はじめに
レコメンドシステムについて調べてみました。
レコメンドシステムとは、ユーザの好みにあったコンテンツなどをおすすめすることです。
例えば、Amazonの例にしてみます。

私の場合、Kindleストアのおすすめ商品に並んでいるのは、だいたい「ヒナまつり」です。
私自身も、ヒナまつりを購入しているので、おすすめ商品として出てくるのはわかります。
しかし、「かぐや様に告らせたい」や「あそびあそばれ」は購入していないのに、おすすめ商品としてでてきます。
これは、ヒナまつりを購入している人は、上記の2冊も購入している傾向にあるよ!ということで、おすすめ商品にでてくるのだと思います。
これが、レコメンドシステムです。
このレコメンドシステムは、様々な種類があります。
| レコメンドの種類 | 詳細 | 例 |
|---|---|---|
| アイテムベースレコメンド(テキストマイニング) | 商品名や商品説明などの情報を元に、今見ている商品と類似性の高い商品を抽出し紹介。お客様の行動履歴がいらないレコメンドです。 | 「関連アイテム」「こちらの商品もおすすめ」 |
| 協調フィルタリング((購買履歴タイプ)) | そのお客様の購買履歴を分析し、同じような購買をするお客様が買っている商品を紹介 | 「この商品を買った人はこんな商品も買っています」 |
| パーソナライズドレコメンド | お客様の行動履歴を基にお客様の嗜好性を分析し、リアルタイムでそのお客様が好みそうな商品を紹介します。 | 「あなたへのおすすめ商品」 |
| ルールベースレコメンド(キャンペーンレコメンド) | サイト運営者が紹介したい商品を、運営者が定めたルールに従って紹介します。 | 「ピックアップアイテム」 |
(引用元)
Amazonの例では、実際に購入履歴を分析し(ひなまつりを購入していると分析し)同じような購買をするお客様が買っている商品(かぐや様に告らせたい・あそびあそばれ)を紹介しているため、協調フィルタリングな気がします。
協調フィルタリングについて
協調フィルタリングの作成手順は下記の通りです。
- ユーザが購入した(閲覧した/評価した)ものテーブルを作成
- ユーザ間の類似スコアを計算
- ユーザに似ている別のユーザを見つける
- そのユーザが購入した(閲覧した/評価した)もので、まだしていないものをおすすめする。
例えば、ユーザが購入したテーブルを下記のように定義します。
- ユーザが購入した(閲覧した/評価した)ものテーブルを作成
|ユーザA|ユーザB|ユーザC|
|:--:|:--:|:--:|:--:|
|ひなまつり1|ひなまつり1|ドラえもん1|
|ひなまつり2|ひなまつり2|どらえもん2|
|ひなまつり3|あそびあそばれ1|クレヨンしんちゃん1|
|ひなまつり4|あそびあそばれ2|クレヨンしんちゃん2|
次に、ユーザ間の類似スコアを計算します。
計算のイメージは、下記の様な感じです。

