概要
【Excelで実装】コンジョイント分析 × 擬似ロジットで確率計算&可視化
では、Excelでユーザー別の効用値 × 製品構成から購買確率を算出・可視化しましたが、
- 属性を変えるたびに表を手でいじる
- 補間や計算式の調整が面倒
PythonでインタラクティブなUI を作成してみました。
❓ なぜPythonでUI化したのか❓
- Excelでは表の更新や線形補間が手作業で手間
- 属性を変更して比較するには、インタラクティブなUIの方が圧倒的に楽
💹 Streamlit を用いた UI で以下のことが可能です
- 属性(バッテリー・画面サイズ・価格など)をプルダウンで選択
- 各ブランドの購買確率を自動計算&棒グラフで可視化
- 属性を変えるたびにリアルタイムで再計算される
-
誰にどの商品が刺さるか?が見える!
→ ユーザー別効用値を使って、ブランドごとの購買確率を計算します
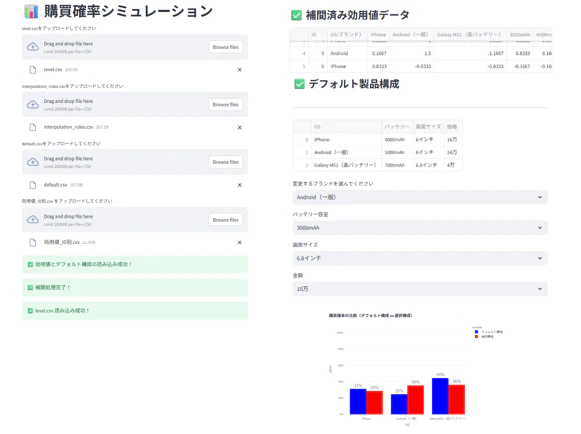
🎬 完成画面(UIイメージ)
※各ブランドの購買確率を棒グラフで可視化しています。
サンプルデータ
📜 ① 効用値(ユーザー × 属性)
【Python×コンジョイント分析】OLS回帰で効用値を推定し、ブランド別に可視化する
で作成した 📜効用値_ID別.csv
ユーザーごとにOLS回帰で推定した「各水準の効用値」 をまとめたもので、
ここからブランドごとの「選ばれやすさ(効用)」を計算します。

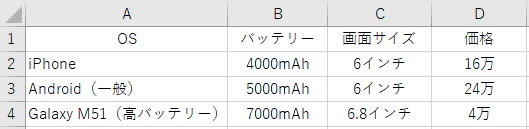
📜② default.csv
実在商品の構成テンプレート(ブランド別スマホのスペック)。
ここにある構成でどのブランドが何%選ばれるか? を可視化します。
📜 ③ interpolation_rules.csv:中間値を補完するルール表(線形補間)
属性の選択肢を柔軟にするため定義されていないスペックにも対応できるように
線形補間のルール表を作成します。
ユーザーがUI上で
「10万円の場合は?」
「7インチだったらどうなる?」
といった中間的な数値を選んだときに、
効用値を線形補間するためのルールを定義したCSVです(自作)。
この表を使うことで、定義されていないスペック値でもスムーズに効用値を導出できます。
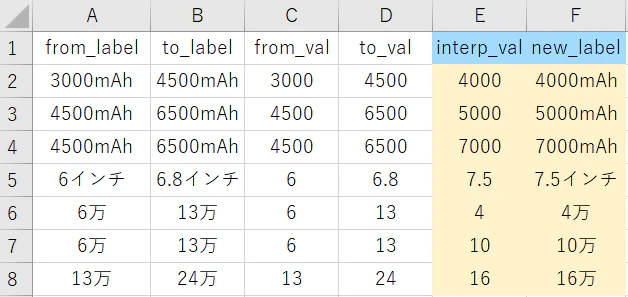
- from_label / to_label:補間する軸(例:バッテリー)を指定
- from_val / to_val:補間の区間(数値、例:4000〜6000)
- interp_val:知りたい中間値(例:5000)
- new_label:補間後の名前(例:5000mAh)
📜 ④ level.csv:属性と水準の定義マスタ(自作)
UIのプルダウン選択肢や、効用値の並び順の整備に使用しています。
補完値も含まれているため、可視化・補間の両方で役立ちます。
このマスタを使うことで、UIのプルダウン順やグラフの並びも整理できます。
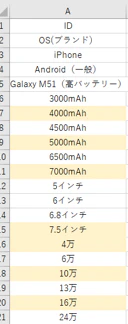
- ヘッダー行(列名)は無し!
- 補間ルールで追加された新しい水準(例:4000mAh, 7000mAhなど) 必須!
