
はじめに
iOSエンジニアの皆さん、ユーザーから「アプリのストレージ使用量が多すぎる」というフィードバックを受けたことはありませんか?
本記事で紹介するのは、**数千万規模のユーザーを抱える決済系アプリ(フィンテック)**での事例です。決済アプリにとって、安定した動作と信頼性は命であり、ストレージの圧迫はUXの低下だけでなく、ユーザー離脱(チャーン)に直結する非常に深刻な課題です。
App Storeでのダウンロードサイズはわずか 130MB。それなのに、一部のユーザー環境で**ストレージ使用量(Documents & Data)**が 40GB にまで膨れ上がっていたとしたら……あなたならどうしますか?
最初は「OSの統計バグだろう」と疑いましたが、ログを調査したところ、そこには目を疑うような「ストレージのブラックホール」が存在していました。本記事では、この問題の特定から、ユーザー体験を損なわずに数GB単位のゴミを静かに掃除した実戦経験を共有します。
1. 意外な発見:40GBの正体は何だったのか?
インストール包は軽量であるにもかかわらず、オンラインモニタリングで判明したデータは衝撃的なものでした。
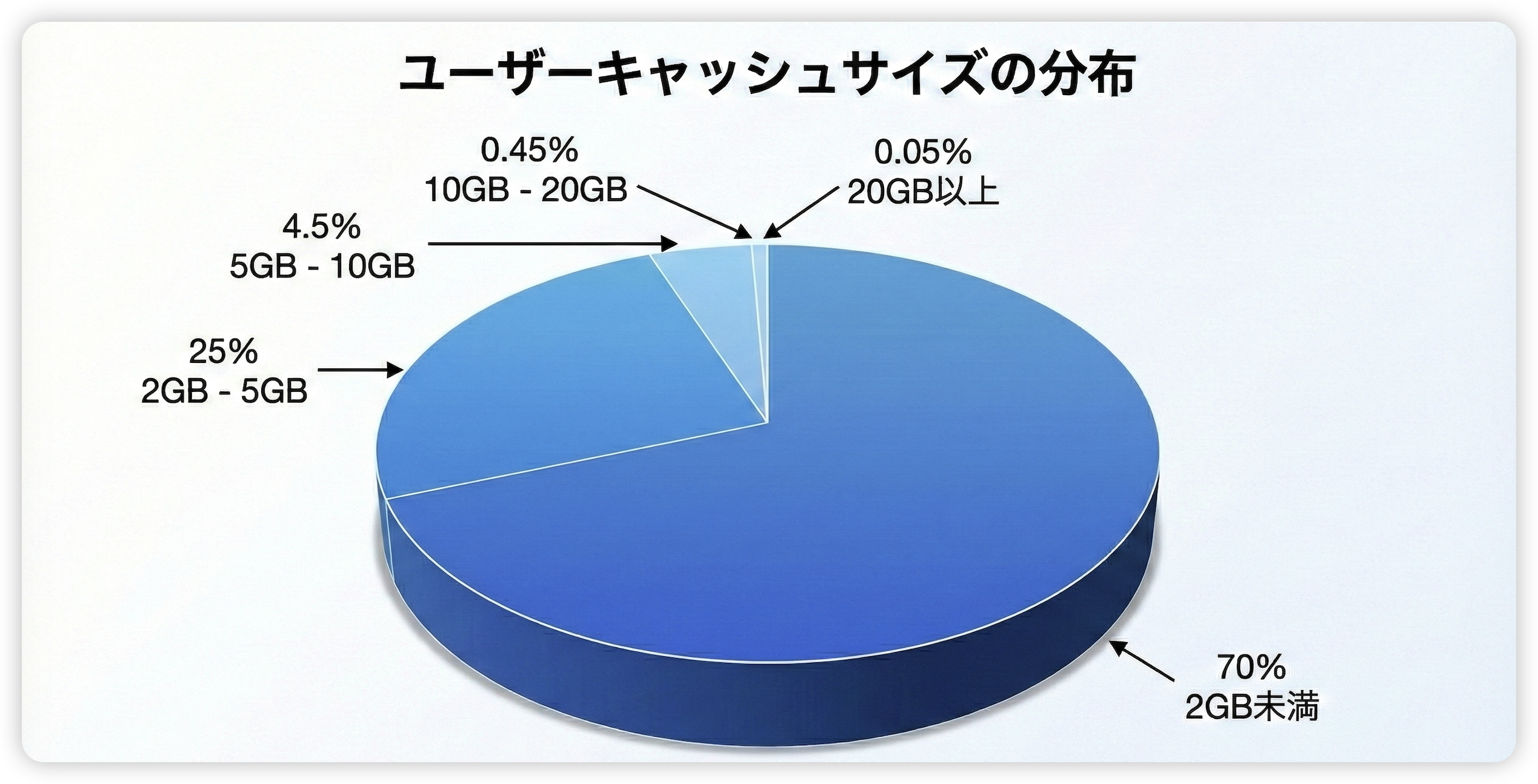
| キャッシュサイズ | ユーザー比率 | 深刻度 | 評価 |
|---|---|---|---|
| 2GB未満 | 70% | 正常 | 理想的な状態 |
| 2GB - 5GB | 25% | 正常 | 一般的な使用範囲 |
| 5GB - 10GB | 4.5% | 注意 | やや多い、監視対象 |
| 10GB - 20GB | 0.45% | 警告 | 異常蓄積の兆候 |
| 20GB以上 | 0.05% | 致命的 | システム遅延・アンインストールの主因 |
犯人の特定
ユーザーの端末を直接触ることはできないため、サンドボックス内のディレクトリ階層ごとにサイズを計算してレポートするログ機能を急遽実装しました。
Swift
// どのディレクトリが「空間」を食い潰しているのかを追跡
let targetPaths = [
"Documents",
"Library/Caches",
"Library/loglite", // ←最終的にここが原因と判明
"tmp"
]
// 各ディレクトリのサイズを計測し、ログ送信(イメージ)
