非構造化データのメタデータ管理を簡素化してくれそうなアップデートがあったので、試してみる。
何者か
S3 Metadataはオブジェクト単位のメタデータを自動的に吸い上げる仕組み。従来のインベントリ機能との違いは、システム定義のメタデータに加えてカスタムメタデータが付けられる点と、後述のS3 Tablesをターゲットとしてニアリアルタイムで更新してくれる点と思われる。
S3 TablesはマネージドIcebergテーブルとも呼ぶべきもので、テーブルバケットという新しいバケット上のIcebergテーブルで上記のメタデータを管理し、検索を可能にする仕組み。都度Glueテーブルを作る必要がなくなり、かつ自動的なメンテナンスで性能を維持してくれる模様。
と、今のところはざっくり理解しておくことにする。
ステップバイステップ
1. テーブルバケットを作成
S3コンソールが新しくなり、テーブルバケットなるものが作れるようになっているので、まずはここからアクセス。
なお、現時点では限られたリージョンでしか利用できない点に注意。今回はバージニア北部(us-east-1)で操作している。
初回は「統合を有効にする」をクリックして、専用のデータカタログ(s3tablescatalog)を作成し、Lake Formationに登録する作業が必要。
[2024/12/6追記] CLIでセットアップすることもできるようだが、2024年12月6日現在、公式ドキュメントにバグがあり、記載の手順では有効化できないため注意。


テーブルバケット名を入力して作成する。

テーブルバケットができた。
メタデータテーブル自体はまだ作成されていない。

テーブルを作成するにはEMRが云々とあるが、次のステップでマネジメントコンソールから作成できるのでいったん無視する。
2. メタデータ設定を作成
次に、通常のバケットを作成し、「メタデータ」プロパティからメタデータ設定を作成する。

送信先テーブルバケットにはテーブルバケット名、メタデータテーブル名は特に支障なければ生成された値(当該の汎用バケット名から自動生成される)を使用する。

できた。

テーブルバケットの方はこんな感じ。
他にもCLIやEMRなど複数の方法で作れるようだが、マネジメントコンソールから作れれば今回は充分。

3. メタデータを検索してみる
まず、適当なファイルをアップロードしておく。
今回は、昨日出たBedrock LLM as a judgeの検証用に作成した評価用ファイルをいくつか投げ込んでみる。

次にAWS CLIを最新化し、aws s3tablesコマンドでいろいろ試してみる。
> brew upgrade awscli
...
> aws --version
aws-cli/2.22.10 Python/3.12.7 Darwin/24.1.0 source/arm64
> aws s3tables get-table-bucket \
--table-bucket-arn arn:aws:s3tables:us-east-1:(省略):bucket/my-table-bucket-(省略)
{
"arn": "arn:aws:s3tables:us-east-1:(省略):bucket/my-table-bucket-(省略)",
"name": "my-table-bucket-(省略)",
"ownerAccountId": "(省略)",
"createdAt": "2024-12-04T01:23:26.102834+00:00"
}
> aws s3tables get-table-metadata-location \
--table-bucket-arn arn:aws:s3tables:us-east-1:(省略):bucket/my-table-bucket-(省略) \
--namespace aws_s3_metadata \
--name s3metadata_s3_metadata_test_(省略)
{
"versionToken": "f711868a57d92610b21a",
"metadataLocation": "s3://8669cd9f-71a3-4c60-m15(省略)tu8xkuse1b--table-s3/metadata/00001-da115e3f-0e54-492f-97fa-d6709847bf48.metadata.json",
"warehouseLocation": "s3://8669cd9f-71a3-4c60-m15(省略)tu8xkuse1b--table-s3"
}
とりあえず何かあることはわかった。
ただ、aws s3tablesコマンドを見渡した限りでは、メタデータ自体をクエリーするコマンドはなさそうである。
公式を見てみると、自動でs3tablescatalogなるカタログが同一リージョンのGlueデータカタログ内に作成される、とあるので、そっちに飛んでみる。