コード内容
サンプルファイルと同じフォルダ内に、以下のコードを app.py という名前で保存します。
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import io
st.set_page_config(page_title="購買確率シミュレーション", layout="centered")
st.title("📊 購買確率シミュレーション")
# 線形補間関数
def linear_interp(df, low_col, high_col, low_val, high_val, new_val, new_col):
df[new_col] = df[low_col] + (df[high_col] - df[low_col]) * ((new_val - low_val) / (high_val - low_val))
return df
# CSV読み込み(Streamlit用)
def safe_read_csv(uploaded_file, **kwargs):
try:
content = uploaded_file.getvalue()
if len(content) == 0:
st.warning(f"{uploaded_file.name} は空のファイルです")
return None
return pd.read_csv(io.BytesIO(content), **kwargs)
except Exception as e:
st.error(f"{uploaded_file.name} の読み込み中にエラーが発生しました: {e}")
return None
# ファイルアップローダー
level_file = st.file_uploader("level.csvをアップロードしてください", type="csv")
rule_file = st.file_uploader("interpolation_rules.csvをアップロードしてください", type="csv")
default_file = st.file_uploader("default.csvをアップロードしてください", type="csv")
uploaded_file = st.file_uploader("効用値_ID別.csv をアップロードしてください", type="csv")
df_levels = None
if uploaded_file is not None and default_file is not None:
df = safe_read_csv(uploaded_file)
df_default = safe_read_csv(default_file)
if df is None or df_default is None:
st.stop()
st.success("✅ 効用値とデフォルト構成の読み込み成功!")
if rule_file is not None:
rules = safe_read_csv(rule_file)
if rules is not None:
for _, row in rules.iterrows():
df = linear_interp(
df,
low_col=row["from_label"],
high_col=row["to_label"],
low_val=float(row["from_val"]),
high_val=float(row["to_val"]),
new_val=float(row["interp_val"]),
new_col=row["new_label"]
)
st.success("✅ 補間処理完了!")
if level_file is not None:
df_levels = safe_read_csv(level_file, header=None)
if df_levels is not None:
st.success("✅ level.csv 読み込み成功!")
desired_order = df_levels[0].tolist()
else:
desired_order = []
else:
st.warning("level.csvをアップロードしてください")
desired_order = []
existing_cols = [c for c in desired_order if c in df.columns]
remaining_cols = [c for c in df.columns if c not in existing_cols]
df = df[existing_cols + remaining_cols]
st.subheader("✅ 補間済み効用値データ")
st.dataframe(df)
st.subheader("✅ デフォルト製品構成")
st.markdown("---")
st.dataframe(df_default)
if df_levels is not None:
df_levels.columns = ['level']
brand_keywords = ["iPhone", "Android", "Galaxy"]
def detect_category(val):
val = str(val).lower()
if 'mah' in val:
return 'battery'
elif 'インチ' in val:
return 'screen'
elif '万' in val:
return 'price'
elif any(keyword.lower() in val for keyword in brand_keywords):
return 'brand'
else:
return 'unknown'
df_levels['category'] = df_levels['level'].astype(str).apply(detect_category)
grouped_levels = df_levels.groupby('category')['level'].apply(list).to_dict()
brand_options = grouped_levels.get('brand', [])
battery_options = grouped_levels.get('battery', [])
screen_options = grouped_levels.get('screen', [])
price_options = grouped_levels.get('price', [])
target_brand = st.selectbox("変更するブランドを選んでください", brand_options)
battery_choice = st.selectbox("バッテリー容量", battery_options)
screen_choice = st.selectbox("画面サイズ", screen_options)
price_choice = st.selectbox("金額", price_options)
default_dict = {
row["OS"]: {
"battery": row["バッテリー"],
"screen": row["画面サイズ"],
"price": row["価格"]
} for _, row in df_default.iterrows()
}
def get_config(brand_name):
cols = [brand_name,
default_dict[brand_name]["battery"],
default_dict[brand_name]["screen"],
default_dict[brand_name]["price"]]
missing_cols = [col for col in cols if col not in df.columns]
if missing_cols:
st.warning(f"{brand_name} の構成に以下の列が見つかりません: {missing_cols}")
return None
else:
return [df[col] for col in cols]
iPhone_conf = get_config("iPhone")
android_conf = get_config("Android(一般)")
galaxy_conf = get_config("Galaxy M51(高バッテリー)")
if target_brand == "iPhone":
iPhone_conf = [df["iPhone"], df[battery_choice], df[screen_choice], df[price_choice]]
elif target_brand == "Android(一般)":
android_conf = [df["Android(一般)"], df[battery_choice], df[screen_choice], df[price_choice]]
elif target_brand == "Galaxy M51(高バッテリー)":
