このPull Requestは2026/01/20に無事にマージされました!
https://github.com/langgenius/dify-official-plugins/pull/2450
本手順に利用するOCI Generative AIのcohere.embed-v4.0のDifyでのVISION対応は現在Pull Request中です。利用についてはマージされるまでお待ちください!
https://github.com/langgenius/dify-official-plugins/pull/2450
DifyのMultimodal Knowledge Baseとは?
DifyではRAGに関する機能をKnowledge Baseと呼んでいます。
これまでKnowledge Baseに登録できるのはテキスト情報でしたが、v1.11.0では画像もEmbeddingして管理できるようになります。
整理すると以下のようになります。

詳細は以下のリリースノートをご確認ください。
OCI Generative AIのどのモデルがVISION対応した?
OCIでは画像のEmbedingができるモデルとしてCohere Embed v4が利用可能です。
なお利用可能なリージョンは以下。
- 日本中央部(大阪)
- サウジアラビア中央部(リヤド)
- 米国中西部(シカゴ)
動かしてみよう
テストデータ
検証するためのテストデータを準備します。
Multimodal Knowledge Baseとしては対応しているのはマークダウンのみで、さらに画像は以下のようにのような形式でダウンロードできる必要があります。
今回は以下の流れでデータを準備しました。
- ChatGPTにお願いしてシンプルなマークダウンテキストと画像を生成してもらう
- OCIのObject StorageにPublicでアクセスできるBucketを作成し、生成された画像をアップロード
- 生成されたマークダウンテキストに画像のURLを挿入する
実際のマークダウンファイルは以下になります。※Object Storageのnamespaceは伏せています。