まだ作成されてなかった。 しばらく待つしかなさそうだ。
ただ、Icebergテーブルと並んで、ここがS3テーブルバケット内のメタデータ分析の肝の一つと見られるので、今日のところは、カタログが自動作成されてS3テーブルがマッピングされるのを楽しみに待つこととしたい。
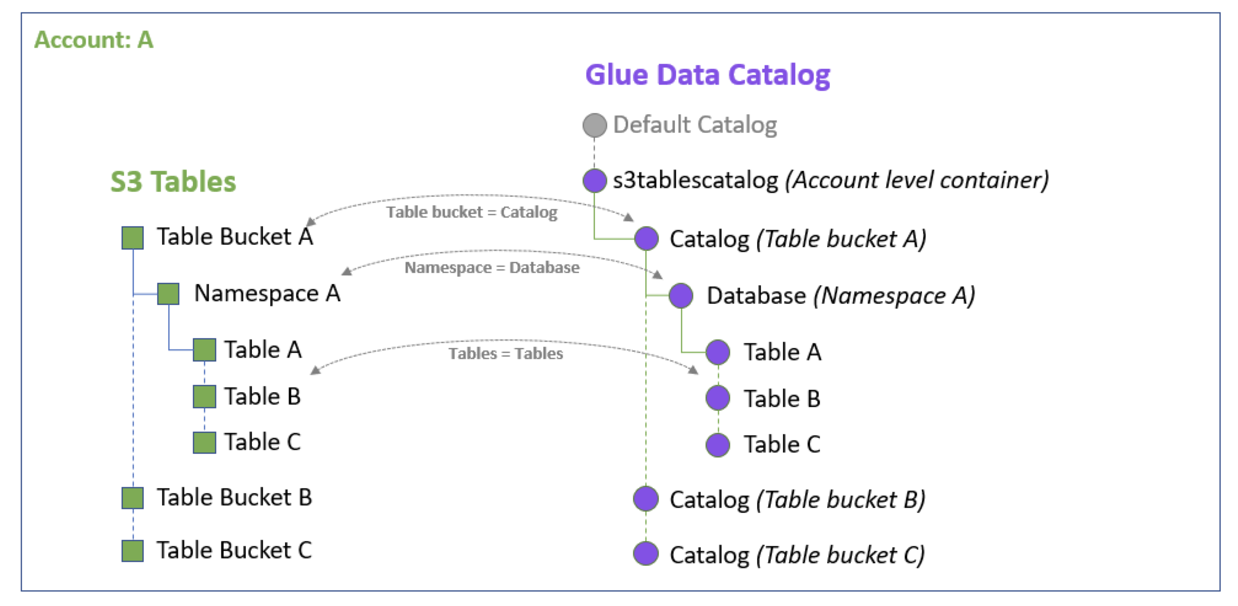
(出典:https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-integrating-aws.html )
[2024/12/6追記] 本来は、数十秒かからず完了するのが正しいらしい。自分のテーブルバケット設定には何らかの異常が発生しているらしく、ステータスが「不明」となっている(通常は「無効」または「有効」)ため作成されていない模様。
また、正常に作成された場合も、404エラーでAthena上ではまだクエリーできない。
まだプレビューということもあり、しばらく熟成を待った方が良さそうだ。