galaxy_conf = [df["Galaxy M51(高バッテリー)"], df[battery_choice], df[screen_choice], df[price_choice]]
df["sum_iPhone"] = sum(iPhone_conf)
df["sum_Android"] = sum(android_conf)
df["sum_Galaxy"] = sum(galaxy_conf)
exp_i, exp_a, exp_g = np.exp(df["sum_iPhone"]), np.exp(df["sum_Android"]), np.exp(df["sum_Galaxy"])
denom = exp_i + exp_a + exp_g
df["p_iPhone"] = exp_i / denom
df["p_Android"] = exp_a / denom
df["p_Galaxy"] = exp_g / denom
mean_probs_selected = df[["p_iPhone", "p_Android", "p_Galaxy"]].mean().rename({
"p_iPhone": "iPhone",
"p_Android": "Android(一般)",
"p_Galaxy": "Galaxy M51(高バッテリー)"
})
brands, sum_eff = [], []
for _, row in df_default.iterrows():
total_eff = sum([df[row[col]].mean() for col in ["OS", "バッテリー", "画面サイズ", "価格"]])
brands.append(row["OS"])
sum_eff.append(total_eff)
df_sum = pd.DataFrame({"OS": brands, "default_sum": sum_eff})
exp_vals = np.exp(df_sum["default_sum"])
df_sum["p_default"] = exp_vals / exp_vals.sum()
df_compare = pd.DataFrame({
"OS": df_sum["OS"],
"デフォルト構成": df_sum["p_default"],
"選択構成": mean_probs_selected.values
})
fig = px.bar(
df_compare,
x="OS", y=["デフォルト構成", "選択構成"],
barmode="group", height=500,
color_discrete_sequence=["blue", "red"]
)
fig.update_traces(texttemplate="%{y:.0%}", textposition="outside")
fig.update_layout(
yaxis_tickformat=".0%", yaxis_range=[0, 1.1],
font=dict(size=18),
title="購買確率の比較(デフォルト構成 vs 選択構成)"
)
st.plotly_chart(fig, use_container_width=True)
else:
st.warning("ファイルをアップロードしてください")
コード解説
🧑💻 1. ライブラリの読み込みとタイトル表示
まずは、使用するライブラリをインポートし、
Streamlitアプリの基本設定とページタイトルを定義します。
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import io
# ページタイトルとレイアウト(中央寄せ)を設定
st.set_page_config(page_title="購買確率シミュレーション", layout="centered")
# ページ上部にタイトルを表示
st.title("📊 購買確率シミュレーション")
🧮 2. 線形補間の関数定義
補完ルールに従って効用値を線形補間(linear interpolation) する関数を定義します。
# 線形補間関数
def linear_interp(df, low_col, high_col, low_val, high_val, new_val, new_col):
if high_val == low_val:
df[new_col] = df[low_col] # または df[high_col]
else:
df[new_col] = df[low_col] + (df[high_col] - df[low_col]) * ((new_val - low_val) / (high_val - low_val))
return df
📌low_col
補間元の効用値列名(下限の列): "4500mAh"
📌high_col
補間元の効用値列名(上限の列): "6500mAh"
📌low_val / high_val:補間区間(数値)
📌new_val
補間対象(例:5000)
📌new_col
新しく作成される補間列(例:"5000mAh")
low_val、high_val、new_val は計算に使う**数値(mAhや円の単位は不要)**です。
この関数は価格・画面サイズ・バッテリー容量 などの連続値属性に対して、
中間値や外挿値を使って効用値を自動計算するために使います。
たとえば…
・「6.0インチ = +0.2」「6.8インチ = +0.6」のとき
・「7インチ」で補間したい場合 → +0.7 などを計算
📄 interpolation_rules.csv にルールを書いておけば、
自動で補間項目が読み取られ、反映されます。
📈 補間範囲の外も予測可能(外挿)
7.5インチのような外れ値でも自動で補完されます。
🧮 3. CSV読み込み関数
Streamlit上でCSVをアップロードし、安全に読み込む関数を定義します。
バイト列の処理やエラー発生時のハンドリングを行っています。
# CSV読み込み(Streamlit用)
def safe_read_csv(uploaded_file, **kwargs):
try:
content = uploaded_file.getvalue()
if len(content) == 0:
st.warning(f"{uploaded_file.name} は空のファイルです")
return None
return pd.read_csv(io.BytesIO(content), **kwargs)
except Exception as e:
st.error(f"{uploaded_file.name} の読み込み中にエラーが発生しました: {e}")
return None
📌uploaded_file.getvalue()
アップロードされたファイルの内容(バイト列)を取得。
📌len(content) == 0
バイト列の長さが0なら「空のファイル」とみなし警告を出す。
文字列ではなくバイト列なので .strip() は使わない。
📌io.BytesIO(content)
バイト列をファイルのように扱い(ラッパー)pandas.read_csv() に渡す。
📌try - except
読み込みエラー(例:文字コード・区切り文字ミス)を補足し、UIに表示。
📌st.warning, st.error(Streamlit)
Streamlit のUI上に問題を通知。
-
st.warning:軽微な問題(黄色) -
st.error:重大な問題(赤)
❓ラッパーとは❓
既存の処理を包んで(wrap)、
使いやすく・安全にした補助的な関数やクラスのことです。
この関数も pd.read_csv() をラップし、ファイルの中身チェックやエラー処理を追加した例です。
🧮 4. CSVファイルアップロード
# ファイルアップローダーでCSVファイルを複数アップロード
level_file = st.file_uploader("level.csvをアップロードしてください", type="csv")
rule_file = st.file_uploader("interpolation_rules.csvをアップロードしてください", type="csv")
default_file = st.file_uploader("default.csvをアップロードしてください", type="csv")
uploaded_file = st.file_uploader("効用値_ID別.csv をアップロードしてください", type="csv")
# 2つのファイルがアップロードされたら読み込み処理を実行
if uploaded_file is not None and default_file is not None:
df = safe_read_csv(uploaded_file)
df_default = safe_read_csv(default_file)
# 読み込みに失敗した場合は処理停止(エラー表示済みを想定)
if df is None or df_default is None:
st.stop()
# 読み込み成功のメッセージを表示
st.success("✅ 効用値とデフォルト構成の読み込み成功!")
