はじめに
この記事で説明すること:
- Oracle SQLのインデックスや実行計画に出てくるオペレーションの種類(データ探索方法)について概要を掴むための、ごく初歩的な説明
- 物理的なディスクI/Oに着目した、データ探索オペレーションの比較
説明しないこと:
- 実行計画そのものの表示の仕方
- 探索アルゴリズム周りの論理構造
以下の説明がとっつきにくいな、カタカナや英語が多くて辛いな、と思った場合、まず抽象編から読んでみて、イメージを掴んでみてください。
TABLE ACCESS FULL(フルスキャン)
- 全表走査、フルスキャン、フルテーブルスキャンとも呼ばれる
- テーブルの全体、全行及び全列をディスク(ストレージ、記憶領域)に保存されている通りに読み込む
- 最も重い処理の一つ
- マルチブロックREADをサポート
INDEX UNIQUE SCAN(インデックススキャン)
- 索引走査、インデックススキャンとも呼ばれる
- まず索引にアクセスし、索引ブロックから行アドレス(ROWID)を取得
- その後取得したROWIDを使用して、直接該当データの入ったブロックにアクセス
- シングルブロックREAD
フルスキャン vs インデックススキャン どちらが速いの?
一般的に「インデックススキャンの方が速い」「索引をつけた方が効率的」と言われます。ただ、これは読み込むデータ量によって変化するものです。フルスキャンとインデックススキャンのデータの読み込み方の違いを比べます。
- Oracleではデータファイルを固定サイズに分割して使用しています。これをデータブロックと呼びます。固定サイズとは2KB, 4KB, 8KB, 16KBまたは32KBのいずれかです
- SQLのSELECT文においてもっとも時間のかかる処理は、ディスクからの物理的なデータブロック読み込み(I/Oコール)部分です
フルスキャンの場合、すべてのデータを検索、比較する必要があるため、読み込むブロックが隣接しています。そこで、隣接したブロックをまとめて読み込むことができるマルチブロックREAD機能をサポートしています。
このマルチブロックREADを利用することにより、ディスクからのI/O回数を減らすことができます。
もちろんマルチブロックREADそれ自体は、シングルブロックREADより重たい(低速な)処理です。そのため、1つのブロックの中にあるレコードのみで完結するような検索(単一行アクセス)の場合、一般的にはシングルブロックREADとなるインデックススキャンが高速です。
ただし、フルスキャンが効率的な場面な場面もあります。それは、テーブル内のレコードの大部分を読み出す場合です。テーブル内レコードの多くを読み出すSQLの場合、SELECT SQL実行時の最も重い処理であるI/Oコールの回数を減らすために、マルチブロックREADの使えるフルスキャンを選択することで、全体的な処理速度が改善する場合があります。
そのため、テーブル内においての選択率が高くなればなるほど、フルスキャンが有利になる場合があります。もしも実行計画を取得してみて、複数取得のSQLなのにインデックススキャンが効いている場合、データ量や選択量にもよりますが、フルスキャンにしたほうがSQLが速くなる場合もあります。
ここまでが抽象編に対応する内容になります。
なお、抽象編で用いた桃太郎の例えは、以下のようなイメージで使っていました。(不正確なところがあるかもしれませんが、雰囲気を掴むための簡単な例えのためご容赦ください)
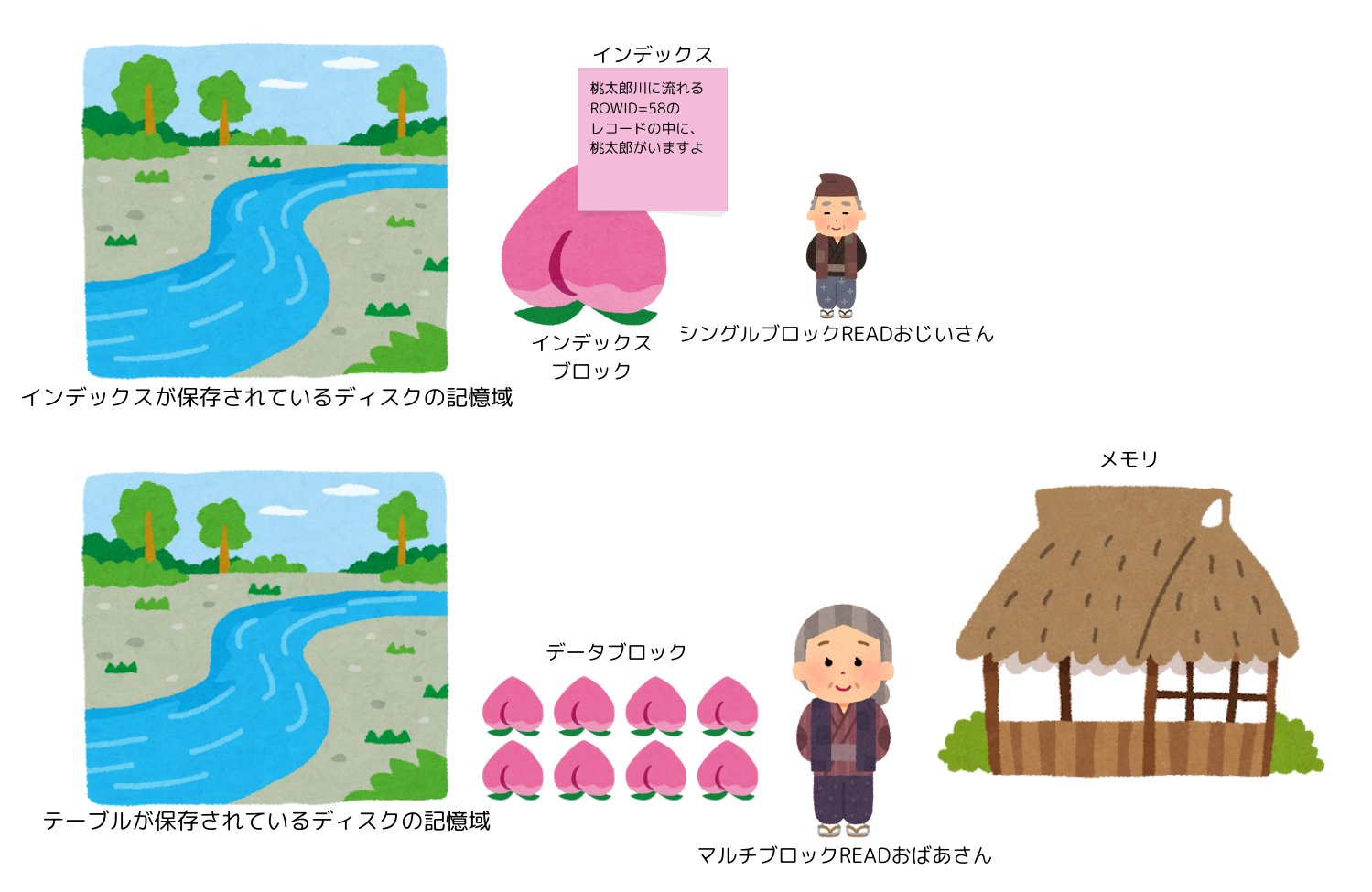
他の代表的なデータ探索オペレーション
今回は分かりやすいフルスキャン vs インデックススキャンの説明をしましたが、データ探索オペレーションには他にもたくさんの種類があります。
INDEX RANGE SCAN
実はインデックスを貼ると、完全一致のデータのみでなく、データの範囲検索も高速になります。ざっくりいうと、範囲検索をする際に使用されるオペレーションがこのINDEX RANGE SCANです。
INDEX UNIQUE SCANとの違いは、INDEX UNIQUE SCANはUNIQUE(唯一)の名の通り、1件探索のためのオペレーションです。B-Treeの走査のみを行います。