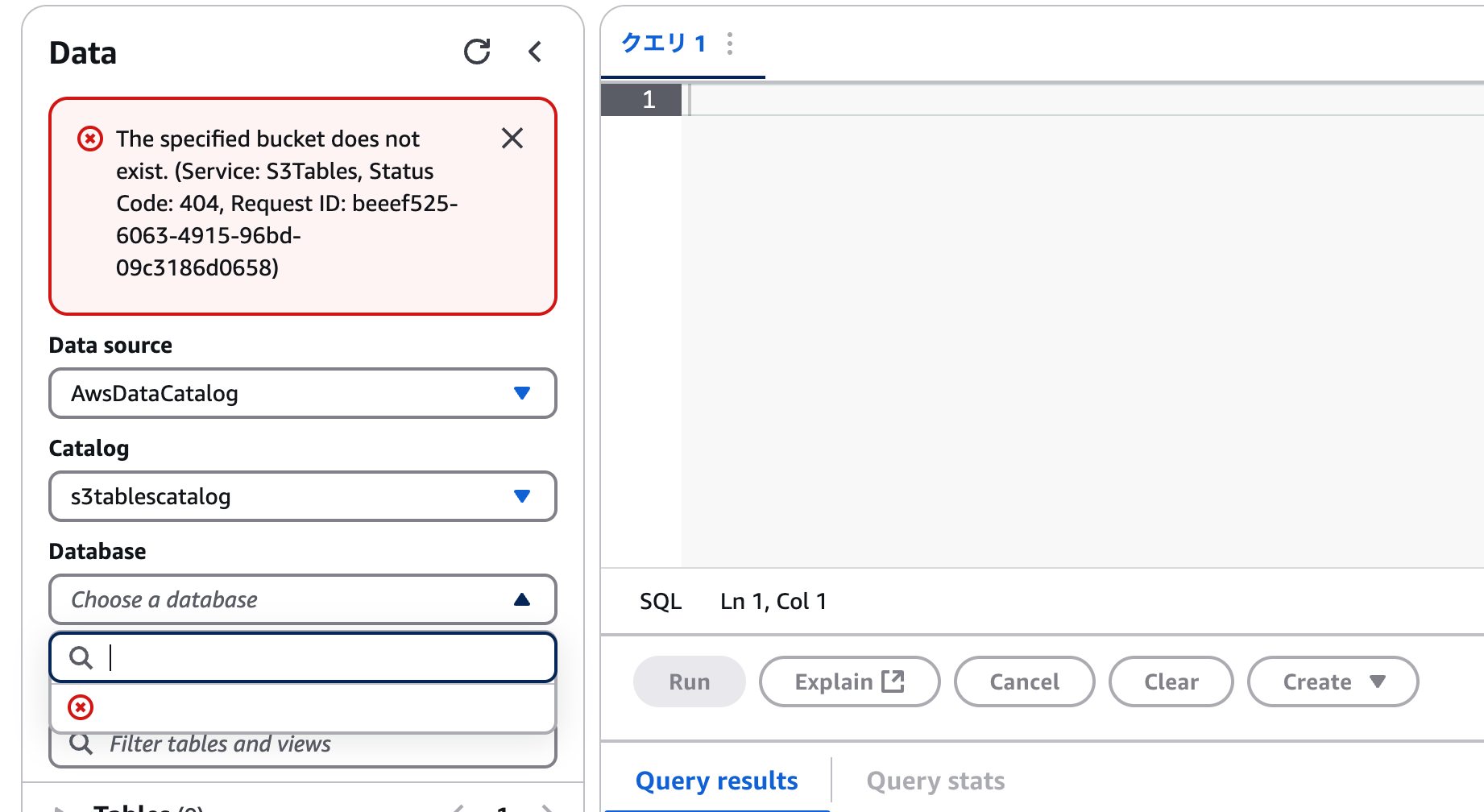
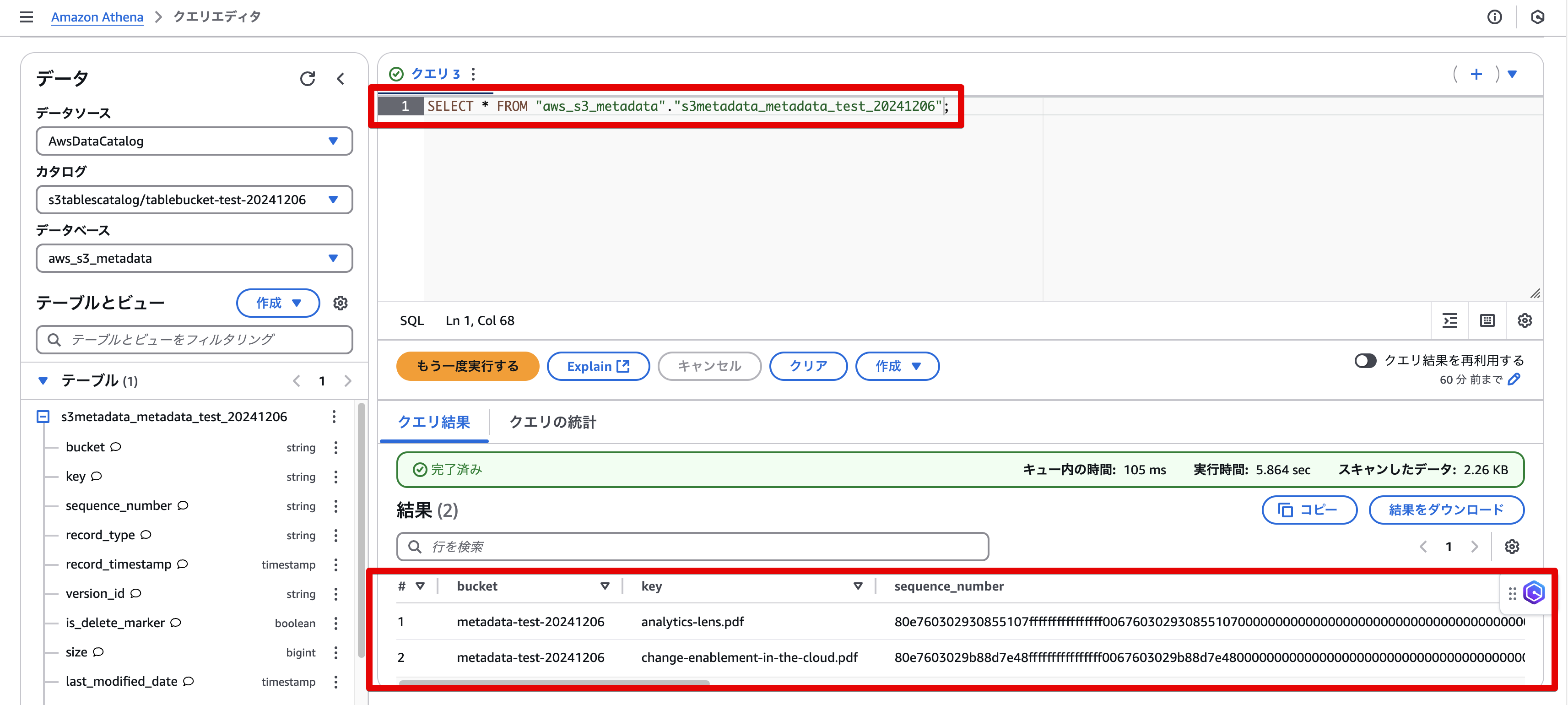
[2024/12/16追記] 最近になって(前回更新からの10日間の間に)カタログの表示が変わり、データベースの方も表示されるようになった。
実はこの状態のままだとまだエラーになるのだが、Lake Formationで該当カタログとテーブルに権限をGrantすることで、ようやくAthenaクエリーが成功した。

まとめ
S3 MetadataとS3 Tablesの挙動を(途中までだが)一通り触ってみた。
ディレクトリバケット、S3オブジェクトへのappendのサポートなど、最近のS3機能の拡張は、以前のような非機能面やコスト面の改善に留まらず、特定のユースケースを後押しするようなものが増えている気がする。
実際、非構造化データのメタデータを管理・検索・分析したい要件は一定程度ある。
今のところ一部機能はプレビューだが、いずれGAすれば、DataZoneあたりと連携してS3メタデータをデータアセットとして公開する、といった用途にも使えるのでは、という期待感がある。