1兆レコードの分析処理基盤@Azure

この記事は,Microsoft Azure Advent Calendar 2018,2日目のエントリーです.
1,目次
- 1,目次
- 2,はじめに
- 3,Azure Databricks(ETL,Analyze)
- 4,Azure Batch AI
- 5,Azure COSMOS DB(Gremlin API)
- 6,Azure SQL Database
- 7,Azure SQL Data Warehouse
- 8,今後の展望
2,はじめに
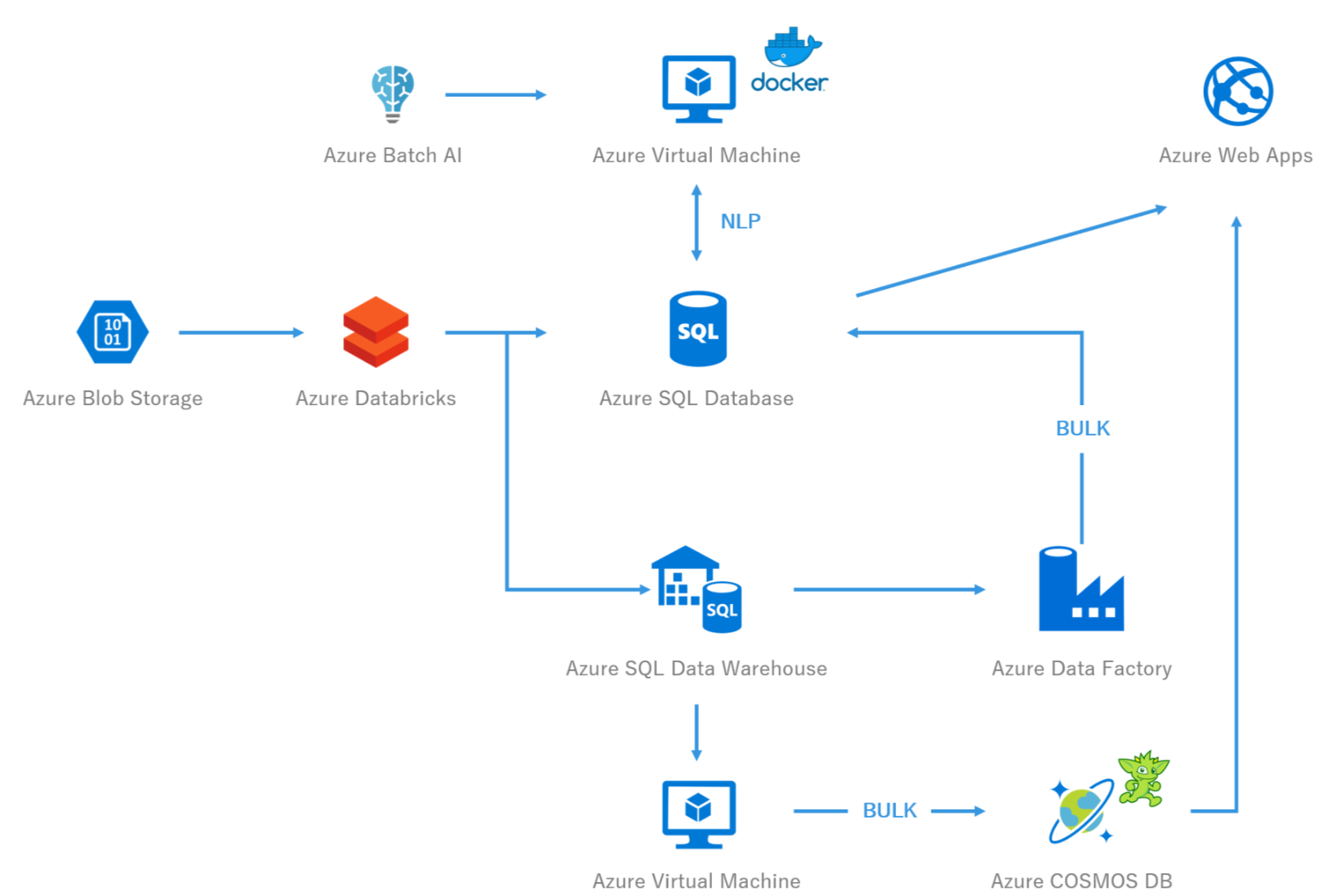
図1 システム構成図
tatsuya.takahashiです.
「いつか分析用に」とデータをため込んではいるが,それを「何の目的」で,「どのように分析すれば」よいか頭を悩ませる事は多いのではないでしょうか.1
本記事は,「どのように分析すれば」のところにフォーカスして,Azureのサービスを活用したビッグデータの分析基盤について書いたものです.
メインコンテンツは,いわゆるやってみた系2ではなく,私が実際の業務で,大量の非構造のテキストデータ(口コミや,ソーシャルメディアの投稿テキストのようなものを想像してください)を分析し,アプリケーションで可視化しようとした際に遭遇した課題の共有と,結論として,現時点での構成の紹介です.なお,可視化の部分には触れません.