📌st.file_uploader
Streamlitのファイルアップロードコンポーネント。ユーザーがファイルをアップロードできるUIを表示する。
📌if uploaded_file is not None and default_file is not None:
両方のファイルがアップロードされるまで処理を進めない。
安全にファイル同士を比較・処理したい場合に重要。
📌safe_read_csv
先に説明した安全読み込み関数を使い、ファイル内容の取得とエラーチェックを一括処理。
📌st.stop()
読み込みに失敗(None)した場合、以降のコードの実行を停止し
メッセージを表示して再度アップロードを促す。
📨 output
❓なぜ【2つのファイルがアップロードされたら読み込み処理を実行】❓
今回の処理では効用値_ID別.csvとdefault.csvの2つのファイルが揃って初めて意味のある比較や計算ができます。
他のファイルlevel.csvやinterpolation_rules.csvは後続の処理や別フェーズで使うため、ここではまだ不要だからです。
もし必要なら、他のファイルも同時にチェックして条件に加えても構いませんが、
処理の段階を分けて読み込みやチェックを行うことで、コードの可読性と保守性が向上します。
(全部まとめて処理するとエラーが起きやすかったため、あえてこのように分けています)
🧮 5. 補間処理の実装例
# 補間処理
if rule_file is not None:
rules = safe_read_csv(rule_file)
if rules is not None:
for _, row in rules.iterrows():
df = linear_interp(
df,
low_col=row["from_label"],
high_col=row["to_label"],
low_val=float(row["from_val"]),
high_val=float(row["to_val"]),
new_val=float(row["interp_val"]),
new_col=row["new_label"]
)
st.success("✅ 補間処理完了!")
📌rule_file is not None
補間ルールがアップロードされているかチェック。ファイルが無ければ補間処理はスキップ。
📌safe_read_csv(rule_file)
安全にCSVを読み込み、データフレームとして取得。読み込み失敗時は補間処理をしない。
📌rules.iterrows()
補間ルールの各行を1つずつ取得してループ処理。
📌linear_interp()
指定した2列(from_label と to_label)の値をもとに、
中間値(interp_val)に対応する効用値を線形補間し、
新しい列(new_label)としてデータフレーム df に追加します。
🧮 6. 水準リスト(level.csv)の読み込みと順序リスト化
# 水準リスト読み込み
if level_file is not None:
df_levels = safe_read_csv(level_file, header=None)
if df_levels is not None:
st.success("✅ level.csv 読み込み成功!")
desired_order = df_levels[0].tolist()
else:
desired_order = []
else:
st.warning("level.csvをアップロードしてください")
desired_order = []
📌level_file
Streamlitのファイルアップローダーで受け取った level.csv。
各属性の「表示順」や「選択肢の並び」を定義したマスタファイルです。
→ ヘッダーは無し(header=None)で読み込みます。
📌safe_read_csv
先に定義した安全な読み込み関数。
空ファイルや形式エラー時は
Noneを返す
読み込み失敗時でもst.stop()で安全に処理を中断できる
📌df_levels[0].tolist()
CSVの**1列目(0列目)**をリスト化して、「希望の水準順(desired_order)」として抽出。
例:
["3000mAh", "4000mAh", "4500mAh", "5000mAh", "6500mAh"]
📌desired_order
水準順のリスト。
読み込み失敗時は空リスト [] にしておくことで、後続処理のエラーを未然に防止。
🧮 列順を調整する処理
# dfの列順調整
existing_cols = [c for c in desired_order if c in df.columns]
remaining_cols = [c for c in df.columns if c not in existing_cols]
df = df[existing_cols + remaining_cols]
📌desired_order
先ほど level.csv から読み込んだ「希望の列順(水準の並び)」のリスト。
→ グラフや表の表示順を統一するために使用。
📌existing_cols = [c for c in desired_order if c in df.columns]
desired_order に書かれている中で、df に実際に存在する列だけを取り出します。
→ 補間前の段階ではまだ存在しない列もあるので、このチェックを行います。
