はじめに
この記事で説明すること:
- Oracle SQLのインデックスや実行計画に出てくるオペレーションの種類(データ探索方法)について概要を掴むための、ごく初歩的な説明
- 物理的なディスクI/Oに着目した、データ探索オペレーションの比較
説明しないこと:
- 実行計画そのものの表示の仕方
- 探索アルゴリズム周りの論理構造
以下の説明が分かりにくいな、もっと具体的な話を知りたいなと思った場合、具体編も併せて参照してください。
昔話をしましょう

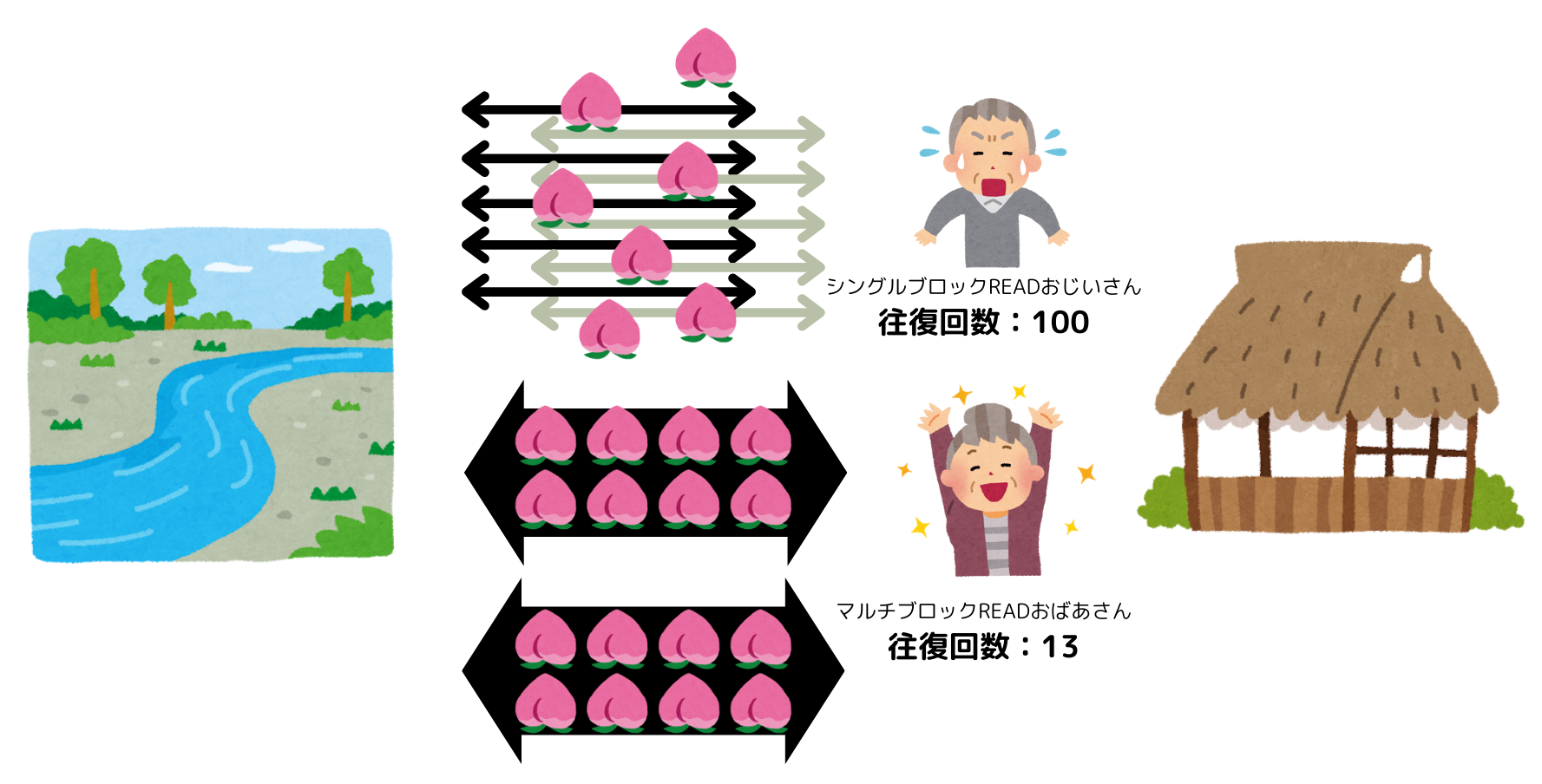
昔々あるところに、インデックススキャン・シングルブロックREADおじいさんと、フルスキャン・マルチブロックREADおばあさんがいました。
シングルブロックREADおじいさんは、川から家までデータブロック…もとい「桃」を、一度にひとつしか運べません。一般的な老人です。
対してマルチブロックREADおばあさんは、桃を一度に8つ1運べます。健康寿命が長いのは良いことです。
包丁は家にしかないので、川で拾った桃をその場で割って確かめることはできません。
桃を8つ持っているおばあさんの方が、桃をひとつしか持たないおじいさんより、川から家までの歩行速度は若干遅いですが、おじいさんが8往復するよりはうんと速いでしょう。
では、川を流れる桃が100個あったとして、以下の場合、おじいさんとおばあさんのどちらがより早く桃太郎(兄弟がいる場合はその全員)を見つけることができるのでしょうか?