執筆動機は,後述する悩みを抱えている方の助力になればという願いと,本記事を読んでいただいた方にご指摘・アドバイスをいただき,より良いアプローチを模索したいというものです.
-
本記事のユースケース
- 大量の非構造のテキストデータを読み込み,グラフ構造に落とし込む.そのデータを,Webアプリケーションで可視化する.
- テキスト処理なので,超高次元の疎行列が発生するため,メモリの最適化が特に必要であった.
-
本記事が向いている人
- 大量のデータを分析したいが,現状のサーバーリソースではスペックが足りず困っている.または,そもそも何をどのように構築したらよいか皆目見当もつかない.
- 分散処理基盤を構築したいが,インフラ・ミドルウェアの知識に乏しい.または,インフラのスキルを持つ人員をアサインできない.
- Azure Databricksについてざっくり知りたい.
-
本記事が向いていない人
- データをどのように活用すればよいか頭を悩ませている.
- Sparkのチューニングや,機械学習のアルゴリズムについて知りたい.
- データをどのようにため込むべきかを知りたい.
3,Azure Databricks(ETL,Analyze)
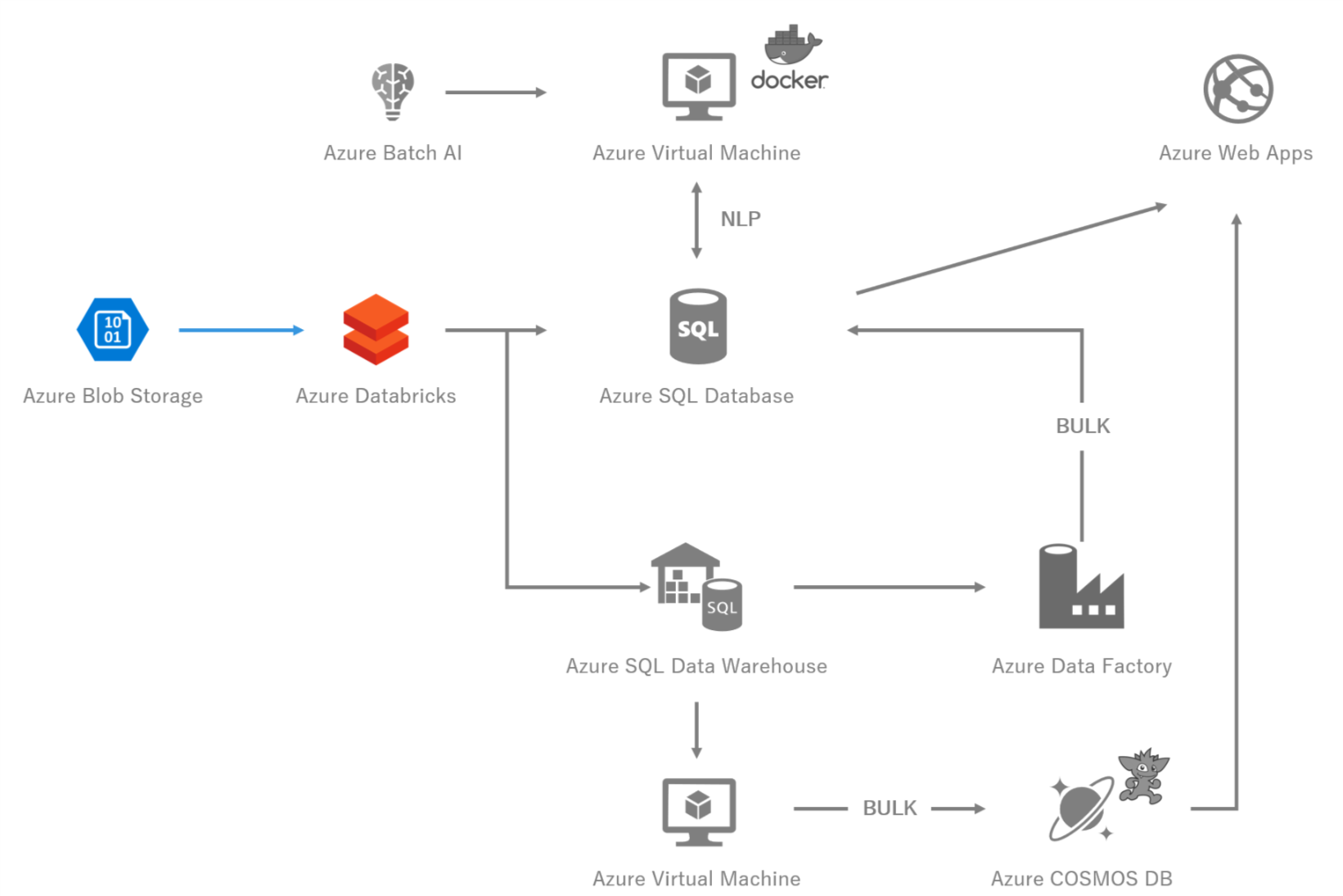
図2 システム構成図 -Azure Databricks-
3-1,Azure Databricksとは
まず初めに,Azure Databricksです.
