はじめに
2025/3/10(月)に開催された「Bedrock Night オンライン 〜AWSで生成AIアプリ開発! 最新ナレッジ共有〜」に参加しましたので、イベントレポートを執筆しました。
Xハッシュタグ:#jawsug_tokyo
本記事は個人的なメモを共有する形でまとめておりますので、一部表現が簡略化されている場合があります。ご了承ください。
アジェンダ
今回のイベントでは、以下の6つのセッションに加え、クイズセッションとディスカッションが行われました:
- LT1:Amazon Bedrock 2025年の熱いアップデート紹介(資料| Speaker Deck)
- LT2:Amazon Bedrock Knowledge basesにLangfuse導入してみた(資料| Speaker Deck)
- LT3:Dify で AWS を使い倒す!(資料| Speaker Deck)
- LT4:LangGraph × Bedrock による複数の Agentic Workflow を利用した Supervisor 型のマルチエージェントの実現(資料| Speaker Deck)
- LT5:OSSの実装を参考にBedrockエージェントを作るBedrockエージェントを作る(資料| Speaker Deck)
- LT6:Bedrock Converse APIでTool useのJSONモードを使って"クエリ拡張"と"クエリ分解"を試してみた(資料 | Qiita)
- Bedrockウルトラクイズ!
- Bedrockのお悩み相談ディスカッション
Bedrockとは
Amazon Bedrockの特徴:
- 40以上のモデルが利用可能
- 従量課金制
- テキスト生成は1回数円〜で利用可能
- RAGを簡単に構築できる「ナレッジベース」機能
- AIエージェント機能を提供
LT1:Amazon Bedrock 2025年の熱いアップデート紹介

Claude 3.7の性能と特徴
- Reasoning性能(数学的な回答性能)が向上
- Claude 3.5に比べて+10〜20ポイントの性能向上
- Extended Thinking Mode によって内部思考を行ってから回答
リクエスト時に以下を指定するだけで有効化できる:
thinking: {
"type": "enabled",
"budget_tokens": 8000,
}
budget_tokensはどれくらい考えるのか上限のトークン数を指定できるが、厳密に担保されるわけではなく目安である点に注意。
Claude 3.7 の細かいTips
-
thinking使用中も課金されるため、Quotaの制限に注意 -
budget_tokensは最低1024必要、複雑なタスクは16,000など大きめに設定 - 1,024 トークン以内のタスクでは
thinkingは不要 -
thinkingを使う場合はプロンプトで詳細な指示を避け、Claudeに任せる
Claude 3.7の使いどころ
- Claude 3.5と価格が同じなので単純置き換えとして利用可能
- 精度が出なかったタスクは
Extended Thinking Modeを試すと改善の可能性あり
Amazon Nova
クロスリージョン推論のため、推論時にデータが国外に出る可能性があることに注意。AWSも認識しており、今後の対応に期待してほしい。
Claude 3.7 x Amazon Q Developer
最新のCLIは日本語対応済み。Windows環境ではWSLを使って利用可能。
q chatコマンドで様々な質問ができる。
以下のプロンプトを入力すると、1-2時間でReactアプリとCDKによるデプロイ環境が構築可能:
I would like to create the page to introduce Amazon Bedrock to developers.
I will write the page by React and host this file to S3 and distribute by CloudFront.
Cloud you please write file and CDK script to deploy to the AWS?

発表者は、Amazon Q Developerはいろいろなことができるので、可能性を引き出してほしいと述べていました。
Amazon Bedrock Session Management API
- セッションを作成し、一定長のやり取りで管理すべき状態を保持可能
- Amazon DynamoDBなど外部DBが不要
- LangGraphではBedrockSessionSaverよりlanggraph_checkpoint_aws.saverをインポートして利用可能
発表者は、LangGraphを使うと、追加でAWSリソースを作成することなくセッションデータを管理できるため、AWSリソースの用意が面倒な場合におすすめであると述べていました。
LT2:Amazon Bedrock Knowledge basesにLangfuse導入してみた

