変更履歴
260224
Papntをアップデートしました。
- Notion APIのアップデートによりPapntが正しく機能しない問題を解決しました
- 設定をするためのファイル(config.ini)を、
~/.config/papnt/config.tomlに置き換えました- アップデートしても設定がリセットされなくなりました
- わざわざこのファイルを開いて編集しなくても、必要なタイミングで必要な情報をCLIが尋ねてくるようになりました
250925
Papntをアップデートしました。
-
papnt pathsを用いてローカルのPDFファイルを指定すると、指定したPDFファイルをNotionへアップロードするようにしました
本記事の「(おまけ)PDFを副クリックしてNotionデータベースに追加」を加筆修正しました。
@nalu0926 様から頂いた修正を取り入れています。
さらに前
250105
Papntをアップデートしました。
- GROBIDを用いて、抽出された全文をページに追加する機能を用意しました
(250925追記)
GROBIDによる全文抽出機能ですが、どうも満足に使える出来でないようです。
Notionの文字数制限やトグル内ブロック数制限にひっかかってしまうためです。
いつか……、いつか直します。
250101
Papntが少しアップデートされました。
- arXivの論文にも対応しました。DOIを入力して
papnt doiしてください -
papnt pathsでディレクトリを指定すると、そのディレクトリ以下にあるすべてのPDFを追加するようにしました(130nnoel様にプルリクしていただきました) - Authorが100人を超える論文にも対応できるようにしました。100件以上はNotionに登録できないので、99番目までとlast authorだけ登録し、ページ内に残りのAuthorをベタ書きする形としました
231108
現在、Pythonのバージョンが3.12だとpipでのインストールに失敗することがあるようです。
バージョン3.10または3.11のPythonを使うのがオススメです。
詳細を記載しました。
インストールの失敗について、ご報告いただきありがとうございました。
230614
Notionデータベース作成の方法に誤りがあったため修正しました。
Firstプロパティも、Selectタイプにする必要があります。
ご指摘ありがとうございました。
前置き
私はこんな感じでNotionを使って論文の管理をしているのですが、
その際に使っているPythonプログラムをコマンドラインツールとしてまとめて、配布してみました。
その名も Papnt です。
所詮素人が作ったプログラムなので大目に見てください。
このプログラムを使った結果について、一切責任は取れません。
なにができるの?
- Notionデータベースに論文DOIを入力→
papnt doi→論文の詳細な情報がデータベースに追加されている! - Notionデータベースに論文PDFをアップ→
papnt pdf→論文の詳細な情報がデータベースに追加されている! -
papnt paths (論文PDFのパス)→論文の詳細な情報がデータベースに追加されている!(NEW)PDFもアップロードされている! - Notionデータベースのうち引用したい論文にタグをつける→
papnt makebib→bibファイルが作られている!
以下は使い方です。
Notion側の準備
データベース作成
特定の名前・タイプをもったプロパティから成る、空のデータベースを作ります。
以下の手順に従うと、比較的簡単にできあがります。
まず、以下をコピーし、Notionのどこかのページにペーストしてください。
|Name|First|Year|PDF|Journal|Type|Authors|Title|Cite in|Citekey|Edition|Publisher|Volume|Issue|Pages|Subject|DOI|HowPublished|info|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
||Select|Number|Files & media|Select|Select|Multiselect||Multiselect|||Select||||Multiselect|||Checkbox|
シンプルテーブルが作られるはずです。
このシンプルテーブルについて、OptionからHeader row(行見出し)をオンにします。

右角の3点ボタンから、Turn into database(データベースに変換)します。

1行目に書かれているとおりのプロパティタイプに変更していってください。
たとえば、Yearの列には「Number」と書かれているので、プロパティタイプをNumberにしてください。

1行目に何も書いていない列(プロパティ)はTextタイプのままにしておいてください。
この作業が終わったら、一行目は削除してしまってください。
これで論文情報を記入するデータベースが完成しました。
ここで作った以外のプロパティを持たせても大丈夫です。
例えば、ページを生成した日付などのプロパティがあると便利です。
プロパティの表示順や、表示・非表示設定は自由です。
プロパティの名前を変えていただくこともできます。
しかし、設定のために一手間かかるのでいったんこの名前のまま進めましょう。

