はじめに
本記事は日鉄ソリューションズ(NSSOL)様でのインターンシップで執筆したものです.
本記事は以下の構成から成ります.
- 概要
- 本記事で解説するモデルPPLMについての大まかな説明をします.
- モデル構成
- PPLMのモデル概観についての解説をします.
- PPLMの Attribute Model の設計と学習
- PPLMの「小規模モデルの接続」というメインアイデアにおける,モデルの設計・学習の解説を実際のコードを交えながら行います.
- PPLMの実行
- 学習済のモデルを実行する際の処理の流れについて,実際のコードを交えながら解説を行います.
- テスト例
- 実際に生成した文章を紹介します.
- 改善点
- 本モデルについて,改善の余地があると思われる点について解説します.
概要
本記事で解説するモデルPPLMについて,大まかな解説をします.
Plug and Play Language Model とは
Plug and Play Language Model (以下PPLM) とは, PLUG AND PLAY LANGUAGE MODELS: A SIMPLE APPROACH TO CONTROLLED TEXT GENERATION で提案されたモデルになります.著者実装もGithubに存在します.
本研究は,controlled text generation というタスクに取り組んだ研究になります.controlled text generation とは,言語生成モデルが文章を生成する際,指定した属性(positive/negative といった極性や「政治」「科学」といったトピック)に合った文章を生成させるというタスクです.
PPLMの何がすごい?
PPLMのすごいところは,既存の言語生成モデルに対して,新たに小規模なモデルを学習するだけで controlled text generation を実現するというところにあります.
このすごさは既存手法と比較することでわかります.
controlled text generation に対する既存研究のアプローチは以下のように分類できます.
- 既存の言語生成モデルを属性1つ1つに対して別々にFine-tuning
- 既存のモデルは往々にして大規模なモデルであり,その再学習を属性の数だけ行うという膨大なコストがかかる
- Decodingの際にスコアを考慮する
- 生成文の自然さが損なわれがち
- そもそもこの手法で属性をコントロールするのは難しい
前者は属性のコントロールに関して十分な性能を発揮しますが,学習コストの面で大きな問題を抱えています.新しい属性を追加したいとなったとき,大規模なモデルを再び学習する必要があります.
後者は学習コスト面では問題ありませんが,性能が前者に比べ大きく劣るようです.
PPLMで提案される手法は,前者に匹敵する性能を維持しながらも,学習コストが非常に小さいという強みを持っています.
モデル構成
PPLMはTransformerをDecoderとして用いた言語生成モデルを対象としたものになります.著者実装ではGPT-2を用いているため,今後はGPT-2の利用を前提として記述します.
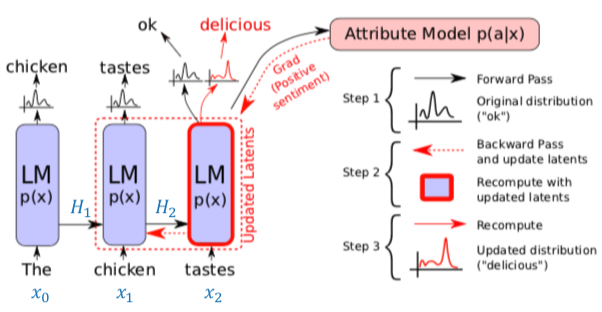
こちらはPPLMの原著論文 (https://openreview.net/pdf?id=H1edEyBKDS) より引用した図になります.ただし,青字($H_1, H_2, x_0, x_1, x_2$)は私が加筆したものです.
図中の黒矢印だけを見て, [Attribute Model p(a|x)] を無視すると元のTransformerのDecoderを用いたモデル(以降,オリジナルのモデルと呼称)となります.
図中のLM (Language Model) は Transformer の Decoder ブロックをl層積み上げたものです.
このl層のブロックそれぞれの中で発生する self-attention の Key, Value のペアを保持したものが$H_t$となります.つまり,$$H_t = [({K_t}^{(1)}, {V_t}^{(1)}), ... , ({K_t}^{(l)}, {V_t}^{(l)})]$$
ここで,${K_t}^{(i)}, {V_t}^{(i)}$はある時刻においてi層目のDecoderブロックによって作成された Key, Value のペアです.
