はじめに
この最新NICであるAcceleronの前段としてOCIのNICに関する特徴についておさらいしましょう。
OCIはリリース時の1つの特徴はオフボックス仮想化でした。
オフボックス仮想化は、通常はハイパーバイザー・ホスト上で行われるネットワーク/ストレージ仮想化とクラウド制御処理を、サーバーの外側にある専用ハードウェアであるCloud Control Computer(以後CCCと記載)で実行し、これによりベアメタルの自由度、VMのセキュリティ向上、ハイパーバイザーのオーバーヘッドを削減による性能向上を実現しました。
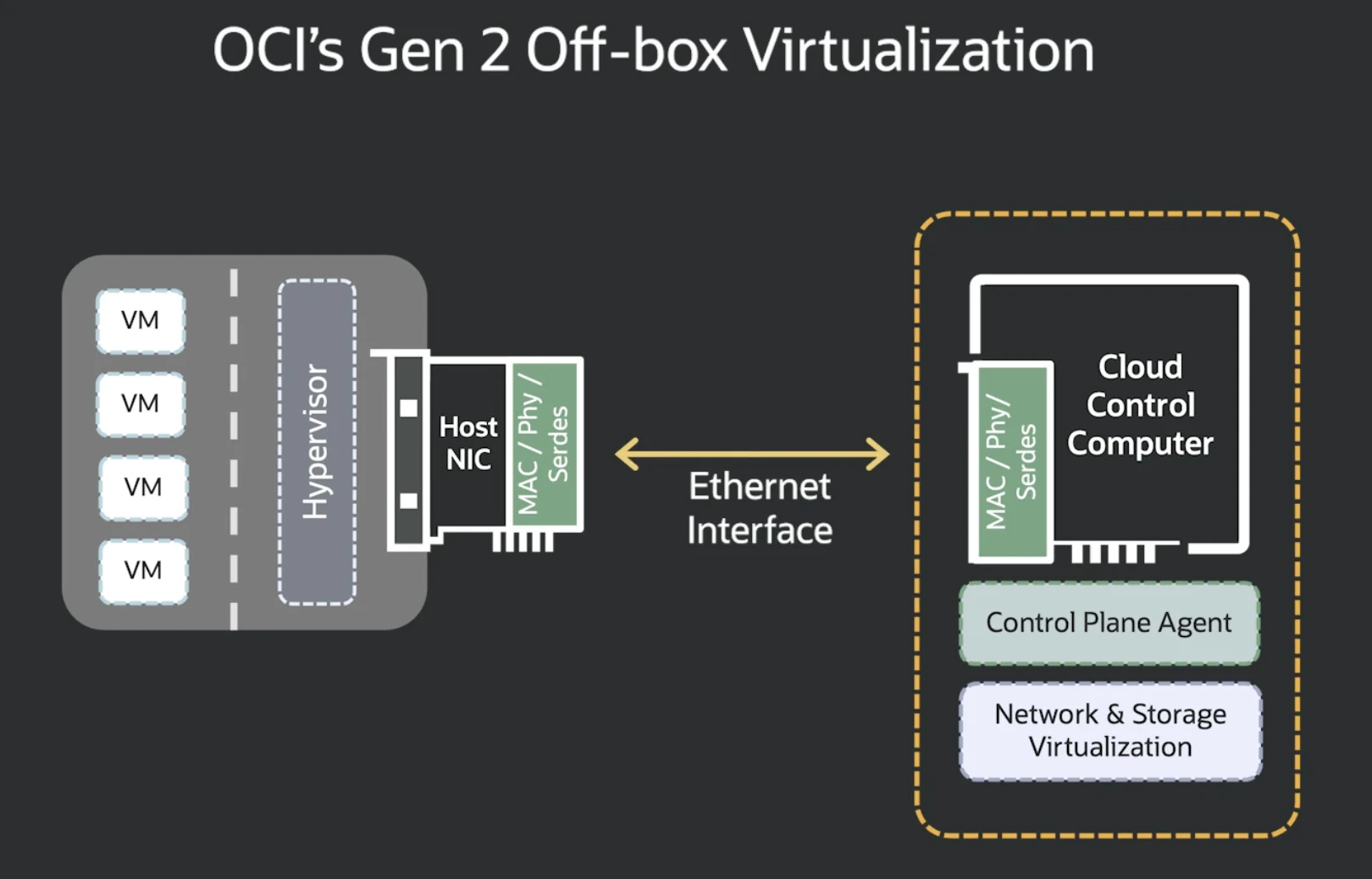
これが最新のNICであるAcceleronではオフボックスで構成されていたCCCの機能とホストNICを同一シリコン上に統合したConverged NIC/SmartNICで実現しました。
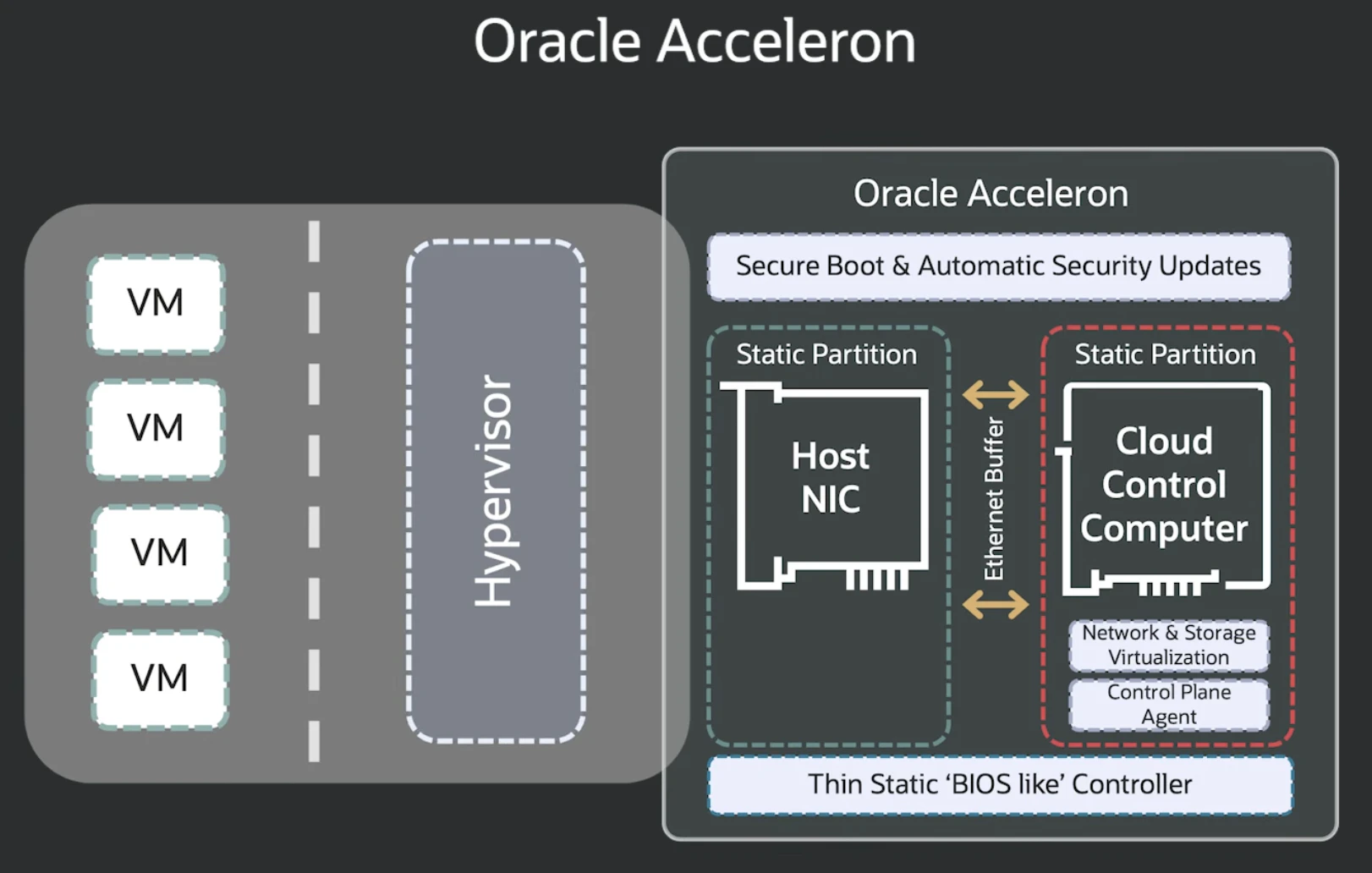
従来はNICとCCCの間に物理的なEthernet相当の接続があり、MAC/PHYなどの回路ブロックが必要でした。Acceleronでは、それを一つのNIC上で実現することで物理的なEthernetケーブル、PHY/MAC/SerDesを減らすことでデータパスが短くなり、レイテンシと電力消費を削減することができます。
本記事で確認したいこと
本記事ではこのレイテンシに注目してAcceleronでの効果を確認していきたいと思います。
