なんの記事?
Pubtatorフォーマットと呼ばれるフォーマットをいい感じに前処理してくれるツールを作ったので、その紹介記事を書きました。今書いている、エンティティ・リンキング用チュートリアルの後編で使用予定です。
PubTatorとは?
主に生物医学分野の論文を扱うPubMedが持つ論文に対してアノテーションを付与するツールになります。専門家がアノテーションしやすいような直感的な操作が特徴の一つです。
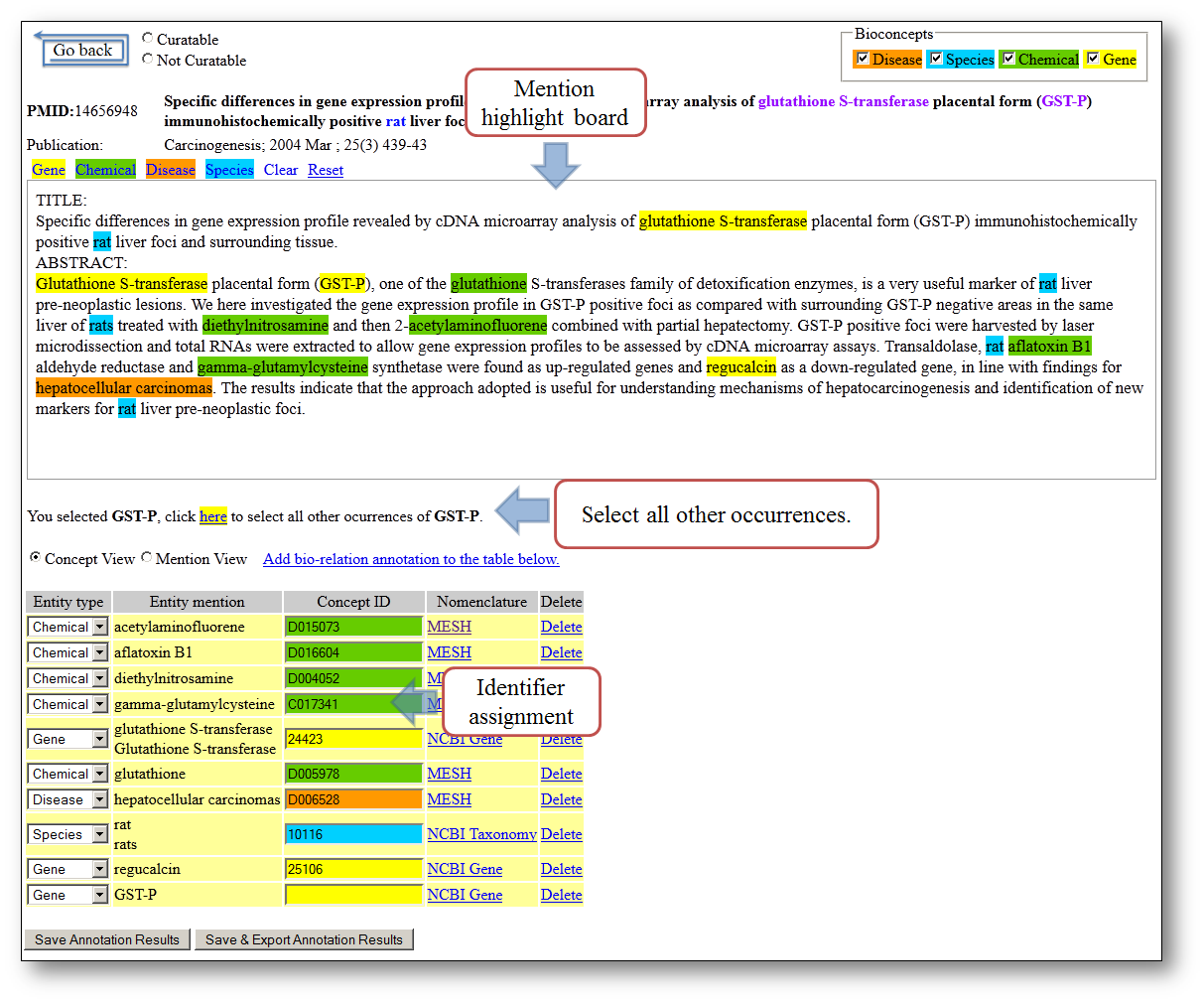
(図は公式より引用)
実際のアノテーションの結果吐き出されるアウトプットについては、以下のようになります。
https://www.ncbi.nlm.nih.gov/CBBresearch/Lu/Demo/tmTools/Format.html
PubTatorを用いてアノテーションされた文書ファイルで実際に中身を見てみましょう。本記事では、種種の生物医学論文にアノテーションされた MedMentions [Mohan and Li, '19] を使用します。
実際のファイルが存在するリポジトリは以下になります。
https://github.com/chanzuckerberg/MedMentions
fullとst21pvの二種が存在します。
st21pvでは、上位階層に属するより一般的な概念が、fullバージョンから除外されています。元来このデータセットは専門家の生物医学文書からの情報抽出を助けることを目的としているため、より上位の概念はそれらのタスクに不向きだと考えられ、st21pvではそれらのアノテーションが除外されています。
