先日、HappyDBで『幸せな瞬間』を文書分類してみるという記事を投稿しました。
HappyDBという 『1日の間で良かったこと』の記述文を集めたデータセットに対して、文書分類を実施してみた という記事です。
HappyDBには、各記述文に、どういった種類の良かったことなのかというカテゴリ(例えば、Achievement(達成)やBonding(人との繋がり))がラベル付けされており、機械学習を適用することで、記述文からカテゴリを推定することをできるようになりました。
しかし、HappyDBは英文データセットです。
得られたモデルを試そうにも、英文を入力する必要があります。
英語で書いてそれなりにちゃんと推定してくれても、何だか達成感がない…。
そう、やっぱり、日本語で試したい…!
という訳で、タイトルの通りなのですが、
HappyDBを日本語に機械翻訳して、翻訳後の文章で文書分類を試してみました。
原文と翻訳文とで、文書分類の精度がどう変化するのかを見てみたいと思います。
もし、外国語のデータセットを翻訳して使用できるとしたら、選択肢が広がって嬉しい、ですよね!
本記事の内容が何らかの形で参考になりましたら幸いです。
対象読者
- 「英文データセットを翻訳して使うってどうなの?」と気になる方
- 自然言語処理の初学者
- 幸せな瞬間データベースHappyDBに興味がある方
概要
- DeepLによる機械翻訳
- GiNZAを用いた日本語の文書分類
- 原文と翻訳文とで精度を比較
- 得られたモデルで、実際に推論してみる
2~4に関しては、Jupyter Notebookとしてコードをまとめています。
また、HappyDBについては、本記事ではあまり説明しません。
こちら↓に記載していますので、ご興味ある方は併せてご参照ください。
DeepLによる機械翻訳
まずは、HappyDBの英文データを日本語翻訳していきます。
今回は、DeepLを使用してみます。
無料版は「1ヶ月あたり500,000文字まで」という制約はありますが、使いやすそう・精度も比較的よさそうということで選びました。文字数上限に達すると自動で使用停止となり、勝手に課金される心配がない、というのも選んだ理由です。
DeepLに関しては、@rihokさんがDeepL API を使ってみる に、使用方法を含めて、とても丁寧にまとめてくださっています。参考にさせていただきました。
ここでは、pythonでAPIを実行する部分だけ載せておきます。
import requests
url = 'https://api-free.deepl.com/v2/translate'
payload = {
'auth_key' : 'XXXXXXXXXX', # 取得した認証キーを記入
'source_lang' : 'EN',
'target_lang' : 'JA',
# 'formality' : 'less' # 日本語では使用できない
}
payload['text'] = src_text
r = requests.get(url, params=payload)
print(r.json())
# 入力: I finished the work project I was working on today.
{
"translations": [
{
"detected_source_language": "EN",
"text": "今日、取り組んでいた仕事のプロジェクトが終了しました。"
}
]
}
なお、formalityで、翻訳文の文調を、フォーマルな堅い感じか、カジュアルなくだけた感じか、どちらに寄せるかを選べるようなのですが、残念ながら日本語は対応していませんでした。
いくつか翻訳結果をみてみる
6,500程度、日本語サンプルが得られました。
いくつか翻訳結果を紹介します。
My sister came to visit me today
今日、妹が遊びに来たんです
Made some sales on Ebay that made my day.
Ebayで売り上げがあり、うれしい限りです。
My mother called me today with some great news.
今日、母から電話があり、嬉しい知らせがありました。
When my nine year old gave me a hug.
9歳の子にハグされたとき。
Introduced my friend to the new Zelda game today, he loved it so I'm glad I could be the one to introduce him to it :)
今日、友人にゼルダの新作を紹介しました。彼はとても気に入ってくれたので、私が紹介する側でよかったです :)
Drinking a ginger tea , thatas all there is , this week hasn't been very exciting or happy , in fact itas been rather tiring and stressful but itas fine , a cup of tea can fix anything.