- 桃すべてに桃太郎がいる場合(桃次郎、桃三郎…桃百郎までの兄弟なのでしょうか。あるいは、桃の中に双子や三つ子の桃太郎が入っているケースもあります。桃はレコード単体ではなくデータブロックを表すので、桃ひとつの中に複数レコードが存在する想定です。つまり、桃太郎は100人以上いるかもしれませんね)
- 桃ひとつに桃太郎ひとりがいる場合
- どれに桃太郎が入っているか知っている場合
- どれに桃太郎が入っているか分からない場合
桃すべてに桃太郎がいる場合(フルスキャンが有利)
フルスキャン・マルチブロックREADおばあさんの桃太郎探索方法は、まず、100個の桃を川から家まで運びます。その上ですべての桃を包丁でパカパカ開けてみて、桃太郎の有無を判別します。
一度に8運べるおばあさんが100の桃を運び切るまでのI/O回数は13回ですね。一回一回の桃運び時間も重たそうです。特に、桃太郎が1人しかいない場合、「一度全部桃を家まで運び切る」という方法はかなり馬鹿げて聞こえますね。
でも、100の桃すべてが目当ての桃であれば、最初に全部運び切ってパカパカ開いていく方法は、効率的ですよね?
一方この場合におじいさんに桃太郎探索をお願いしてしまうと、おじいさんは一度にひとつしか桃を運べないため、100回のI/Oが発生してしまいます。
桃ひとつに桃太郎がいる、かつ、どれに桃太郎が入っているか知っている場合(インデックススキャンが有利)