利用するインスタンスは以下になります。これらを2インスタンス起動し、pingなどでレイテンシを確認していきたいと思います。
また、効果を見極めやすいように最低限のスペックである1コア構成としています。
| Shape名 | NICタイプ | コア数 | メモリ容量(GB) | ネットワーク帯域(Gbps) |
|---|---|---|---|---|
| VM.Standard3.Flex | 旧(Off-box仮想化) | 1 | 16 | 1 |
| VM.Standard4.Ax.Flex | 新(Acceleron) | 1 | 16 | 1 |
計測する上でのポイント
物理的に近い位置にインスタンスを配置
ネットワークのレイテンシを計測するので、Cluster Placement Groupを利用してデプロイされる両インスタンスが物理的に近い位置で配置されるようにします。
vNICタイプ
旧NICについてはvNICのタイプとして以下が選択可能なため両方で確認します。
- PARAVIRTUALIZED (ハイパーバイザーを経由する準仮想化ネットワーク)
- VFIO (SR-IOVで、NICのハードウェアレベルでの仮想化されたもの)
デフォルトではPARAVIRTUALIZEDが選択されますが、低レイテンシや高パケットレートを重視するワークロードでは、SR-IOV/VFIOの利用が適しています。一方で、PARAVIRTUALIZEDは汎用性や運用面の柔軟性に利点があります。