Databricksは,Apache Sparkのクリエイターが出資したDatabricks社が提供する,クラウドベースでApache Sparkを活用できるようにしたソフトウェアです.3
DatabricksをAzureのVM上で実現し,それをPaaSとして提供するものが,Azure Databricksです.なので,Azure Databricksと,Databricksは厳密に言い分ける必要があります.
本記事のユースケースでは,Azure Databricksを,主にETLと,分析用途で使っています.
ETLとは,Extract・Transform・Loadの略で,その名の通りデータを抽出・変形(FromからToの形に)・読み込み(保存)することを指します.
ETLでは,凝った変形がいらない場合は後述するData Factoryの方が向いている場合もあります.
3-2,Azure Databricks + Sparkで知っておくべきこと
分散処理に対する誤解
Apache Sparkとは,メモリ上で分散処理を行ってくれるOSSです.
分散処理というと,まずはその基盤の構築から,また独自のプログラムの書き方など,とても敷居の高そうな印象があります(実際,インフラレベルから構築するのは,インフラ・ミドルウェア・ネットワークの知識が不可欠です).
しかし,それらの敷居を大きく下げてくれるのが,Azure Databricksです.
Azure DatabricksはPaaSなので,原理原則,低レイヤ層のことはAzureにお任せできます.
我々が低レイヤ層で気を使うべきことは,主にドライバーマシンのスペック,ワーカーのスペックとノード数,Sparkのチューニングのみです.
しかもそれらはGUI上でボタン1つで実行できます.スペックが足りなくなってきたら,ノード数を増やして再起動するのみです.
それにより,我々はコアなアプリケーションの開発に注力することができます.
また,プログラミングについても,Scala,Python,SQLなどをインターフェースとして用いることができます.
特にPythonでは,pandasのDataframeと似たような概念が存在するため,多大な学習コストをかけることなく,Sparkプログラミングに取り組むことができます.
価格はVMより高い
見積時に気を付けなければいけないのは,裏側はAzure Virtual Machineであれど,価格はそれにDBUという料金が加算されます.
更に,Azureの価格の見積機能を利用すると,2018年12月1日現在,DBUが利用できないというバグになっていますが,日本リージョンを使用してもきっちりDBU料金は加算されるので,注意が必要です.4
Sparkで最低限知っておくべきこと
「分散処理に対する誤解」の節で書いたことと背反してしまう部分もあるのですが,Sparkでプログラムを書いたからと言って,いきなりパフォーマンスが向上し,処理が早く収束する,ということはありません.最低限知っておくべきことがあり,それらをうまく活用することで,分散処理基盤の恩恵に与ることができます.
遅延評価とRDD,変換とアクション
Sparkのアーキテクチャについては,本記事の範囲を超えるので割愛しますが,下記記事が大変参考になります.
Apache Spark で分散処理入門
最低限,RDDとは何か,そして遅延評価の仕組みについては知っておく必要があります.
例えば,
# 単語のリストの,最初の単語を取得し,新しい列に追加する
df = df.withColumn("firstword", split(col("words"), ",").getItem(0))
上記の処理は,データフレームのwords列の単語リストをカンマで分解し,最初に登場する単語をfirstword列として新たに追加するというものです.
こちらは,データフレーム内のデータ件数が,100件であろうが,100,000件であろうが,処理時間はほぼ変わらず,一瞬で終了します.
Pythonコーダーにはにわかには信じがたい結果ですが,これはSparkのRDDの機構が大きく寄与しています.
ここで行った処理は「変換」であり,あくまで処理の手順をRDDに記録したのみとなります.
その後,アクション(count()や,collect()など)を行った際に,実際にこの処理が実行されます.
なぜこのような機構かというと,SparkはRDDとして複数の変換を記録したうえで,アクションを行う際に積み上げた変換を最適化し,実行するためです.
たとえば1億件のテキストデータを読み込んで(RDDインスタンス作成),フィルターして(変換),機械学習(アクション)にかける一連の処理があったときに,普通のPythonでは順序通り実行されますが,Sparkではテキストを読み込みながらフィルターをかけるため,処理量がO(n)ではなく,あくまでフィルター対象のデータ量のみになる,といった具合です.
このあたりの詳細は,オライリー社の初めてのSparkという本がとても役に立ちます.
少し古い本であり,当時Dataframeという概念がなかった頃のものですが,国内有識者による大変良質な加筆が加えられており,おすすめです.
永続化
前述の通り,Sparkには変換とアクションがありますが,アクションが行われるたびに,1から変換が行われます.
同じデータを繰り返し処理したい場合は,必ずキャッシュを保存してください.
Apache Sparkとデータの永続化
Collect()はよほどじゃない限り実行しない
Sparkのデータフレームは,複数のWorkerに分散して保持されています.
それをCollect()すると,一気にすべてのデータを1台のDriverに持ってくることになるため,あっという間にメモリ資源が枯渇してしまいます.
ループで処理したいシチュエーションで安易に用いたくなりますが,RDDの変換や,ブロードキャスト,アキュムレータを駆使し,分散環境の恩恵をフルに生かすようなプログラミングを心がけることが,処理高速化への第1歩です.
