はじめに
本記事では、spaCyとGiNZAを使った日本語の自然言語処理の手順を紹介します。
コードの部分ではspaCyのクラスがわかるように示していますので、ぜひ公式ドキュメントも参照ください。
想定する読者
以下の人を想定して書いてます。
- 日本語の自然言語処理に興味がある人(※自然言語処理に関する知識は必要ないです。)
- Pythonのソースコードが読める人
使用するライブラリ
今回はspaCyとGiNZAという2つのライブラリを使用します。
spaCyとは
spaCyは高度な自然言語処理を行うためのライブラリです。
自然言語処理では対象とする言語(日本語や英語)によって必要な処理や複雑度が変わるのですが、spaCyは多言語対応を意識して設計・開発されており、そのアーキテクチャから学べることも多く非常に良くできたライブラリです。
spaCyでは訓練済みのモデルを読み込むことで多言語の自然言語処理に対応します。
GiNZAとは
GiNZAは日本語の自然言語処理を行うためのライブラリでリクルートと国語研が共同で開発したライブラリです。
GiNZAはspaCyのAPIを使用して学習されており、spaCyからモデルをロードして使用することができます。
spaCyを使った日本語自然言語処理
spaCyを使った自然言語処理の手順やできることを実際に動かしてみながら理解しましょう。
実行環境にはGoogle Colaboratoryを利用します。
Google ColaboratoryにはspaCyがデフォルトでインストールされています。
なので利用するGiNZAの日本語モデルをpip installで取得します。
今回はja_ginzaのモデルを扱います。
pip install ja-ginza
なお補足ですがGoogle Colaboratoryでpip installコマンドを実行するには先頭に!をつけます。
!pip install ja-ginza
ja_ginzaについて簡単に説明します。
ja_ginzaは国語研のデータセットを畳み込みニューラルネットワーク(CNN)で依存関係ラベリングや単語依存構造解析などのタスクを学習させたモデルになります。
spaCyからGiNZAのモデルをロードする
ではGiNZAのモデルをロードしてみましょう。
以下のコードでja_ginzaモデルをロードできます。
(Google Colaboratoryを使用していてモデルのロードがうまくいかない場合はランタイムから「ランタイムの再起動」をして再度pip installをすることで解消する場合が多いです。)
import spacy
# Languageクラス 変数名をnlpで宣言するのが一般的(spaCy推奨)
nlp: spacy.Language = spacy.load('ja_ginza')
spaCyではまずLanguageクラスを生成します。
Languageクラスはテキスト文をDocクラスを変換する責務を持ちます。
この部分はspaCyの公式ドキュメントでアーキテクチャとして解説されています。
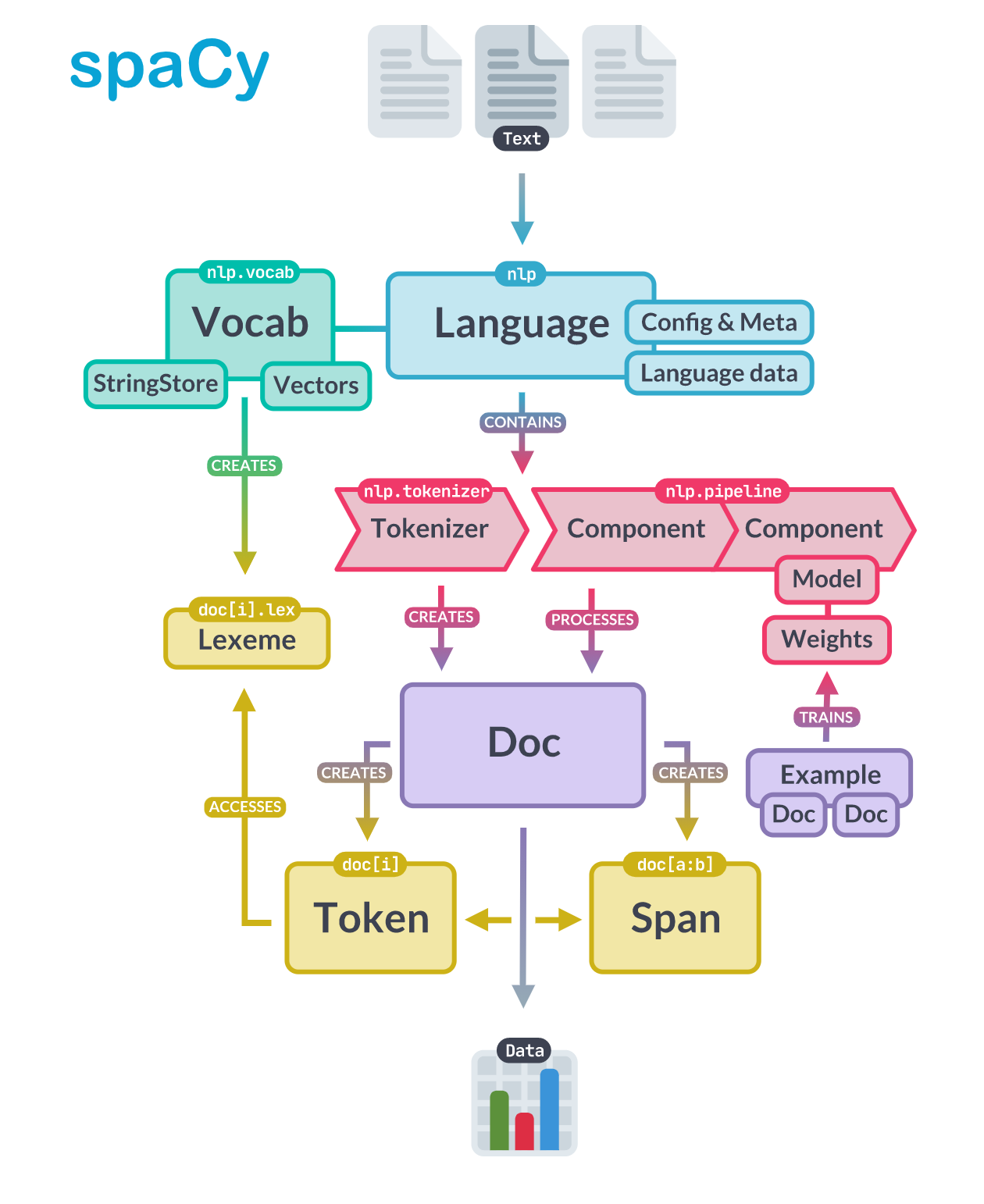
出典元 spaCy - Library Architecture, https://spacy.io/api
では実際に動かしながらLanguageクラス以外のクラスの役割もみていきましょう。
テキスト文からDocクラスを生成する
生成したLanguageクラスのインスタンスにテキスト文をに与えることでDocクラスを生成します。
# text を Doc クラスに変換する
text: str = '錦織圭選手はテニスが大好きです。'