Notion APIとの接続
作成したデータベースを、Notion APIで操作できるように設定してください。
詳細は、「Notion API データベース」あたりでググってください。
TokenkeyとDatabase IDを取得し、作成したIntegrationをデータベースにadd connectionできればOKです。

データベースをインライン表示している場合はご注意ください。
インラインでデータベースを埋め込んでいるページのIDではなく、データベースそのもののIDを取得する必要があります。
データベースの左上の::をクリックして、Open as pageしてからTokenkey、IDの取得、add connectionをしましょう。

Papntのインストール
pipでインストール
ご自身でPython環境をお持ちでしたら、以下のコマンドでインストール完了です。
% pip3 install git+https://github.com/issakuss/papnt.git@main
いくつかのパッケージがご使用の環境にインストールされるのでご注意ください。
また、Python 3.11 以降が必要です。
Homebrewでインストール
macOSをご使用でしたら、Homebrewを使って以下のコマンドでインストールするのがオススメです。
% brew install issakuss/papnt/papnt
Python環境ごとインストールするので、面倒なことを考える必要がありません。
ただし、インストールに少々時間がかかります。
私の環境だと6分ほどかかりました。
コマンドの実行
Terminalなりコマンドプロンプトなりでコマンドを打って使用してください。
いずれも、初めて実行する際は実行に必要な情報が尋ねられます。
-
Please enter Notion integration token key
と言われた場合には、上記 Notion-APIとの接続 を参照のうえ、トークンキーをTerminalなりコマンドプロンプトなりに貼り付けてください。 -
Please enter Notion database ID
と言われた場合にも、上記 Notion-APIとの接続 を参照のうえ、データベースIDを貼り付けてください。 -
Please Directory to save BIB file
と言われた場合は、BIBファイルの保存先となるディレクトリを入力してください。
~/user-name/Desktopとか。
これらの設定は ~/.config/papnt/config.toml に記録されます。
一度入力した情報に編集が必要な場合はこちらをテキストエディタで開いてください。
papnt paths
基本的にはこちらを使うのがオススメです。
ローカルにある論文PDFファイルのパスを指定すると、その論文の情報をデータベースに追加します。
以下のようにして、論文PDFファイルのパスを指定して実行します。
papnt paths /Users/issakuss/Downloads/sample1.pdf
すると、データベースにページが追加され、情報が入力されます。

PDFもこのデータベースにアップロードしてくれます。
複数のファイルをカンマで区切って入力することで、複数の論文をいっぺんに追加することもできます。
papnt paths /Users/issakuss/Downloads/sample2.pdf,/Users/issakuss/Downloads/sample3.pdf
また、PDFファイルのパスではなくディレクトリを指定することも可能です。
そのディレクトリ以下にあるPDFファイルすべてを対象に実行します。
papnt paths /Users/issakuss/Downloads/takusan-no-pdf-folder/
より詳細な挙動
- 入力されたファイルパスをカンマで区切ります
- それぞれのパスにあるPDFに対して、pdf2doiを用いてDOIを抽出します
- 抽出されたDOIをもとに論文情報を収集します
DOIから論文情報を収集するのには、crossrefapiを使います。 - 収集した論文情報をNotion Propertyの形に整えます。
- Notion APIを使ってデータベースに反映させます。
papnt doi
papnt paths で指定した際、DOIの抽出に失敗することがあります。
その場合はこちらのコマンドを使いましょう。
データベースに記入されたDOIをもとに、情報を埋めるコマンドです。
これを使うにはまず、データベース内のページにDOIを記入します。