今週はあまりエキサイティングでもハッピーでもなく、むしろ疲れてストレスフルな日々でしたが、大丈夫、お茶を飲めば何でも解決です。
ぱらぱらと見てみましたが、概ね良い感じに翻訳されていると感じました。
visit を「遊びに」と訳していたり、原文では一文のところを二文に分けていたり、自然な感じに訳されています。 普通にスゴイですね。
(HappyDBの問題ですが、that's が thatas となっている部分がありますね。事前に気付けず、今回はそのままDeepLに入力しています。)
When my house ready to live with my family
家族と一緒に住むための家ができたら
going to my friend home
友人宅へ
一応、イマイチな翻訳結果の例も載せておきます。
とは言っても、翻訳自体が問題な訳ではなく、「1日の間で良かったことは何?」という質問に対する回答としては微妙 というものです。
数もかなり少ないので、今回は特に対処せずそのままサンプルとして使用しています。
GiNZAを用いた日本語の文書分類
続いて、日本語の文書分類をしていきます。
ここでは、GiNZAを使用します。
GiNZAは、日本語自然言語処理オープンソースライブラリです。
(必要な機能としては形態素解析だけなので、MeCabやJanomeを使用することも可能です。)
また、文書分類には (1)Bag of Words(BoW)と (2)ロジスティック回帰 を用います。
5分割交差検証により、各カテゴリのPrecision/Recall/F1-scoreの平均を算出します。
(この辺りの詳細は、前回の記事に記載しています。)
それでは、Google Colab環境を想定して、コードを説明していきます。
GiNZAで分かち書き
まずは、GiNZAをインストール していきます。
# 今回は、従来型モデル、を使用
# cf. https://megagonlabs.github.io/ginza/
! pip install -U ginza ja_ginza
次に、文書分類の前処理として、入力文を スペース区切りの分かち書き に変換します。
この時、各単語は原形(lemma)に変換しておきます。
文書分類の中で単語の出現頻度を扱いやすくするためです。(例えば「歩い」「歩き」「歩く」を同じ「歩く」とすることで、活用による違いを吸収します。)
それでは、テキストを入力して、分かち書き形式に変換する関数を定義します。
# GiNZAで分かち書き
import spacy
nlp = spacy.load('ja_ginza')
def wakati_preprocess(text):
"""分かち書き. 各単語はlemma(原形)に変換しておく."""
doc = nlp(text)
lemmas = []
for sent in doc.sents:
for token in sent:
lemmas.append(token.lemma_)
return ' '.join(lemmas)
print(wakati_preprocess('すもももももももものうち。'))
# すもも も もも も もも の うち 。
最後に、メインである、文書分類のコードです。
sklearnをインポートし、ロジスティック回帰には LogisticRegression, BoWには CountVectorizerを使用しています。
CountVectorizerの引数について、細かくチューニングはしていません。stop_wordsを指定することで、もう少し精度が良くなる可能性はあります。
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
import pandas
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
# データ読み込みはここでは割愛
# jp_texts : 記述文(日本語翻訳)の list
# label_ids : カテゴリラベルID(0~6)の numpy.ndarray
# 分かち書きを適用する
docs_jp = [wakati_preprocess(text) for text in jp_texts]
