django上にkerasを使ってディープラーニングを用いたアプリを作ろうとした時に
<tensor> is not an element of this graph
というエラーが出て困った時の解決策です。
状況
以下の画像は作ったアプリのUIです。
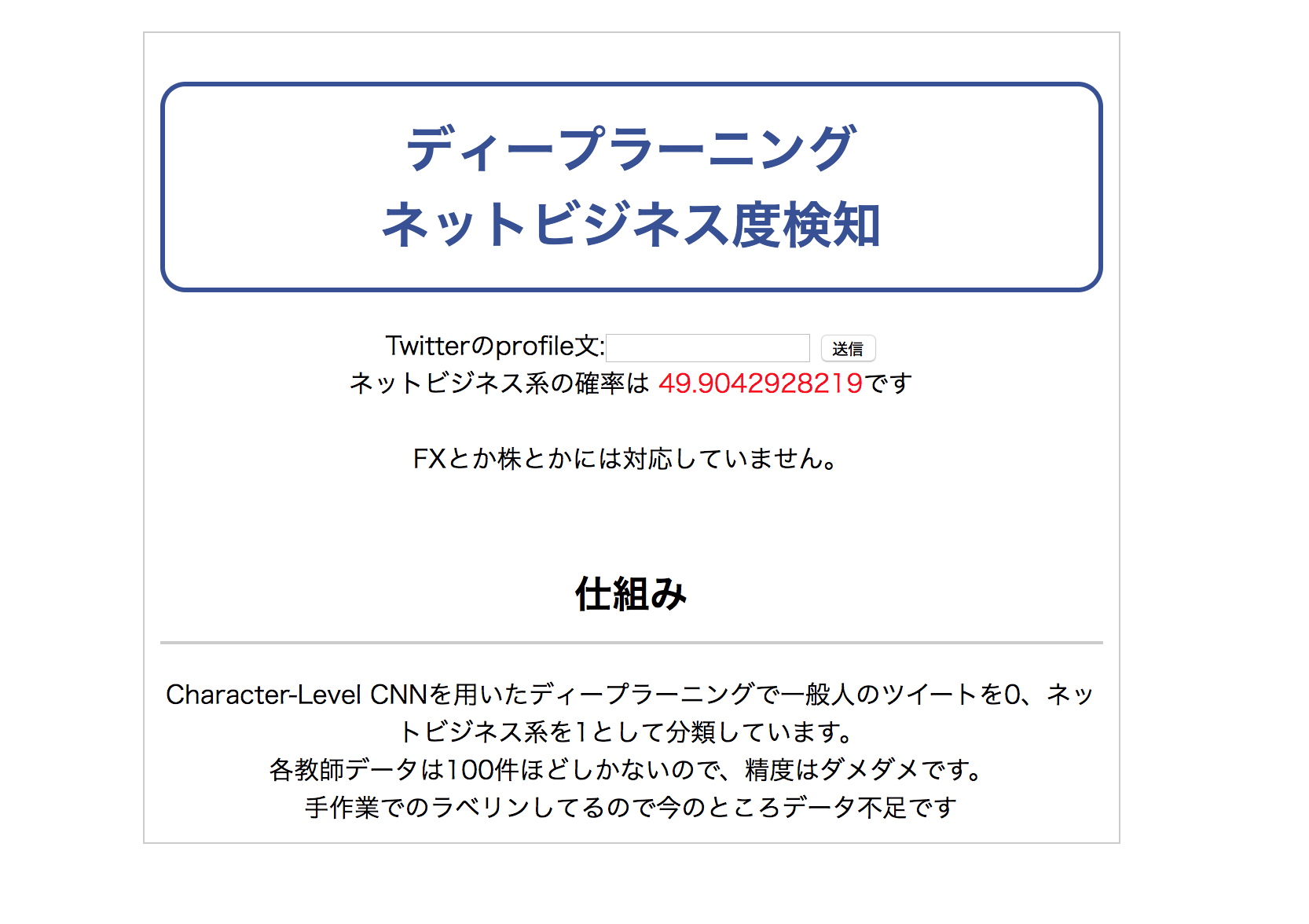
フォームを設置して文章が送られてきたら、CNNを用いてネットビジネス度を判定するというアプリです。
このときにkerasのモデルを使って分類しています。
view.pyにはだいたいこんな事を書いています。
def get_text(request):
result = classify(request.GET.get('text'))
d = {
'text': result
}
return render(request, 'index.html', d)
def classify(comments):
raw_comment = comments
predict_result = 0
if comments != None:
comment = [ord(x) for x in raw_comment if ord(x)<65000]
comment = comment[:300]
if len(comment) < 300:
comment += ([0] * (300 - len(comment)))
ret = predict(np.array([comment]))
predict_result = ret[0][0]
return predict_result * 100
def predict(comments):
ret = model.predict(comments)
return ret
①get_textがフォームからgetメソッドで入力された文を取得してくる。
②classifyに入力された文を渡す。
③classifyが入力された文を数値化してそれをpredictに渡す
④predictが分類する
⑤classifyが確率を返す。
⑥get_textがhtmlページに表示させる
という流れです。
どこにもkerasのgraphを使う記述が無いのに
「is not an element of this graph」
とエラーを吐きます。
ややこしいことに、普通に出来ることもあれば時間をおいたらエラーを吐くこともあるという
最悪の状況でした。
解決策
def get_text(request):
classify('run')#追加
result = classify(request.GET.get('text'))
d = {
'text': result
}
return render(request, 'index.html', d)
って感じにしてやりました。
恐らくですが
・モデルを使って学習するときにpredictを行うプログラムが立ち上がらないまま分類してる。
・mod_wsgiとの連携がうまくいってない。
・初回にアクセスした時にも'text'が無いにもかかわらずclassifyしている
(ただ、ホームページは表示されてて「送信」ボタンを押したらエラーが出ていたのであまり関係ないかも)
今となっては原因不明ですがフォームから送られてきた文章をclassifyする前に、一度適当な文章を投げてやってpredictを行うプログラムを立ち上げてやれば問題なく動くようになりました。
[追記]
コメントを頂いてその方法を試してみるとすんなりいったのでこちらにも書いておきます。
import tensorflow as tf
graph = tf.get_default_graph()
def get_text(request):
global graph
with graph.as_default():
result = classify(request.GET.get('text'))
d = {
'text': result
}
return render(request, 'index.html', d)
に変更してやると問題もなく動作しました。
コメントありがとうございました。
ちなみに、モデル作るときのソースコードは
import sys, os.path, re, csv, os, glob
import pandas as pds
import numpy as np
import zipfile
import codecs
from keras.layers import Activation, Dense, Dropout, Flatten, Convolution2D, MaxPooling2D, Reshape, Input, merge, Conv2D