上記のことを、ユーザBとユーザCの関係、ユーザCとユーザAの関係も繰り返し処理すると、
下記のようになると思います。
|ユーザAとユーザBの関係|ユーザBとユーザCの関係|ユーザCとユーザAの関係|
|:--:|:--:|:--:|:--:|
|1+1+0+0|0+0+0+0|0+0+0+0|
|1+1+0+0|0+0+0+0|0+0+0+0|
|1+1+0+0|0+0+0+0|0+0+0+0|
|1+1+0+0|0+0+0+0|0+0+0+0|
以上より、ユーザAとユーザBが似ていることを示せます。
ユーザAが購入していて、ユーザBが購入しているものは「あそびあそばれ1」と「あそびあそばれ2」になります。
そのため、ユーザAへのおすすめ商品としては、「あそびあそばれ1」「あそびあそばれ2」が表示され、ユーザBへのおすすめ商品としては、「ひなまつり3」「ひなまつり4」が出てくることになります。
協調フィルタリングの問題点
協調フィルタリングの問題点としては、下記があります。
-
ユーザの好みが変化する。
-
ユーザの数が多い
-
ユーザの行動理由が異なる場合がある。
-
ユーザの好みが変化する。
ユーザの好みは変化します。上の例でいうと、ユーザAとユーザBは似ているユーザと判定していますが、急遽ユーザBの好みが変わってしまう場合もあります。そうすると、ユーザAへのおすすめ商品は、「これは本当におすすめ商品なのか?」と疑えてしまうような商品がレコメンドされてしまう可能性があります。 -
ユーザの数が多い
ユーザが多ければ多いほど、計算量が多くなります。
そのため、ユーザ数が多くなればなるほど、処理に時間がかかってしまいます。 -
ユーザの行動理由が異なる場合がある。
何らか理由(例えば、商品の割引があったり)により、購入している場合もあります。
使用するデータ
使用するデータは、MovieLensを使います。
MovieLensは、レコメンドシステムの開発やベンチマークのために作成された、映画レビューのデータセットです。GroupLens Researchプロジェクトの1つで、研究目的・非商用で下記ウェブサイトが運用されております。
https://grouplens.org/datasets/movielens/
その中でも「ml-100k」というデータセットを使用していきます。
コーディング
import pandas as pd
colname1 = ["user_id","movie_id","ratings"]
rates = pd.read_csv(r"hoge\ml-100k\ml-100k\u.data",engine="python",sep='\t',names=colname1,usecols=range(3))
colname2 = ["movie_id","title"]
mov = pd.read_csv(r"hoge\ml-100k\ml-100k\u.item",engine="python",sep="|",names=colname2,usecols=range(2))
ratesの中を見てみましょう。
10000レコードのデータがあり、user_idとmovie_idとratingsがあります。
user_idは個人を一意に識別するためのコードであり、movie_idは映画を一意に識別するためのコードであることがわかります。また、ratingsは映画の評価(5段階評価)であることがわかります。
では、1人の人がどの程度映画のレビューをしているのでしょうか。
rates["user_id"].value_counts().sort_values()
rates["user_id"].value_counts().mean()

user_idが895の人は、20本の映画をレビューしておりますが、405の人は、737本の映画をレビューしていることがわかりました。
また、平均をとってみたところ、101本、中央値をとってみたところ、1人あたり、65本でした。
とてもレビュー書いていますね。
次に、movをみてみます。

映画自体は、1682本しかないみたいです。
つまり、user_idが405の人は、45%近く映画のレビューをしていることになります。すごいですね。
では、これらをマージしてみます。
df = pd.merge(mov,rates)
mergeした結果、下記のようになりました。

次に、dfのデータの形を変換します。
titleの項目を縦持ちから横持ちにします。
indexはuser_idにし、columnsはtitleにし、表中の値をratingsにします。
df_pivot = df.pivot_table(index={"user_id"},columns={"title"},values="ratings")

では、スターウォーズを見た人は、他にどのような映画をみているのか見てみます。
まず、スターを評価したユーザを抽出します。
SW_df = df_pivot["Star Wars (1977)"]