計測
ping
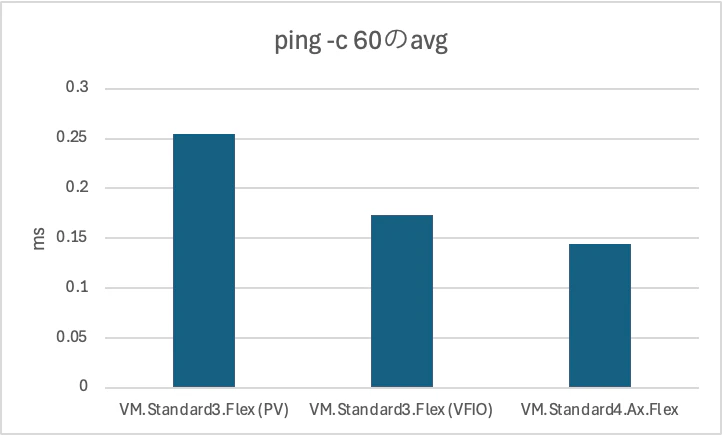
まずはシンプルにpingでのレイテンシを比較してみましょう。
計測の詳細
### VM.Standard3.FlexPV
60 packets transmitted, 60 received, 0% packet loss, time 60456ms
rtt min/avg/max/mdev = 0.194/0.255/0.362/0.041 ms
VFIO
60 packets transmitted, 60 received, 0% packet loss, time 60426ms
rtt min/avg/max/mdev = 0.145/0.173/0.249/0.020 ms
VM.Standard4.Ax.Flex
60 packets transmitted, 60 received, 0% packet loss, time 60436ms
rtt min/avg/max/mdev = 0.104/0.144/0.769/0.082 ms
pingpong
pingpong(IMB-MPI1 pingpong)は主にHPC領域でインスタンス間のレイテンシやスループットの計測で利用されるツールです。転送Byte sizeが0byteから4MBの範囲で計測されるので、どのような特性かを判断する上で有用なツールです。