実際のPubTatorフォーマットについて
ここ からダウンロードが可能です。
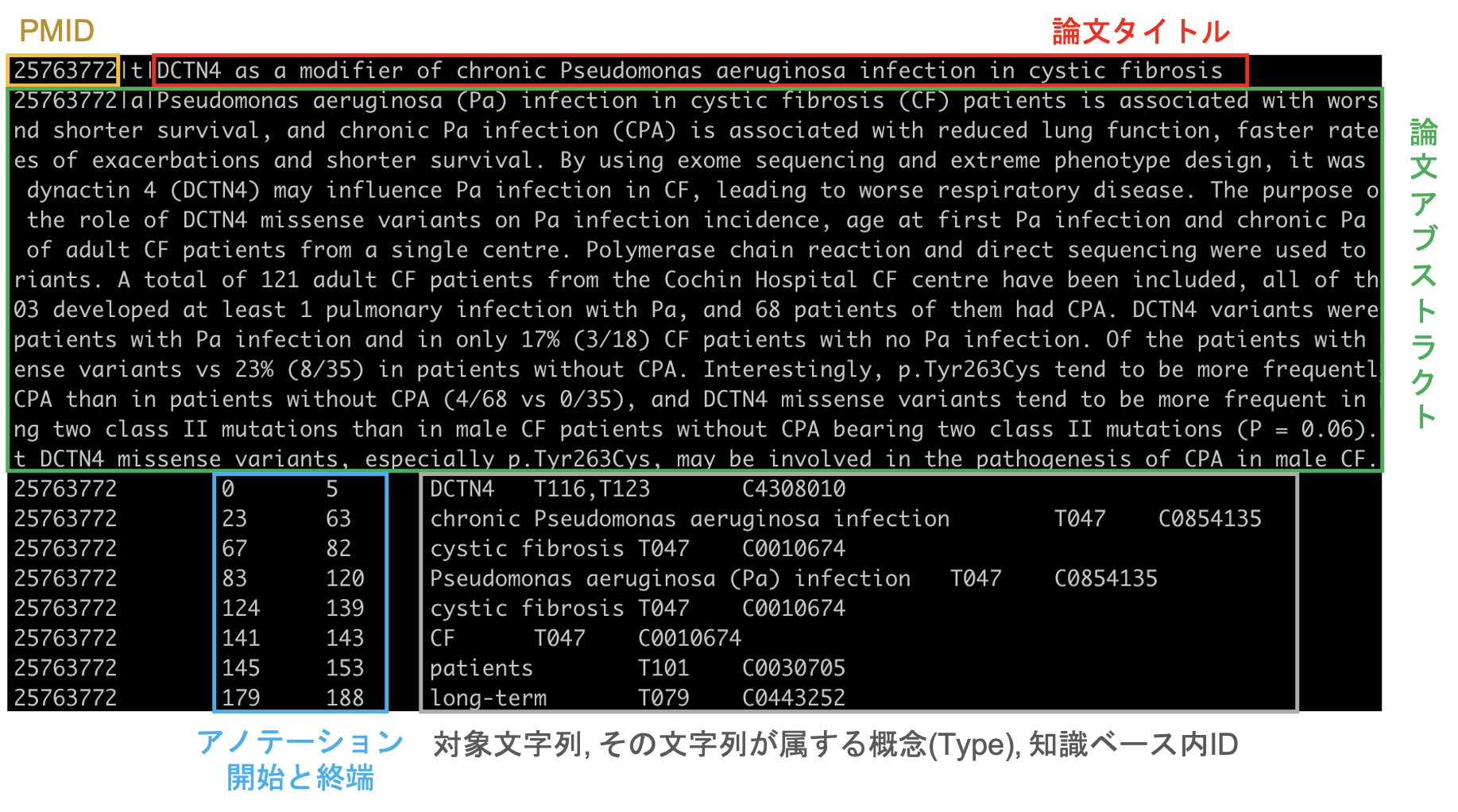
フォーマットは、1つの論文に対して上記のようになっています。MedMentionsは、このようなアノテーションを4392文書に対して行ったものになります。
アノテーションの開始文字列について、1. 論文タイトルが始点であること。 2. 論文アブスト内のアノテーションスパンも、論文タイトル+論文アブストを結合した上での論文タイトルが始点であること。これらに注意しましょう。
Semantics Types について
上の図で言う、T101, T116, T123 などがこれに相当します。今回のデータセットはUMLSと呼ばれる知識ベースに紐づいています。
知識ベースの中にも多種多様な概念があり、これらを予め決められた型(Type)のラベル集合で分類した場合に、専門家が付与したラベルになります。
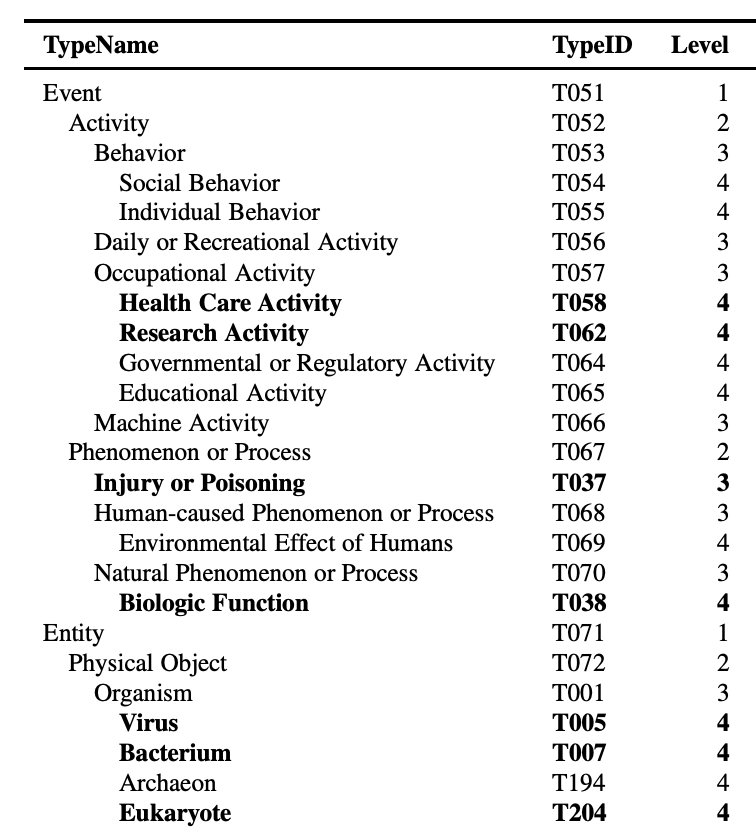
(図は論文から引用)
UMLS について
今回扱うPubTatorフォーマットアノテーションと紐づいている知識ベースが統合医学用語システム (Unified Medical Language System:UMLS) を使用する.になります。UMLSは多くの生物医学分野用語をカバーしており、毎年新しい語彙が追加されアップデートされています。