papnt doiを実行すると、自動で論文情報が入力されます。
情報が埋められると、infoというプロパティに自動でチェックがつきます。
papnt doiは、DOIに入力があり、かつinfoにチェックがついていないページを探します。
そしてヒットしたすべてのページの情報を、入力されたDOIをもとに埋めます。
より詳細な挙動
- Notion APIでデータベースを取得します
- そこから、
DOIに入力があり、かつinfoにチェックがついていないページを探します - ヒットしたすべてのページにおいて、入力されたDOIをもとに論文情報を収集します
DOIから論文情報を収集するのには、crossrefapiを使います。 - 収集した論文情報をNotion Propertyの形に整えます。
- Notion APIを使ってデータベースに反映させます。
papnt pdf
データベースにアップロードされたPDFファイルをもとに、情報を埋めます。
papnt paths にPDFアップロード機能もついたので、もはやいらない機能かもしれません。
これを使うにはまず、データベース内のページにPDFファイルをアップロードします。

papnt pdfを実行すると、自動で論文情報が入力されます。
papnt doiと同様、PDFにファイルがあり、かつinfoにチェックがついていないページを探します。
そしてヒットしたすべてのページの情報を、PDFに書かれたDOIをもとに入力します。
より詳細な挙動
- Notion APIでデータベースを取得します
- そこから、
PDFにファイルがあり、かつinfoにチェックがついていないページを探します - PDFファイルを"you-can-delete-this-file.pdf"という名前でダウンロードします
このファイルは自動的に削除されます。 - pdf2doiを用いてDOIを抽出します
- 以降は
papnt pathsの挙動3以降と同様です
papnt makebib
特定のタグをつけた論文からbibファイルを作成するコマンドです。
これを使うにはまず、bibファイルに含めるページのCite inプロパティに任意のタグをつけます。
たとえば、next-paperというタグをつけてみましょう。
任意のタグです。自分で判別できるならどんなのでも構いません。suggoi-kenkyu-ronbunとか。
別のタグ(たとえばlatest-paper)がついていても問題ありません。