あらかじめMLLibの仕様を理解しておく
Sparkには,分散環境の恩恵を生かしつつ機械学習を行うMLLibというライブラリがあります.
大量データを分散して格納できるデータフレームをInputとし,なおかつ処理もパラレルで行われるため,大変効率がよいです.
ただし,良いことばかりではなく,できることには限りがあります.
sklearn相当のものを期待すると,実はそれらの機能が無く,途中でまた別のアルゴリズムを検討することになってしまします.
例えば,MLLibにはKneighborが存在しません.超高次元のベクトルの近傍を探索する課題を解く場合,代替する手段もありますが,それがk近傍法と等価であるとは限らないので,結果を注意深く観察する必要があります.
Python or Scala
Sparkの多くのドキュメント(Stackoverflowや,海外有識者のブログ)がScalaで書かれているような印象です.5
Sparkのコアな部分は,JAVA/Scalaで書かれており,JVM上で動作するので,親和性が高いのはScalaです.
事実,一昔前はScalaの方が圧倒的に速かったのです.
しかし,Dataframe登場以降は,その差は大分縮まっています.6
すなわち,慣れている言語で良いと考えます.
ただし,Spark向け外部ライブラリなどでは,Scalaしかないものがあったりするので注意が必要です.
例)azure-sqldb-spark
4,Azure Batch AI
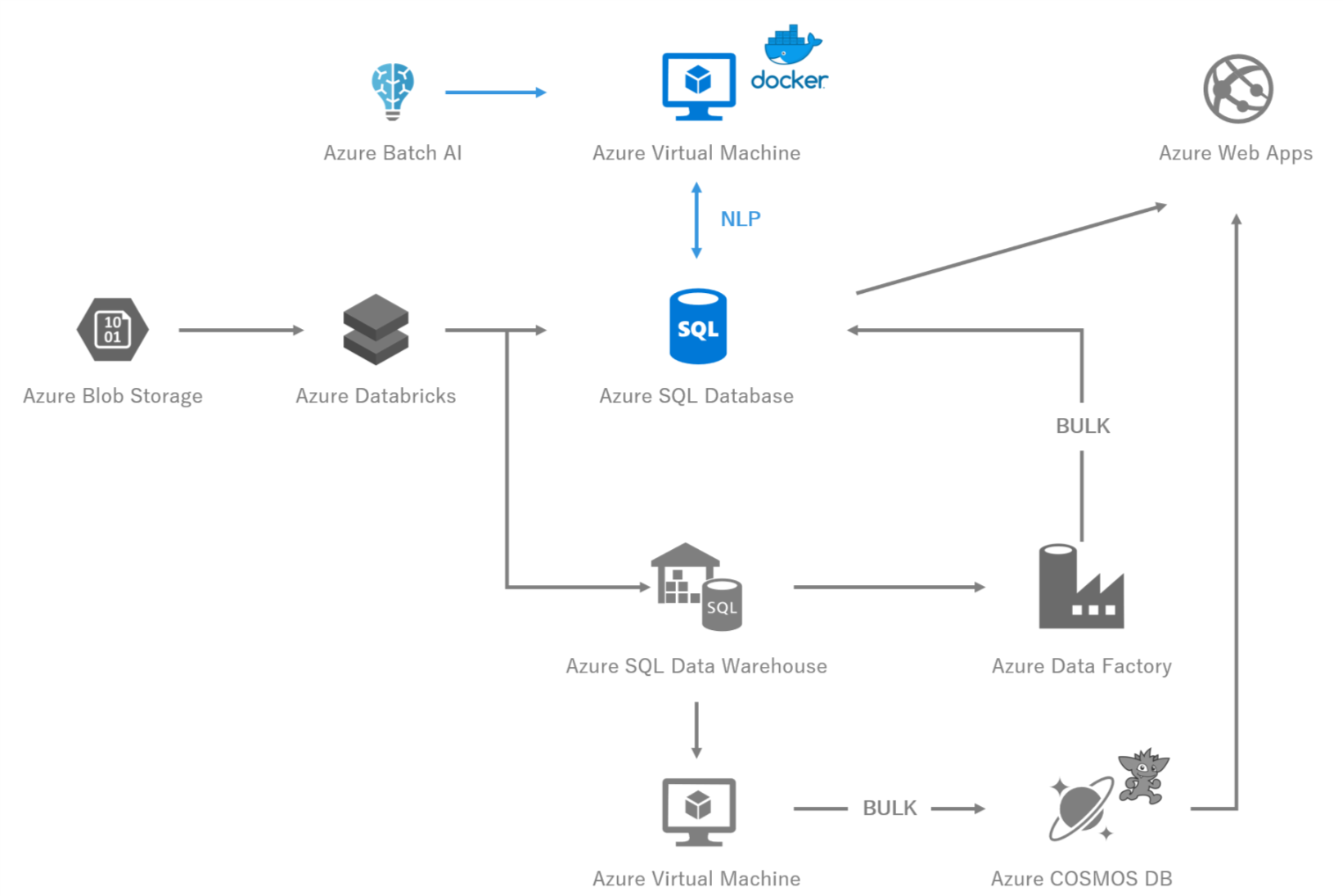
図3 システム構成図 -Azure Batch AI-
4-1,Azure Batch AIとは
Azure Batch AIとは,その名の通りBatch処理をVM上で実現してくれるサービスです.