# Multimodal KB Simple Test (Markdown)
このテストデータは、Difyの**マルチモーダル(画像も参照して答える)**動作を、誰でも直感的に確認できるように作ったものです。
「画像に書いてある情報」を質問すると、うまく動いていれば**画像の中身を根拠に回答**できます。
> 画像はすべて合成(Mock)です。実在の店舗・施設とは関係ありません。
---
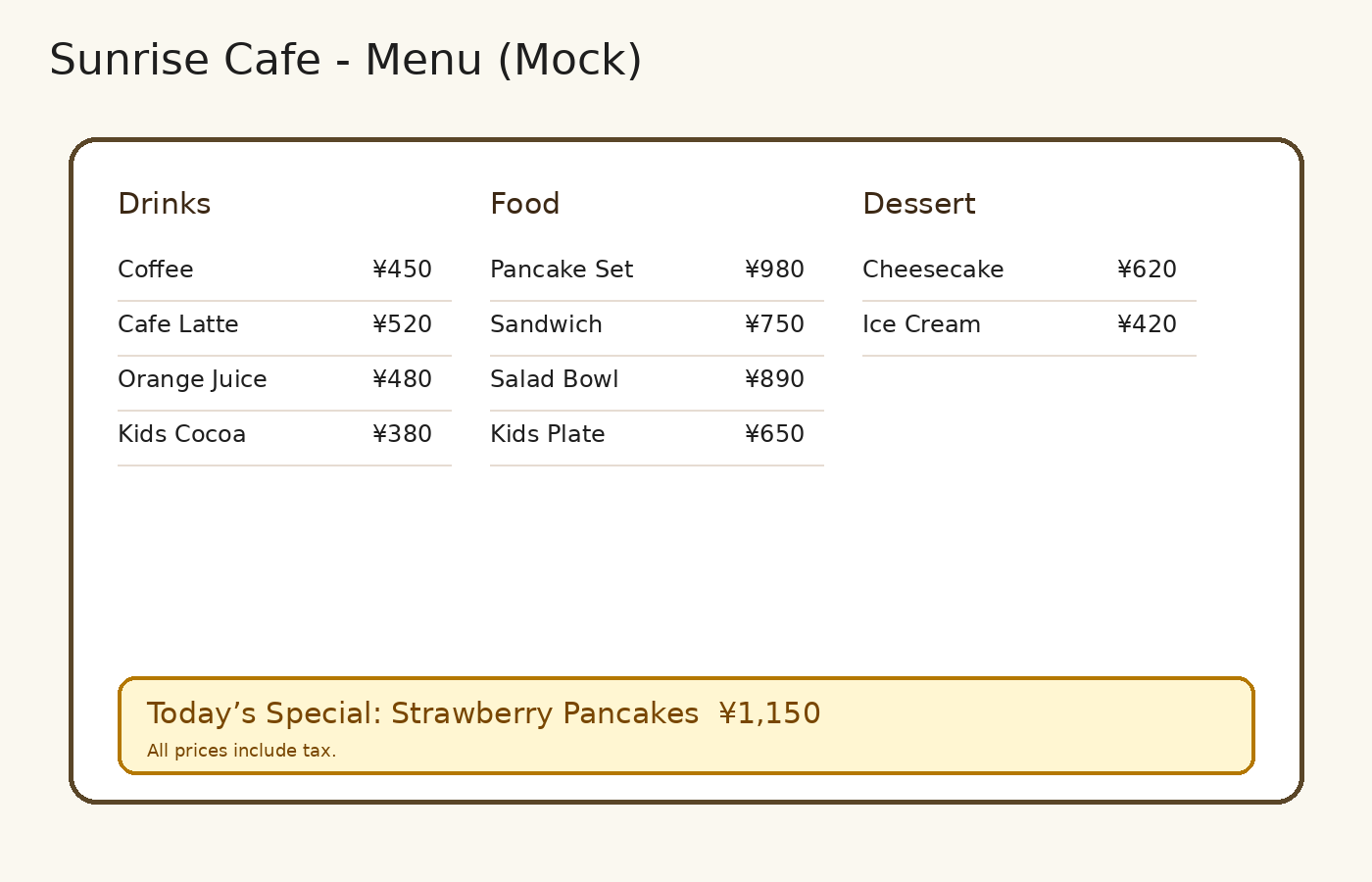
## 1. カフェのメニュー(画像にしかない価格を質問する)
次の画像はカフェのメニューです。

---