スターウォーズを見た人は、943人いるみたいですね。
次に、スターウォーズを見たユーザの評価と、他のユーザの評価のペアワイズ相関を計算します。
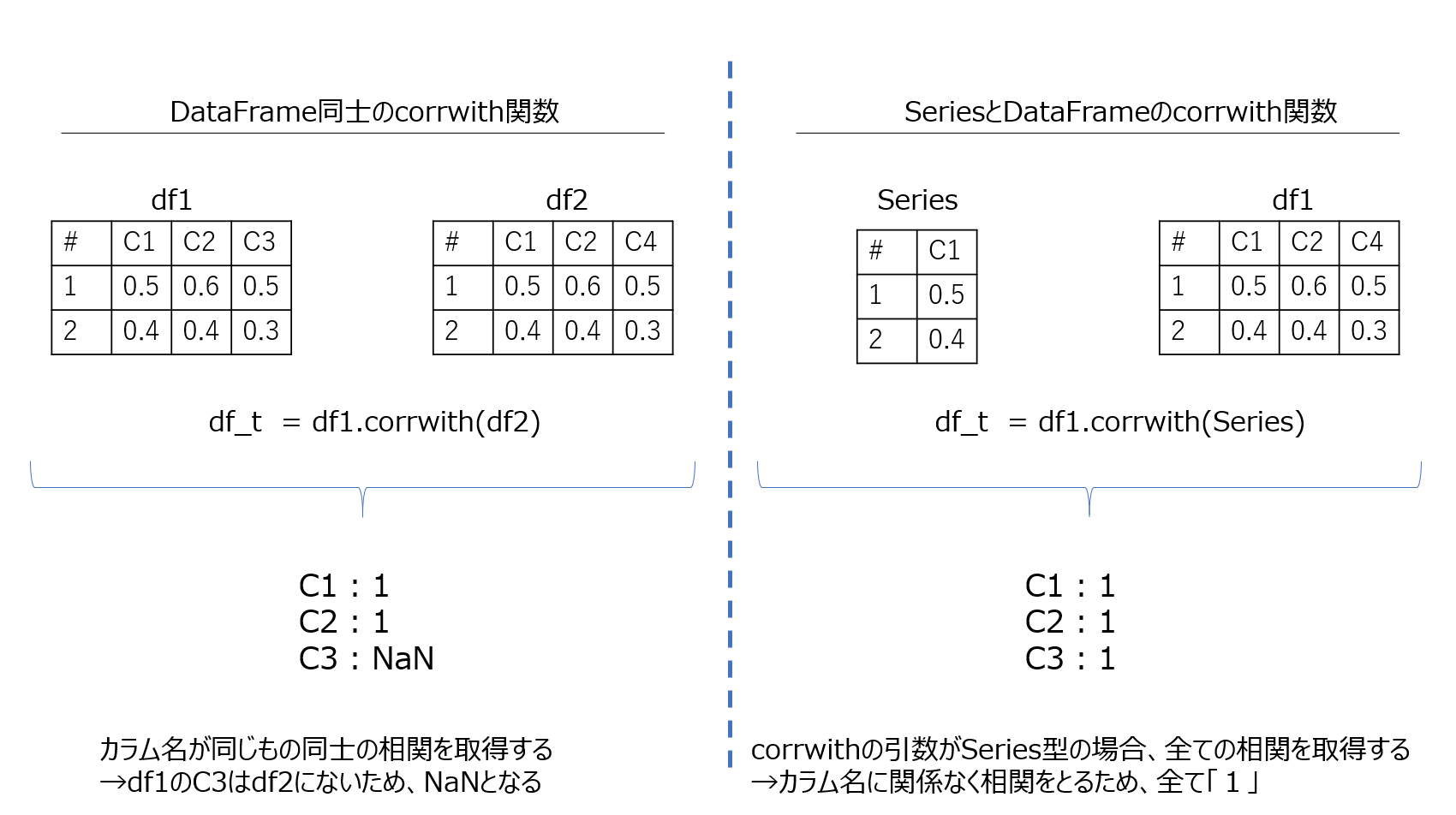
pandasにはペアワイズ相関を計算するためにpd.corrwith関数があります。
- DataFrameとDataFrameの相関を取得
- SeriesとDataFrameの相関を取得
の二つができます。
df1 = pd.read_csv("hoge1.csv")
df2 = pd.read_csv("hoge2.csv")
df_t = df1.corrwith(df2)
df1 = pd.read_csv("hoge1.csv")
# df1から特定カラムを抽出
sr = df1["piyo"]
df2 = pd.read_csv("hoge2.csv")
df_t = df1.corrwith(sr)
それぞれ結果が異なります。
DataFrame同士の場合、カラム名が一致知っている列の相関を取得します。
SeriesとDataFrameの場合、corrwith関数の引数がSeries型だった場合、
カラム名に関係なく全ての相関を取得します。
今回はスターウォーズを見たユーザの評価と、他のユーザの評価の相関を取りたいため、
Series型とDataFrame型で比較します。
# SW_df = df_pivot["Star Wars (1977)"]をしているので
# SW_dfには、Series型です。
simiSW_df = df_pivot.corrwith(SW_df)
ここでやっていることは、
| スターウォーズ | 映画1 | 映画2 | 映画3 | 映画4 | 映画5 | |
|---|---|---|---|---|---|---|
| user1 | 94 | 72 | 94 | 55 | 73 | 41 |
| user2 | 92 | 74 | 96 | 52 | 92 | 56 |
| user3 | 91 | 77 | 92 | 57 | 84 | 53 |
| user4 | 97 | 74 | 95 | 60 | 93 | 43 |
| user5 | 98 | 75 | 90 | 57 | 81 | 55 |
| user6 | 95 | 77 | 93 | 60 | 79 | 66 |
| user7 | 98 | 74 | 100 | 57 | 88 | 50 |
という表があった時、
スターウォーズと映画1のスコア相関
スターウォーズと映画2のスコア相関
スターウォーズと映画3のスコア相関
スターウォーズと映画4のスコア相関
スターウォーズと映画5のスコア相関
を算出しています。
結果は下記のようになります。