📌remaining_cols = [c for c in df.columns if c not in existing_cols]
df に存在するけどdesired_orderには書かれていない列を抽出。
→ 例えば "id" , "OS", "price" などの情報列が該当。
📌df = df[existing_cols + remaining_cols]
「水準順に並び替えたい列」→「それ以外の列」の順で連結して、列順を再構成します。
例:
desired_order = ["3000mAh", "4000mAh", "5000mAh"]
df.columns = ["id", "OS", "4000mAh", "5000mAh", "7000mAh"]
→ 並び替え後は
["4000mAh", "5000mAh", "id", "OS", "7000mAh"]
これによって、グラフやUI表示で列の順序がズレないようになり
直感的にわかりやすい表示になります。
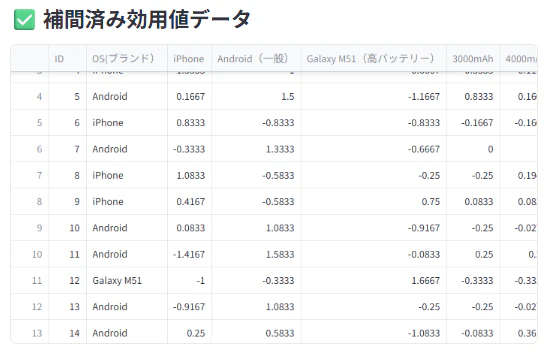
🧮 7. 補間済み効用値(整列済み)の表示
# 表示
st.subheader("✅ 補間済み効用値データ")
st.dataframe(df)
📨 output

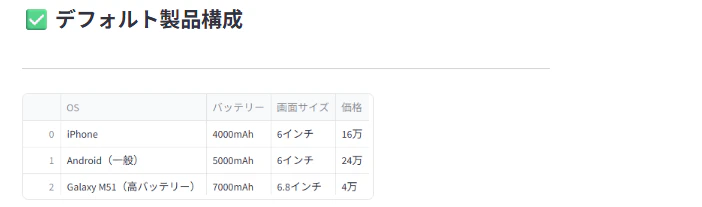
🧮 8. デフォルト構成の表示
st.subheader("✅ デフォルト製品構成")
st.markdown("---")
st.dataframe(df_default)
📨 output
🌸デフォルトスペックを表示する事で、比較ができます。
🧮 9. 製品構成のカスタマイズ(選択UI)
if df_levels is not None:
df_levels.columns = ['level'] # 読み込んだデータに列名を付ける
brand_keywords = ["iPhone", "Android", "Galaxy"] # ブランド判別に使うキーワードリスト
def detect_category(val):
val = str(val).lower() # 文字列を小文字にして比較のズレを防止
if 'mah' in val: # バッテリー容量を表す単位で判別
return 'battery'
elif 'インチ' in val: # 画面サイズの単位で判別
return 'screen'
elif '万' in val: # 価格の単位で判別
return 'price'
elif any(keyword.lower() in val for keyword in brand_keywords): # ブランド判別
return 'brand'
else:
return 'unknown' # どれにも該当しないものはunknown扱い
# 各行の値に対してカテゴリを判別して新しい列 'category' に追加
df_levels['category'] = df_levels['level'].astype(str).apply(detect_category)
# カテゴリごとにレベル(値)をまとめて辞書化
grouped_levels = df_levels.groupby('category')['level'].apply(list).to_dict()
# 各カテゴリの選択肢を取得(存在しなければ空リストになる)
brand_options = grouped_levels.get('brand', [])
battery_options = grouped_levels.get('battery', [])
screen_options = grouped_levels.get('screen', [])
price_options = grouped_levels.get('price', [])
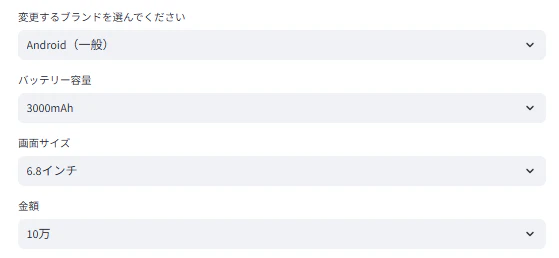
# StreamlitのUIでセレクトボックスを表示。ユーザーが選択できるようにする
target_brand = st.selectbox("変更するブランドを選んでください", brand_options)
battery_choice = st.selectbox("バッテリー容量", battery_options)
screen_choice = st.selectbox("画面サイズ", screen_options)
price_choice = st.selectbox("金額", price_options)
else:
# ファイルが読み込めなかった場合の警告表示
st.warning("level.csvの読み込みに失敗しました")
📌df_levels.columns = ['level']
level.csvはヘッダーなしで読み込んでいるので、明示的に列名を 'level' に付けておくことで、後続の処理で df_levels['level'] として参照できるようにします。
📌brand_keywords
ブランドを判別するキーワードのリスト。ここに入っている文字列を含むと「ブランド」と判別します。
例:"iPhone", "Android", "Galaxy"など。
📌detect_category
値に含まれるキーワードをもとに、以下のようにカテゴリを判定します。
| 値 | 判定カテゴリ |
|---|---|
| "5000mAh" | battery |
| "6.5インチ" | screen |
| "10万円" | price |