オリジナルのモデルでは,前の時刻に出力した単語と共に,この$H_t$がLMに渡されます.つまり,
$$
o_{t+1}, H_{t+1} = \text{LM}(x_t, H_t)
$$
$o_{t+1}$ はLMからの出力であり,次のように行列 $W$ によって線形変換したのち,Softmax関数にかけて全単語の尤度の分布 $p_{t+1}$ が求まります. $x_{t+1}$ はこの分布に従います.
$$
x_{t+1} \sim p_{t+1} = \text{Softmax}(W o_{t+1})
$$
このようにして次々に単語を生成していくのがオリジナルのモデルになります.
ここからがPPLMの話になります.PPLMでは,接続した Attribute Model が $H_t$ を受け取り, $x_{t+1}$ が指定した属性 $a$ に対してどれだけ尤もらしいかを表す $p(a|x_{t+1})$ が大きくなるように $H_t$ を更新します.この $H_t$ を更新した $\tilde{H_t}$ をもとに新たに $\tilde{p_{t+1}}$ が計算されるため,単語の尤度の分布が変化します.図中においては,オリジナルのモデルから出力された $p_3$ では "ok" の尤度が高くなっていましたが, $\tilde{p_3}$ では "delicious" の尤度が高くなっている様子が描かれています.
PPLMの Attribute Model の設計と学習
PPLMでは, Attribute Model $p(a|x)$ の構成に対して2つの手法が提唱されています.一方がBag-of-Wordsを利用するもの,もう一方が判別器によるものです.ここでは,これらについて実装コードを交えながら解説します.
Bag-of-Wordsによる Attribute Model
ここでは,事前に属性に関連するキーワードの集合を作成します.著者実装において用意されている属性には "computers", "fantasy", "kitchen", "legal", "military", "politics", "positive_words", "religion", "science", "space" があります.例えば "science" であれば, "astronomy", "atom", "biology", "cell", "chemical" など,48単語が用意されています.
ある属性 $a$ についてのキーワード集合 $\{ w_1, ... , w_k \}$ を用意したとき,オリジナルのモデルによって計算される単語の尤度の分布 $p_{t+1}$ を用いると,出力単語 $x_{t+1}$ が属性 $a$ に対してどれだけ尤もらしいかを表す $p(a|x_{t+1})$ は次のように考えることができます.
$$
p(a|x_{t+1}) = \sum_{i}^k p_{t+1}[w_i]
$$
この式の右辺が表すものは,キーワード集合に含まれる単語が出現する確率,つまり望んだ属性に関連する単語が出現する確率です.
原著論文には書いていませんが, $p(a|x_{t+1})$ (これは論文内では $p(a|x)$ と表記されています)を$p(a|p_{t+1})$ として,単語の尤度の分布がどれだけ属性 $a$ にふさわしいか,と捉えた方がわかりやすいかもしれません.
なお,後述の判別器とは違い,Bag-of-Wordsを利用した Attribute Model には学習パラメータが存在せず,学習は行いません
判別器による Attribute Model
前述のBag-of-Wordsを利用した Attribute Model はシンプルな設計でしたが,問題があります.それは,属性をキーワードの集合のみで表すのが難しいケースがあるということです.そのような場合,本節で解説する判別器によるモデルが有用です.
属性の判別器は,出力単語 $x$ の属性 $a$ らしさを表す $p(a|x)$ を, self-attention の Key, Value のペア $H_t$ を利用して $p(a|H_t)$ と再解釈します.つまり, $H_t$ を入力として受け取り,属性 $a$ の尤度を返す判別器の学習を行います.