# BoW (CountVectorizer)
bow_vectorizer = CountVectorizer(max_df=0.5, min_df=0.001, stop_words=[])
bow_vectorizer.fit(docs_jp)
x_data = bow_vectorizer.transform(docs_jp).toarray()
# ロジスティック回帰
logreg = LogisticRegression(max_iter=1000)
# 層化k分割交差検証
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
scores_all = []
for train_index, test_index in skf.split(x_data, label_ids):
x_train, x_test = x_data[train_index], x_data[test_index]
y_train, y_true = label_ids[train_index], label_ids[test_index]
# 学習
logreg.fit(x_train, y_train)
y_pred = logreg.predict(x_test)
# クラス別のPrecision, Recall, F1-scoreを計算
scores = []
scores.append(precision_score(y_true=y_true, y_pred=y_pred, average=None))
scores.append(recall_score(y_true=y_true, y_pred=y_pred, average=None))
scores.append(f1_score(y_true=y_true, y_pred=y_pred, average=None))
scores_all.append(scores)
# 各スコアの平均値を算出
scores_mean = np.stack(scores_all).mean(axis=0)
df_scores_mean = pd.DataFrame(scores_mean.T, index=LABELS_ALL, columns=['precision', 'recall', 'f1'])
df_scores_mean
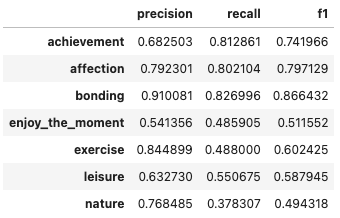
結果は上の表の通りです。
平均F1-score 0.654で、全体的にあまり精度は高くはないですね。
ただ、そもそもこのカテゴリ分類タスク自体が、絶対的正解がある訳ではなく、やや曖昧性を帯びているものなので、この結果も仕方ないかもしれません。
原文と翻訳文とで精度を比較
それでは、英語原文 と 日本語翻訳文 とで、文書分類の精度を比較してみます。
英語での文書分類は、ここでは割愛します。
基本的には、日本語の文書分類と同じで、違いは 分かち書き形式への変換が不要 という点ぐらいです。分かち書きが不要なのは、英文は元々スペース区切りで単語が記載されているためです。(詳細は→前回記事 or notebook)
では、2つの結果を比較してみます。
5%以上差分があった箇所は、色を塗っています。(赤は良い、青は悪い。)
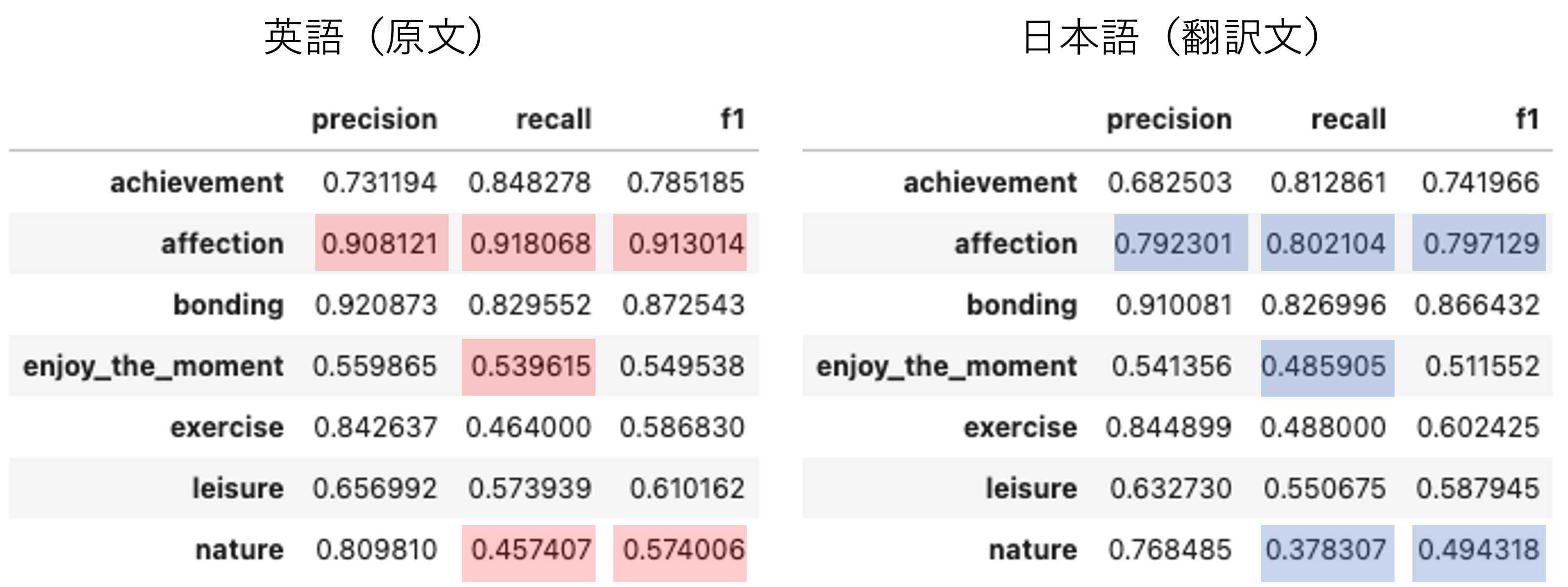
残念ながら、日本語翻訳文の方が総じて少し精度が下がっています。
F1-scoreの平均では、5ポイント程度の劣化(0.699→0.654)です。
特に、Affection(家族やペットとの愛)は、精度劣化が大きいですね。
明確な原因はわからないですが、想定される原因の1つに、日本語と英語での 家族の呼称の違い が挙げられます。
