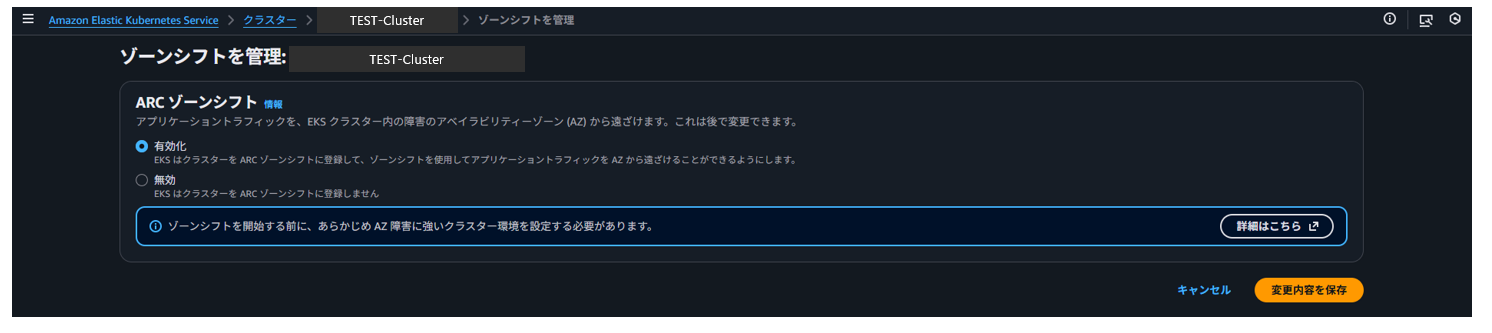
ARCを有効化すると、EKSクラスターもALBやASGと同様にARCのゾーンシフト設定対象リソースとして登録され、ゾーンシフトの設定が可能になります。
EKSのARCは、以下のサポートはされていませんので注意しましょう。
- karpenter、EKS Auto Modeの利用
- EKS Fargate
ゾーンシフトの設定
ゾーンシフトは、利用者が任意のタイミングで発動させる機能です。マネジメントコンソールで設定を見ていきましょう。
ゾーンシフトを開始する場合は、障害が発生しており迂回させたい1つのAZと、ARCを有効化している対象のリソースを選択します。

また、ゾーンシフトを発動させる有効期限を、1分から3日までの期間で選択します。ゾーンシフトを開始するとトラフィックを処理するリソースが減少するため、その点を理解し、同意することも求められます。
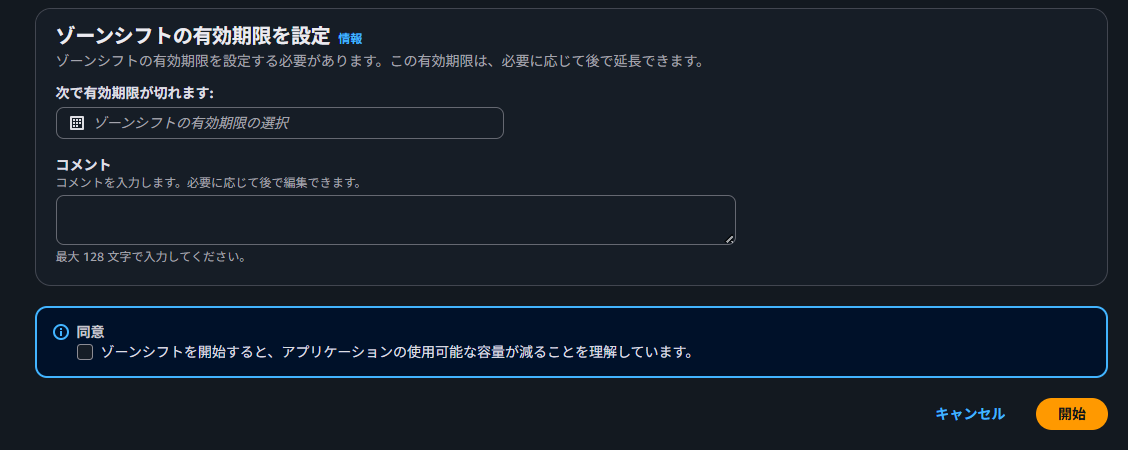
ゾーンオートシフトの設定
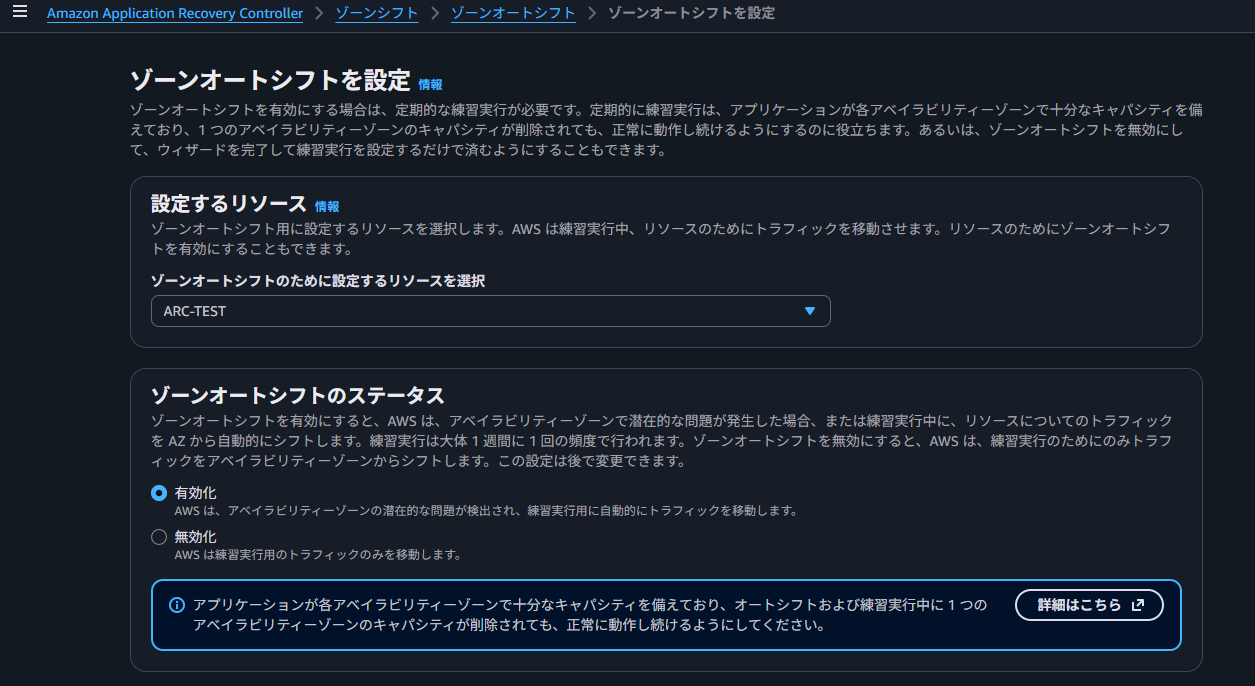
ゾーンオートシフトを設定すると、ゾーンシフトがAWSによって自動で発動されるようになります。こちらもマネジメントコンソールで設定を見ていきましょう。
まず、ゾーンオートシフトを有効化するリソースを選択します。
ゾーンオートシフトのステータスには、有効化と無効化があります。
無効化は、『練習実行』と呼ばれるAWSによる週に一度の確認のみを実行させる場合に選択します。これは、事前に練習実行で挙動を確認したいなど、テスト期間中の選択肢と考えられます。AZ障害を自動で迂回させたい場合は、『有効化』を選択します。
ゾーンオートシフトを有効化するための練習実行
練習実行について見ていきましょう。
ARCを有効化する場合、AWSによる週に一度、約30分間行われる『練習実行』と呼ばれる確認動作が必須設定となります。練習実行中は、ゾーンオートシフトが発動した場合と同じ動作になり、1つのAZへトラフィックが流れない迂回状態になります。
また、練習実行の結果をモニタリングするための『結果アラーム』は必須設定です。練習実行中に指定したアラームが発動した場合、練習実行は失敗と判断されます。