実装上ではこの判別器が返すものは,全属性に関しての尤度の分布の対数を取ったものになります.以下の実際のコードを見て行きましょう.
class Discriminator(torch.nn.Module):
"""Transformer encoder followed by a Classification Head"""
def __init__(
self,
class_size,
pretrained_model="gpt2-medium",
cached_mode=False,
device='cpu'
):
super(Discriminator, self).__init__()
self.tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model)
self.encoder = GPT2LMHeadModel.from_pretrained(pretrained_model)
self.embed_size = self.encoder.transformer.config.hidden_size
self.classifier_head = ClassificationHead(
class_size=class_size,
embed_size=self.embed_size
)
self.cached_mode = cached_mode
self.device = device
def get_classifier(self):
return self.classifier_head
def train_custom(self):
for param in self.encoder.parameters():
param.requires_grad = False
self.classifier_head.train()
def avg_representation(self, x):
mask = x.ne(0).unsqueeze(2).repeat(
1, 1, self.embed_size
).float().to(self.device).detach() # maskはpaddingの0を無視するために利用
hidden, _ = self.encoder.transformer(x)
masked_hidden = hidden * mask
avg_hidden = torch.sum(masked_hidden, dim=1) / (
torch.sum(mask, dim=1).detach() + EPSILON
)
return avg_hidden
def forward(self, x):
if self.cached_mode:
avg_hidden = x.to(self.device)
else:
avg_hidden = self.avg_representation(x.to(self.device))
logits = self.classifier_head(avg_hidden)
probs = F.log_softmax(logits, dim=-1)
return probs
class ClassificationHead(torch.nn.Module):
"""Classification Head for transformer encoders"""
def __init__(self, class_size, embed_size):
super(ClassificationHead, self).__init__()
self.class_size = class_size
self.embed_size = embed_size
self.mlp = torch.nn.Linear(embed_size, class_size)
def forward(self, hidden_state):
logits = self.mlp(hidden_state)
return logits
Discriminator クラスは,事前学習済のモデルとこれから学習する ClassificationHead の2部から構成されます.学習済のモデルの再学習は一切行いません.なお,PPLMの実行時に $p(a|x)$ (より正確には $p(a|H_t)$)のモデルとして利用するのは ClassificationHead の部分のみになります.
Discriminator の処理の解説をします.入力xはミニバッチで,各単語をIDで表した文がバッチサイズ分並んだTensorになります.これが事前学習済モデルによって処理され,hiddenが出力されます.
hidden, _ = self.encoder.transformer(x)
この hidden は入力xの各単語を分散表現で表したようなものになっています.次に,この hidden には padding による余計な単語が Tensor のバッチ処理の関係上含まれているため,それを無視するために mask をかけます.こうすることで,padding によって追加された単語の分散表現が0になります(masked_hidden).最後に,この masked_hidden の各文中の分散表現を足し合わせることで avg_hidden が求まります.1つの文中の単語を足し合わせていると考えると,これは文を分散表現で表したものと解釈できます.この avg_hidden が ClassificationHead への入力となります.
ClassificationHead は中間層の存在しない,入力層と出力層のみのニューラルネットです.入力層のノード数はavg_hiddenの分散表現の次元数で,出力層のノード数は属性の数です.出力はロジットとなっており,これをソフトマックス関数に通してさらに対数をとります.
logits = self.classifier_head(avg_hidden)
probs = F.log_softmax(logits, dim=-1)
このprobs (= output_t) の,正解クラス(target_t)に対応する値(負対数尤度)がlossとなり,このlossをbackpropして学習します.
loss = F.nll_loss(output_t, target_t)
loss.backward(retain_graph=True)
optimizer.step()
PPLMの実行
前章の Attribute Model の学習を終えたら次は実際にPPLMの実行です.なお,実際には学習済の Attribute Model が用意されているため,動作を確認するだけならば改めて学習する必要はありません.また,Bag-of-Wordsによる Attribute Model を利用する場合も学習は必要ありません.
モデル構成で述べたように,PPLMではオリジナルのモデルの $H_t$ を更新した $\tilde{H_t}$ を用いることで出力単語をコントロールします.この更新は,実際には次のように行われます.
\begin{align}
\tilde{H_t} &= H_t + \Delta H_t \\
\Delta H_t & \leftarrow \Delta H_t + \alpha \frac{\nabla_{\Delta H_t} \log p(a | H_t + \Delta H_t)}{||\nabla_{\Delta H_t} \log p(a | H_t + \Delta H_t)||^{\gamma}}
\end{align}
$\alpha, \gamma$ はハイパーパラメータです.ここで行っているのは,属性 $a$ の尤度を高めるような更新 $\Delta H_t$ の計算です.この $\Delta H_t$ 自身は複数回計算して更新したのちに, $H_t$ に加算されます.この回数は3-10回だと言われています(実装コードでのデフォルト値は3).