例えば、英語の oldest son は「長男」と訳されます。この場合、英語では son (息子)としてカウントされますが、日本語では「長男」としてカウントされ「息子」の場合とは異なる扱い となります。その結果、英語の son と比較して、日本語の「長男」や「息子」の影響力が弱まってしまったのかもしれません。
こうした現象は、Affectionに限らず、他のカテゴリでも生じている可能性はあります。
もし上記が正しければ、英語と日本語の違いが問題であり、翻訳したことの問題ではない 訳ですが、今回はそこは切り分けられていません。
また、日本語の文書分類では stop_words を指定していないため、それによる精度劣化という可能性もなくはないです。
いずれにせよ、多少の精度劣化はあるものの、翻訳文でも原文と同様の結果を得られている、と言ってよいレベルかな…とは思っています。
得られたモデルで、実際に推論してみる
ここまで読んでくださった方の中に、
「訓練・評価サンプルも翻訳文じゃ、評価として意味無いのでは…?」
と思われた方がいるかもしれません。
はい、その通りと思います…(´д`|||)
(当然、全く意味ないとは思ってはいないですが。)
ということで、得られたモデルを実際に試してみることで、使えそうかどうかを定性的に確認してみたい と思います。
以下では、入力した文章と、それに対する推定結果、を列挙しています。
(どうでもよいですが、実体験と架空のものが混在しています)
text : 昼ごはんに食べたカニクリームコロッケが美味しすぎて感動した
category : enjoy_the_moment(楽しい時間)
text : 読書の時間を持てたこと
category : leisure(趣味、娯楽)
text : 今日は久々に実家に帰ってきて両親とゆっくり夕ご飯を食べた
category : affection(家族やペットとの愛)
text : 今日は姪と遊んで楽しく過ごせた
category : affection(家族やペットとの愛)
text : 昨日は友人と久々に電話をして話をした
category : bonding(人との繋がり)
text : 今朝はちゃんと起きてランニングをした
category : achievement(達成)
text : 今朝はちゃんと起きてヨガをした
category : exercise(運動、エクササイズ)
それっぽく推定できていそうですね…!
最後の2例、「ランニング」と「ヨガ」とで推定結果が異なるのは、単純に、「ランニング」がBoWの集計対象の単語に含まれておらず、「ヨガ」は含まれていた、という違いから起因するものと考えられます。
ただ、「今朝はちゃんと起きてランニングをした」が Achievement(達成)、という結果自体は正しいと感じるので、問題ないかなと思います。
おまけ:寄与度の大きい単語をみてみる
最後に、得られた回帰係数から、寄与度の大きい単語を列挙してみたいと思います。
各カテゴリについて、「その単語があるとそのカテゴリに判定されやすい」 単語をみてみるといことです。
各カテゴリの回帰係数が大きい順に10個を表示しています。
()内の数字はオッズ比で、「その単語があると、何倍そのカテゴリとして判定されやすいか」を表しています。
# LABELS_ALL = ['achievement', 'affection', 'bonding', 'enjoy_the_moment', 'exercise', 'leisure', 'nature']
for label, coef in zip(LABELS_ALL, logreg.coef_):
print(f'{label:<15s} : ', end='')
top_idxs = np.argsort(coef)[::-1][:10]
for i in top_idxs:
word = vocab[i]
odds_ratio = np.exp(coef[i])
print(f'{word} ( {odds_ratio:0.1f} ), ', end='')
print('')