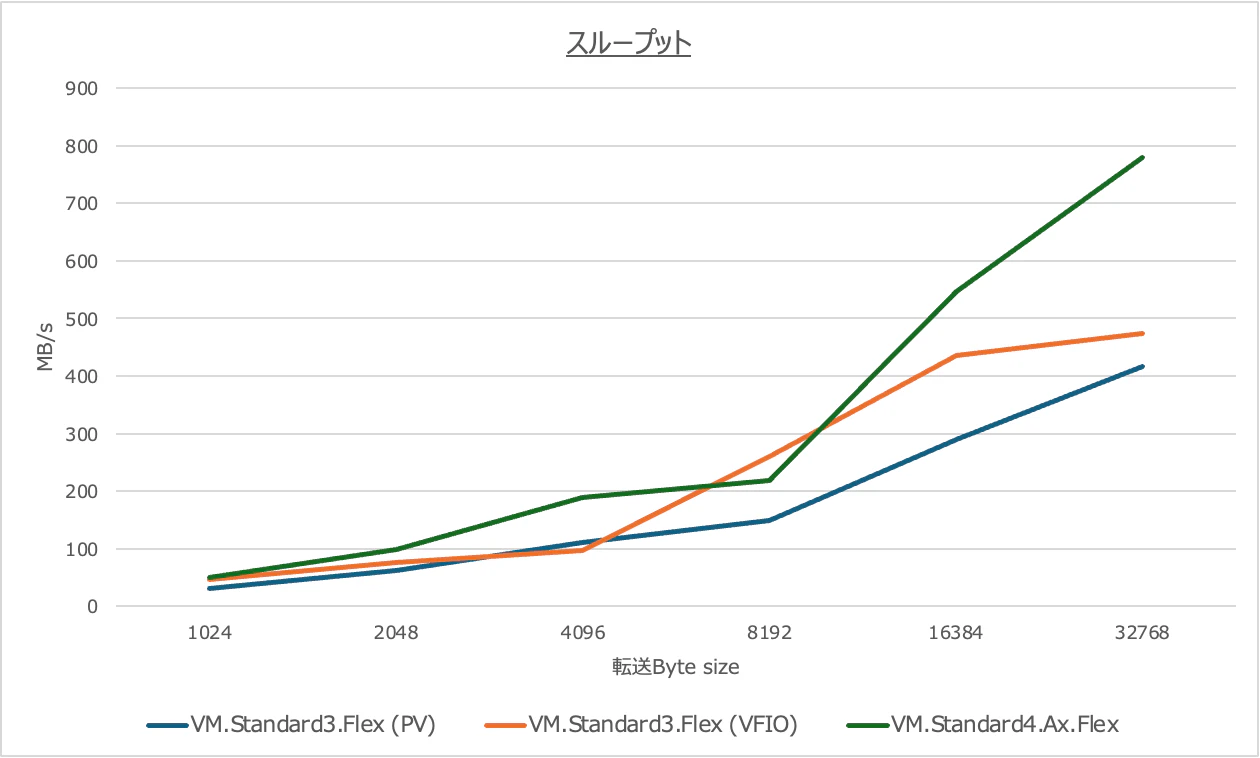
これでスモールパケットでのレイテンシとスループットをみていきましょう。
レイテンシ

スループット
計測の詳細
VM.Standard3.Flex
PV
[opc@network-latency-vm-s3-01 ~]$ mpirun --mca pml ucx --mca osc ucx --mca btl ^vader,tcp,openib,uct -x UCX_TLS=tcp,self,sm -x UCX_NET_DEVICES=ens3 --mca coll_hcoll_enable 0 -x HCOLL_ENABLE_MCAST_ALL=0 --use-hwthread-cpus --bind-to hwthread --map-by hwthread --rank-by hwthread --report-bindings -np 2 -H 10.0.0.59:1,10.0.0.254:1 /usr/mpi/gcc/openmpi-4.1.7rc1/tests/imb/IMB-MPI1 pingpong
[network-latency-vm-s3-01:04221] MCW rank 0 bound to socket 0[core 0[hwt 0]]: [B.]
[network-latency-vm-s3-02:04275] MCW rank 1 bound to socket 0[core 0[hwt 0]]: [B.]