Knowledge Baseの可視化にはCloudWatch Logsやメトリクスでは煩雑。
Langfuseを導入して一括で解決できる方法を検証した。
Langfuseの導入方法
@observeデコレータを使用して簡単に導入可能:
from langfuse.decorators import observe
from langfuse.openai import openai # OpenAI integration
@observe()
def story():
return openai.chat.completions.create(
model="gpt-3.5-turbo",
max_tokens=100,
messages=[
{"role": "system", "content": "You are a great storyteller."},
{"role": "user", "content": "Once upon a time in a galaxy far, far away..."}
],
).choices[0].message.content
@observe()
def main():
return story()
main()
コードの引用元:https://langfuse.com/docs/sdk/python/decorators
実装方法の比較

retrieve_and_generate APIの場合
- メリット:導入が簡単でシンプル
- デメリット:表示項目が少なく、Token消費量や処理時間の内訳が不明確
retrieve APIの場合
- メリット:BedrockのConverse APIを使用しトークン情報が取得可能、各処理時間が可視化可能
- デメリット:導入がやや複雑

発表者は、Knowledge BaseでもLangfuseが簡単に導入できると説明していました。retrieve_and_generateとretrieveはプロジェクトの要件に合わせて選択することが重要だと強調していました。また、Knowledge Base画面から直接ログを確認できる機能が追加されれば利便性が向上すると述べていました。
LT3:Dify で AWS を使い倒す!

Difyとは生成AIアプリケーション開発プラットフォーム:
- ノーコードで作成可能
- OSS
- 様々なLLMが利用可能
- v1.0.0がリリース済み
Difyの利用方法
ホスティングの選択肢
-
Dify Cloud
- メリット:すぐに利用可能、Self Hostより安価
- デメリット:ベクトルDB制限、API呼び出しタイムアウト60秒、セキュリティカスタマイズ不可 など
-
Self Host(AWSでの選択肢)
-
EC2でDocker Compose
- デメリット:インスタンスの管理が必要、負荷によっては高スペックとなる
- Difyの公式AMIあり
-
EKS、Aurora、ElastiCache
- AWSマネージドサービス活用
- DBサービスコスト最適化(Aurora Serverless 0ACU、ElastiCache for Valkey)
-
CDKのサンプルあり

-
ECS、Aurora、ElastiCache
- EKSより学習コストが低い
-
CDKのサンプルあり

-
EC2でDocker Compose
機能拡張
-
ナレッジベース拡張
- Dify標準ナレッジベースの課題(チャンキング戦略負荷、PDFから図表のデータ読み取り不可)は、Bedrock Knowledge Baseで解決可能
-
独自モデル利用方法
- ソースコードに追加(xinference.yaml、xinference.llm.llm.py)
- SageMaker AI連携で容易に追加可能
ガバナンス
- Guardrails:Bedrock Guardrailsを利用
- ログ記録:Bedrockログ記録有効化、Langfuseも利用可能
発表者は、Dify公式のAMIやCDKが提供されていることで、AWSでの利用環境が整っていると強調していました。
LT4:LangGraph × Bedrock による複数の Agentic Workflow を利用した Supervisor 型のマルチエージェントの実現

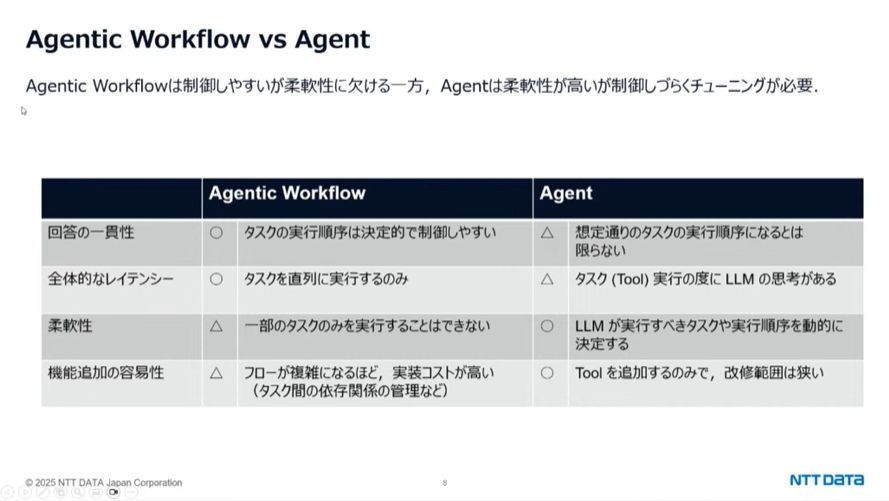
Agentic Workflow vs Agent
- Agentic Workflow:事前定義されたタスクを順序通りに実行。一貫性と正確性が高い
- Agent:状況に応じてLLMが実行ツールを自律的に決定。柔軟性が高いが制御が難しい
Supervisor型Multi Agent
- Supervisorエージェントが状況に応じて実行するSubAgentを決定
- 結果に基づいて次の行動を思考