## 2. 週末イベントのチラシ(日時・場所・料金が画像にある)
次の画像はイベントのチラシです。

---
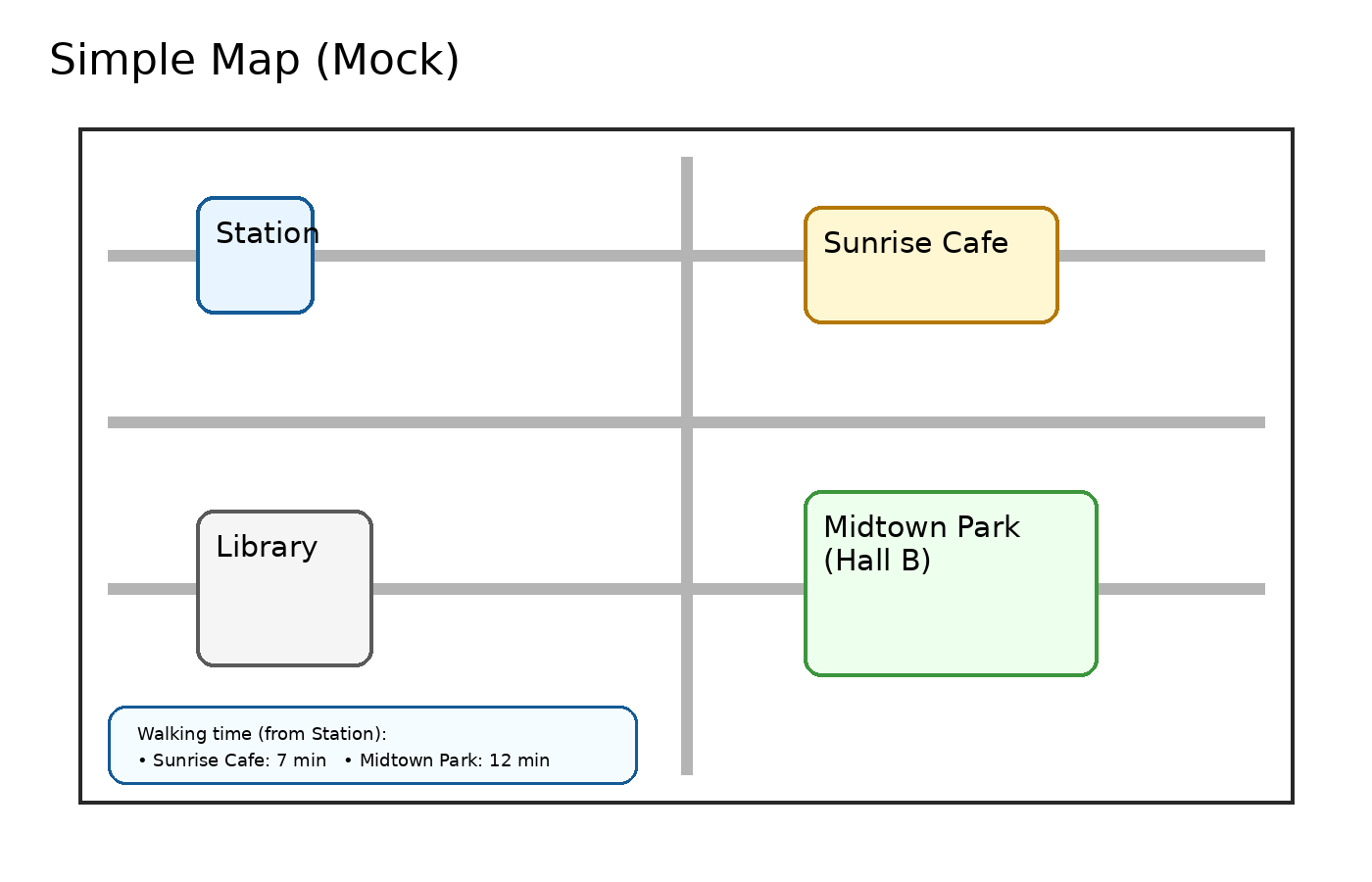
## 3. 簡易マップ(場所名と徒歩時間を画像から読む)
次の画像は簡単な地図です。

---
ぞれそれのファイルは以下の画像です。
cafe_menu.png
weekend_event_flyer.png

simple_map.png
ナレッジベースの作成
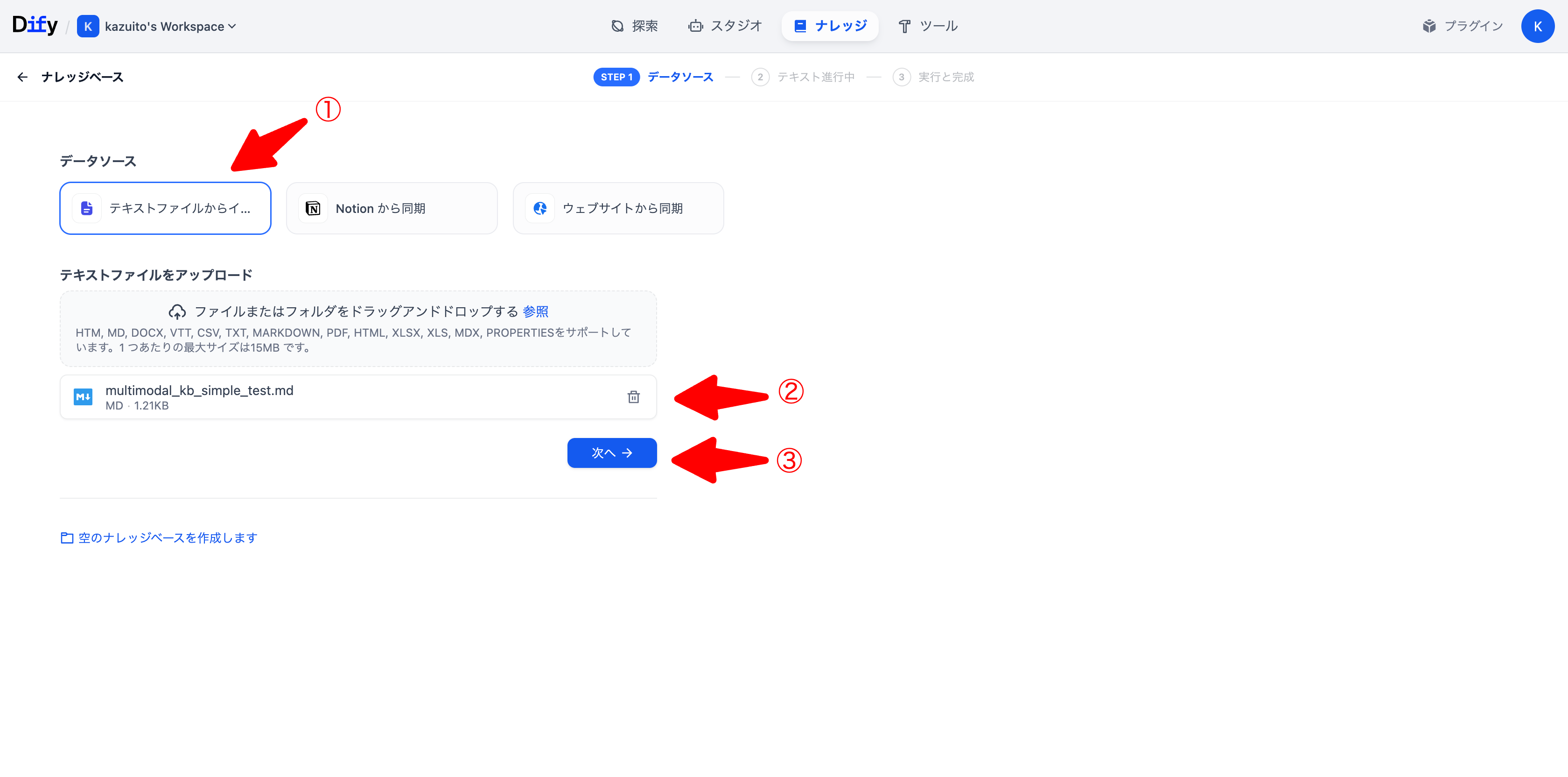
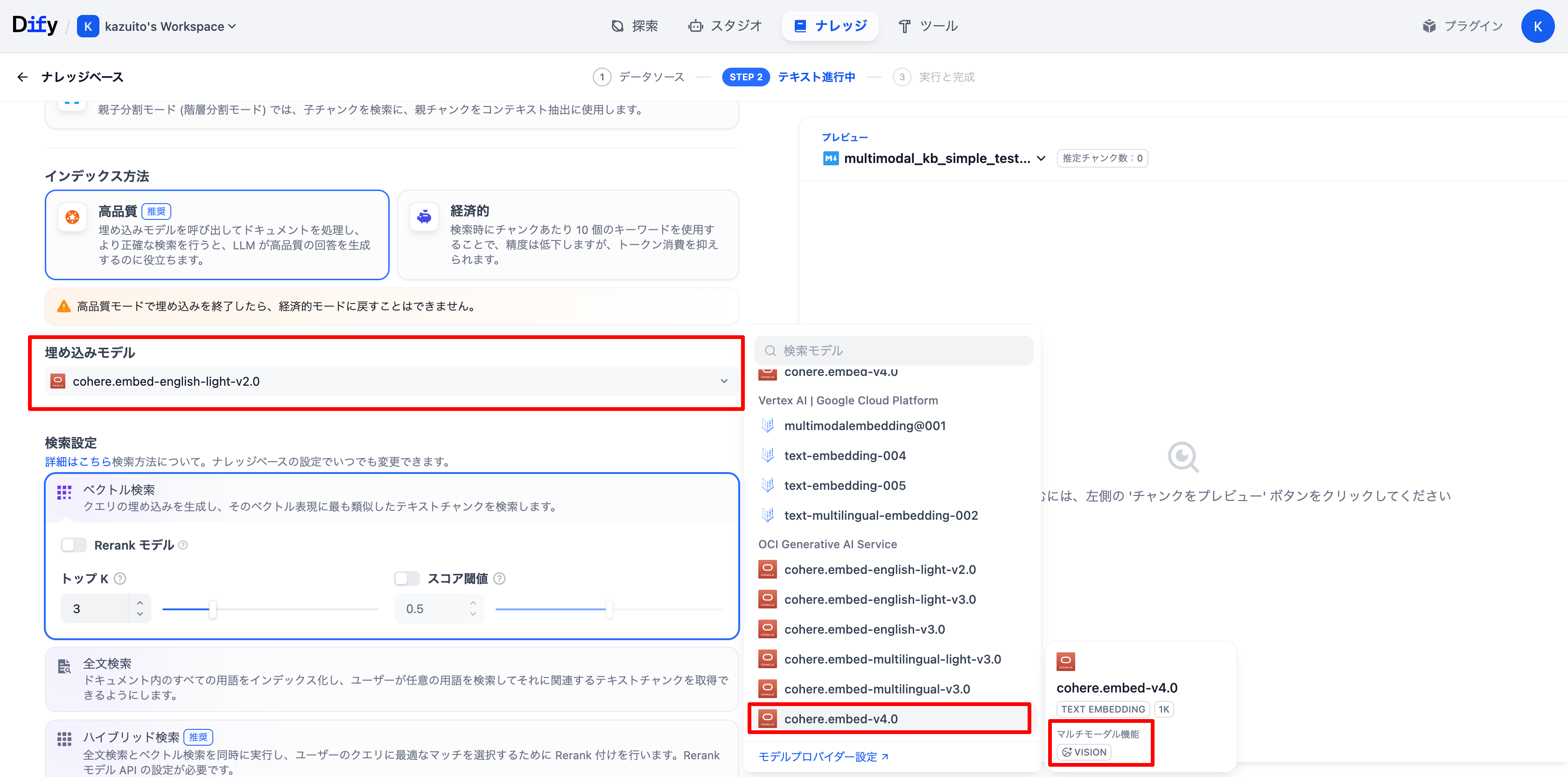
動作確認
検索テストから動作確認をしてみましょう。
