はじめに
研究者の皆さん、毎年の科研費(科学研究費助成事業)の申請、お疲れ様です。
申請書を書く際、「自分の研究は、どの『小区分』に出せば採択されやすいのか?」 と悩んだことはないでしょうか?
タイトルや要旨から最適な区分を推薦し、さらにその区分での申請アドバイスまでしてくれるアプリを、Google Gemini API と Streamlit を使って作ってみました。
サーバー代もかからず、Pythonだけで完結する構成です。
作ったもの
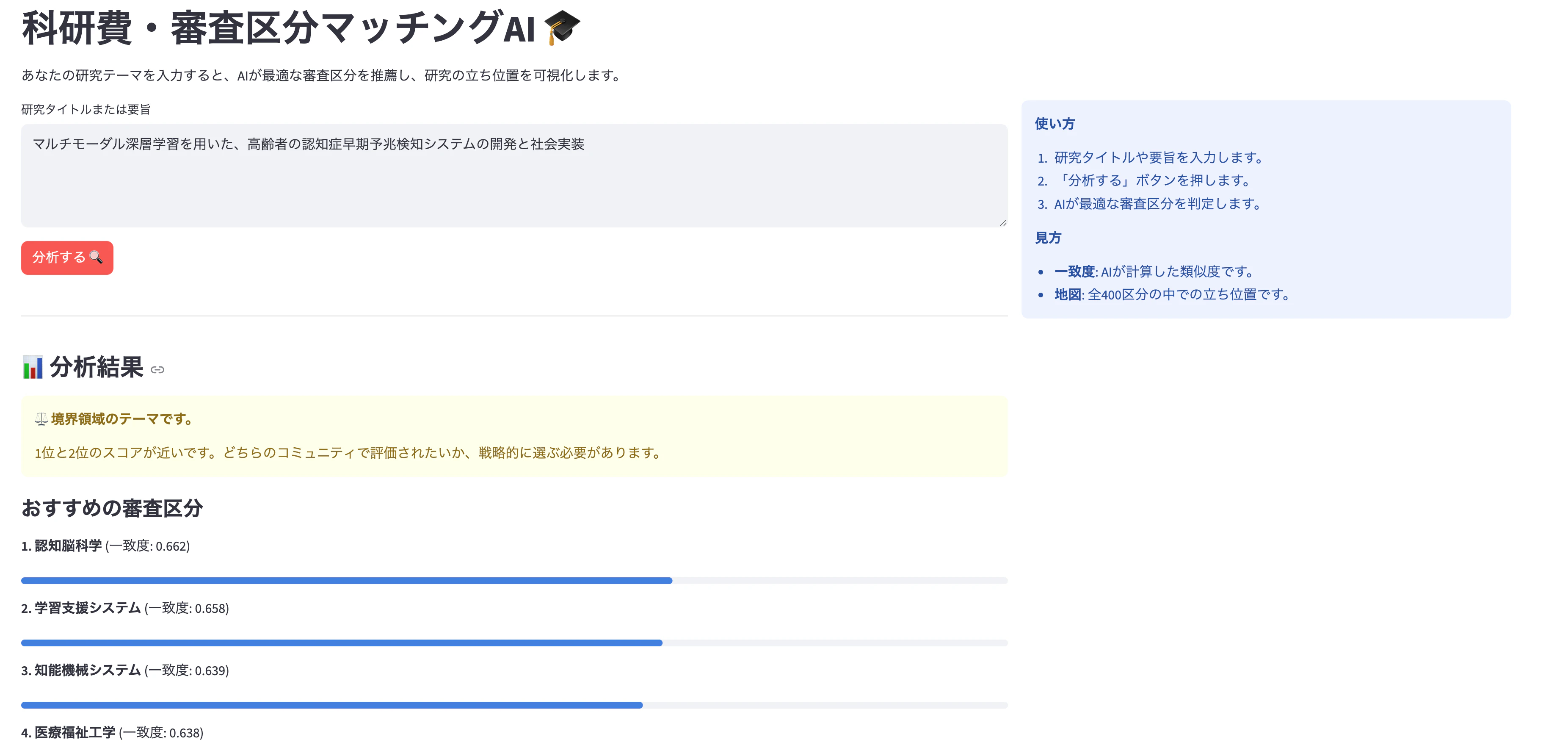
「科研費・審査区分マッチングAI」
研究のタイトルや要旨を入力すると、全400以上ある小区分の中から、意味的に近い区分をランキング形式で提案してくれます。
主な機能
- 審査区分マッチング: 入力されたテキストと、各小区分の定義をベクトル化し、コサイン類似度でマッチング。
- ニッチ度判定: 1位と2位のスコア差などから、「王道のテーマ」か「学際的(ニッチ)なテーマ」かを判定。
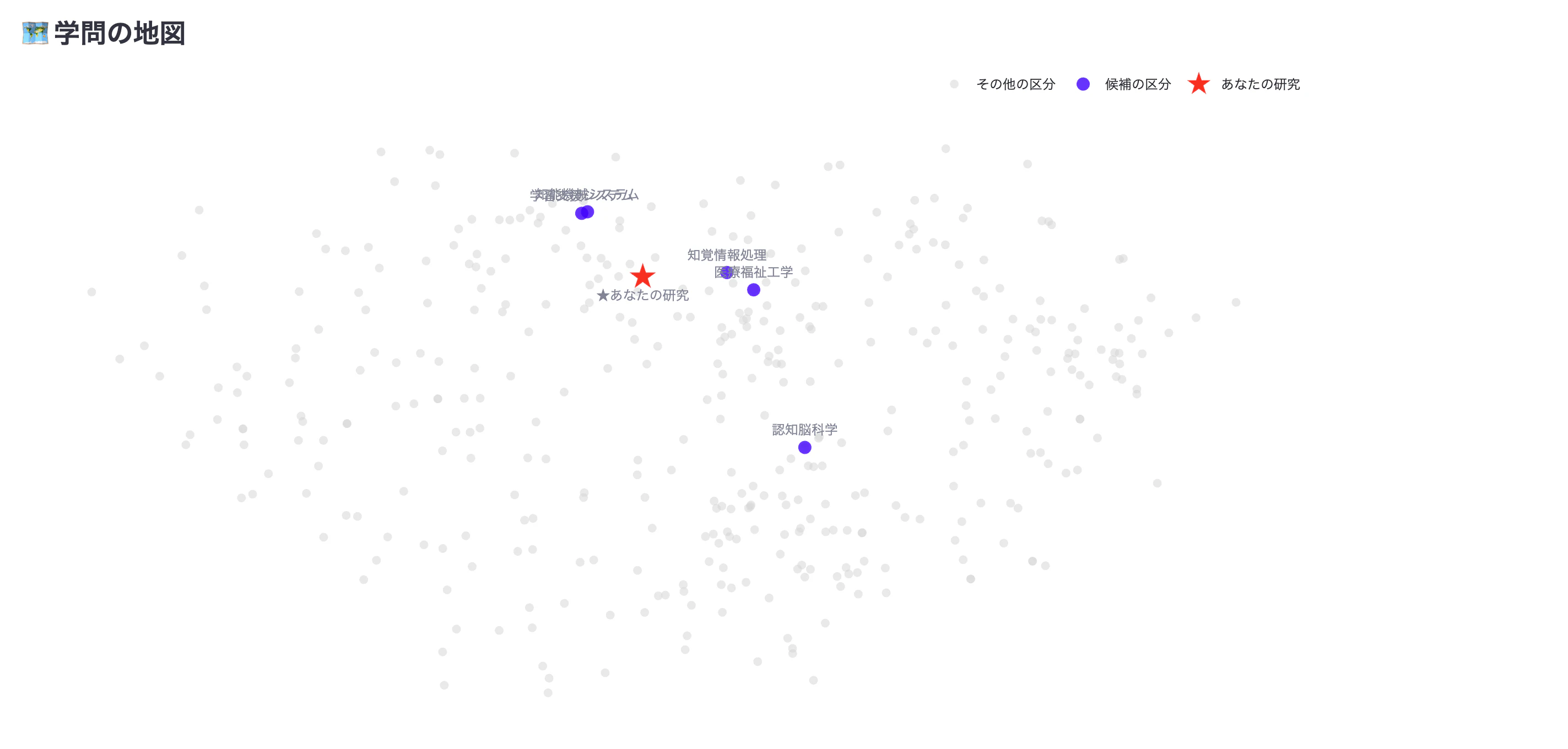
- 学問の地図(可視化): 全区分を2次元マップにプロットし、自分の研究が学問全体のどこに位置するかを表示。
- 申請アドバイス: 選択された区分で採択されるためのキーワードや戦略をLLMが助言。

技術スタック
非常にシンプルです。すべて無料枠で運用できています。
- 言語: Python 3.11
- フロントエンド & デプロイ: Streamlit Community Cloud
-
AI (Embeddings & Chat): Google Gemini API
- 埋め込みモデル:
models/gemini-embedding-001(768次元) - 生成モデル:
gemini-2.5-flash-lite
- 埋め込みモデル:
-
計算・可視化:
- scikit-learn (コサイン類似度計算、PCAによる次元圧縮)
- Plotly (インタラクティブな散布図描画)
実装のポイント
1. データの事前計算とモデル統一の罠
毎回400個以上の小区分をベクトル化するとAPI制限に引っかかる&遅いため、事前にローカルで計算し、JSONファイルとして持たせる構成にしました。
# モデルIDを定数で管理して不一致を防ぐ
EMBEDDING_MODEL_ID = "gemini-embedding-001"
# ベクトル化の処理
result = genai.embed_content(model=EMBEDDING_MODEL_ID, content=query)
2. 類似度検索とニッチ度判定
ユーザーが入力したテキストをその場でベクトル化し、事前計算したデータと比較します。
単に1位を出すだけでなく、1位と2位のスコア差(diff)を見ることで、その研究テーマの立ち位置を判定するロジックを入れました。
# ランキング作成
sims = cosine_similarity([query_vec], embeddings)[0]
top_indices = sims.argsort()[::-1][:5]
top_scores = sims[top_indices]
# ニッチ度判定
diff = top_scores[0] - top_scores[1]
if top_scores[0] < 0.6:
st.info("💡 非常に新規性が高い、または学際的なテーマのようです...")