Workflow + Multi Agent
SubAgentとして、Agentic Workflowを利用することで、Agentic WorkflowとMulti Agentの長所を組み合わせられるのではないか。
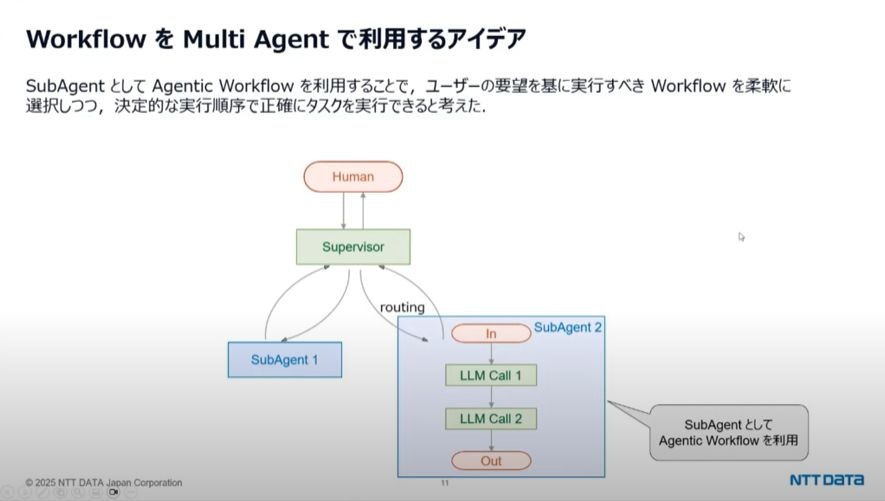
LangGraphで実装するには、以下の機能を利用します。
- SubGraph:Agentic WorkflowやAgentをノードとして利用可能
- handoff(Command):あるAgentが別のAgentに制御を渡す仕組み

発表者は、Agentic WorkflowとAgentはそれぞれ長所短所があるが、LangGraphとBedrockを組み合わせてSupervisor型MultiAgentを簡単に実装できることが強調されていました。
参考リンク:
- https://note.com/digitalsuccess/n/n958487f4d1cf
- https://qiita.com/yamato0811/items/02688690a85a670b773f
LT5:OSSの実装を参考にBedrockエージェントを作るBedrockエージェントを作る


Bedrockエージェントの種類
-
ビルド済みエージェント(正式名は不明)
- ビルド時:マネジメントコンソールやAPIで構築、Action GroupsとInstructionを登録
- 実行時:Input Textのみ渡す
-
インラインエージェント
- ビルド時:不要
- 実行時:Action Groups、Instruction、Input Textをパラメータで実行時に指定
Action Groupsの種類
- Lambda:必要なタイミングで呼び出される
- Return Control:呼び出し後、制御が呼び出し元に返却される

実装手法
- invoke_inline_agent APIを使用
- 関数からJSONを自動生成する方法:https://qiita.com/moritalous/items/5c12ca179fac7ca416c3

Instructionを定義するのが難しいのではないか?
そこで、Instruction定義の作成にCrewAIのYaml定義を参考する。
そこには、「ロール、バックストーリー、説明、ゴール、期待するアウトプット」が定義されているのでこれを取り入れる。
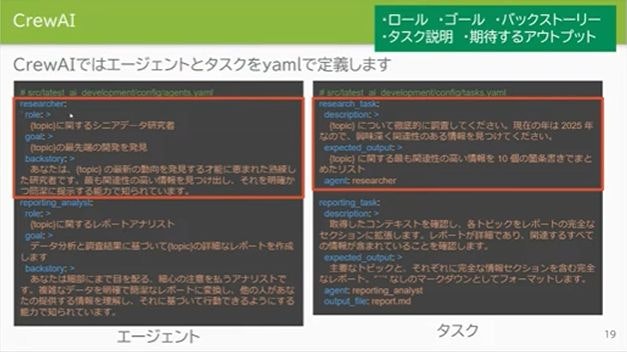
Bedrockエージェントを作るBedrockエージェントを作る
しかし、「ロール、バックストーリー」を考えるのもエージェントにやらせればよいのではないか?