Azure Batch AI自体もクラスタ環境を組んで処理してくれます.
しかし,今回Batch AIを用いたのはそれ目的ではなく,VM上で実現したかった処理をBatch化したい,かつ廉価版VM7を利用したかった,というものです.
4-2,NLP
今回,日本語の自然言語処理の前処理を行うにあたり,形態素解析+独自の専門用語辞書を必要としました.
しかし,上記要件がDatabricks上で満たせなかったので,Docker上に実装し,Azure Container Registryにプッシュし,Batch AIで実行しています.
少し話がそれますが,Azure上の何らかのリソースにDockerをPullする場合は,絶対的にAzure Container Registryを利用することをお勧めします.Docker Hubからのプルに比べて,ダウンロード時間が劇的に高速化します.
話を戻しまして,Databricksでは,pip installなどの取り込みはできるのですが,OSレベルでのインストールは,Databricksのポータル経由では原則できません.8
今回は形態素解析にmecabを利用したかったこと(janomeでは現実的な時間で処理が終了しなかったため)と,専門用語の辞書が巨大すぎて,Databricks上で保持するにはコストに見合わなかったため,このような方式にしています.
なので一旦DatabricksでETLしSQL Databaseに保存し,それをBatch AIで形態素解析した結果を保存し,またDatabricksに処理を戻すという,いささか複雑な流れになっています.
5,Azure COSMOS DB(Gremlin API)
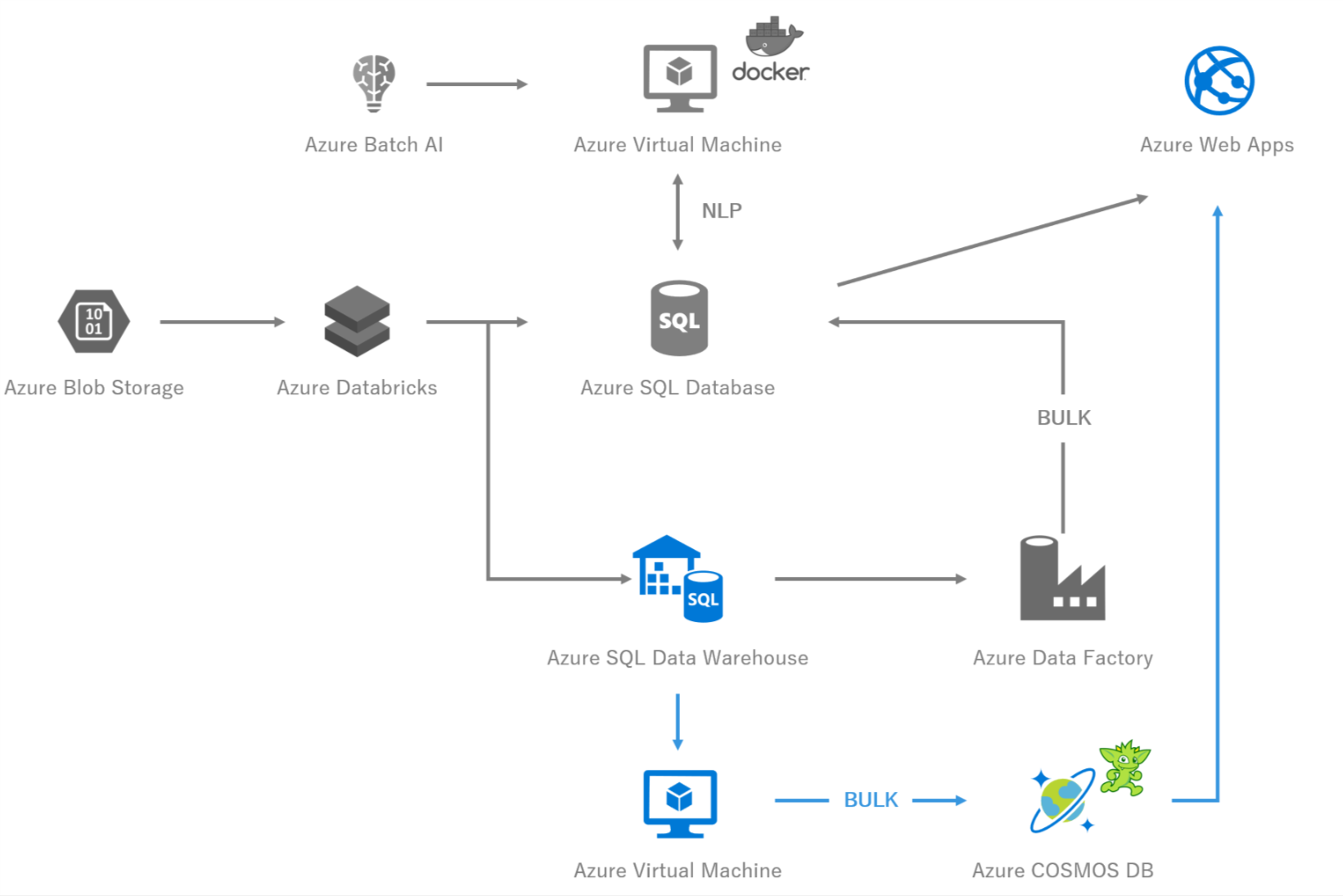
図4 システム構成図 -Azure COSMOS DB-
5-1,COSMOS DBとは
あえて説明する必要もないほどに有名なサービスですが.グローバルに分散するデータベースです.