まずはテストデータとして登録した画像(simple_map.png)をアップロードしてテストをしてみます。
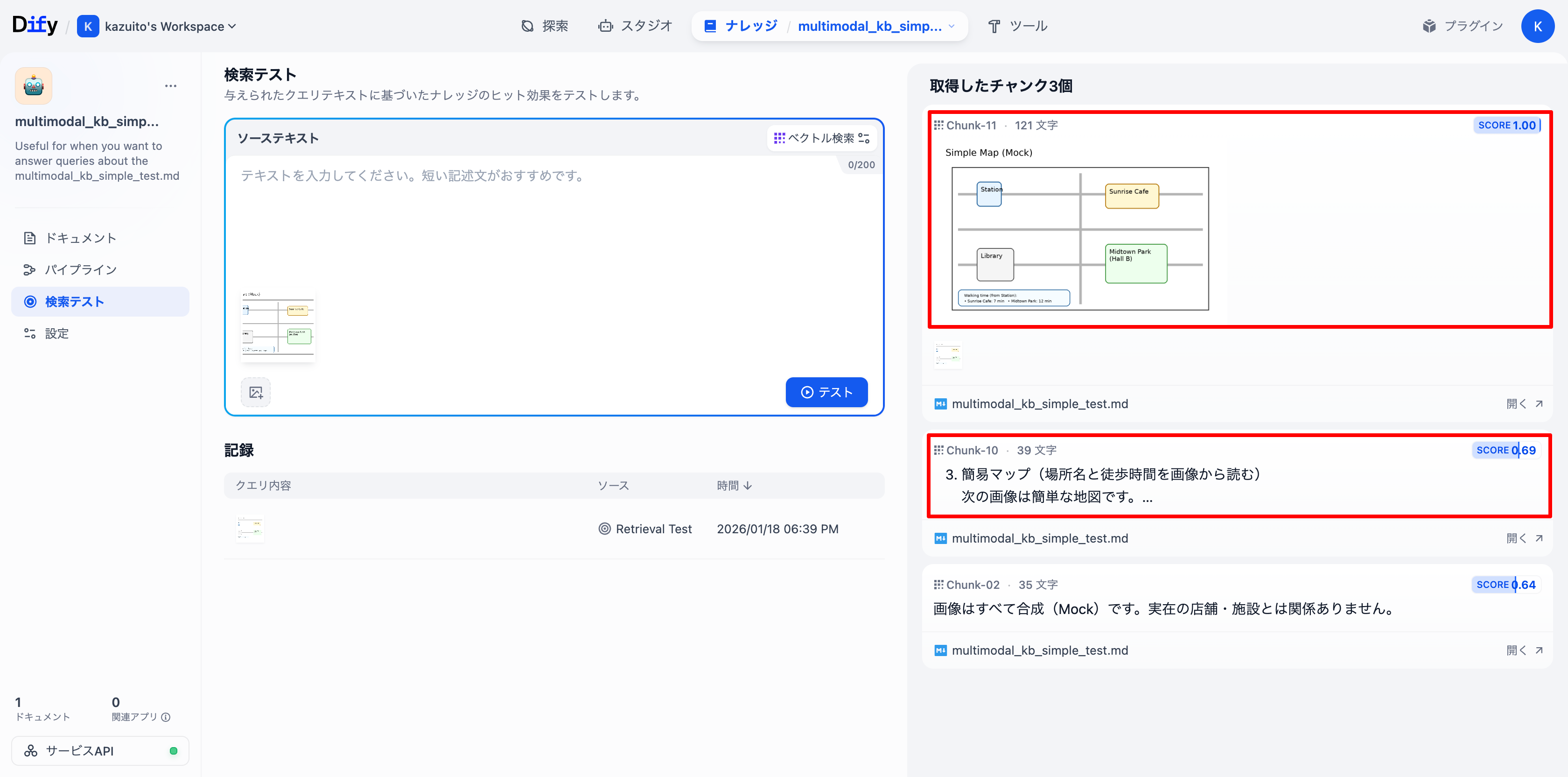
チャンクが3つ取得されました。
1番目は同じ画像が検索されました。同じファイルなのでScore 1.0ですね。
2番目はテキストのみのチャンクがヒットしました。内容にマップなどが含まれていてScore 0.69でした。
これで画像から画像、画像からテキストの検索ができていることが確認できました。
では、今度は似た画像で検索してみましょう。以下の画像です。

⬆️この画像で検索してcafe_menu.pngがヒットするか確認してみます。