func reportStorageUsage() {
let usageMap = targetPaths.map { path in
return [path: calculateSize(of: path)]
}
Analytics.track("storage_leak_hunt", properties: usageMap)
}
特定結果: 全ての原因は Library/loglite にありました。
これは特定のサードパーティ製SDK(決済系SDK)が生成するログフォルダでした。極端なケースでは、このフォルダだけで40.2GBを占有していました。
2. 原因分析:ネットワーク失敗が生んだ「負のループ」
SDK開発チームとの協議とソースコードの確認により、40GBまで膨らんだメカニズムが判明しました。
- 仕組み:SDKはユーザーのアクションごとにログを生成し、リアルタイムでサーバーへアップロードしようとする。
-
負のループ:オフラインや弱電界環境でアップロードに失敗すると、SDKはログを失わないようローカルの
logliteフォルダに保存し、次回の起動時に再試行する。 - 致命的な欠陥:蓄積されたログが巨大(GB単位)になると、弱電界環境ではアップロードがタイムアウトしやすくなり、さらに失敗率が上がる。
- 結果:ログが溜まれば溜まるほど成功率が下がり、最終的にローカルストレージを食い尽くす「ブラックホール」が完成する。
3. 解決策:いかに「スマートに」掃除するか?
すでに発生してしまった数十GBのキャッシュに対し、一斉に強制削除を行うのはリスクが伴います。そこで、私たちは**「三段構え」**の防御体系を構築しました。
案1:SDKにリベンジの機会を与える(能動的アップロード)
アプリ起動時にSDKの非同期アップロードAPIを明示的に呼び出します。
- 狙い:ネットワーク環境が改善したタイミングで「借金(未送信ログ)」を返済させる。
- 限界:数万個のログファイルが溜まっているユーザーの場合、アップロード処理自体がタイムアウトしてしまい、効果が限定的でした。
案2:【本命】構成管理によるバックグラウンド・セグメント削除
これが今回の対策のキモです。**AMCS(モバイル構成管理センター)**を利用して、クリーンアップ戦略を動的に配信するようにしました。
① なぜ「グレー配信(段階的適用)」なのか?