この更新は run_pplm.py の perturb_past関数内で行われます.まず,Bag-of-Words を利用した Attribute Model による実装を見てみましょう.
loss = 0.0
bow_logits = torch.mm(probs, torch.t(one_hot_bow))
bow_loss = -torch.log(torch.sum(bow_logits))
loss += bow_loss
過程を省きましたが,probsは $p_{t+1}$ に相当するもので,言語モデルの知識にある全単語の尤度の分布です. one_hot_bow は属性のキーワード集合に属する各単語を,言語モデルの知識にある全単語に対する one-hot-vector で表したものです.これらを掛け合わせた bow_logits の和をとることは Bag-of-WordsによるAttribute Model に記した $\sum_{i}^k p_{t+1}[w_i]$ の計算に相当します.この和の負の対数を取ったものが bow_loss となります.この bow_loss は, $- \log p(a | H_t + \Delta H_t)$ に相当します.
次に,判別器を利用した Attribute Model による実装は以下のようになっています.
ce_loss = torch.nn.CrossEntropyLoss()
prediction = classifier(new_accumulated_hidden / (curr_length + 1 + horizon_length))
label = torch.tensor(prediction.shape[0] * [class_label],
device=device,
dtype=torch.long)
discrim_loss = ce_loss(prediction, label)
loss += discrim_loss
classifier は前章で学習した,判別器の ClassificationHead の部分になります.new_accumulated_hidden の解説をします.GPT-2に対して更新した $\tilde{H_t}$ を与えて計算した,12層重ねたTransformerの最後の層から出力される隠れ状態を,判別器による Attribute Modelで解説したavg_hiddenと同様に分散表現を足し合わせたものを考えます.この計算を,未更新の $H_t$ についても同様に行い,これら2つを足し合わせたものが new_accumulated_hidden になります.このあたりは実際にコードを追いかけないとわからないかもしれませんが,隠れ状態を classifier に入力している,の認識程度でも大丈夫かもしれません.curr_length は現時点でのGPT-2に対する入力単語数, horizon_length は1がデフォルト値となっています(horizon_length 何の役割を担っているのかは本家の解説が薄くわかりません).
label に使われる class_label は run_pplm.py 実行時にユーザにより与えられるものです.例えば positive クラスに対して事前に割り当てたインデックスなどです.この label と prediction 間のクロスエントロピーロスを求めます.
このようにして計算した discrim_loss もまた,$- \log p(a | H_t + \Delta H_t)$ に相当します.
なお,Bag-of-Words と判別器による Attribute Model は併用できます.その場合は bow_loss と discrim_loss を足し合わせます
loss = 0.0
loss += bow_loss
loss += discrim_loss
ここまでで $\log p(a | H_t + \Delta H_t)$ の計算はできており( $\log p(a | H_t + \Delta H_t) = - \text{loss}$ ),あとは勾配を求めることで $\Delta H_t$ の更新が可能となりますが,これだけではうまくいきません.これまでに考えたきたことは, $p(a|x)$ (あるいは $p(a|H_t)$ )の値を大きくすることだけでした. $p(x)$ 自体については考慮していません.そのため,生成文が不自然なものになってしまう可能性が残ってしまいます.
この問題は,2つのアプローチにより解決されています.1つが, $p_{t+1}$ と $\tilde{p_{t+1}}$ 間の KL-Divergence, つまり
$$
\text{kl_loss} = \sum_i \tilde{p_{t+1}}[w_i] \log{ \frac{ \tilde{p_{t+1}}[w_i] }{ p_{t+1}[w_i] } }
$$
を小さくすることです.実装を見てみましょう.
kl_loss = kl_scale * (
(corrected_probs * (corrected_probs / unpert_probs).log()).sum()
)
loss += kl_loss
ここで, corrected_probs が $\tilde{p_{t+1}}$ ,unpert_probs が $p_{t+1}$ に当たります. kl_scale はハイパーパラメータで,基本的には0.01に設定すればいいようです.計算した kl_loss は, bow_loss や discrim_loss あるいはそれらの和にさらに加算されます. $\Delta H_t$ の更新時にすべてまとめて勾配方向に移動させる形です.