achievement : ビジネス ( 5.6 ), 掃除 ( 5.2 ), 探す ( 5.0 ), ボーナス ( 5.0 ), お客様 ( 4.7 ), 上司 ( 4.6 ), 倒す ( 4.4 ), mturk ( 4.4 ), ドル ( 4.3 ), 稼ぐ ( 4.1 ),
affection : 息子 ( 23.1 ), 家族 ( 18.2 ), 彼氏 ( 17.0 ), 恋人 ( 15.2 ), 赤ちゃん ( 9.7 ), 一緒 ( 9.4 ), 主人 ( 8.2 ), 両親 ( 8.1 ), フィアンセ ( 8.0 ), 寄り添う ( 7.1 ),
bonding : 友人 ( 173.3 ), 親友 ( 70.2 ), 友達 ( 57.6 ), 旧友 ( 41.2 ), 同僚 ( 38.6 ), ルームメイト ( 33.6 ), 仲間 ( 12.7 ), 近所 ( 8.0 ), 幼なじみ ( 6.3 ), 会う ( 6.2 ),
enjoy_the_moment : 眠れる ( 7.1 ), 教会 ( 4.1 ), 食べる ( 3.8 ), 失くす ( 3.7 ), 注文 ( 3.7 ), いただく ( 3.4 ), 楽しむ ( 3.4 ), 十分 ( 3.2 ), お気に入り ( 3.2 ), 荷物 ( 3.1 ),
exercise : ジム ( 51.6 ), 運動 ( 27.6 ), トレーニング ( 16.4 ), ヨガ ( 12.6 ), マイル ( 8.5 ), 走り ( 8.4 ), 走る ( 6.2 ), 出かける ( 4.2 ), 20 ( 3.7 ), ダイエット ( 3.4 ),
leisure : ゲーム ( 12.8 ), 読む ( 9.2 ), 聴く ( 7.6 ), エピソード ( 6.6 ), 寝坊 ( 6.4 ), 昼寝 ( 6.3 ), 観戦 ( 6.0 ), のんびり ( 4.8 ), 観る ( 4.5 ), チケット ( 4.1 ),
nature : 天気 ( 17.8 ), 降る ( 15.4 ), 気候 ( 8.9 ), ハイキング ( 8.4 ), 太陽 ( 8.1 ), 咲く ( 5.3 ), 植物 ( 5.3 ), 植える ( 4.9 ), 帰り ( 4.3 ), 散歩 ( 4.2 ),
割と納得感のある結果になっていると思います。
(気になるのは、enjoy_the_moment の「失くす」がよくわからないのと、exercise の「20」は前処理で対処すべき、ということくらいでしょうか。)
結論とまとめ
英文データセットを日本語翻訳して文書分類に使えるのかを試してみました。
残念ながら、英語原文と比較すると、
日本語翻訳文では総じて低精度、という結果でした。
とは言え、F1-score平均で5ポイント程度の劣化でしたし、
劣化の原因が、翻訳ではなく、言語の違いに依るものの可能性もあるので、
「英文データセットを翻訳して使うってどうなの?」 の答えとしては、
『それなりに使える』
と言ってよいのかなと思います。
ただ、今回のこの結論は、(1)文書分類タスクだから、(2)方式がBoWだから、という背景があると考えています。
(1) 文書分類だから
文書分類では、翻訳文が直接影響するのは入力だけ です。一方で、文章要約や対話文生成といった、文章生成タスクにおいては、翻訳文が出力にも影響する ので、使い所や使い方が限られてくると思われます。
(2) 方式がBoWだから
今回用いた方式は BoW (Bag of Words) という 単語ベースの方式 でした。そのため、文章としての正しさや自然さは、精度にほとんど影響がなく、翻訳文でもそれなりの精度が得られたものと思います。
BERTに代表される深層学習の方式では、単語や文章間の繋がりがより影響してくると考えられるので、英語原文と日本語翻訳文とで今回よりも大きな精度劣化が生じるかもしれません。
という感じで終わりたいと思います。
私としては、
やっぱり、日本語で試したい…!
という思いを果たせたので満足しています( *¯ ꒳¯*)
最後までお読みいただきありがとうございました。
本記事の内容が何かの参考になりましたら嬉しいです。