続いて、以下のコマンドを打ちます。
% papnt makebib next-paper
しばらくすると、next-paper.bibという名前でファイルが生成されます。
保存先は、config.iniファイルで指定したディレクトリです。
より詳細な挙動
- Notion APIでデータベースを取得します。
- そこから、指定されたタグのついたページを探します。
- ページに書いてある論文情報をもとにbibファイルを生成します。
さらに、同じディレクトリにnext-paper.jsonというファイルも生成されます。
これには、生成したbibファイルに含まれるすべてのジャーナル名の略称情報が含まれています。
{
"default": {
"container-title": {
"Frontiers in Psychology": "Front. Psychol.",
"Scientific Reports": "Sci. Rep."
}
}
}
たとえばPandocなら、--citation-abbreviationsオプションを使用してこのjsonファイルを指定することで、省略したジャーナル名を参考文献リストに記載することができます。
一部、省略がうまくいかないことがあります。
たとえば「PLOS ONE」が、「PLO ONE」になったりします。
そういったジャーナル名に対応するためには、~/.config/papnt/config.toml に、手動で省略形を記載してください。
[abbr]
# Specifiation of abbreviation
'Full Name' = 'Abbreviated'
'PLOS ONE' = 'PLOS ONE'
左に省略前のジャーナル名、右に省略後のジャーナル名を書いてください。
jsonファイルの生成に反映されます。
より詳細な挙動
- 生成されたbibファイルを読み込みます。
- bibファイルに含まれるジャーナル名の一覧を作ります。
- 各ジャーナル名について、iso4を使って省略名を生成します。
- config.tomlによって指定されている省略名があれば、それをもって上書きします。
- jsonファイルとして出力します。
Papntの設定
~/.config/papnt/config.toml を、テキストエディットやメモ帳など、お手元のエディタで開いてください。
以下のように表示されるはずです。
[database]
tokenkey = ''
database_id = ''
[propnames]
# Property Names
## bib name = property name
## Check bib names: https://ja.wikipedia.org/wiki/BibTeX
## Note that bib names will be used as lower case
doi = 'DOI'
author = 'Authors'
title = 'Title'
edition = 'Edition'
year = 'Year'
journal = 'Journal'
volume = 'Volume'
pages = 'Pages'
publisher = 'Publisher'
id = 'Citekey'
entrytype = 'Type'
howpublished = 'HowPublished'
# Other property
output_target = 'Cite in'
pdf = 'PDF'
[abbr]
# Specification of abbreviation
'Full Name' = 'Abbreviated'
'PLOS ONE' = 'PLOS ONE'
[grobid]
server = '' # Keep it empty if you do not wanna extract fulltext
# server = 'https://kermitt2-grobid.hf.space' # Demo server provided by GROBID developer, no use too much!
[misc]
# Directory to save bib files
dir_save_bib = ''
upload_pdf = true
必須項目(CLIから入力を求められます)
以下の2項目には、それぞれNotionデータベースにアクセスするためのTokenkeyとDatabase IDを入力してください。
[database]
tokenkey = 'vja_Qgg2FGGjfaFQFGgagafFgjoiHffaefHFfaeKeeLs'
# ↑こんな感じの50桁です(適当に作った例です)
database_id = 'ac4ss3gajfhkga887fav2343tgggaq34'
# ↑こんな感じの32桁です(適当に作った例です)
さらに、以下にbibファイルの保存先を指定してください。
[misc]
# Directory to save bib files
dir_save_bib = ''
以下は例です。
[misc]
# Directory to save bib files
dir_save_bib = '/Users/issakuss/Desktop'
GROBIDサーバーの設定
PDFから全文を抽出する機能を使いたい場合は、GROBIDサーバーを[grobid] serverに指定してください。
大体の人は、以下のような設定になると思います。
[grobid]
server = 'http://localhost:8070'
全文抽出をOFFにする場合は、以下のように空欄にしてください。
[grobid]
server = ''
そもそもGROBIDサーバーって何?という方は、こちらをご覧ください。
https://grobid.readthedocs.io/en/latest/Grobid-service/
オススメの方法はDockerです。
Dockerを使える環境にさえあれば、
docker run --rm --init --ulimit core=0 -p 8070:8070 -p 8081:8071 grobid/grobid:0.8.1
でいけます。
http://localhost:8070
をWEBブラウザで開いたときに、以下のような画面が出ていればサーバーの設定はOKです。
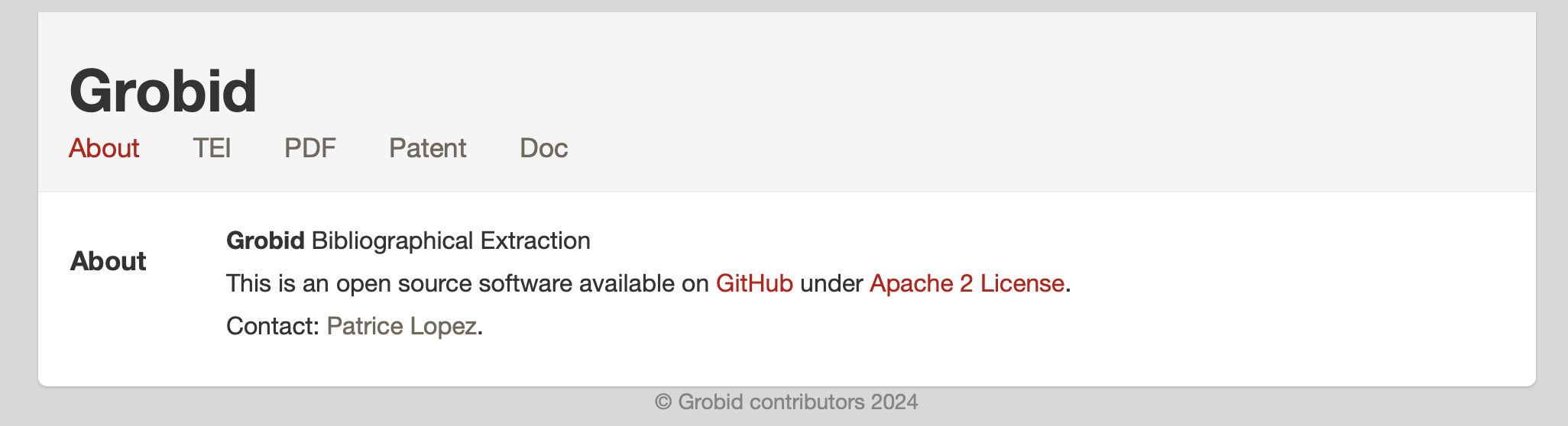
GROBIDサーバーとかよくわかんないけどちょっと試してみたいという方は、
[grobid]
server = 'https://kermitt2-grobid.hf.space'
としてみてください。
GROBID制作者が用意したデモ用サーバーを使って全文抽出を試すことができます。
ただ、負荷がかかることは前提としていないようです。
ご迷惑になるかと思うので、普通に使うときは自前でGROBIDサーバーを用意しましょう。
Dockerさえ準備できればあとは簡単ですよ!
プロパティ名の設定
もしプロパティの名前を変更する場合は、[propnames]を編集してください。
たとえば、Authorsというプロパティ名をChosyaに変えたい場合は、
author = Chosya
としてください。
(おまけ)PDFを副クリックしてNotionデータベースに追加
macOS限定です。
add-pdf-to-notion.workflow.zipをDLして、解凍してください。
workflowファイルをダブルクリックしてインストールしてください。
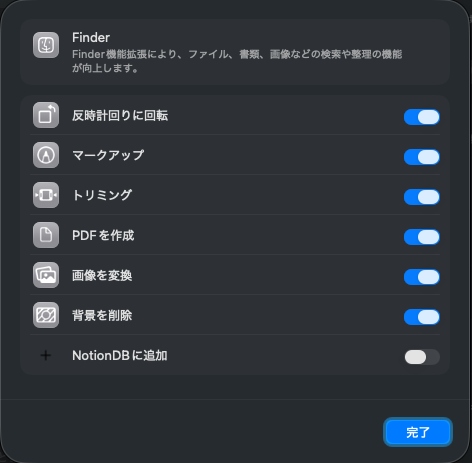
その後適当な論文PDFを副クリックすると、クイックアクションにNotionDBに追加が加わっているはずです。