という結果になりました。
スターウォーズのSeriesを使ってcorrwithをした結果、下記のような結果になりました。

この中には、NaNもあるため、下記で削除します。
# dropna()で削除。ついでにDataFrameにキャスト
simiSW_df = pd.DataFrame(simiSW_df.dropna())
すると、下記のようになりました。

NaNを消さないと、1664。NaNを消すと1410になりました。
次に、見やすくするためにカラム名の変更を行い、ソートします。
# indexをつけ直す。
simiSW_df = simiSW_df.reset_index()
simiSW_df.columns = ["title","Score"]
simiSW_df.sort_values("Score",ascending=False)
結果は下記の通りです。

Scoreが1の部分が多いような気もします。1ということは類似度が100という意味なので、ちょっと考えにくいです。
もう少し拡大してみます。
simiSW_dfs[simiSW_dfs["Score"]>=0.9]
結果は下記のようになります。

やはり、相関が1のところが多いような気がします。
下記の仮説を考えてみます。
人気具合が異なる映画を同列に考えてはいけない
例えば、スター・ウォーズは一般的に考えて、有名な映画で、人気のある映画です。とても人気のある映画と、あまり人気がなく、視聴者数が少ない映画を一緒くたにレコメンド分析すると、おかしくなってしまうのではないかと仮説をしました。つまり、何らかの特性で映画を区分わけして分析する必要があると仮説をたてます。

現在のデータを考えると、ratingsから考えるか、映画のレビュー数(映画の視聴者人数)のどちらかから、映画の特性を分割できそうです。
一旦、映画のレビュー数(映画の視聴者人数)から
- スターウォーズのような多くの人が視聴している映画
- 少数人数が視聴している映画
の二つに分類してみます。
# titleでグルーピングして、ratingsの数と平均値を集計する。
df_stat = df.groupby("title").agg({"ratings":[np.size,np.mean]})
df_stat.head(10)
結果は下記のようにでてきます。

ついでにヒストグラムも見てみます。
hist(df_stat["ratings"]["size"])
結果は下記のような感じです。

上記のヒストグラムをみると、基本的に0~100が一番多く、どんどん小さくなっていることがわかります。
df_stat2 = df_stat.reset_index()
df_stat2[df_stat2["title"]=="Star Wars (1977)"]
# わざわざreset_index()を使わなくても、下記でも大丈夫
df_stat[df_stat.index=="Star Wars (1977)"]
としたところ、

という結果になりました。
まさかのsizeが583という、かなり大きな値がわかりました。
583人の人たちによってratingsがつけられている映画と、100人ぐらいの人たちによってratingsがつけられている映画を同列に扱って相関係数を算出しても、あまり意味がないものになってしまうと考えられるため、sizeが少ないものは切り離して分析したほうがよいということがわかりました。
# sizeが200以下の映画を対象に分析します。
popdf_stat = df_stat["ratings"]["size"]>=200
# 前段で作成したpopdf_statを元に、ratingsのsizeでソーティングする
df_stat[popdf_stat].sort_values([("ratings","size")],ascending=False)[:15]
結果は下記の通りです。

スターウォーズが最も評価されており、次点でコンタクト、ファーゴ、ジェダイの帰還ということがわかりました。
では、最後にsizeが200以下で絞った映画と、スター・ウォーズとペアワイズ相関をとったデータフレームをpd.merge関数を使ってマージします。
df2 = df_stat[popdf_stat]
# Scoreでソーティング
df_v1.sort_values(["Score"],ascending=False)[:15]
結果は下記の通りです。

スターウォーズを元にペアワイズ相関をとっているので、一番相関が高いのは自身との相関をとっているものになります。
次点で、帝国の逆襲、ジェダイの帰還、レイダース/失われたアークということがわかりました。
以上より、スターウォーズを見ている人は、帝国の逆襲か、ジェダイの帰還か、レイダース/失われたアークがレコメンドされることになります。
おわりに
分析の切り口として、人気具合が異なる映画を同列に考えてレコメンドしないほうがよいということをしました。結果としてまぁそれっぽい結果が出たと思います。
今回、sizeを200と、適当に決めてしまっていますが、ここをどうにか自動で決めれるようにしたいです。
平均+標準偏差とかでしょうか。こういう場合、どのように決めるのが正解なのだろうか。。。