
はじめに
社内の経費申請システム(SharePointサイト)がリニューアルされることになりました。
それにともない、旧システムに残っている申請データを全件保存しておく必要が生じました。
件数は GE(一般経費)708件・TE(出張経費)470件、合計1,178件。
1件ごとに以下作業を行わなくてはなりません。
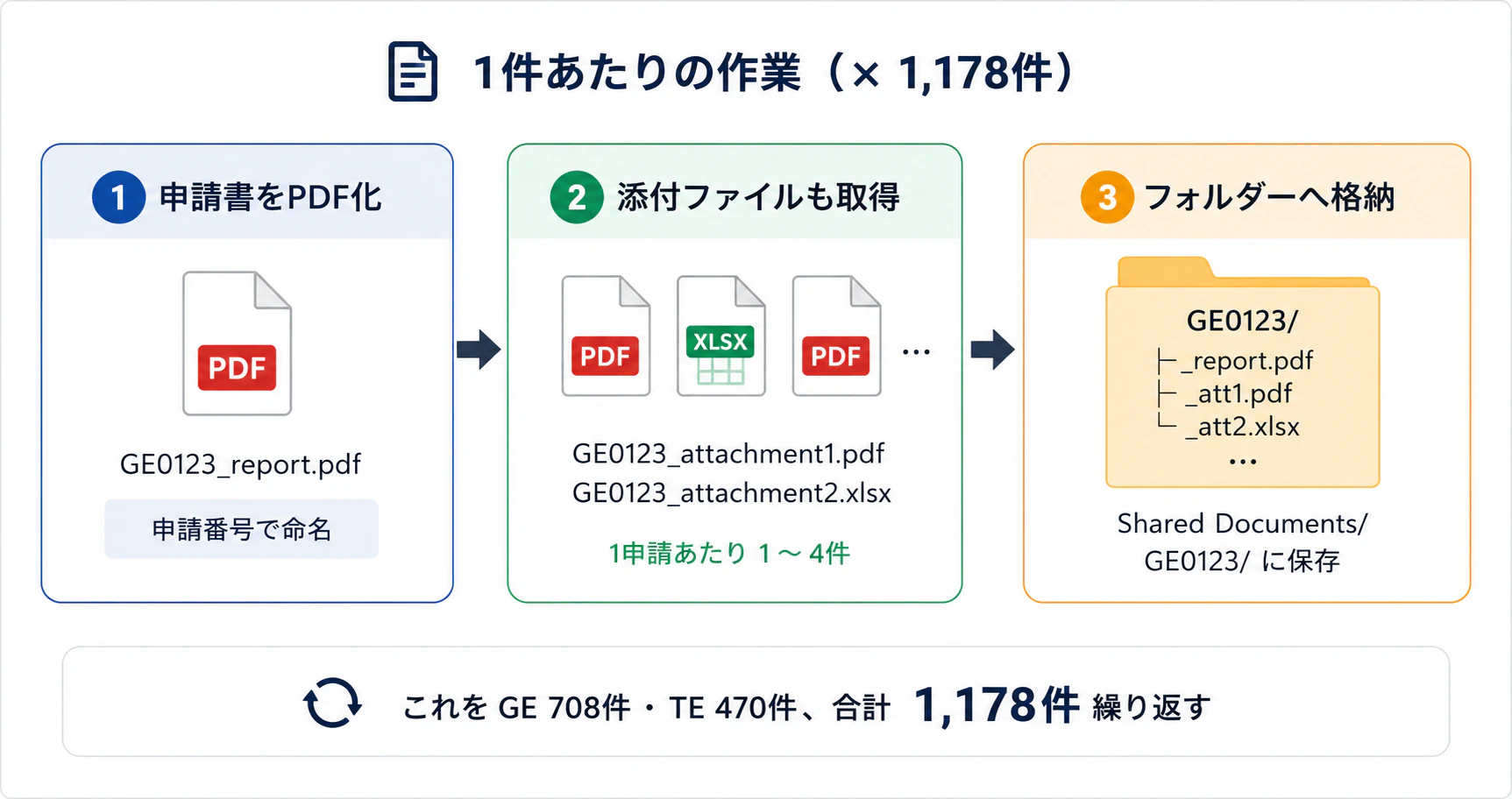
これを1,178件分、手作業でやるとしたら……
1件ずつ申請書を開いて、Ctrl+Shift+P でPDF化して、ファイル名を「GE0123_report.pdf」に変えて、添付ファイルも保存して、SharePointの正しいフォルダーに入れて……
気が遠くなるので「自動化しよう!」と動き始めたのが、この話のスタートです。
目次
- なぜ Power Automate をやめたのか
- Pythonで作った構成
- 生成AIをどう使ったか
- ハマったポイント2選
- 途中で止まっても安全に再開できる設計
- Power Automateと比べてどうだったか
- 結果
1. なぜ Power Automate をやめたのか
最初からPythonで作ったわけではありません。
まず使い慣れた Power Automate(Microsoftのノーコード自動化ツール)で実装を試みました。
クラウドフローはある程度動いた
クラウドフロー:インターネット上で動くフロー。
SharePointから添付ファイルを取得してOneDriveに保存する部分は、クラウドフローで実現できました。ここまでは順調でした。
デスクトップフローで詰まった
デスクトップフロー:
PCの画面を自動操作するフロー。ブラウザの操作なども自動化できる。
申請書をPDF化するには、ブラウザで申請書を開いて印刷する操作が必要です。これをデスクトップフローで実装したのですが、2つの問題にぶつかりました。
① 実行中はPCがまるごと占有される
デスクトップフローが動いている間、マウスやキーボードが自動操作されるため、他の作業が一切できません。1,178件の処理には数時間かかるため、その間ずっとPCを放置するのは現実的ではありませんでした。
② 処理が正しく動いているか確認できない
自動操作の画面を眺めていても「本当に正しいファイルが取れているのか」が見えにくく、全部終わってから初めて問題に気づくということが起きました。ログも限定的で、どこで失敗したかの調査に時間がかかります。
➡「PCを占有せず、バックグラウンドで動きながら、処理状況をリアルタイムで確認できる」構成が必要だと判断し、Pythonで作り直すことにしました。
2. Pythonで作った構成
今回使ったのは主に2つのライブラリです。
| ライブラリ | 役割 |
|---|---|
| Playwright | ブラウザを裏側で自動操作する。ログイン・申請書を開く・PDFに変換する |
| requests | SharePointのAPIを通じてファイルの取得・保存を行う |
Python スクリプト
├── Playwright ── ブラウザをバックグラウンドで操作し、申請書をPDF化
├── requests ── SharePointへファイルをアップロード・フォルダー一覧を取得
└── ログイン情報(Cookie)を両者で使い回す仕組み
Cookieとは:
「このユーザーはログイン済み」という情報をブラウザが持ち歩く仕組み。
Playwrightでログインした際のCookieをrequestsにも渡すことで、二重ログインなしでAPIも使える。
処理の流れはこうです。
① Playwrightでブラウザを起動・Microsoftアカウントへログイン
② ログイン情報(Cookie)をrequestsにも渡す
③ 申請書リストをSharePoint APIで取得(1,178件)
④ 1件ずつ:申請書を開く → PDFに変換 → SharePointの所定フォルダーへ保存
ログで「今何が起きているか」をリアルタイムに把握できる