doc: spacy.tokens.doc.Doc = nlp(text)
# Doc クラスは Token クラスのイテレーターになっている
for token in doc:
print(token.text, type(token)) # token.text は日本語の形態素の単位
錦織 <class 'spacy.tokens.token.Token'>
圭 <class 'spacy.tokens.token.Token'>
選手 <class 'spacy.tokens.token.Token'>
は <class 'spacy.tokens.token.Token'>
テニス <class 'spacy.tokens.token.Token'>
が <class 'spacy.tokens.token.Token'>
大好き <class 'spacy.tokens.token.Token'>
です <class 'spacy.tokens.token.Token'>
。 <class 'spacy.tokens.token.Token'>
spaCyではテキスト文からDocクラスを生成した段階で形態素解析や品詞のタグ付けなどの処理が終わっています。
Docクラスを利用して色々みてみましょう。
単語依存構造の可視化
spaCyではdisplacyモジュールが用意されており、Docクラスの解析結果を可視化(HTML/SVG出力)することができます。
手始めに解析したDocクラスから単語依存構造の可視化してみましょう。
from spacy import displacy
# 依存関係の可視化(jupyter=TrueとすることでNotebook上で表示できる)
displacy.render(doc, style="dep", options={"compact":True}, jupyter=True)
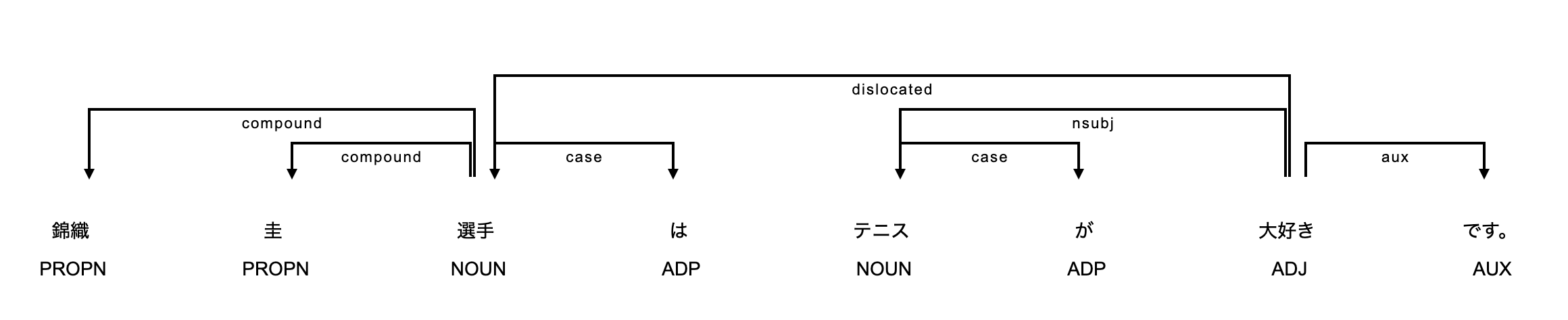
それぞれの単語(形態素)の下に表示されているのは品詞タグです。矢印の下に表示されているのは係り受けタグになります。
spaCyで使われる品詞タグと係り受けタグは、Universal Dependencies: UDに基づきます。
UDは異なる言語間で共通化したツリーバンクを作成するプロジェクトで品詞や係り受けの関係について一貫したタグをつけるためのフレームワークになります。
品詞タグはUniversal POS tagsで、係り受けタグUniversal Dependency Relationsです。
これらの品詞タグと係り受けタグについては以下の記事や論文で日本語の役割が書いてあります。
日本語 Universal Dependencies の試案, https://www.anlp.jp/proceedings/annual_meeting/2015/pdf_dir/E3-4.pdf
文の構造を読み取るには、ルートとなる単語から矢印を追うだけです。
今回の「錦織圭選手はテニスが大好きです。」という文章のルートとなる単語は「大好き」になります。
ルートとなる単語から形成される最も短い文章は「大好きです。」になります。
そして可視化された構造から文章において”何”を示す部分は「テニスが」となり「テニスが大好きです。」と読み取れます。
同様に"誰"を示す部分は「錦織圭選手は」となり「錦織圭選手はテニスが大好きです。」となります。
エンティティ抽出
エンティティとは実世界のオブジェクトを指す単語のことです。