from keras.models import Model, Sequential
from keras.layers.embeddings import Embedding
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from keras.optimizers import Adam
from keras.callbacks import LearningRateScheduler, Callback, CSVLogger, ModelCheckpoint
import random
os.environ['KERAS_BACKEND'] = 'tensorflow'
# create model for CCNN
def create_model(embed_size=128, max_length=300, filter_sizes=(2, 3, 4, 5, 6, 7, 8), filter_num=64):
inp = Input(shape=(max_length,))
emb = Embedding(0xffff, embed_size)(inp)
emb_ex = Reshape((max_length, embed_size, 1))(emb)
convs = []
# Conv2Dを複数通りかける
for filter_size in filter_sizes:
conv = Conv2D(filter_num, (filter_size, embed_size), activation="relu")(emb_ex)
pool = MaxPooling2D(pool_size=(max_length - filter_size + 1, 1))(conv)
convs.append(pool)
convs_merged = merge(convs, mode='concat')
reshape = Reshape((filter_num * len(filter_sizes),))(convs_merged)
fc1 = Dense(64, activation="relu")(reshape)
bn1 = BatchNormalization()(fc1)
do1 = Dropout(0.5)(bn1)
fc2 = Dense(1, activation='sigmoid')(do1)
model = Model(input=inp, output=fc2)
return model
def load_data(filepath, filepath1 ,max_length=300, min_length=10):
"""
Twitterのプロフィール欄のコメントを入力データとする。
eg
京大3回/フルオートSNSマーケティング/Twitterを開く→
規定の文章をツイート→月10万~50万の自動収入を見込めるシステムの無料テストユーザー募集中
/テストユーザー故定員に達したら即打ち切ります/興味ある人はインスタより
"""
comments = []
comments2 = []
#ビジネス系の人のプロフィールの読み込み
with open(filepath) as f:
for l in f:
# 文字毎にUNICODEに変換しつつ顔文字を除外
comment = [ord(x) for x in str(l).strip() if ord(x)<65000]
# 長い部分は打ち切り
comment = comment[:max_length]
comment_len = len(comment)
if comment_len < min_length:
continue
if comment_len < max_length:
# 固定長にするために足りない部分を0で埋める
comment += ([0] * (max_length - comment_len))
comments.append((1, comment))
else:
comments.append((1, comment))
#普通の人のプロフィールの読み込み
with open(filepath1) as f:
for l1 in f2:
# 文字毎にUNICODEに変換しつつ顔文字を除外
comment2 = [ord(x) for x in str(l1).strip() if ord(x)<65000]
# 長い部分は打ち切り
comment2 = comment2[:max_length]