加わっていなかったら、クイックアクション > カスタマイズ... から、NotionDBに追加をオンにしてください。
これを実行してみてうまくいくようならそれでOKです。
「command not found: papnt」的なエラーが出ましたら、papntのPATHを設定してやる必要があります。
エラーメッセージにあるワークフローを表示ボタンを押して、NotionDBに追加.workflowをAutomatorで編集しましょう。
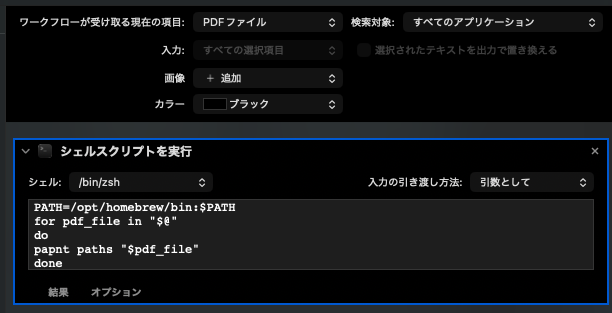
シェルスクリプトを実行の項目に注目。
初期設定で、PATH=/opt/homebrew/bin:$PATHとなっています。
/opt/homebrew/binにpapntがないと「command not found: papnt」となります。
ご自身の環境のどこにpapntがあるかを調べるために、ターミナルを開いてwhich papntをします。
これで出てきたパスから、最後のpapntを除いて.workflowファイルを書き換えてください。
たとえば、which papntしたときに
/opt/homebrew/Caskroom/miniconda/base/envs/papnt/bin/papnt
と表示されたなら、

こうです。
大目に見てください
macOSでのみ動作チェックしたので、Windowsでもうまく動くか未確認です。
もっといろんな環境で確認してからリリース(?)しようかと思ったのですが、
いつまで経っても世に出せなさそうだったので見切り発車です。
うまく動かない旨ご報告いただければ、できるだけ対応します。
時間はかかります。
パソコンに被害を及ぼしうるようなシロモノではないと思うのですが、
所詮シロウトのプログラムなのでご警戒ください。
ご不安であれば、ご自身でコード読み取っていただいて、
使えそうな部分だけピックアップするような形ででも使ってください。
pdf2doiの限界などのために、誤った論文情報を持ってくるようなことはしばしばあります。
論文情報が正しいかどうか、必ずご自身でご確認ください。