BedrockのインラインエージェントとReturn Controlを組み合わせると、マネジメントコンソールを使わずデプロイ不要のBedrockエージェントが利用可能。発表者は、Instructionの定義にはCrewAIの実装が参考になることと、LLMの選択によってエージェントの動作が変わることを述べていました。
LT6:Bedrock Converse APIでTool useのJSONモードを使って"クエリ拡張"と"クエリ分解"を試してみた

RAG精度向上の手法
クエリ拡張
- 元のクエリに関連語や同意語を追加し、多様な検索結果を得る
- 使いどころ:あるキーワードで関連するドキュメントを検索できない場合
(例:「引っ越し」から、「転居」「住所変更」のドキュメントを検索できない)
クエリ分解
- 複雑なクエリを複数の簡単なクエリに分解して精度向上
- 「課題は?」という曖昧なクエリを具体的な課題に分解
- 経済的な課題は?持続可能性に関する課題は?個人情報保護に関する課題は?など。
Tool useのJSONモードの実装

- minItems、maxItems:クエリ拡張の最小・最大件数を指定
- query>description:ここの部分が重要。ツールが受け取ったクエリをどのような要件に拡張するのか定義
Converse APIの使用例:
// ツール定義
def load_tool_config():
return {
"tools": {
}
}
// ツール定義をtoolConfigにセットして実行する
response = bedrock_client.converse(
:
toolConfig=load_tool_config()
)

観点の指定
LLM任せではなく、特定の観点でクエリを実行したい場合に指定します。
- focus要素:特定の観点に基づいたクエリを取得するよう指定

ツール定義のポイント
- 詳細な説明を提供すること
- ツールが何をするか
- ツールを使用するタイミング
- パラメータの意味と影響
- 具体例よりも詳細な説明を優先
詳細は、こちらのドキュメント

ツール定義によって実装なしにクエリ拡張や分解が行え、ツール定義次第でクエリ数や観点を制御可能。発表者は、Tool useは非常に便利な機能であると強調されていました。
Bedrockウルトラクイズ!

1. この中で、Amazon Bedrockが利用できないリージョンは?
- アイルランド
- 大阪
- チューリッヒ
- 北カリフォルニア
答え:
1. アイルランド2. Bedrockナレッジベースでベクトルストアとして選択できないものは?
- Amazon Aurora Serverless
- Amazon DocumentDB
- MongoDB Atlas
- Amazon Neptune Analytics
答え:
2. Amazon DocumentDB3. Bedrockのファインチューニングに対応していないモデルは?
- Nova Micro
- Claude 3 Haiku
- Llama 3.1 70B
- Command Light
答え:
1. Nova Micro4. 基盤モデルを呼び出さずに利用できるBedrockのAPIは?
- Converse API
- Retrieve API
- RetrieveAndGenerate API
- Rerank API
答え:
2 Retrieve API5. Bedrockエージェントにできないことは?
- Lambda関数呼び出し
- ナレッジベース呼び出し
- 別のエージェント呼び出し
- CloudWatch Logsにトレースログを出力
答え:
4. CloudWatch Logsにトレースログを出力6. 日本語対応のBedrockの機能は?
- マルチエージェントコラボレーション
- ガードレール
- プロンプトルーター
- ナレッジベース with Kendra GenAI Index
答え:
1. マルチエージェントコラボレーション7. モデル応答のストリーミング出力に対応していないBedrockの機能は?
- Converse API
- ナレッジベース
- エージェント
- クロスリージョン推論
答え:
3. エージェントBedrockのお悩み相談ディスカッション

- クロスリージョン推論
- AWSでも認識していて、解決に向けた動きはある
- オブザーバビリティツールについて
- 何を監視できるようになりたいか?トレース?トークンの使用量?
- デバッグと障害対応
- ツールやエージェントのどこで障害が発生しているか分析が大変
- システムの利用者が増えるとトレースログでは解析が大変なのでグラフィカルな表示がほしい
- エージェント運用をするとコスト削減を求められる
- マルチエージェントで、適切なモデルに切り替えるためにも必要
- 生成AIのエディタを社内利用する場合に、誰がいくら使用したかというレベルで監視できるとよい
- アプリケーション推論プロファイルを使うとコストタグが利用できる
- Clineでは対応していない。
- 推論するときにユーザーを記録して、Athenaなどで分析するか、アカウントを分けるといった方法がある
まとめ
今回のBedrock Nightでは、最新のAmazon Bedrock機能やアップデートについて、実践的な知見が共有されました。Claude 3.7の新機能、KBのモニタリング手法、Difyの活用方法、マルチエージェント実装など、幅広いトピックが紹介されました。
Bedrockの進化は急速で、今後も注目していきたいと思います。次回のイベントも楽しみです!