| "iPhone15" | brand |
📌groupby → to_dict
判別したカテゴリごとに属性値をまとめて辞書形式に変換し、カテゴリごとに選択肢を取り出しやすくする。
📌st.selectbox
StreamlitのUIコンポーネントの1つで、ユーザーが選択肢から項目を選べるドロップダウンメニューを表示。
📨 output
🧮 10. デフォルト製品構成の取り出しと準備
# デフォルト構成辞書化
default_dict = {
row["OS"]: {
"battery": row["バッテリー"],
"screen": row["画面サイズ"],
"price": row["価格"]
} for _, row in df_default.iterrows()
}
📌 default_dict
デフォルト製品構成を辞書形式に変換しています。
df_default の各行を OS(ブランド)名をキーとして、バッテリー・画面サイズ・価格の情報をネストした辞書にします。
❓ネストとは❓
「辞書の中に辞書があることをネスト構造 と呼びます。
✅ 普通の辞書(ネストなし)
{"iPhone": "3000mAh"}
これは単に "iPhone" というキーに "3000mAh" という値が入っているだけ。
✅ ネストされた辞書(入れ子)
| ブランド名 | battery | screen | price |
|---|---|---|---|
| iPhone | 3000mAh | 5インチ | 10万 |
| Android | 4000mAh | 6.5インチ | 8万 |
{"iPhone": {"battery": "3000mAh","screen": "5インチ","price": "10万"}}
これが「ネストされた辞書構造(dictionary of dictionaries)」です。
# ✅ 存在確認しながら構成を抽出する関数
def get_config(brand_name):
cols = [brand_name,
default_dict[brand_name]["battery"],
default_dict[brand_name]["screen"],
default_dict[brand_name]["price"]]
# ⚠️ 存在しない列を検出
missing_cols = [col for col in cols if col not in df.columns]
if missing_cols:
st.warning(f"{brand_name} の構成に以下の列が見つかりません: {missing_cols}")
return None
else:
return [df[col] for col in cols]
# 🚀 各ブランドの構成を取得
iPhone_conf = get_config("iPhone")
android_conf = get_config("Android(一般)")
galaxy_conf = get_config("Galaxy M51(高バッテリー)")
📌get_config(brand_name)
指定したブランドの構成をdfから安全に取り出す関数。
戻り値 [df[col] for col in cols]
戻り値
各構成列(Series)をリストで返します。
例:[df["iPhone"], df["3000mAh"], df["6.1インチ"], df["10万"]]後続処理でロジットモデルに入力する際などに使用します。
📌cols
ブランドの構成(OS + battery + screen + price)に対応する列名(文字列)のリスト。
📌missing_cols = [col for col in cols if col not in df.columns]
4列すべて df に存在するか確認。足りない列は missing_cols に格納。
📌if missing_cols
1つでも見つからなければ Streamlit で警告を出しNone を返す。
📌get_config()
ブランドごとの構成を取得。
🧮 11. ブランドごとの効用値リスト作成
def get_config(brand_name):
cols = [brand_name,
default_dict[brand_name]["battery"],
default_dict[brand_name]["screen"],
default_dict[brand_name]["price"]]
missing_cols = [col for col in cols if col not in df.columns]
if missing_cols:
st.warning(f"{brand_name} の構成に以下の列が見つかりません: {missing_cols}")
return None
else:
return [df[col] for col in cols]
iPhone_conf = get_config("iPhone")
android_conf = get_config("Android(一般)")
galaxy_conf = get_config("Galaxy M51(高バッテリー)")
📌default_dict
ブランドごとに「バッテリー」「画面サイズ」「価格」の列名を管理する辞書。
例えば default_dict["iPhone"]["battery"] は、
iPhoneのバッテリー容量に対応する列名(例:"4000mAh"など)を返す。
📌df[...]