更新式の設計段階での対策は KL-Divergence のみです.もう1つのアプローチは, $\tilde{p_{t+1}}$ の計算後,実際に尤度にしたがって単語をサンプリングする際に行います.以下のようにサンプリングを行います.
$$
x_{t+1} \sim \frac{1}{\beta} \left( \tilde{p_{t+1}}^{\gamma_{gm}} {p_{t+1}}^{1-\gamma_{gm}} \right)
$$
このサンプリングが表すことは,更新した分布 $\tilde{p_{t+1}}$ だけでなく,更新前の $p_{t+1}$ も考慮したサンプリングを行うということです. $\beta$ は単なる確率分布として成立させるための正規化係数で, $\tilde{p_{t+1}}^{\gamma_{gm}} {p_{t+1}}^{1-\gamma_{gm}}$ の総和です. $\gamma_{gm}$ はハイパーパラメータで, $\gamma_{gm}$ を1に近づけると $\tilde{p_{t+1}}$ に近づき,0に近づけると $p_{t+1}$ に近づきます.実際には, $\gamma_{gm}$ は $0.8 \sim 0.95$ に設定するといいようです.つまり,更新後の分布は少し考慮するのみで,更新前の分布を重く考える,といった具合でしょうか.実装は以下のようになっています.
pert_probs = ((pert_probs ** gm_scale) * (unpert_probs ** (1 - gm_scale)))
pert_probs = top_k_filter(pert_probs, k=top_k, probs=True)
if torch.sum(pert_probs) <= 1:
pert_probs = pert_probs / torch.sum(pert_probs)
if sample:
last = torch.multinomial(pert_probs, num_samples=1)
else:
_, last = torch.topk(pert_probs, k=1, dim=-1)
1行目で $\tilde{p_{t+1}}^{\gamma_{gm}} {p_{t+1}}^{1-\gamma_{gm}}$ を計算しています.2行目では,サンプリングする際に尤度の小さすぎる単語が出現しないよう,尤度上位k個の単語のみ残すようフィルタをかけています.3-4行目の操作が $\beta$ で割る操作です.6-7行目は尤度の分布にしたがってのサンプリングで,8-9行目が貪欲に最大尤度の単語をサンプリングする場合です.
以上が $H_t$ の更新およびサンプリングの工夫という,PPLMのアイデアになります.
テスト例
実際のテスト例を載せます.著者実装には2つの命令例が載せてあるため,それらを試します.
Bag-of-Words PPLMモデルの例
まず,Bag-of-Words を利用したPPLMについて.著者実装の以下の命令を試しに使います.
python run_pplm.py -B military --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample
-Β military で military 属性の Bag-of-Words モデルを指定しています.結果がこちら.
Unperturbed generated text
<|endoftext|>The potato is probably the world's most widely eaten plant. But what if it's also the most dangerous?
In the last two decades, there's been a dramatic decrease in potato crop damage from crop rot and disease. The decline, which started in
Perturbed generated text 1
<|endoftext|>The potato-flour soup that is the best way to start a weekend!
The following recipe is one of several that I have been working on over the past few months. I think it is the best of them. It uses all the elements of the
Perturbed generated text 2
<|endoftext|>The potato bomb and the anti-Semitic attack that killed four Jewish students at a Jewish school in France are the most recent examples of bomb threats targeting Israeli facilities. The latest bomb threat targeting a U.S. nuclear facility, the bomb was sent out over the
Perturbed generated text 3
<|endoftext|>The potato chip explosion has been a boon to the world's food industry since its release in late March. A handful of companies have already announced plans to produce chips using the chips, including Chipotle Mexican Grill Corp.'s parent company, Taco Bell Corp.'s
Perturbed generated text 4
<|endoftext|>The potato is a very popular and delicious vegetable in many countries, but it can also cause severe health problems for people. The health of your body depends on your diet. If your diet doesn't include enough protein to get through the meal, or if you are
Perturbed generated text 5
<|endoftext|>The potato plant, which is a member of the same family as wheat, can be found around the world. It's also used to make potato chips, bread, and other food products.