spaCyでは先ほどの依存構造の可視化と同様にdisplacyモジュールを使って、テキスト中に含まれるエンティティをハイライトして表示することができます。
(styleの引数をentにするだけです。)
# エンティティの可視化(jupyter=TrueとすることでNotebook上で表示できる)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

このように「錦織圭」の部分はPersonで人を表す単語、「選手」の部分はPosition_Vocationで職業を表す単語、「テニス」はSportとスポーツを表す単語であると抽出できます。
これらのエンティティ抽出はテキストをDocクラスにした段階で済んでおり、Docクラスのentsプロパティから取り出すことができます。
以下はその操作を実現するPythonのコードになります。
for ent in doc.ents:
print(ent.text, type(ent))
錦織圭 <class 'spacy.tokens.span.Span'>
選手 <class 'spacy.tokens.span.Span'>
テニス <class 'spacy.tokens.span.Span'>
エンティティは複数の単語から形成される場合もあるので型はSpanクラスになっています。
Spanクラスは初めて出てきましたがspaCyのアーキテクチャにあるようにDocクラスのスライスです。そのためDocクラスと同様にTokenクラスのイテレーターになっています。
今回の処理だと意味はないですが、以下のような二重構造のfor文を使ってエンティティに含まれるTokenクラスを操作することもできます。
for ent in doc.ents:
for token in ent:
print(token.text, type(token))
錦織 <class 'spacy.tokens.token.Token'>
圭 <class 'spacy.tokens.token.Token'>
選手 <class 'spacy.tokens.token.Token'>
テニス <class 'spacy.tokens.token.Token'>
名詞句の抽出
ヒトは文に含まれる名詞を把握するだけで、なんとなくでも内容を把握することができるので、テキスト文の内容把握したいようなユースケースでは、自然言語処理によってテキスト文から名詞だけを抽出するという操作がよく行われます。
spaCyではこのようなユースケースに応えるように名詞句を簡単に抽出できます。
"句"は"単語"よりも上位の概念です。
文の中で品詞の役割を果たす単位が"句"になります。
先ほどの文章とは別のテキスト文「錦織圭選手は偉大なテニス選手です。」で考えます。
spaCyではDocクラスを生成した段階で名詞句を抽出しnoun_chunksプロパティに保持しています。
doc2 = nlp('錦織圭選手は偉大なテニス選手です。')
# noun_chunksでテキスト文に含まれる名詞句を取り出す
for chunk in doc2.noun_chunks:
print(chunk.text, type(chunk))
錦織圭選手 <class 'spacy.tokens.span.Span'>
偉大なテニス選手 <class 'spacy.tokens.span.Span'>
今回のテキスト文から名詞だけを取り出すと「錦織」「圭」「選手」「テニス」「選手」の5単語になりますが、名詞句の単位で取り出すと「錦織圭選手」と「偉大なテニス選手」の2つの句にになります。