40GBものファイルを一気に削除すると、ディスクI/Oが集中し、アプリのフリーズやOSのWatchdogによる強制終了を招く恐れがあります。そこで、影響の大きいユーザーから順に、割合を制御しながら適用しました。
JSON
// AMCS(モバイル構成管理)から配信されるクリーンアップ戦略の例
{
"clean_strategy": [
{
"threshold": "20GB",
"gray_ratio": 1.0,
"delete_ratio": 0.95
}, // 【致命的】20GB以上の全ユーザーを対象に、ほぼ全てのキャッシュを強制削除
{
"threshold": "5GB",
"gray_ratio": 0.2,
"delete_ratio": 0.5
} // 【注意】5GB以上のユーザーの20%にテスト配信し、半分だけ掃除
]
}
② Background Task によるサイレント実行
ユーザーの操作を妨げないよう、アプリがバックグラウンドに回った瞬間に削除処理を開始し、いつでも中断可能な設計にしました。
Swift
class LogCleanManager {
private var cleanTask: DispatchWorkItem?
func applicationDidEnterBackground() {
// アプリが裏側に回ったら作業開始
cleanTask = DispatchWorkItem { [weak self] in
self?.performSelectiveClean()
}
DispatchQueue.global(qos: .background).async(execute: cleanTask!)
}
func applicationWillEnterForeground() {
// ユーザーが戻ってきたら、作業途中でも即中断してI/Oをメインスレッドに返す
cleanTask?.cancel()
}
}
案3:ユーザーに最終手段を与える
「設定 > キャッシュ削除」メニューに、当該SDKのパスも対象に含めました。あくまで予備手段ですが、ユーザー自身が「自衛」できる手段を提供することで、カスタマーサポートへの不満を軽減しました。
4. 今後の最適化:火消しの次は「防火」
今回の危機を脱した後、二度と「40GBの悪夢」を見ないよう長期的メカニズムを導入しました。
① アプリ内の「自浄メカニズム」の実装
クラウドからの指示を待つだけでなく、アプリ自身に「自律性」を持たせました。
Swift
func schedulePeriodicCheck() {
// 1日1回巡回し、500MBの閾値を超えたら予防的にクリーンアップを実行
Timer.scheduledTimer(withTimeInterval: 24 * 60 * 60, repeats: true) { _ in
if getLogLiteSize() > 500 * 1024 * 1024 {
performPreventiveClean()
}
}
}
② SDKベンダーへのフィードバックと改善
「根本的な解決」のためにSDKチームと協議し、以下の改善を約束しました。
-
容量上限の設定:SDK内部で
MaxCapacityを設け、古いログから自動上書きする。 - チャンクアップロード:巨大なファイルを分割して送信し、弱電界での成功率を高める。
③ アラートモニタリングの構築
リアルタイム監視ダッシュボードを構築しました。キャッシュサイズのP95値が異常変動を検知すると、開発チームへ自動でアラートが飛ぶ仕組みになっており、ユーザーがアプリを削除する前に対応できる体制を整えました。
5. 最終的な成果と振り返り
1ヶ月間の段階的リリースを経て、結果は予想以上のものでした。
- キャッシュサイズの P99値(99パーセンタイル):8.5GB から 1.2GB へ削減。
- 問題ユーザーの解消:20GB超のユーザー 10,015名 を対処し、該当率をほぼ 0% に。
- 直接削減量:これらのユーザーから 300TB以上 のキャッシュを削除。
まとめ
今回の経験で痛感したのは、**「サードパーティSDKを盲信してはいけない」**ということです。複雑なビジネス要件下では、何気ないファイル書き込みが、特定の条件でストレージを食い尽くすブラックホールへと変貌します。
もしこの記事が参考になったら、ぜひ「いいね」やコメントをお願いします!