The Plant
The plant grows as a seed and produces
Perturbed generated text 6
<|endoftext|>The potato bomb has been a controversial weapon for years. The device is packed with bomb-like devices and packed on a bomb-filled potato bomb. It's a bomb that detonates in the bomb-packed potato bomb and explodes in the potato bomb. So
Perturbed generated text 7
<|endoftext|>The potato has a lot in common with the human earworm: The first, and only, time you hear it, you'll hear the sound of the potato in your ear as well.
It's the first sound you hear when your cat or dog
Perturbed generated text 8
<|endoftext|>The potato salad is coming to a restaurant near you!
The new restaurant, in the heart of downtown Chicago, will be named the Potato Salad.
A photo posted by @the_mike_barnes on Aug 7, 2016 at
Perturbed generated text 9
<|endoftext|>The potato is a staple in many people's diet, and it is an easy food to make in your home.
The best potato chips in the world are made by hand using only potatoes.
The potato is a staple in many people's diet
Perturbed generated text 10
<|endoftext|>The potato bomb is an improvised explosive device, typically containing one bomb and no more than 10 grams of explosive and containing no explosive material.
Bombardment of an aircraft aircraft, a tank truck or explosive device
Bombardment of an aircraft aircraft
実行の際に指定した num_samples の数だけ独立に文を生成します(今回は10).赤字で強調しているのが属性に関連する語になります.これは実行時に --colorama を指定することで標準出力に赤字で表示させることができます.
生成例を見ていきましょう.まず,コントロールしていないオリジナルのモデルの生成文には military の要素は特に見られません.
コントロールした文に関しては,2, 6, 10に関しては "bomb" という単語がよく現れているのが見受けられます.ただ,他の例に関してはあまり military の文という印象は受けません.The potato から始まる military 属性の
文は少し難しかったのかもしれません.
Discriminator PPLMモデルの例
属性の判別器を利用したモデルを試します.実行は著者実装の以下の文です.
python run_pplm.py -D sentiment --class_label 2 --cond_text "My dog died" --length 50 --gamma 1.0 --num_iterations 10 --num_samples 10 --stepsize 0.04 --kl_scale 0.01 --gm_scale 0.95 --sample
結果がこちら.
Unperturbed generated text
<|endoftext|>My dog died in February, after suffering from severe arthritis. He had been suffering with a terrible cold that was causing his skin to break. I couldn't afford a replacement dog and couldn't afford to have him taken to the vet. I knew the vet would be
Perturbed generated text 1
<|endoftext|>My dog died of a heart attack at the age of 88, his son said, and her death has shocked and brought closure to the family. (Published Wednesday, March 12, 2017)
A mother who was found dead at home with a heart attack on
Perturbed generated text 2
<|endoftext|>My dog died from a rare and potentially deadly form of a rare form of sickle cell disease.
A rare form of sickle cell is called hemizygaly in the families.
The family is an important part of the game and it's
Perturbed generated text 3
<|endoftext|>My dog died after being shot.
A woman in the United States died after a man in his 20s opened fire at her home in North Carolina and injured several others.
On March 12 a neighbor heard a woman screaming. After she ran outside to
Perturbed generated text 4
<|endoftext|>My dog died of a heart attack, after suffering from a heart attack.
The title text of this page has a a a
of
of the work and work in to be an in a way, that the idea of the idea to a
Perturbed generated text 5
<|endoftext|>My dog died from a rare form of cancer that was not known before.
The rare form of brain cancer called glioblastomatosis is more common in people of European descent. People of European descent are also at greater risk of glioma
Perturbed generated text 6
<|endoftext|>My dog died from anaphase and I don't know how to give birth to a child with a rare genetic condition, an important personal health gain, with health - "" " The " " " "'The'"'" The book " The word
Perturbed generated text 7
<|endoftext|>My dog died from a rare form of cancer, the Daily Mail reports.