練習実行をブロックする『ブロッキングアラーム』はオプション設定です。練習実行前に指定したアラームが発動した場合、練習実行は開始されないようにできます。

例えば、ターゲットのUnhealthyメトリクスが1つ以上ある場合にCloudWatchアラームを設定した場合、練習実行中にターゲットが1つでもUnhealthyとなれば結果を失敗と判断させ、練習実行前にターゲットが1つでもUnhealthyであれば、練習実行を開始しないように設定できます。
練習実行中はトラフィックを処理するリソースが1AZ分だけ減少するため、任意の時間帯に稼働するよう設定可能です。設定は、実行を許可する『allowed windows』と、実行を拒否する『blocked windows』から、それぞれ15個のウィンドウを設定できます。
イメージしやすいよう、例をあげます。
以下は、allowed windowsを土曜、日曜の0時から1時に設定した例です。この設定により、練習実行は指定された日時(土曜・日曜の0時から1時)にのみ許可されます。ゾーンシフトと同様に、作成には同意が必要です。

以下は、blocked windowsを月曜から金曜の平日に設定し、かつ土日であってもブロックしたい特異日として、12/13、12/14を個別に設定した場合の例です。blocked windowsのみ、ブロックしたい日付を指定することもできます。
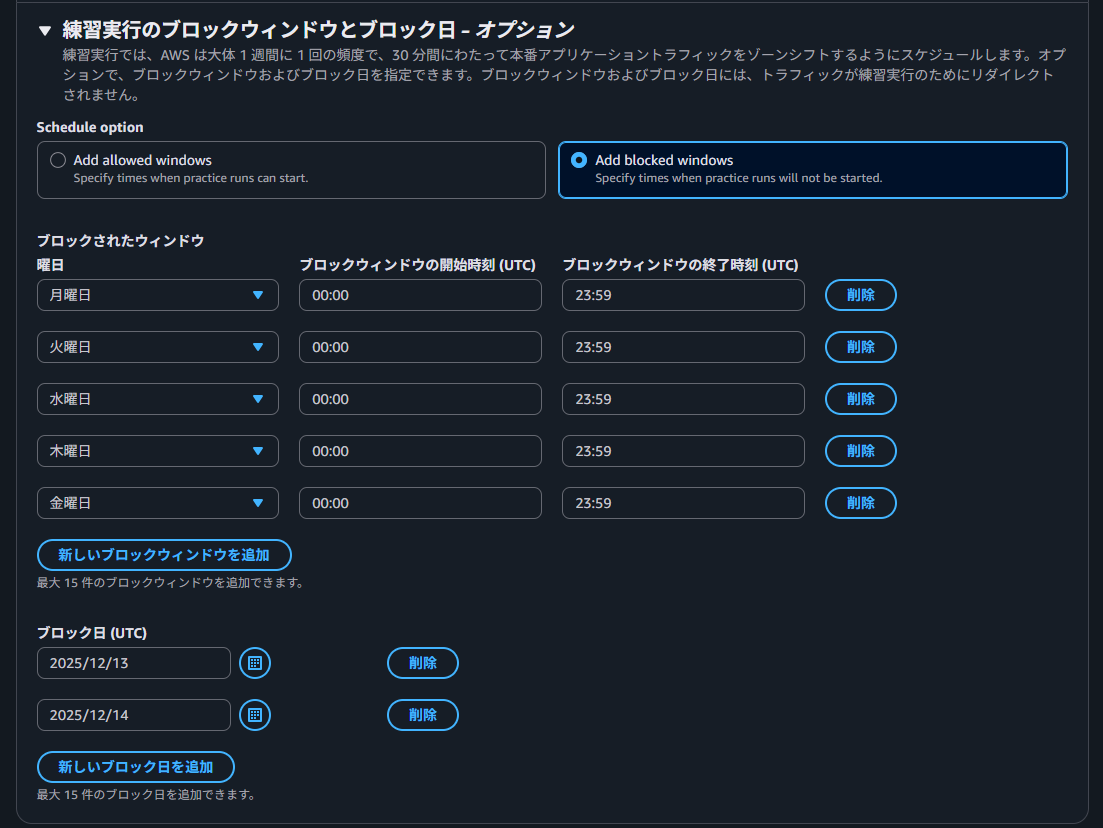
練習実行のウインドウでの日時設定はUTCとなります。JST(日本標準時)ではないので注意しましょう。
練習実行のオンデマンド実行
2025年6月に、練習実行を任意のタイミングで実行できるオンデマンド実行機能がリリースされました。それ以前は、ゾーンオートシフトのテストをするにはFault Injection Service (FIS)のaws:arc:start-zonal-autoshiftアクションを利用したりする必要がありましたが、ARC内の機能でゾーンオートシフトの単独テストが簡易に実行できます。
以下は、私が実装した際に、ALBで練習実行のオンデマンド実行をテストした場合のトラフィック推移です。通常時6台で処理しているトラフィックが、対象としたAZの2台には、練習実行時間である30分間振り分けられなくなっていることが分かります。