comment2_len = len(comment2)
if comment2_len < min_length:
continue
if comment2_len < max_length:
# 固定長にするために足りない部分を0で埋める
comment2 += ([0] * (max_length - comment2_len))
comments2.append((0, comment2))
else:
comments2.append((0, comment2))
comments.extend(comments2[:len(comments)])
random.shuffle(comments)
return comments
def train(inputs, targets, batch_size=100, epoch_count=100, max_length=300, model_filepath="model.h5", learning_rate=0.001):
# 学習率を少しずつ下げるようにする
start = learning_rate
stop = learning_rate * 0.01
learning_rates = np.linspace(start, stop, epoch_count)
# モデル作成
model = create_model(max_length=max_length)
optimizer = Adam(lr=learning_rate)
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# 学習
model.fit(inputs, targets,
nb_epoch=epoch_count,
batch_size=batch_size,
verbose=1,
validation_split=0.1,
shuffle=True,
callbacks=[
LearningRateScheduler(lambda epoch: learning_rates[epoch]),
])
# モデルの保存
model.save(model_filepath)
if __name__ == "__main__":
comments = load_data(filepath='/data',filepath1='/data1')
print(comments)
input_values = []
category_values = []
for category_value, input_value in comments:
input_values.append(input_value)
category_values.append(category_value)
input_values = np.array(input_values)
category_values = np.array(category_values)
train(input_values, category_values)
こんな感じで、ローカルでテストするなら
import numpy as np
from keras.models import load_model
def predict(comments, model_filepath="model.h5"):
model = load_model(model_filepath)
ret = model.predict(comments)
return ret
if __name__ == "__main__":
raw_comment = "22歳/トレード/投資/暗号通貨/月収7桁/ スマホ可/ 勝率90%越え/SPADE♠︎代表/生徒平均月収25,5万無料攻略マニュアル【30名限定で】配布中"
comment = [ord(x) for x in raw_comment.strip()]
comment = comment[:300]
if len(comment) < 10:
exit("too short!!")
if len(comment) < 300:
comment += ([0] * (300 - len(comment)))
ret = predict(np.array([comment]))
predict_result = ret[0][0]
print('input data :'+raw_comment+'\n')
print ("ネットビジネス度: {}%".format(predict_result * 100))
って感じです。