インデックスがある場合、インデックススキャン・シングルブロックREADおじいさんは、家からすぐ川には行きません。一度別の川に行きます。その川にはこんな桃がピンポイントで流れています。

これを元に、おじいさんは桃太郎川へ行き、100の桃の中からピンポイントで桃太郎のいる桃(データブロック)を把握し、その桃だけを家に持ち帰るのです。
インデックス(索引)は、表領域とは異なる川(セグメント、あるいはデータファイルの集まり)に存在しますが、テーブルアクセスよりかなり高速なアクセスが可能です。また、おじいさんは桃をひとつしか家に持って帰らないため、運び切るまでのI/O回数は1回となり、とても効率的に桃太郎を探索することができます。
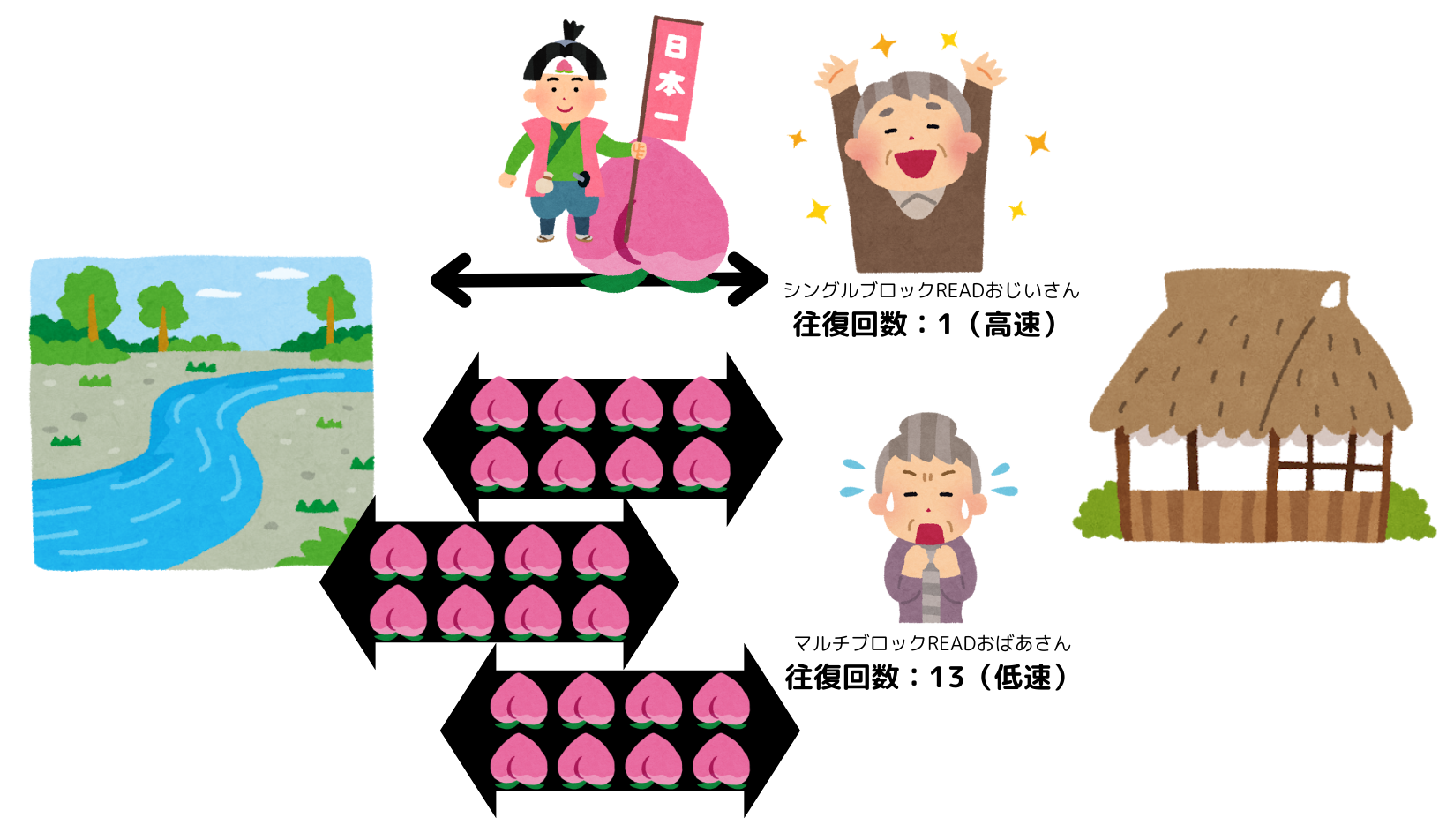
しかし、データに対して適切なインデックスを貼っていない場合、検索結果が1件にも関わらずフルスキャンが発生してしまう場合もあります。
どれに桃太郎が入っているか分からない場合がそれにあたります。実にもったいないですね。
おじいさんやおばあさんに無駄働きをさせないよう、インデックスを有効活用してください。
-
なお、実際のマルチブロックREADで参照されるパラメータはDB_FILE_MULTIBLOCK_READ_COUNTです。デフォルト値や最大I/Oサイズはプラットフォームによって異なります。
https://docs.oracle.com/cd/E16338_01/server.112/b56311/initparams056.htm ↩