列名を使って、効用値が入ったDataFrameの特定の列を取得。
効用値は各列に対応しており、後で合計してブランドごとの評価を計算する。
🚀 ここで作成した各ブランドの効用値リストは、次に登場する「ロジットモデルによる購買確率推定」に使われます。
🧮 12. 構成変更処理(ユーザー選択に応じて効用値を更新)
# 構成変更
if target_brand == "iPhone":
iPhone_conf = [df["iPhone"], df[battery_choice], df[screen_choice], df[price_choice]]
elif target_brand == "Android(一般)":
android_conf = [df["Android(一般)"], df[battery_choice], df[screen_choice], df[price_choice]]
elif target_brand == "Galaxy M51(高バッテリー)":
galaxy_conf = [df["Galaxy M51(高バッテリー)"], df[battery_choice], df[screen_choice], df[price_choice]]
プルダウンリストの選択から効用値を更新。
ユーザーが選択した属性(バッテリー容量・画面サイズ・価格)に合わせて、対象ブランドの効用値リストを動的に変更します。
🧮 13. 購買確率計算と効用値合計
# 合計効用値
df["sum_iPhone"] = sum(iPhone_conf)
df["sum_Android"] = sum(android_conf)
df["sum_Galaxy"] = sum(galaxy_conf)
# 購買確率計算(ロジットモデル)
exp_i, exp_a, exp_g = np.exp(df["sum_iPhone"]), np.exp(df["sum_Android"]), np.exp(df["sum_Galaxy"])
denom = exp_i + exp_a + exp_g
df["p_iPhone"] = exp_i / denom
df["p_Android"] = exp_a / denom
df["p_Galaxy"] = exp_g / denom
# 各ブランドの平均購買確率を計算し、名前を分かりやすく変更
# 指定順に並べ替えた平均
mean_probs_selected = df[["p_iPhone", "p_Android", "p_Galaxy"]].mean()
mean_probs_selected.index = ["iPhone", "Android(一般)", "Galaxy M51(高バッテリー)"]
mean_probs_selected = mean_probs_selected.loc[["iPhone", "Android(一般)", "Galaxy M51(高バッテリー)"]]
📌 sum_iPhone, sum_Android, sum_Galaxy
IDごとにブランド+バッテリー+画面+価格の効用値を合計。
この合計値を使って、そのユーザーがどのブランドを選びやすいか購買確率を計算。
📌 np.exp()
効用値の違いを確率に変えるために、指数関数を使用。
ロジットモデルの基本的な計算
📌 denom
すべてのブランドの指数関数の合計値。
確率を計算する際の分母に使用
📌 p_iPhone, p_Android, p_Galaxy
各ブランドの購買確率。
合計の指数関数で割って、確率の形に変。
📌 mean_probs_selected
全IDの購買確率の平均値。
🧮 14 . デフォルト構成の効用値と購買確率の算出
# デフォルト構成の効用値
brands, sum_eff = [], []
for _, row in df_default.iterrows():
total_eff = sum([df[row[col]].mean() for col in ["OS", "バッテリー", "画面サイズ", "価格"]])
brands.append(row["OS"])
sum_eff.append(total_eff)
df_sum = pd.DataFrame({"OS": brands, "default_sum": sum_eff})
exp_vals = np.exp(df_sum["default_sum"])
df_sum["p_default"] = exp_vals / exp_vals.sum()
df_compare = pd.DataFrame({
"OS": df_sum["OS"],
"デフォルト構成": df_sum["p_default"],
"選択構成": mean_probs_selected.values
})
📌 df_default.iterrows()
各ブランドの「デフォルト構成」を1行ずつ取り出して処理するループ。
OS・バッテリー・画面サイズ・価格の列名を取得し、対応する効用値の平均を計算。
📌 df[row[col]].mean()
各属性(例:4000mAh, 6.1インチ, 10万など)の効用値を、dfから取り出して平均。
ブランドの構成(4属性)の平均効用値の合計。
📌 df_sum
OSごとのデフォルト構成の合計効用値と、それをもとにした購買確率を格納したDataFrame。
default_sum各ブランドの効用値合計
p_default効用値合計をロジット変換した購買確率
📌 np.exp() + .sum()
効用値合計を指数変換して、確率に変換(ロジットモデルの基本式)。
全ブランド分の指数和で割ることで、確率として正規化。
📌 df_compare
最終出力。構成変更前後の購買確率を並べた比較表。
デフォルト構成":変更前(初期状態)の購買確率
選択構成":変更後(ユーザー選択による構成)の平均購買確率
🧮 15. 購買確率の比較グラフ(デフォルト構成 vs 選択構成)
fig = px.bar(
df_compare,
x="OS", y=["デフォルト構成", "選択構成"],
barmode="group", height=500,
color_discrete_sequence=["blue", "red"]
)
fig.update_traces(texttemplate="%{y:.0%}", textposition="outside")
fig.update_layout(
yaxis_tickformat=".0%", yaxis_range=[0, 1.1],
font=dict(size=18),
title="購買確率の比較(デフォルト構成 vs 選択構成)"
)
st.plotly_chart(fig, use_container_width=True)
📌 px.bar(...)
棒グラフを作成
📌barmode="group
2本の棒(デフォルト構成と選択構成)を横に並べて比較。
📌 color_discrete_sequence=["blue", "red"]
デフォルト構成 → 青色
選択構成 → 赤色
📌 update_traces(...)
棒グラフの上にパーセンテージ(%)表示
📌 st.plotly_chart(...)