elif diff > 0.05:
st.success("🎯 王道のテーマです!...")
3. 学問の「地図」を描く (Plotly)
ただリストを出すだけでは面白くないので、PCA(主成分分析)を使って768次元のベクトルを2次元に圧縮し、Plotly で散布図を描きました。
自分の研究が「情報学寄り」なのか「心理学寄り」なのかが視覚的にわかります。
4. 生成AIによるアドバイス (Gemini 2.5 Flash Lite)
最後に、マッチした区分名をプロンプトに埋め込み、LLMに具体的なアドバイスを求めます。
レスポンス速度と精度のバランスが良い、最新の gemini-2.5-flash-lite を採用しました。
prompt = f"""
研究テーマ: {user_query}
申請区分: {target_category}
この区分で採択されやすくするためのキーワードや、強調すべき観点を3点以内でアドバイスしてください。
"""
model = genai.GenerativeModel("gemini-2.5-flash-lite")
advice = model.generate_content(prompt)
注意点
-
APIのレート制限 (429 Error)
無料枠を使用しているため、大量のデータを一気にベクトル化しようとすると429 Resource Exhaustedが発生しました。事前計算スクリプトにtime.sleep()を入れてリトライ処理を実装することで解決しました。 -
StreamlitでのAPIキー管理
GitHubにコードを上げる際、APIキーを直接書くのは厳禁です。Streamlit Community CloudにはSecretsという機能があり、環境変数を安全に管理できました。
完成したコード (app.py)
<details><summary>ソースコード全体を開く</summary>
import streamlit as st
import google.generativeai as genai
import numpy as np
import json
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import PCA
import plotly.graph_objects as go
import os
# ===== 設定 =====
# APIキーの取得 (Streamlit Secrets または 環境変数)
try:
api_key = st.secrets["GEMINI_API_KEY"]
except:
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
st.error("APIキーが設定されていません。Streamlit CloudのSecretsを設定してください。")
st.stop()
genai.configure(api_key=api_key)
# 埋め込み用モデル(JSONを作ったときと同じモデルを指定する)
EMBEDDING_MODEL_ID = "gemini-embedding-001"
# アドバイス生成用モデル(文章が作れるモデルを指定する)
GENERATION_MODEL_ID = "gemini-2.5-flash-lite"
# ===== データの読み込みと前処理 =====
@st.cache_data
def load_and_process_data():