今回はグラフ処理を高速に行う必要があったため,COSMOS DBのGremlin APIを採択しました.
グラフデータとは,例えば人の「ノード」と,人と人の関係性の「エッジ」からなるデータ集合のことです.

図5 グラフの例
5-2,COSMOS DBの難解さ
単純にリソースを作成し,RUを設定し,使う分には問題ないのですが,大量データを扱う上ではもう少しRUやパーティションに敏感になる必要があります.そうしないとあっという間にハイコストになってしまい,予算を消費してしまいます.
私が特に理解に苦しんだところを共有しますので,それが誰かの助けになれば幸いです.
物理パーティション,論理パーティション,RUの関係
下記の通りです.下記のルールは確実に理解しておく必要があります.
- 設定したRUの数によって,物理パーティションの数がCOSMOS DBによって自動的に決まる.
- 1物理パーティションあたり,100RUが必要.
- 論理パーティションは,1GB以内に収める必要がある.
上記のルールのポイントは,RUを上げるにつれて,最低限ラインのRU値も比例してあがってしまう,ということです.
なぜなら,RUを上げると,物理パーティションの数が増え,1物理パーティション100RUが必要なので,物理パーティション数*100RUが最低ラインになるからです.
すなわち,INSERTの時だけ一次的にRUを上げて,運用時は下げようとしても,元のRUには戻せない可能性があります.
具体例)
- もともと400RUに設定していた.
- INSERTを高速にしたいため,一時的にRUを1000,000RUに設定した.
- INSERTが終了したため,RUを400に戻そうとしたところ,17,000以下にはできないというエラーが出た.
上記のようなことが,実際に発生します.
なお,物理パーティションの算出数は公開されていない9ため,見積時には注意深く下限RUを見極める必要があります.
とはいえ,400RUでは大量のデータをINSERTするにはあまりにも低スペックすぎます.
そのため,Bulk Insert用のやり方が公式から展開されています.
Bulk Insert
COSMOS DBでは,RUを超えたリクエストが来ると429のエラーを返却します.
なので,大量データをINSERTするときは,エラーをうまくCatchし,リトライする必要があります.
それらをうまくキャッチアップし,なおかつRU最大限まで活用してBulk Insertする方法が,公式から掲示されています.
https://docs.microsoft.com/ja-jp/azure/cosmos-db/bulk-executor-overview
また,Azure Virtual Machineから,かつ同一リージョンから行うことにより,処理が最適化すると書かれている通り10,私が実際に試してみても,ローカルのマシンから実行するより,同一リージョンのVMから実行したほうが3倍以上速かったです.