また、練習実行中も同量のトラフィックを流しているため、その他のAZで稼働する4台の処理するトラフィックが増加していることも確認できます。

オンデマンド実行も、allowed windowsの時間外やblocked windowsの時間内では実行ができません。一時的にオンデマンド実行を利用してテストする場合は、テスト時間帯をallowed windowsで設定するか、blocked windowsの時間外に設定しましょう。
練習実行のキャパシティチェック機能
ALB、NLB、ASGでは、練習実行前にキャパシティチェックを実施できます。チェックに失敗すると練習実行自体がCAPACITY_CHECK_FAILEDで失敗します。
練習実行時に、発動してよいキャパシティ配置ができているかをチェックできる機能です。概要を表でまとめます。
| サービス | 概要 | 例 |
|---|---|---|
| ALB、NLB | ターゲットが登録されているすべてのAZにおいて、正常なターゲットの数が均等であることを確認。「均等」とは、各AZの正常なキャパシティが他のゾーンとわずかな差異内で均等であることを意味する | 通常時3AZに2台づつ、合計6台のターゲットを配置している場合、1AZのターゲットが1台であった場合(1台をターゲットから切り離ししている場合)は、均等と判断しない |
| ASG | 設定している「希望するキャパシティ」数のリソースが、練習実行が発動した場合でも満たせるかどうかを確認 | 「希望するキャパシティ」が5、各AZにリソースを2つ、合計6つ配置の構成では、1AZを切り離すとターゲットが「希望するキャパシティ」未満の4になるため発動しない |
私が実装した際に、3AZに2台づつ、合計6台のターゲットを通常配置している構成において、1AZの1台のターゲットを切り離した状態では、実際にキャパシティチェックでエラーが発生しましたので紹介します。

なお、練習実行の結果は、上述のマネジメントコンソール、または次のモニタリングで記載するイベントメッセージにて確認できます。
ゾーンオートシフトのモニタリング