なおこの名詞句も先ほどのエンティティと同様にSpanクラスになります。
一応、品詞タグの情報に基づいて文に含まれる名詞だけを抽出して結果を見ておきましょう。
# 品詞タグから名詞の単語を抽出する
for token in doc2:
if token.pos_ in ['NOUN', 'PROPN']: # NOUNが名詞、PROPNが固有名詞
print(token.text, token.tag_, type(token))
錦織 名詞-固有名詞-人名-姓 <class 'spacy.tokens.token.Token'>
圭 名詞-固有名詞-人名-名 <class 'spacy.tokens.token.Token'>
選手 名詞-普通名詞-一般 <class 'spacy.tokens.token.Token'>
テニス 名詞-普通名詞-一般 <class 'spacy.tokens.token.Token'>
選手 名詞-普通名詞-一般 <class 'spacy.tokens.token.Token'>
想定通りに「錦織」「圭」「選手」「テニス」「選手」の5単語になりましたね。
これらは単語なので型はTokenクラスになります。
用途にもよりますが、テキストの内容を把握するような場合は名詞句で取り出した方が目的にあった形で抽出できることが多いはずです。
類似度の計算
次に与えられた2つの文章の類似度を求めてみましょう。
自然言語処理では文章の類似度の判定では、基本的にベクトルのコサイン類似度を用います。
コサイン類似度は0〜1までの値を取り、1に近いほど2つの文章が似ているという尺度になります。
spaCyではDocクラスを生成した段階でテキスト文のベクトルへの落とし込みが完了しています。
そしてDocクラスのsimilarityメソッドを呼び出すだけでコサイン類似度を求めることができます。
先ほどまでの2文「錦織圭選手はテニスが大好きです。」と「錦織圭選手は偉大なテニス選手です。」のコサイン類似度を求めてみましょう。
print('doc1',doc.text)
print('doc2',doc2.text)
# 2つの文の類似度を求める
print('cos類似度:', doc.similarity(doc2))
doc1 錦織圭選手はテニスが大好きです。
doc2 錦織圭選手は偉大なテニス選手です。
cos類似度: 0.9598306277628903
コサイン類似度は0.959となり、この2文は意味的に似ていることがわかります。
文章中の重要部分の抽出
ここまでで紹介した「名詞句の抽出」と「類似度の計算」を組み合わせて文章中の重要部分を抽出するアプローチを実践してみましょう。
ここでは以下の方法で得られる部分を文章の中で重要度が高い部分として扱います。
- 文章中から重要部分の候補として名詞句を取り出す。(
Spanクラス) - 1で取り出した名詞句と文章全体の類似度を求め、類似度が高い名詞句が文章の重要部分である。
今回はYahooニュースの中で適当に上位にあった「阪神がリーグ優勝を逃した」という内容の記事の文章を使います。
[利用記事], https://news.yahoo.co.jp/articles/4404781e0936f61df78b6d84efa92808f4046dac
text3 = '''
阪神がリーグ優勝を逃した。すでに勝利で試合を終えたヤクルトがマジック1としており、この試合に敗れた瞬間、ヤクルトの6年ぶりの優勝と阪神のV逸が決定。阪神にとって16年ぶりの夢が、本拠地で散った。