※1千万件のノードのInsert比較時.
6,Azure SQL Database
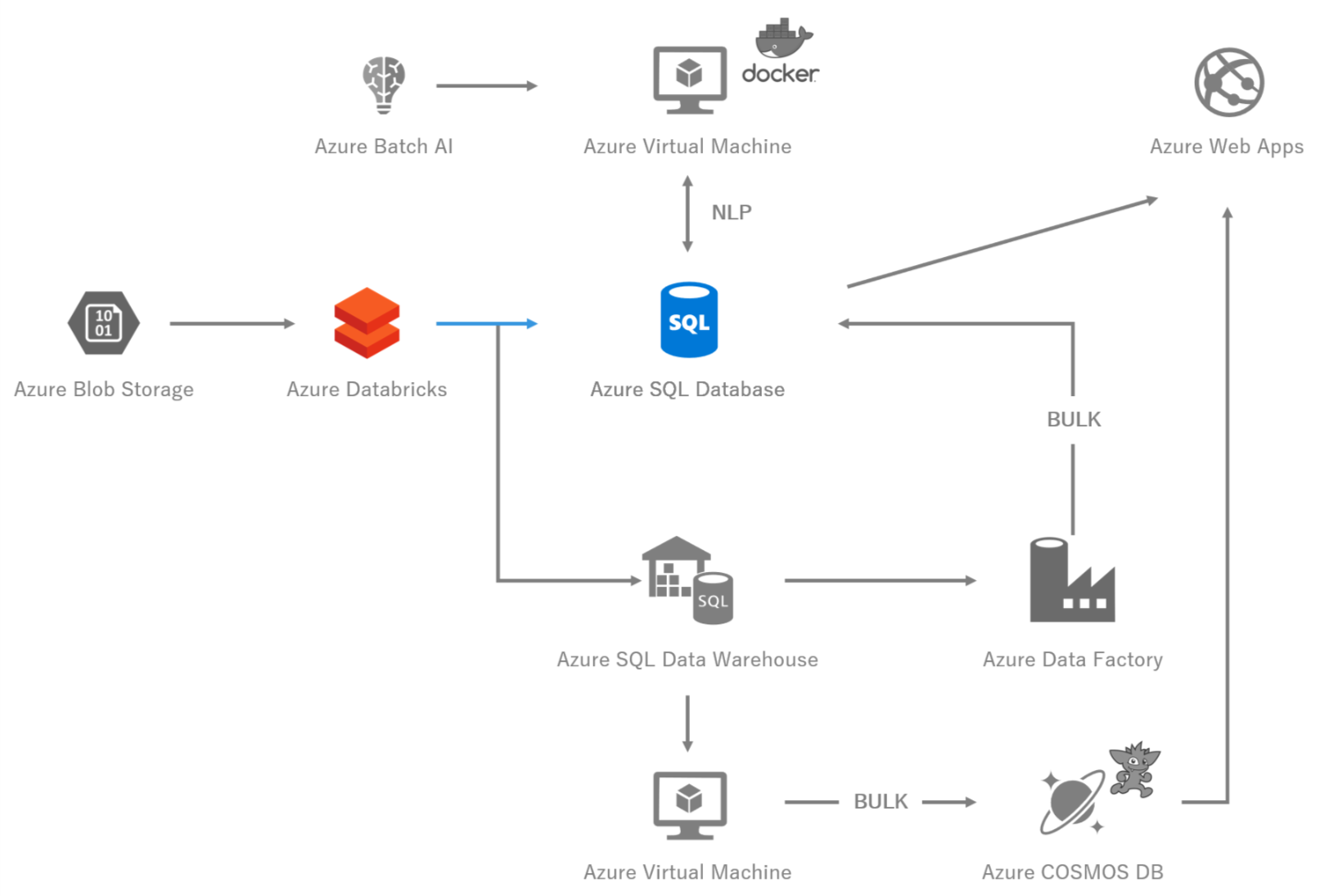
図6 システム構成図 -Azure SQL Database-
6-1,Azure SQL Databaseとは
SQL Serverの,PaaS版です.
Managed Instanceという,オンプレ版と互換性の極めて高いものもあります.
6-2,なぜGraphを使わないのか
Azure SQL Databaseには,SQL Server2017から搭載されたグラフ機能があります.
しかし,今回は利用を見送りしました.
理由としては,
- パフォーマンスが極めて悪い
- できるクエリが少ない
の2点です.
パフォーマンスについては,結果が等価となるグラフのクエリと,テーブル結合によるクエリを比較したところ,ほとんど差がありませんでした.グラフ用に最適化されていないという結果です.
また,最短経路検索などの専用クエリが用意されていなく,基本的にはSQLベースでそれらを実現していくことになります.結果グラフ用に処理が簡易化するわけでもなく,あまりメリットを感じられませんでした.
6-3,SQL Server 2019
SQL Server 2019では,多くの機能が強化されました.
その中でも,SQL Server自体が分散基盤に乗っかることや,グラフ処理の強化は特筆すべき事項であると考えます.
もし,SQL Server 2019がPaaS版11として登場したら,検討する余地は大いにあります.
6-4,Azure Databricksから,SQL Databaseに大量INSERTは向いていない?
SparkのDataframeの,jdbcライブラリを用いて,SQL Databaseに大量データをINSERTしようとすると,原則行単位の分散トランザクションとしてINSERTされます.
想像に難くないですが,例えば数十億件規模のデータを行単位で分散INSERTしようとすれば,SQL Databaseはあっという間に音を上げてしまいます.
音を上げるとどうなるかというと,SQL Databaseが復旧や移動を行い,一時的にサービス停止に陥るだけではなく,数千万件規模の大量の不履行トランザクションがロックをつかんだまま取り残されるので,なにをしてもうんともすんとも言わないデータベースになってしまいます.
なので,少なくともBulk Insertを行うのが現実的なプランですが,実はSparkからだとScala用のライブラリしかなく,それを無理やりPythonから使うか,別の方法を検討する必要があります.
それが,下記のDatawarehouseを経由する方法です.