"I have a really strong desire to help others and so I am happy to have the chance to help others to be happy and to love their loved ones and that's something I love
Perturbed generated text 8
<|endoftext|>My dog died because I didn't let him go.
I have a 6-year-old, 3-year-old, 1-year-old, 2-year-old, and 2-year-old. I have a very active and
Perturbed generated text 9
<|endoftext|>My dog died of a heart attack while while while I was in the house. I had the old man's head and body, and a large one, I have my hands and feet with me. I have a good time, and the best, as I am
Perturbed generated text 10
<|endoftext|>My dog died from a rare form of cancer, scientists have found.... James M. He he is is is is a
A lot of a lot of a fun!! The Great Escape The Great Escape! The Great Escape! The Great Escape
Bag-of-Words のときとは違い,関連する単語の強調表示はできません.
-D sentiment で,事前に学習済の "sentiment" の判別器を指定しています.この判別器は "very_positive", "very_negative" の2つのクラスを判別する判別器で,今回指定している class_label=2 は, "very_positive" を表します.(なお, class_label=3 とすると "very_negative" を指定できます)."My dog died" というネガティブな文章しか生成されなさそうな始まりに対して,ポジティブな文を生成させようという例です.各例を見ていきましょう.
属性のコントロールをしていないオリジナルのモデルの生成文は悲観的な文章になっています.
コントロールした生成文に関しては,2, 5, 7などは比較的前向き(というよりネガティブさがない)文が生成されています.rare や love などの単語が目立ちます.1, 3, 4, 6, 8, 9, 10などはネガティブさが消えていなかったり,不自然な文になっていたりするため,文の始まりと属性が合わないと適切な生成が困難である様子が見て取れます.
もう少し生成しやすそうな例を試す
上記の例は生成が難しそうな文の始まりと属性の組み合わせでした.もう少し文の始まりと属性を合わせてみましょう.始まりを The potato にして,属性を positive_words にします.
python run_pplm.py -B positive_words --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample
結果がこちら.
Unperturbed generated text
<|endoftext|>The potato is probably the world's most widely eaten plant. But what if it's also the most dangerous?
In the last two decades, there's been a dramatic decrease in potato crop damage from crop rot and disease. The decline, which started in
Perturbed generated text 1
<|endoftext|>The potato-like, gluten-free, low-calorie, sweet, and nutritious sweet potato pie recipe. Easy to make, and perfect for those who love to eat sweet, healthy, and filling pie!
When my kids are home from school
Perturbed generated text 2
<|endoftext|>The potato has been a popular favorite since the 1980s. But with its recent popularity and rising popularity, is it time to eat your favorite potato again?
The potato is still a great food to enjoy and enjoy, with its healthy benefits and delicious flavor
Perturbed generated text 3
<|endoftext|>The potato chip craze is in full swing.
The popular snacks have been making the rounds in recent weeks as people seek out fresh and healthier alternatives to fried foods.
But there may have never been a better time to eat these crispy snacks than
Perturbed generated text 4
<|endoftext|>The potato is a very versatile, versatile vegetable and it is a great addition to many tasty salads, soups and stews.
The potato is the star of many salads and stirfries. I love the versatility of potatoes in many recipes.
Perturbed generated text 5
<|endoftext|>The potato is a common dish, so much so in fact that it is often served with pasta. It is often served with rice, or topped with a sweet and savoury sauce.
Serves 4
1 onion
2 cloves garlic
Perturbed generated text 6
<|endoftext|>The potato has become the new darling of American farmers in recent years. Its popularity is so great that it has even been featured in many successful television shows like "The Big Bang Theory".
But there has never been an easier way to prepare your favorite snack
Perturbed generated text 7
<|endoftext|>The potato is a favorite among the health-conscious, so what better time to try a new way to eat them? The recipe below is easy and healthy, and you can easily freeze it, freeze it for later, reheat it for breakfast or lunch,
Perturbed generated text 8
<|endoftext|>The potato salad that inspired the popular dish is one of a number of new varieties of the dish being sold at popular popular restaurants. (Photo: Thinkstock)
When it comes to classic American comfort food, a popular dish that's popular around the country
Perturbed generated text 9
<|endoftext|>The potato is a staple in many people's diet, and it is not only delicious in its own right, but is also a good protein source. It is easy to eat, nutritious, and healthy.