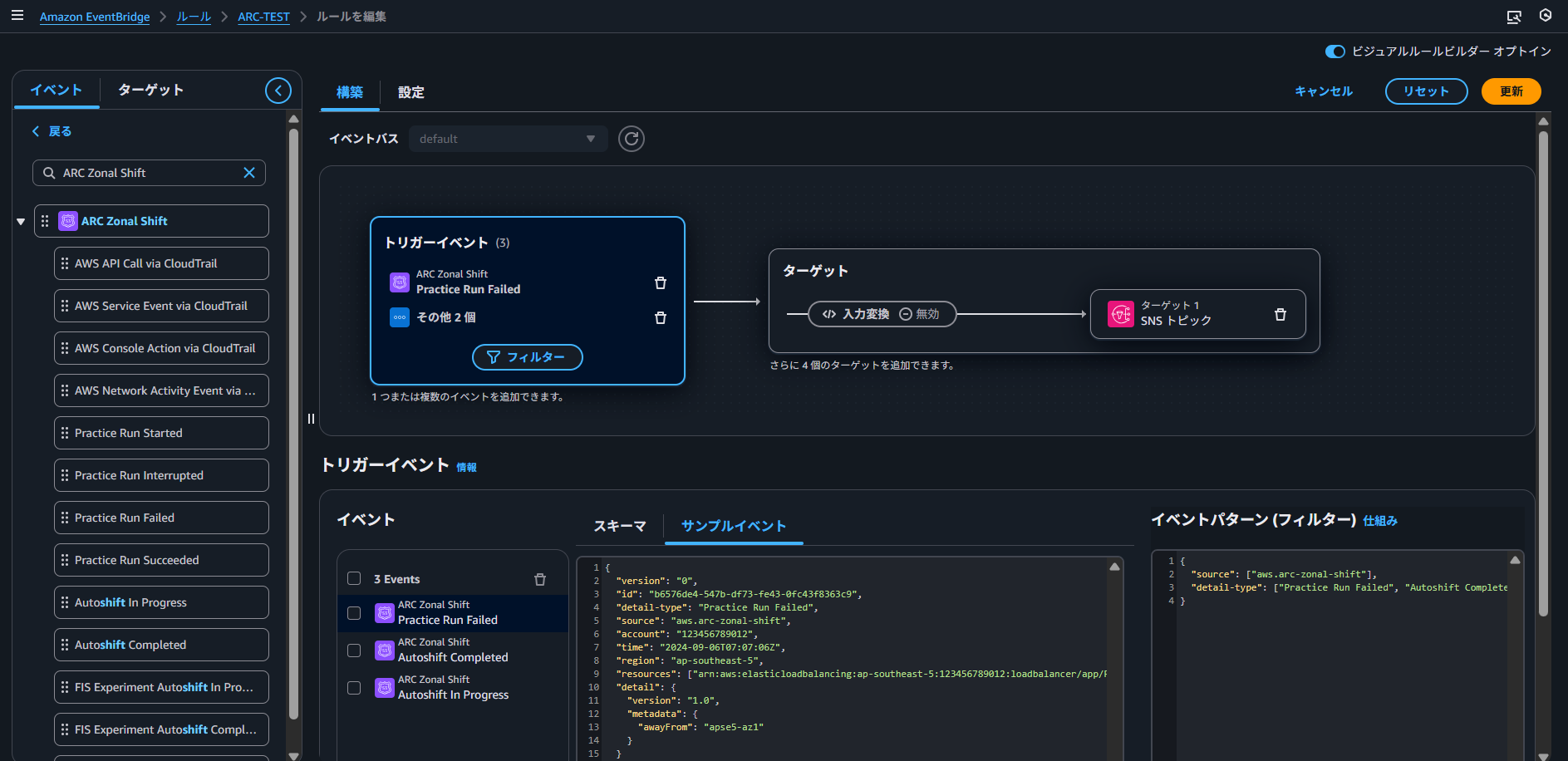
EventBridgeを利用してARCのイベントをモニタリングし、例えばSNSによる通知が可能です。SNS以外にも、CloudWatch logなどEventBridgeがサポートするターゲットを設定できます。

ゾーンオートシフトのイベントと概要を紹介します。
以下の例では、ゾーンオートシフトの発動と完了、また練習実行の失敗を検知対象として選定しています。要件に合わせて、通知対象を選定しましょう。
| イベント | イベント概要 | 通知対象 |
|---|---|---|
| Autoshift In Progress | ゾーンオートシフトの発生 | ◯ |
| Autoshift Completed | ゾーンオートシフトの完了 | ◯ |
| Practice Run Started | 練習実行の開始 | ✕ |
| Practice Run Succeeded | 練習実行の成功 | ✕ |
| Practice Run Interrupted | ブロックウィンドウ内での練習実行の中止 | ✕ |
| Practice Run Failed | 練習実行の失敗 | ◯ |
| FIS Experiment Autoshift In Progress | Fault Injection Service (FIS) でゾーンオートシフトの発生 | ✕ |
| FIS Experiment Autoshift Completed | Fault Injection Service (FIS) でゾーンオートシフトが完了 | ✕ |
| FIS Experiment Autoshift Canceled | Fault Injection Service (FIS) でゾーンオートシフトがキャンセル | ✕ |
以下は、マネジメントコンソールでの設定例となります。選定した3つのイベントをトリガーイベントとして選択し、ターゲットにはSNSを設定しています。
EventBridgeを利用したモニタリングについては、以下のAWSブログ記事もご確認ください。
まとめ
ARCのゾーンシフト/ゾーンオートシフトについて完全に理解した、と言っていただける内容を目指して記載してみました。