一方INDEX RANGE SCANは、B-Treeの走査に加えて、リーフノードチェーンを辿って検索します。
B-Tree(B木)について、しっかりふんわり学ぶには、以下の記事がおすすめです。
インデックスの特徴 | 図解DBインデックス
今回は物理的なディスクアクセスを重視したSQLチューニングの説明をし、探索アルゴリズムの説明を省きましたが、B-Treeをはじめとした論理的な探索アルゴリズムについて理解することでも、SQLチューニングに必要な知識が身に付くことと思います。
TABLE ACCESS BY INDEX ROWID
TABLE ACCESS BY INDEX ROWIDは、テーブルから行を読み出すためのオペレーションです。これは既にインデックスが読み込まれた直後に、レコードを読み出すために行われます。
INDEX FAST FULL SCAN(高速全索引スキャン)
インデックスの全体、つまり全行を読み込みます。TABLE ACCESS FULLと同じくマルチブロックREADが効きます。必要な列がすべてインデックス上にある場合にこれを使用することで、不要なテーブルアクセスを減らすことができ、高速化が実現します。ディスクI/Oが最も低速なのですが、テーブルアクセスもSQLの中で重い処理にはなるので、インデックスブロックへのアクセスのみで済む条件であれば、これを使うと高速化が見込まれます。
ただし、SQLにたった一列だけ別の非索引列にアクセスするような変更を追加するだけで、大きく実行計画が変わってしまいますので、ご利用は計画的に。
オペレーションの変更方法
Oracleの場合、基本的にデータ探索方法はオプティマイザにより最適化をされていますが、データの分布に偏りがあるなどオプティマイザが適切な判断をできない場合もありますので、ヒストグラムを作成するなどしてオプティマイザが最適な判断をできるようにするのがSQLチューニングの一つの方法です。
また、以下のようにヒント句を使うことで、明示的にオプティマイザにオペレーション方法を指定することもできます。
SELECT
/*+ FULL(river)*/ --フルスキャンを指定するヒント句
id, name, age
FROM
river
WHERE
name = "桃太郎";
SELECT
/*+ INDEX(river river_id_index)*/ --インデックススキャンを指定するヒント句
id, name, age
FROM
river
WHERE
name = "桃太郎";
SELECT
/*+ INDEX_FFS(river river_id_index)*/ --高速全索引スキャンを指定するヒント句
id
FROM
river;
参考文献
実践!! パフォーマンス・チューニング -索引チューニング編- 【前編】| Oracle Direct Seminar
https://www.oracle.com/jp/a/tech/docs/technical-resources/index-tuning1.pdf
実践!! パフォーマンス・チューニング -索引チューニング編- 【後編】| Oracle Direct Seminar
https://www.oracle.com/jp/a/tech/docs/technical-resources/performance-tuning.pdf
オラクルマスター教科書 Silver SQL Oracle Database SQL
https://www.shoeisha.co.jp/book/detail/9784798172361
Oracle SQL実行計画の読み方 | コーソルDatabaseエンジニアのブログ
https://cosol.jp/techdb/2020/04/how_to_read_oracle_sql_execution_plan/
実行計画の処理 | Use The Index, Luke 開発者のためのSQLのチューニングへのガイド
https://use-the-index-luke.com/ja/sql/explain-plan/oracle/operations