#------------------------------------------------------------
# Intel (R) MPI Benchmarks 2018, MPI-1 part
#------------------------------------------------------------
# Date : Fri May 8 15:37:46 2026
# Machine : x86_64
# System : Linux
# Release : 4.18.0-553.60.1.el8_10.x86_64
# Version : #1 SMP Wed Jul 9 04:04:33 PDT 2025
# MPI Version : 3.1
# MPI Thread Environment:
# Calling sequence was:
# /usr/mpi/gcc/openmpi-4.1.7rc1/tests/imb/IMB-MPI1 pingpong
# Minimum message length in bytes: 0
# Maximum message length in bytes: 4194304
#
# MPI_Datatype : MPI_BYTE
# MPI_Datatype for reductions : MPI_FLOAT
# MPI_Op : MPI_SUM
#
#
# List of Benchmarks to run:
# PingPong
#---------------------------------------------------
# Benchmarking PingPong
# #processes = 2
#---------------------------------------------------
#bytes #repetitions t[usec] Mbytes/sec
0 1000 31.91 0.00
1 1000 30.15 0.03
2 1000 30.36 0.07
4 1000 29.93 0.13
8 1000 30.41 0.26
16 1000 29.91 0.53
32 1000 30.09 1.06
64 1000 30.02 2.13
128 1000 30.73 4.17
256 1000 30.96 8.27
512 1000 36.54 14.01
1024 1000 33.28 30.77
2048 1000 33.45 61.23
4096 1000 36.94 110.88
8192 1000 54.82 149.44
16384 1000 56.40 290.47
32768 1000 78.77 416.01
65536 640 147.94 442.99
131072 320 252.07 519.98
262144 160 1205.68 217.42
524288 80 2636.29 198.87
1048576 40 4147.95 252.79
2097152 20 9541.63 219.79
4194304 10 23170.99 181.02
# All processes entering MPI_Finalize
VFIO
[opc@network-latency-vm-s3-01 ~]$ mpirun \
> --mca pml ucx \
> --mca osc ucx \
> --mca btl ^vader,tcp,openib,uct \
> -x UCX_TLS=tcp,self,sm \
> -x UCX_NET_DEVICES=ens3 \
> --mca coll_hcoll_enable 0 \
> -x HCOLL_ENABLE_MCAST_ALL=0 \
> --use-hwthread-cpus \
> --bind-to hwthread \
> --map-by hwthread \
> --rank-by hwthread \
> --report-bindings \
> -np 2 \
> -H 10.0.0.59:1,10.0.0.254:1 \
> /usr/mpi/gcc/openmpi-4.1.7rc1/tests/imb/IMB-MPI1 pingpong
[network-latency-vm-s3-01:05996] MCW rank 0 bound to socket 0[core 0[hwt 0]]: [B.]
[network-latency-vm-s3-02:06082] MCW rank 1 bound to socket 0[core 0[hwt 0]]: [B.]
#------------------------------------------------------------
# Intel (R) MPI Benchmarks 2018, MPI-1 part
#------------------------------------------------------------
# Date : Fri May 8 15:33:19 2026
# Machine : x86_64
# System : Linux
# Release : 4.18.0-553.60.1.el8_10.x86_64
# Version : #1 SMP Wed Jul 9 04:04:33 PDT 2025
# MPI Version : 3.1
# MPI Thread Environment:
# Calling sequence was:
# /usr/mpi/gcc/openmpi-4.1.7rc1/tests/imb/IMB-MPI1 pingpong
# Minimum message length in bytes: 0
# Maximum message length in bytes: 4194304
#
# MPI_Datatype : MPI_BYTE
# MPI_Datatype for reductions : MPI_FLOAT
# MPI_Op : MPI_SUM
#
#
# List of Benchmarks to run:
# PingPong
#---------------------------------------------------
# Benchmarking PingPong
# #processes = 2
#---------------------------------------------------
#bytes #repetitions t[usec] Mbytes/sec
0 1000 21.98 0.00
1 1000 22.09 0.05