7,Azure SQL Data Warehouse
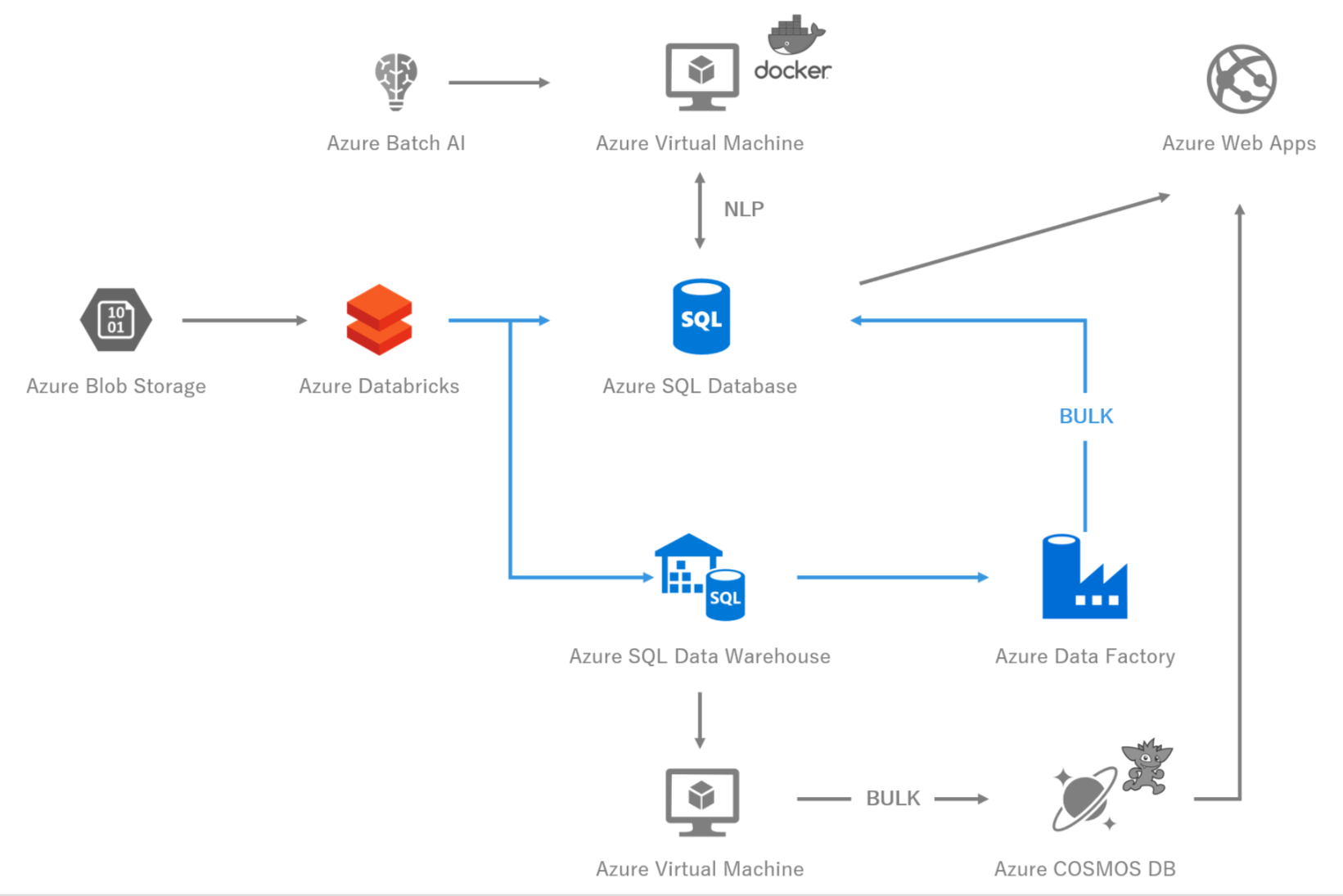
図7 システム構成図 -Azure SQL Data Warehouse-
7-1,Azure SQL Data Warehouseとは
エンタープライズ級のSQL Serverです.詳細な説明はやはり本記事の範囲を超えるため割愛します.
7-2,使いどころ
5-4節で説明した通り,DatabricksからSQL Serverへの大量INSERTにはいくつかの問題があるため,一旦Datawarehouseにデータを退避させ,その後,Azure DataFactoryを利用し,SQL Serverに移動させています.
Azure DatabricksからAzure SQL Data WarehouseへのISNERTは,公式12でやり方が掲示されています.Gen1のDW200であっても,5億件/10分でINSERTできたので,恐ろしいほど優れたコンピューティング機能です.
8,今後の展望
トライ&エラーを繰り返しながら構築していったため,今は,全ての手順を順番通りに・手動で行っています.
これらの処理を,Datafactoryのパイプラインに繋いで,自動化を行ったり,
Sparkをチューニングし,コスト最適化を図ったりしていきます.
また,SQL Server2019のポテンシャルも試してみて,ASISでは様々なデータプラットを用いていますが,もう少しSQL Serverに一元化できるかもしれません.
新しい情報は,随時本記事を更新していきたいと考えております.
-
日本マイクロソフト社に問い合わせた結果,バグというお話だったので,そのように書いております.そのうち修正されるかもしれません. ↩
-
主観です, ↩
-
Improving Python and Spark (PySpark) Performance and Interoperability ↩
-
Databricksで環境構築後,それぞれのVM(もしくはDriverだけでもよいが)にSSHでログインし,ミドルウェアをインストールすれば可能であるはずですが,実証していません. ↩
-
こちらも日本マイクロソフト社に問い合わせた結果です.参考としての算出式は教えていただきましたが,公表されてない理由から,本記事への転記は避けています. ↩
-
Azureのサービス間のやりとりは,Azureのバックボーンの帯域を使うため,一般のネットワーク経由より高速と言われています.Azure データセンター ネットワーク インフラストラクチャーを参考にしてください. ↩