Streamlit 上にインタラクティブな棒グラフを表示
📊 UIを使ってみる
ターミナルを開き
PS C:\Users\user> cd C:\Users\user\aa.pyが保存されてるフォルダ
PS C:\Users\user\aa.pyが保存されてるフォルダ> streamlit run csvapp.py
ファイルをアップロードする画面が表示されるので、指定されたファイルをアップロードします。
📨 output
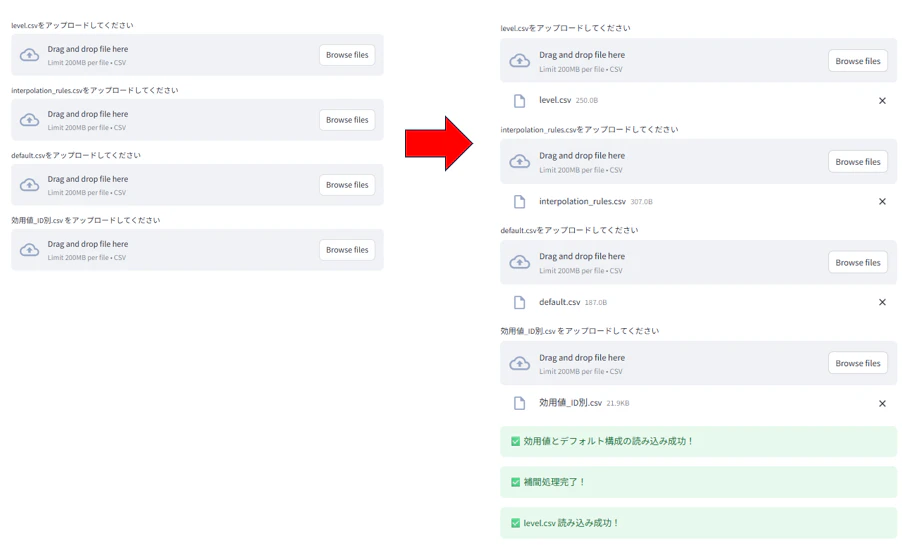
アップロード後、補完済みの効用値データ表示。
👉ダウンロード可能
📨 output
デフォルトの製品情報
📨 output
プルダウンで、比較したい属性を選択。
📨 output
📨 output
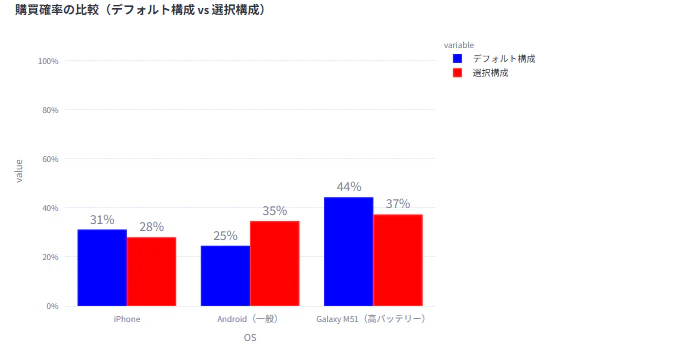
🎯グラフの色がやや鮮やかすぎる場合は、color_discrete_sequenceで調整可能です。
例えば ["#1f77b4", "#ff7f0e"] など、柔らかいトーンのカラーパレットにすることで見やすくなります。
製品構成を変更したときに、どのブランドの購買意向が上がるかを直感的に把握できるため、マーケティング施策や商品企画のシミュレーションにも活用できます。
📊 エクセルで作ったグラフを比較
🎯 前回、Excelで計算・可視化した結果と比較してみました。
Streamlitのグラフでは、効用値 → 購買確率の変換をロジットモデルで行っており
その際の平均の取り方や指数変換のタイミングがExcelと異なるため、若干の差が生じています。
とはいえ、傾向としては概ね一致しており
Pythonでもロジックが正しく再現されていることが確認できました。
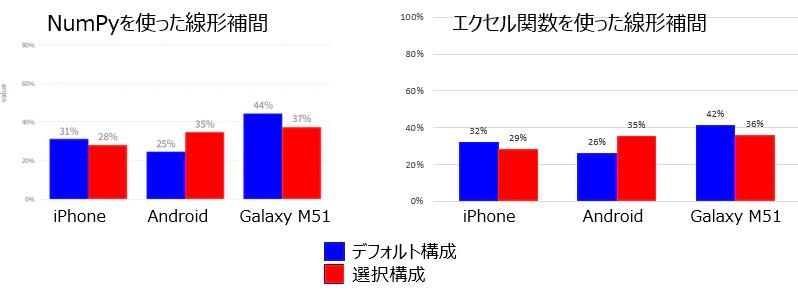
Pythonではnp.interp()で線形補間した効用値を使ってロジットモデルで購買確率を推定しています。
一方、Excelでは補間値に対して関数を適用して計算しているため、
処理順序や丸め誤差の違いにより数値に若干のズレが生じることがあります。
まとめ
エクセルでやると結構めんどうだった線形補間や効用値の計算が、
ブランドやスペックを選ぶだけでサクッと購買確率まで計算できちゃいます。
PythonとStreamlitなら、こんなUIも簡単に作れて便利です!