ARCのゾーンシフト/ゾーンオートシフトは比較的シンプルなサービスですが、以下の設計ポイントがあります。
| 設計要素 | 設計ポイント |
|---|---|
| ALB、NLBで利用する場合のDNSのTTL | クライアントからALB、NLBへの新規のトラフィックを障害AZから早めに遠ざけるため、「DNSのTTL」を60秒など小さい値にする |
| ALBで利用する場合のHTTPクライアントのキープアライブ期間 | クライアントからALBへの既存のトラフィックを障害AZから早めに遠ざけるため、ALBの「HTTPクライアントのキープアライブ期間」を60秒など小さい値にする |
| ゾーンオートシフトの練習実行の時間設定 | AWSにより週に一度、30分間ゾーンオートシフトが発動。トラフィックを処理するリソースが減少するため、適切な時間に行われるようallowed windowsまたはblocked windowsを指定する |
| ゾーンオートシフトの練習実行のCloudWatchアラーム設定 | 練習実行の成否を判断する「結果アラーム」は必須の設定。また、練習実行の可否を判断する「ブロッキングアラーム」はオプションの設定。システム特性に合わせてCloudWatchアラームを設定する |
| ゾーンオートシフトのモニタリング | EventBridgeを利用してトリガーイベントを選定し、通知など必要なターゲット(アクション)を設定する |
ARCはAZ障害を手動、または自動迂回できる機能です。
ALB、NLBのクロスゾーン負荷分散に対応している現在では、システムのレジリエンス(回復力)向上のため、ARCの有効化を積極的に検討してみましょう。
なお、レジリエンス向上は、一度の設定や機能で完結するものではありません。モニタリングやアップデート機能の取り込みを継続的に実施していきましょう。
また、ARCのリージョン切り替えについては対象外としましたが、グラフィカルエディタを使用してワークフローを作成することもできます。
ARCのルーティングコントロール以外に、EC2 Auto Scalingを利用したスケールや、Aurora Global Databaseのフェイルオーバーも実行できるようになっています。
興味のある方は以下のAWSブログ記事もご確認ください。