獲得点数 475/1000点
正答率: 47.5 % ( 19問 / 40問 正解 )
以下のコードの後に、np.dot(a, b)を実行した場合の出力と同じにならないものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = a.copy()
a = a.reshape(3,2)
A,np.multiply(a,b)
インフォメーション
NumPyの行列積メソッドの問題です。dot、@、matmulは
全て行列積のメソッドですが、
multiplyはスカラー倍のメソッドになります。
以下のコードを実行した後に、np.hstack((a,b))を実行した場合の出力と同じにするにはどれを実行すれば良いか?正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
A,np.concatenate([a,b],axis=1) #水平方向に連結
#np.hstack(()) 水平方向に配列を連結
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df.iloc[1]>3 #スライスしない場合はインデックスがキーで配列がそれぞれ出る つまりA2と B7
A,A False
B True
以下のscikit-learnの説明のうち正しいものを選べ
A,GPUで動かすためのサポートがない
特徴量の次元削減について説明している以下の文章のうち、正しいものを選べ
A,なるべくデータの情報を落とさずに、少ない特徴量でデータを表現するために用いられる
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.full((2,2),1)
B = np.zeros((2,2))
np.concatenate([A, B], axis=0)
A,array([[1., 1.], [1., 1.], [0., 0.], [0., 0.]])
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 1],[1, 1]])
B = np.array([1, 1])
np.dot(A, B)
A,array([2, 2])
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 0]])
B = np.array([1, 0])
A @ B
A,array([1])
数値データが格納されたpandasデータフレーム(df)に対して、
各カラム間の相関係数を算出するコードとして正しいものを選べ
A,df.corr()
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
A,df[df.index==2]
#df[“国名”]==”中国”だと一列目のBOOL値で返される
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import matplotlib.pyplot as plt
import math
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
y_list2 = list(map(lambda x: x**3+x**2, x_list))
y_list3 = list(map(lambda x: (math.e)**x, x_list))
plt.plot(x_list, y_list, label="x**2")
plt.plot(x_list, y_list2, label="x**3+x**2")
plt.plot(x_list, y_list3, label="exp(x)")
plt.legend()
plt.show()
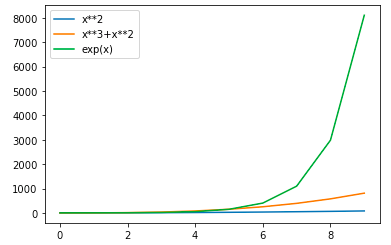
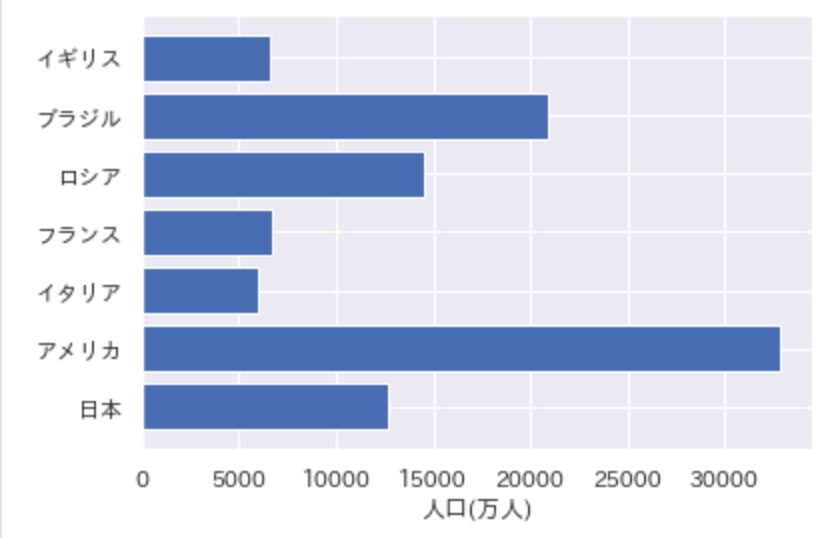
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"], "人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
plt.rcParams["font.family"] = "AppleGothic"
plt.barh(df["国名"], df["人口/万人"])
plt.xlabel("人口(万人)")
plt.show()
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値をカラムごとの平均値で埋める処理として正しいものを選べ
A,df.fillna(df.mean())
シグモイド関数について説明している以下の文章のうち、正しいものを選べ
A,ニューラルネットワークの活性化関数として使われる関数であり、この関数の出力は0より大きく1より小さい
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
plt.rcParams["font.family"] = "AppleGothic"
XXX
plt.xlabel("人口(万人)")
plt.show()
A,plt.pie(df["人口/万人"], labels=df["国名"], counterclock=False, startangle=90, autopct="%1.1f%%", pctdistance=0.8)
#pctdistanceは%の文字の位置 startangle=90が一般的な開始位置 counterclock=False 右回り
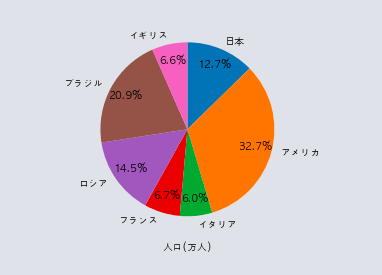
scikit-learnのGridSearchCVクラスには、もっとも精度が良い時のハイパーパラメーターの値を取得するための属性がある。その属性として正しいものを選べ
A,best_params_
機械学習アルゴリズムにおける、ハイパーパラメーターの説明として正しいものを以下の中から選べ
A,学習時にアルゴリズムで決定されず、モデル構築者が指定する必要があるパラメーター
テストデータを用いてパラメーターチューニングをしてはいけない理由として正しいものを選べ
A,実際には手に入り得ないデータであり、
未来の情報をみてモデルの精度を恣意的に向上させていることになるから
scikit-learnのDesicionTreeClassifierモジュールを
使用する場合に引数として指定できないものを選べ
A,木の数
決定木について説明している以下の文章のうち、正しいものを選べ
A,情報利得の大きい順に特徴量が使用され、木が作られる
勾配ブースティングの手法として正しくないものを選べ
A,ニューラルネットワーク
scikit-learnのサポートベクターマシンの
ハイパーパラメーターのCについて説明している以下の文章のうち正しいものを選べ
A,Cの値が小さいほど、マージンは大きくなる
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
カラムごとの欠損値の割合を円グラフとして可視化するコードとして正しいものを選べ
A,
import matplotlib.pyplot as plt
plt.pie(df.isnull().sum()/len(df), labels=df.columns, autopct="%1.1f%%")
plt.show()
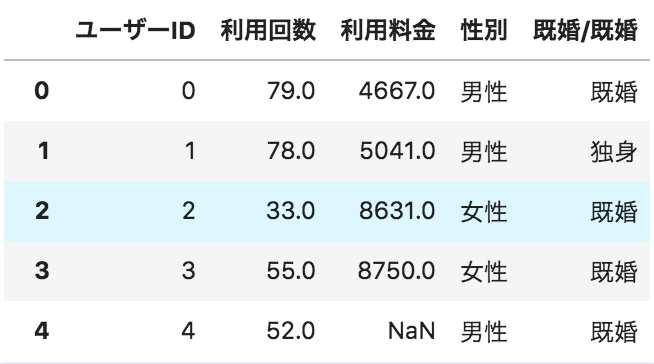
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
性別ごとの人数を棒グラフで表示するためのコードとして正しいものを選べ
A,import matplotlib.pyplot as plt
df["性別"].value_counts().plot.bar()
plt.show()