2 1000 22.09 0.09
4 1000 22.02 0.18
8 1000 22.06 0.36
16 1000 22.05 0.73
32 1000 18.60 1.72
64 1000 20.79 3.08
128 1000 23.32 5.49
256 1000 17.90 14.31
512 1000 18.18 28.16
1024 1000 21.67 47.25
2048 1000 26.95 75.99
4096 1000 42.19 97.08
8192 1000 31.39 260.98
16384 1000 37.55 436.36
32768 1000 69.11 474.15
65536 640 457.88 143.13
131072 320 901.05 145.47
262144 160 1149.46 228.06
524288 80 3290.92 159.31
1048576 40 4003.53 261.91
2097152 20 18738.17 111.92
4194304 10 25352.60 165.44
# All processes entering MPI_Finalize
VM.Standard4.Ax.Flex
[opc@network-latency-vm-s4-01 ~]$ mpirun \
> --mca pml ucx \
> --mca osc ucx \
> --mca btl ^vader,tcp,openib,uct \
> -x UCX_TLS=tcp,self,sm \
> -x UCX_NET_DEVICES=enp0s5 \
> --mca coll_hcoll_enable 0 \
> -x HCOLL_ENABLE_MCAST_ALL=0 \
> --use-hwthread-cpus \
> --bind-to hwthread \
> --map-by hwthread \
> --rank-by hwthread \
> --report-bindings \
> -np 2 \
> -H 10.0.0.50:1,10.0.0.175:1 \
> /usr/mpi/gcc/openmpi-4.1.7rc1/tests/imb/IMB-MPI1 pingpong
[network-latency-vm-s4-01:06913] MCW rank 0 bound to socket 0[core 0[hwt 0]]: [B.]
[network-latency-vm-s4-02:06561] MCW rank 1 bound to socket 0[core 0[hwt 0]]: [B.]
#------------------------------------------------------------
# Intel (R) MPI Benchmarks 2018, MPI-1 part
#------------------------------------------------------------
# Date : Wed May 6 03:27:36 2026
# Machine : x86_64
# System : Linux
# Release : 4.18.0-553.60.1.el8_10.x86_64
# Version : #1 SMP Wed Jul 9 04:04:33 PDT 2025
# MPI Version : 3.1
# MPI Thread Environment:
# Calling sequence was:
# /usr/mpi/gcc/openmpi-4.1.7rc1/tests/imb/IMB-MPI1 pingpong
# Minimum message length in bytes: 0
# Maximum message length in bytes: 4194304
#
# MPI_Datatype : MPI_BYTE
# MPI_Datatype for reductions : MPI_FLOAT
# MPI_Op : MPI_SUM
#
#
# List of Benchmarks to run:
# PingPong
#---------------------------------------------------
# Benchmarking PingPong
# #processes = 2
#---------------------------------------------------
#bytes #repetitions t[usec] Mbytes/sec
0 1000 19.97 0.00
1 1000 19.82 0.05
2 1000 19.85 0.10
4 1000 19.82 0.20
8 1000 19.89 0.40
16 1000 19.94 0.80
32 1000 19.79 1.62
64 1000 19.75 3.24
128 1000 19.83 6.45
256 1000 19.98 12.81
512 1000 20.00 25.60
1024 1000 20.33 50.37
2048 1000 20.86 98.20
4096 1000 21.76 188.26
8192 1000 37.55 218.19
16384 1000 29.99 546.36
32768 1000 41.99 780.46
65536 640 235.17 278.67
131072 320 460.99 284.33
262144 160 789.73 331.94
524288 80 3005.39 174.45
1048576 40 5485.85 191.14
2097152 20 11031.05 190.11
4194304 10 11590.27 361.88
# All processes entering MPI_Finalize
まとめ
OCIの最新NICであるAcceleronを採用したVM.Standard4.Ax.Flexと、従来世代のVM.Standard3.Flexを比較し、インスタンス間ネットワークレイテンシとpingpongの特性を確認しました。
pingでは、Acceleronが最も低い平均RTTを示しました。
pingpongでは、Acceleronは特に小〜中サイズのメッセージで低く安定したレイテンシを示し、1KB〜4KB、16KB〜32KBなど複数のサイズ帯で旧NIC構成を上回る結果となりました。スループットについても複数のサイズ帯で良好な結果が確認できました。
以上のことから特にネットワークのレイテンシという観点ではAcceleronの効果がみられたのではないかと思います。