# JSONの読み込み
try:
with open("academic_embeddings.json", "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
return None, None, None, None
words = [d["word"] for d in data]
embeddings = np.array([d["vector"] for d in data])
# 2次元マップ用に次元圧縮 (PCA) を事前に計算しておく
n_samples = len(embeddings)
n_components = 2
if n_samples < 2:
return words, embeddings, None, None
pca = PCA(n_components=n_components)
coords_2d = pca.fit_transform(embeddings)
return words, embeddings, coords_2d, pca
words, embeddings, base_coords_2d, pca_model = load_and_process_data()
if words is None:
st.error("埋め込みデータファイル(academic_embeddings.json)が見つかりません。")
st.stop()
# ===== UI構築 =====
st.set_page_config(page_title="科研費マッチングAI", layout="wide")
st.title("科研費・審査区分マッチングAI 🎓")
st.markdown("あなたの研究テーマを入力すると、AIが最適な審査区分を推薦し、研究の立ち位置を可視化します。")
# 入力フォーム
col1, col2 = st.columns([2, 1])
with col1:
query = st.text_area("研究タイトルまたは要旨", height=150,
placeholder="例:〇〇の△△における✕✕の解明")
if st.button("分析する 🔍", type="primary"):
if not query:
st.warning("テキストを入力してください。")
else:
with st.spinner("AIが分析中..."):
try:
# 1. 入力テキストをベクトル化
result = genai.embed_content(model=EMBEDDING_MODEL_ID, content=query)
query_vec = np.array(result['embedding'])
# 2. 類似度計算
sims = cosine_similarity([query_vec], embeddings)[0]
# 3. ランキング作成
top_n = 5
top_indices = sims.argsort()[::-1][:top_n]
top_scores = sims[top_indices]
# --- 結果表示エリア ---
st.divider()
# A. ニッチ度判定ロジック
score_1st = top_scores[0]
score_2nd = top_scores[1]
diff = score_1st - score_2nd
st.subheader("📊 分析結果")