PubTatorフォーマットを扱う上での難しさ
一言で言ってしまうと、文章分割されていない点にあります。
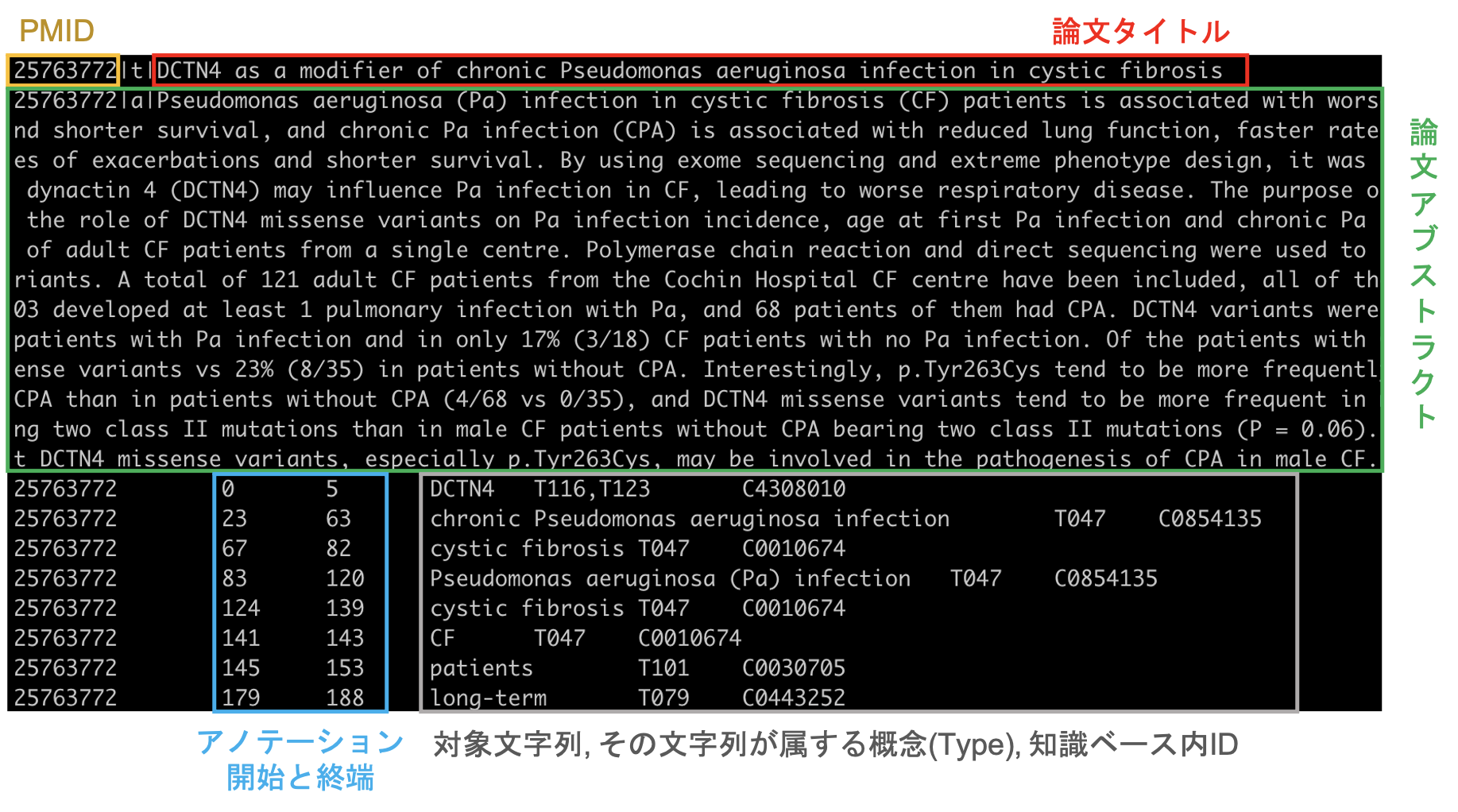
もう一度フォーマットを見てみましょう。例えば上記の cystic fibrosis が含まれる文章は、アノテーション対象論文のアブストラクトの1文目だと人が見れば瞬時に分かりますが、これを自動化するにはどのようにすれば良いでしょうか?
まず思いつくのは ".(ピリオド)"を区切りに文書を分割してしまうことです。しかし、上記の図を見れば分かるとおり、今回扱う文書のドメインは生物医学分野であるので、例えば p.Tyr263Cys などのようにピリオドを含む語彙も平然と登場します。これらの語彙を、他の区切り文字まで考慮して全てルール化するのは、現実的ではありません。
そこで本記事では、AllenNLPが開発しているspaCyモジュールの一つ、scispaCyを利用します。
scispaCyとは?
https://allenai.github.io/scispacy/ より
scispaCy is a Python package containing spaCy models for processing biomedical, scientific or clinical text. と公式で述べられています。この通り、科学論文や医療・生物医学論文に特化したspaCyモデルです。この他にも、略語解消などの機能も内包されています。
今回はscispaCyを用いて、PubTatorフォーマットをいい感じに文書分割してアノテーションを保持するツールを作成しました。
使い方
https://github.com/izuna385/PubTator-Multiprocess-Parser
上記にドキュメントを起こしました。
scispacyを並列処理で用いて、文章分割しつつアノテーションを各論文ごとに保存します。
アノテーション結果は./pickled_doc_dir/ 下に(pmid)+.jsonとして保存されます。
このjsonに含まれる lines 要素に、アノテーションが保存されます。
"C0007589\tT043\tcell differentiation\tthese result indicate that nonylphenol
diethoxylate have capability to affect <target> cell differentiation </target>
and development and have potentially harmful effect on organism because of its
unexpected impact on apoptosis ."
このように、アノテーションを含む一文まで切り出して、UMLS内ID、Type、アノテーションされた文字列、トークナイズされた一文が保存されます。アノテーションの周辺には <target>, </target> アンカーが挿入されます。
良ければ使ってみてください。