Score 0.85でcafe_menu.pngがヒットしました。
最後にテキストから画像がヒットするかを確認してみます。
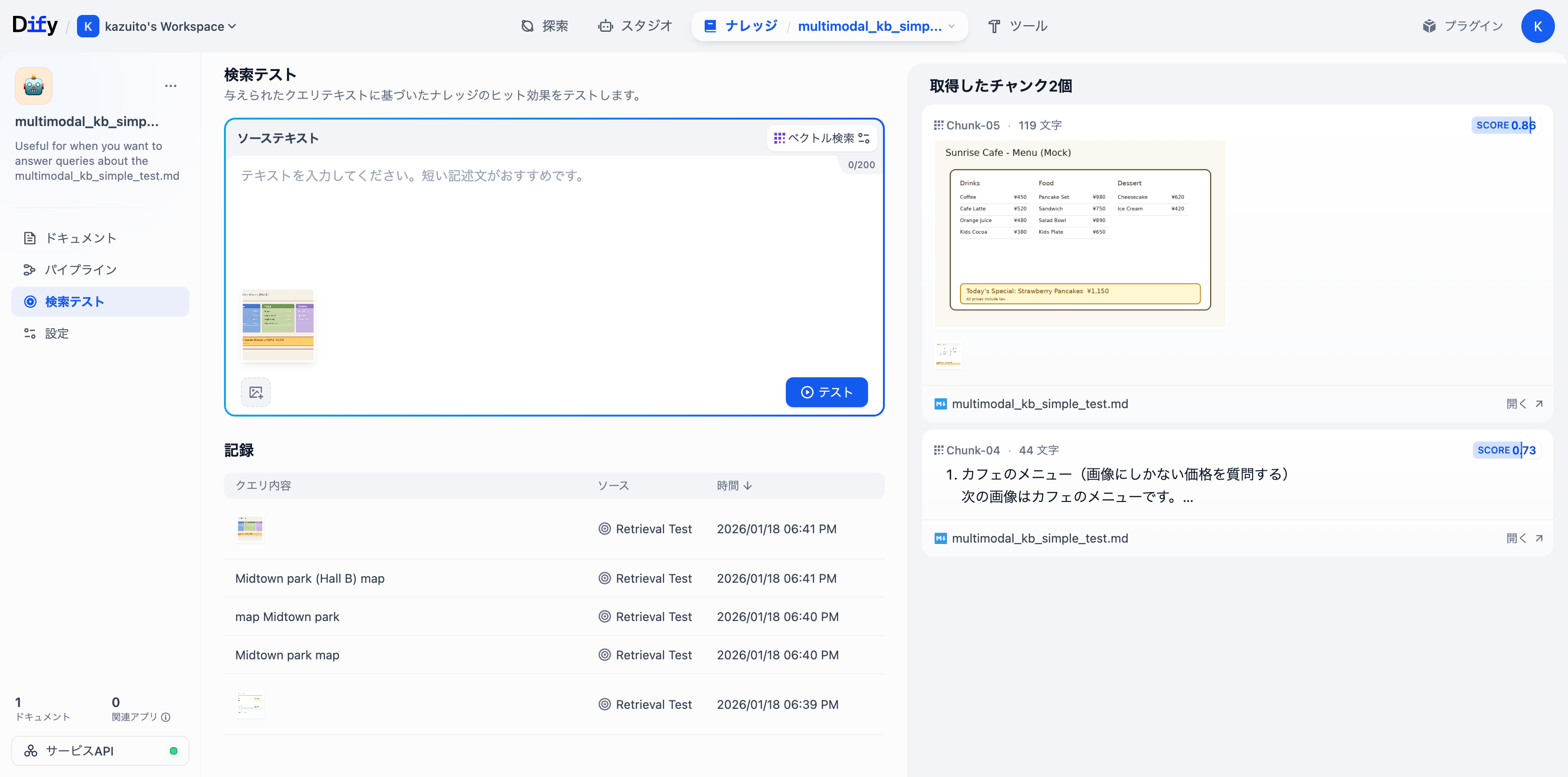
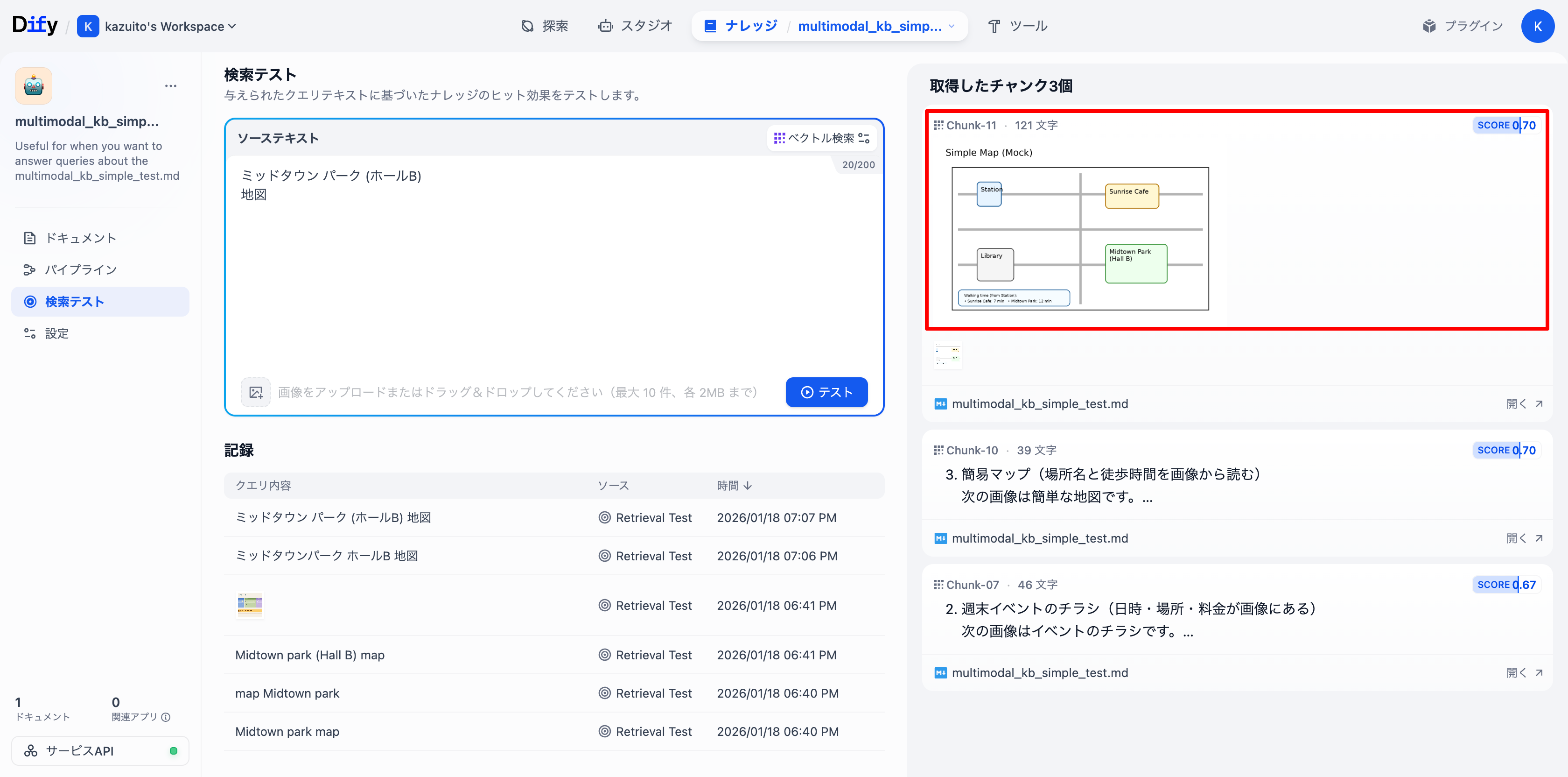
simple_map.pngを狙って、Midtown park (Hall B)とmapでテストしてみます。
結果、狙い通りsimple_map.pngがScore 0.73でヒットしました。
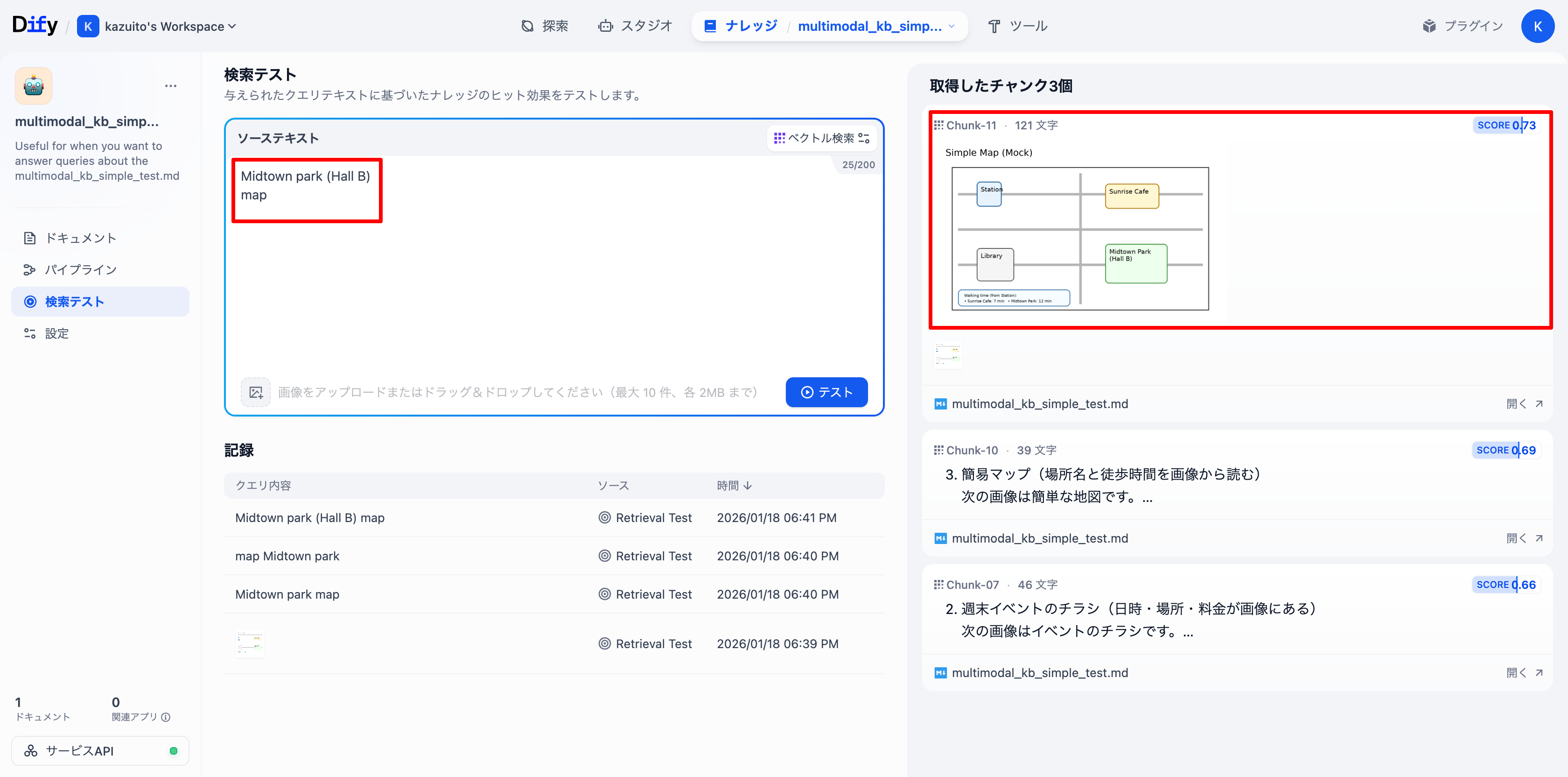
念の為、テキストで検索について英語ではなく日本語で検索をしてみます。
Cohere Embed v4はドキュメントではLanguage SupportとしてImage: English only.と記載があったため。
先ほどの英語と同じ日本語ワードでテストしたところ1番目に目的の画像がヒットしました。検索自体はできるようです。
最後に
本記事ではDify v1.11.0の新機能であるMultimodal Knowledge Baseについて動作検証を行い、想定通りの挙動が得られました。
現状だと上記で試したようにマークダウン形式にする必要があり、ひと手間必要ですが、、、とはいえ、画像をナレッジベースで使えるようになり、利用の幅が広がりますね!