Potato, as we know it, originated
Perturbed generated text 10
<|endoftext|>The potato has been used as an ingredient in everything from salad dressing to soups for decades. However, it was once thought to be a poor performer in the kitchen. In recent years, scientists have shown potatoes to be a promising food source. The research shows
最初のオリジナルの生成文は客観的な事実を述べているような文で,ポジティブな印象は特に受けません.他の文は,おおむねポジティブな文になっているのが見て取れます(2は何を言っているのかよくわからなかったり,3は better の前に never が付いてしまっていたりしますが...).
やはり,文の開始と属性の取り合わせはある程度考える必要がありそうです.これは,論文にも「属性によっては制御が難しい」と記されています.
改善点
実行時間が長い
今回の実験では,単語数50の文章を生成しました.その際,1つの文章を生成するのに,オリジナルのGPT-2による生成には2-3秒しかかかりませんが,Bag-of-Words によるモデルでは22秒ほど,判別器によるモデルでは95秒ほどかかっています.
利用タスクにも依存しますが,50単語程度の文を作成するのにこれほど時間がかかってしまうのがネックになります.学習するパラメータはオリジナルのモデルに比べると非常に少ないですが,ハイパーパラメータは $\Delta H_t$ を更新する際の $\alpha, \gamma$, KL-Divergenece kl_loss, $p_{t+1}$ と $\tilde{p_{t+1}}$ のバランスをとるための $\gamma_{gm}$ と多く,1回の実行に時間がかかりすぎるのはチューニングのコストに響いてしまうと考えられます.
この長さはおそらく, $H_t$ の更新時に偏微分の操作を何度も行っているのが原因だと私は考えています.普通のネットワークでは順方向に伝播していくだけで,そのような操作はありません.偏微分したりせずに, $H_t$ を入力すると $\tilde{H_t}$ が出力されるようなネットワークを構成・学習できればこの問題は解決できるかもしれません.
Transformer 利用モデルに限定
本モデルのメインアイデアである $H_t$ の更新は, Transformer をデコーダとして利用している言語モデルに限る話になります.今後,違った構造が主流になるとこの手法は利用できない可能性があります.
まとめ
本記事では,Transformer をデコーダに用いたモデルで文を生成する際に,指定した属性に合った文章を生成する手法PPLMについて解説いたしました.
PPLMのメインアイデアは,外部接続したモデルにより,指定した属性の文を生成する方向に Transformer のself-attention の Key, Value を再帰的に更新すると言う考えです.この考えにより,オリジナルの大規模なモデルを再学習する必要なく属性の制御が可能になります.
テスト結果からは,おおむね制御できているものの,文の始まりと属性の相性が悪いと生成が困難である様子が見てとれました.また,実行時間がオリジナルのモデルに比べて長くなってしまう欠点もあります.
参考文献
読んだもの
-
PLUG AND PLAY LANGUAGE MODELS: A SIMPLE APPROACH TO CONTROLLED TEXT GENERATION
- 原著論文.平易な英語で書かれており,とても読みやすいため,興味があればぜひお読みください.
-
Language Models are Unsupervised Multitask Learners
- GPT-2の原著論文.基本的なモデル構成についてはGPTの原著論文(後述)の方に書かれています.
-
The Illustrated GPT-2 (Visualizing Transformer Language Models)
- GPT-2を懇切丁寧に図解した記事.非常にわかりやすいです.
-
The Illustrated Transformer
- Transformer を懇切丁寧に図解した記事.非常にわかりやすいです.
-
作って理解する Transformer / Attention
- Transformer とその要素技術である self-attention, さらにそもそも attention とは? から始まる丁寧な記事です.上記の The Illustrated Transformer と併せて読むと理解が深まります.
他・関連文献
-
Improving Language Understanding
by Generative Pre-Training- GPT-2の古いバージョン,GPTの原著論文.モデル構成についてはこちらに書かれています.
-
Attention Is All You Need
- 言わずと知れた Transformer を発明した原著論文.