ミスで無駄な点を与える、今季を象徴するような戦いぶりだった。二回1死一、二塁、木下拓の三ゴロで併殺コースは、二塁手・糸原が一塁へ悪送球する適時失策で先制点を献上した。
0-1の五回は無死から2番手・及川が、先頭・岡林をスライダーで空振り三振に仕留めたが、ワンバウンドした球を捕手・坂本が一塁ベンチ方向にそらし、振り逃げで出塁を許した。(記録は投手の暴投)この後、四球、安打で1死満塁として三番手・馬場に交代。馬場は2死後、大島に2点適時打を浴びた。
負けられない1戦。矢野監督は二回、2死一、三塁の好機に、先発の青柳に代打・小野寺を送る積極采配。結果は遊飛に終わった。決死のリレーも及川が3イニング目につかまった。今季最終戦だが、“第2先発”を任せられる他の先発陣をベンチにはスタンバイさせる策を取っていなかった。
打線も沈黙した。糸原が猛打賞と気を吐いたが、その他は大山の1安打のみ。計4安打完封負けで今季を終えた。
今季は佐藤輝、中野、伊藤将のルーキートリオが大活躍。マルテ、スアレスら外国人も機能し、5月まで破竹の勢いで白星を重ねた。一時は2位に最大7ゲーム差をつけ、独走の雰囲気も漂った。
だが、打線の勢いが低下し、夏場に失速。8月末に首位の座を奪われた。10月は投手陣の奮闘もあり、ヤクルトに負けじと貯金を増やした。最後までVへの執念もみせたが、わずかに頂点へ届かなかった。
矢野監督は試合後の挨拶で「今日のこの最後の試合、こういう試合で勝ちきれる、もっともっといいチームに、もっともっと強いチームになっていけるよう。新たなスタートとして、この悔しさを持って戦っていきます」と今後に向けて語った。
'''
doc3 = nlp(text3)
# 重要部分をresultsに保存する
results = []
for chunk in doc3.noun_chunks:
results.append((chunk.text, chunk.similarity(doc3)))
# 上位10個の名詞句を表示する
print(sorted(results,key=lambda x: x[1],reverse=True)[:10])
('無駄な点を与える、今季を象徴するような戦いぶり', 0.8716695222240806)
('試合を終えたヤクルト', 0.8082536851795971)
('代打・小野寺を送る積極采配', 0.7806458469021531)
('新たなスタート', 0.7030685619184737)
('もっともっと強いチーム', 0.6992613871249276)
('「今日', 0.6967788923050456)
('こういう試合', 0.6951281994681076)
('三番手・馬場', 0.6915117712597708)
('もっともっといいチーム', 0.6817258599487056)
('先発陣をベンチ', 0.6815011465308766)
非常に単純な方法ですが「無駄な点を与える、今季を象徴するような戦いぶり」という部分が文章の中で最も重要度が高いと抽出することができました。
ただしspaCyのDocクラス、Spanクラスのベクトル表現は標準では含まれている各Tokenクラスの値の平均を取得するため、今回のような単純な方法だと長いSpanほど重要と判定されていることは注意が必要です。
おわりに
本記事ではspaCyとGiNZAを使った日本語の自然言語処理の手順を紹介しました。
GiNZAでは今回扱ったja_ginzaの他にTransformerを利用したja_ginza_electraという日本語モデルも提供されていますので、そちらを利用した内容も今後紹介できればと考えております。