はじめに
教師なし学習のクラスタリングをコーディングしてみます。
クラスタリングは、データに対してクラスタリングをし、何かしらの規則性を解釈するために使うものだと理解しております。
そのため、この技術が何かしらの解を与えるのではなく、きっかけをうみだすものだと認識しております。
使用するデータ
使用するデータは、例によってアボカドデータです。
https://qiita.com/iwasaki_kenichi/items/ea580fd9498ad6950a75
ただし、クラスタリングをする際は数字データを使うことができないため、文字列となるデータ(今回の場合はregionやtype)は削除して処理します。
コード
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import scale
from sklearn.cluster import KMeans
df = pd.read_csv("hogehoge/avocado.csv",engine="python")
from sklearn.preprocessing import scale
のscaleとfrom sklearn.cluster import KMeansのKMeansが今回新しく使用する機能です。
scaleは、正規化する関数であり、平均値を引いて標準偏差で除算する処理を行っています。
df.info()
df情報を見ると、下記だとわかりました。
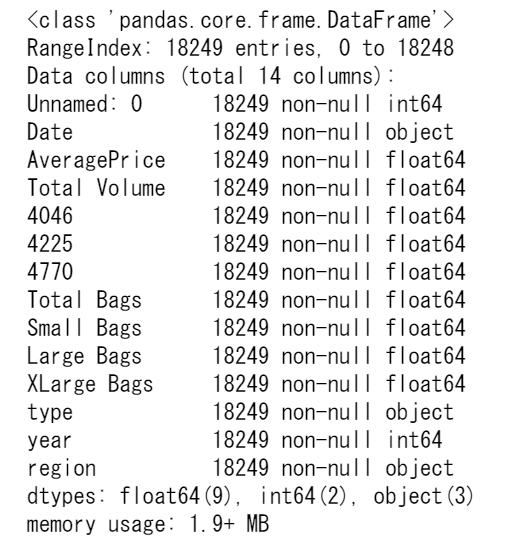
Dateとtype、regionはobject型であり、実際に中身を見てみると文字列であることがわかりました。
そのため、KMeansを実行するとエラーがそのため、
- 削除する
-
pd.Categorical(df.type).codesを使って値に変更する。
のどちらかをする必要があります。今回は、1番の削除をする方向で進めます。
また、Unnamed:0は列番号のため、意味をなしません。
そのため、Unnameed;0は削除します。
del(df["Unnamed: 0"],df["Date"],df["type"],df["year"],df["region"])
# モデルの作成
model = KMeans(n_clusters=4,random_state=1)
# データを正規化し、fit関数により訓練を実施
model = model.fit(scale(df))
df_model = pd.DataFrame(model.labels_)
df["k_value"] = df_model
plt.figure(figsize=(8,6))
plt.scatter(df["4770"],df["k_value"],c=model.labels_.astype(float))
n_clusters=4とし、クラスター数は4とします。
また、model.labels_はnumpy.ndarray型のため、これをDataFrame型に変換し、dfに新たに"k_value"という列を追加し、そこに結果を入れます。
クラスタリングした結果をプロットすると、下記のようになりました。
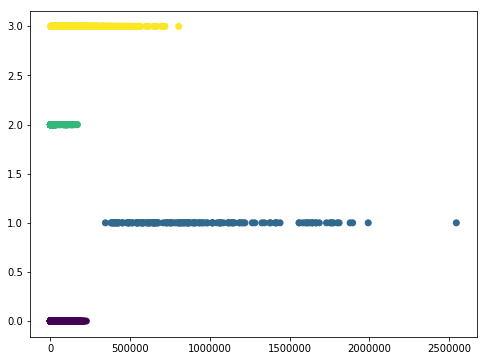
クラスタの値は0~4であるにも関わらず、対になる変数が大きな値のため、プロットしてもよくわからない図になってしまいました。。。片対数とかにしたほうがいいかもしれません。。。
次に、k_valueごとの各項目の平均値を求めます。
df[df["k_value"]==0].mean()
df[df["k_value"]==1].mean()
df[df["k_value"]==2].mean()
df[df["k_value"]==3].mean()
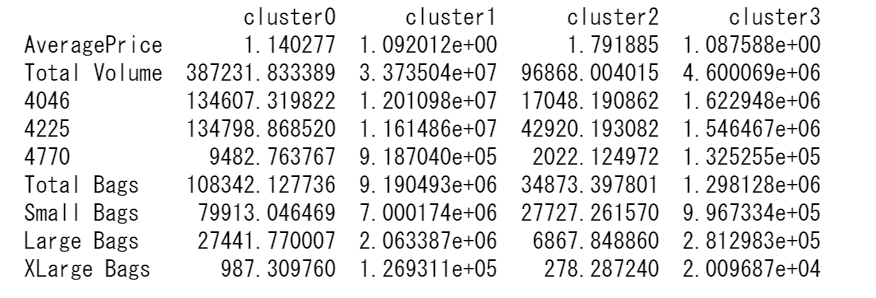
上記をまとめたものが下記になります。
cinfo = pd.DataFrame()
for i in range(4):
cinfo['cluster' + str(i)] = df[df['k_value'] == i].mean()
最後にグラフをプロットしてみます。
myplot = cinfo.T.plot(kind = 'bar',stacked=True,
title = "main")
myplot.set_xticklabels(myplot.xaxis.get_majorticklabels(),rotation=0)
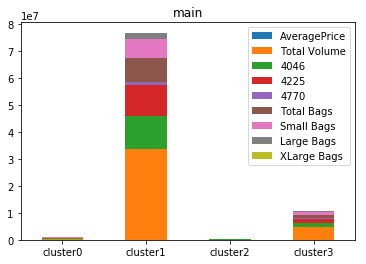
cluster0<cluster2<cluster3<cluster1の順番で値が大きくなっているのがわかりますね。
cluster0とcluster2が小さすぎるため、このままでは傾向がつかめることができませんが。。。
もっと扱いやすいデータでトライしてみたいです。
おわりに
教師なし学習のクラスタリングでした。実務ではどのように使われているのか気になります。
教師あり学習の前処理的な使われ方をするのでしょうか。