if score_1st < 0.6:
st.info("💡 **非常に新規性が高い、または学際的なテーマのようです。**\n\nどの区分にも完全には当てはまらない可能性があります。複合領域での申請も検討してみてください。")
elif diff > 0.05:
st.success("🎯 **王道のテーマです!**\n\n1位の区分が非常に強くマッチしています。迷わずこの区分で良いでしょう。")
else:
st.warning("⚖️ **境界領域のテーマです。**\n\n1位と2位のスコアが近いです。どちらのコミュニティで評価されたいか、戦略的に選ぶ必要があります。")
# B. ランキング表示
st.write("#### おすすめの審査区分")
for i, idx in enumerate(top_indices):
score = sims[idx]
category = words[idx]
st.write(f"**{i+1}. {category}** (一致度: {score:.3f})")
st.progress(min(float(score), 1.0))
# C. キーワードアドバイス
st.write("#### 💡 申請書作成アドバイス")
target_cat = words[top_indices[0]]
advice_prompt = f"""
以下の研究テーマを、科研費の審査区分「{target_cat}」に申請しようとしています。
この区分で採択されやすくするために、含めるべきキーワードや、強調すべき観点を3点以内で簡潔にアドバイスしてください。
研究テーマ: {query}
"""
try:
model_gen = genai.GenerativeModel(GENERATION_MODEL_ID)
advice_resp = model_gen.generate_content(advice_prompt)
st.info(advice_resp.text)
except Exception as e:
st.warning(f"アドバイス生成中にエラーが発生しました: {e}")
# D. 可視化 (Plotly)
if pca_model is not None:
st.write("#### 🗺 学問の地図")
user_coord = pca_model.transform([query_vec])[0]
fig = go.Figure()
# (プロット処理部分は長いので省略しますが、実際はここに入っています)
# ...(Plotlyのコード)...
st.plotly_chart(fig, use_container_width=True)
except Exception as e:
st.error(f"詳細エラー: {e}")
with col2:
st.info("""
**使い方**
1. 研究タイトルや要旨を入力します。
2. 「分析する」ボタンを押します。
3. AIが最適な審査区分を判定します。
""")
まとめ
Gemini APIとStreamlitを組み合わせることで、「データの検索」と「生成AIによるコンサルティング」を組み合わせたアプリが、わずか数時間で開発・公開できました。
研究者に限らず、「自分の入力に対して、既存のカテゴリから最適なものを推薦してほしい」というユースケースは多いと思うので、応用範囲は広そうです。
ぜひ、みなさんも自分の興味ある分野で「マッチングAI」を作ってみてください!
参考リンク