はじめに
こんにちは。
私はIT企業で経理として働いています。
せっかくIT企業に勤めているんだからバックオフィスの業務にもプログラミングを活かしてみたい、、、!
そんな気持ちでPythonを触ってみました。
こんな人に向けて書きました
- スクレイピングについてざっと知りたい人
- ほんの少しプログラミングをかじって、できることを探している人
- 業務を自動化できないか検討中の管理部の人
目次
- スクレイピングって何ができるの?
- スクレイピングの仕組みは?
- サンプル①
- サンプル②(応用例)
スクレイピングって何ができるの?
取得したHTMLから、任意の情報を抽出し、加工することができます。
具体的には、スクレイピングを活用してこんなことができます。
- 毎日同じWEBサイトにアクセスして、情報をcsvファイルに転記する作業を自動化
- SNSで特定のキーワードでヒットした画像をすべてダウンロードする
- 特定のキーワードに当てはまる企業を抽出し営業リストを作成
スクレイピングの仕組みは?
ざっくりというと、
WEBサイト上の情報の取得 → 情報の抽出 → 結果の出力
という3ステップになっています。
この記事では、Pythonを用いてスクレイピングを行う方法を紹介します。今回は以下2つを利用しました。
- BeautifulSoupというライブラリ(情報の抽出、結果の出力)
- urllib というモジュール(WEBサイト上の情報の取得)
具体的には、下記のような処理を行います。
- HTML,XMLから任意の情報を取得します。(この記事ではHTMLに絞って書きます。)
- スクレイピング対象のURLにリクエストを送り、HTMLを取得します。
- 取得したHTMLからBeautifulSoupオブジェクトを作り、
- 抽出したい情報があるHTML要素を指定します。
- 指定したHTML要素に含まれる値が抽出できます。
HTML要素を指定する際には、find系のメソッドとselect系のメソッドが用意されています。
今回はfind系のメソッドに絞って使用します。
- find():一つだけ要素を返す
- findAll():条件に当てはまる要素をリストで返す
早速サンプルを見てみましょう。
準備
①pythonのダウンロード
https://www.javadrive.jp/python/install/index1.html
②beautifulsoupのインストール
pipでインストールすることができます。
$ pip install beautifulsoup4
③urllibのインストール
こちらもpipでインストールできます。
$ pip install urllib3
サンプルコード
弊社のホームページから、タイトルを取得してみます。
import urllib.request #urllibを利用可能に
from bs4 import BeautifulSoup #BeautifulSoupを利用可能に
r = urllib.request.urlopen(‘https://www.is-tech.co.jp/’) #情報の取得対処となるページのHTMLを取得
html = r.read().decode('utf-8', 'ignore') #HTMLをutf-8に変換して読み出す
parser = "html.parser" #情報の指定先をHTMLに指定
soup = BeautifulSoup(html, parser) #BeautifulSoupオブジェクトの完成
title = soup.find("title").text #HTML内のtitleタグに含まれる文字を抽出対象に指定
print(title) #titleタグに含まれる文字を表示
結果
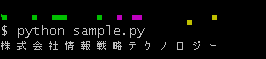
抽出できました。
応用例
下記の画像のような架空のwebサイトがあるとします。
架空の上場企業の決算情報がページごとにまとめられているサイトです。
会社ごとに直近3年度分の売上を抽出し、csvに出力します。
urlはhttps://www.example.com/NNNN とします。
※NNNNには4桁の証券コードがあてはまります。

<!DOCTYPE html>
</html>
<html>
<head>
<meta charset="utf-8">
<title>決算情報</title>
</head>
<body>
<h1 class="company">株式会社hogehoge</h1>
<table class="information">
<tr>
<td> </td>
<td>前期</td>
<td>2期前</td>
<td>3期前</td>
</tr>
<tr>
<td>売上高</td>
<td>1,200百万円</td>
<td>1,100百万円</td>
<td>1,000百万円</td>
</tr>
<tr>
<td>経常利益</td>
<td>240百万円</td>
<td>220百万円</td>
<td>200百万円</td>
</tr>
<tr>
<td>当期利益</td>
<td>120百万円</td>
<td>110百万円</td>
<td>100百万円</td>
</tr>
</table>
</body>
先ほど、ホームページからタイトルを抽出したサンプルに、下記のようなアレンジを加えます。
- 4桁の証券コード(1000~9999)について、繰り返し処理する
- 証券コードが存在しない場合は何もしない
- findAll()メソッドも利用し、○○内の何番目の△△という条件でHTML要素を指定
- 一回の処理が終わる度に、5秒休止(アクセス先のサーバの負荷軽減のため)
- 最後はcsvに出力する
import urllib.request
from bs4 import BeautifulSoup
import csv #csv関連の処理を利用可能に
import time #処理の休止機能を利用可能に
class Scraper:
def __init__(self, site, code): #クラスを作成
self.site = site
self.code = code
def scrape(self): #インスタンスを作成
url = str(self.site) + str(self.code) #企業のurl
r = urllib.request.urlopen(url)
html = r.read().decode('utf-8', 'ignore')
parser = "html.parser"
soup = BeautifulSoup(html, parser) #soupオブジェクトの完成
company = soup.find("h1") #会社名を取得
time.sleep(5) #5秒処理を休止
if "企業情報ページが見つかりません" in company.text: #該当する証券コードの企業がない場合は処理を行わない
pass
else: #それ以外の場合
table = soup.find("table") #直近3期の決算情報が載った表
data = table.findAll("td") #tableの中で、tdタグが付いているものをすべて指定
sales = data[5].text.split('百万円')[0] #前期の売上(=dataの中で6つ目のtdタグ)
sales_two_years_ago = data[6].text.split('百万円')[0] #2期前の売上(=dataの中で7つ目のtdタグ)
sales_three_years_ago = data[7].text.split('百万円')[0] #3期前の売上(=dataの中で8つ目のtdタグ)
row = [code, company, sales, sales_two_years_ago, sales_three_years_ago] #csvに出力するため、リスト化
with open('test.csv', 'a', newline ='') as f: #csvに書き出す
writer = csv.writer(f)
writer.writerow(row)
time.sleep(5) #5秒処理を休止
source = "https://www.example.com/" #urlの共通部分
for i in range(1000, 10000): #証券コード1000~9999に対して繰り返し処理
Scraper(source, i).scrape()
結果

このように、すべての企業の情報をcsvに出力することができます。
注意
業務を自動化するためYahoo!ファイナンスをスクレイピングしようと思ってコードを作成したのですが、利用規約で禁止されてました、、、
スクレイピングを利用する際には事前にWEBサイトの利用規約を確認するようにしてください。
サイトによってはAPIが公開されている場合がありますので、APIを活用して処理を行うという手段もあります。