Power Automateのデスクトップフローでの一番の問題は「処理が正しく動いているかわからない」ことでした。Pythonに切り替えた際、この問題をログで解決しています。
処理中は以下のようなログがターミナルに流れます。
[1/708] 処理中: GE62
PDF アップロード完了: GE62_report.pdf
[2/708] 処理中: GE63
PDF 生成失敗: GE63_report.pdf ← どこで・何が失敗したか一目瞭然
[3/708] 処理中: GE64
PDF アップロード完了: GE64_report.pdf
添付ファイル アップロード完了: GE64_attachment1.xlsx
「708件中の何件目を処理しているか」「どのファイルが失敗したか」がリアルタイムでわかります。処理が終わった後にログファイルを確認すれば、全件の成否も一覧で確認できます。
Power Automateのデスクトップフローでは「全部終わってから問題に気づく」でしたが、Pythonではエラーが出た瞬間に番号とファイル名がわかるので、ピンポイントで再処理できます。
3. 生成AIをどう使ったか
今回のメインツールは Claude Codeです。
① スクリプト全体を30分で完成させた
Power Automateでの実装に約3日かかったのに対し、Claude Codeに構成を伝えたところ約30分でスクリプトが完成しました。
やったことはシンプルで、「何をしたいか」を日本語で伝えただけです。
伝えた内容の例:
「SharePointにPlaywrightでログインし、申請書の一覧をAPIで取得、
1件ずつページを開いてPDF化してSharePointにアップロードするPythonスクリプトを作って。
ログイン情報はAPIクライアントとも共有する設計で。」
② ハマったときの壁打ち相手
うまく動かないとき、エラーメッセージとコードをそのまま貼って相談しました。
相談例:
「パスワードを自動入力するとMicrosoftにログイン画面へ戻されてしまう。
このコードとエラーを見て、原因と解決策を教えて」
AIが「人間らしいタイピング速度で入力すると検知されにくい」という方向性を教えてくれたので、そこから自分で試して調整しました。
注意点:AIの提案をそのままコピペしても動かないことはある。 「この方向が正しそう」という仮説をもらって、自分で検証する、という使い方が現実的です。
③ コードを整理・読みやすくしてもらう
動いたコードを「関数に分割して、コメントもつけて整理して」と依頼すると、きれいに返してくれます。後から見直すときの負担が大幅に減りました。
4. ハマったポイント2選
① 全件処理後の検証で「500件しか確認できていない」ことが発覚
全件処理が終わった後、「本当に1,178件すべてアップロードできているか」を確認するための検証スクリプトを走らせました。SharePointのフォルダー一覧を取得して件数を数えるだけのスクリプトです。
ところが、1,178件あるはずのフォルダーが500件しか返ってこないという結果になりました。
原因: SharePointのAPIは、1回のリクエスト(問い合わせ)で返せる件数が最大500件に制限されています。処理そのものは正しく動いていたのですが、確認スクリプト側がこの制限を考慮していませんでした。
# 問題のある取得方法(500件で打ち切られる)
/Folders?$top=500
解決策: 「GEで始まるフォルダーだけ取得する」という条件(フィルタ)を加えました。GEとTEでスクリプトを分けて実行する構成だったため、これで1回500件以内に収まりました。
# 解決後(GEで始まるフォルダーだけ、最大1000件取得)
/Folders?$filter=startswith(Name,'GE')&$top=1000
② 長時間動かすとログアウトされる
1,178件の処理には数時間かかります。その間にログイン状態が切れると、「ログイン画面のスクリーンショット」がPDFとして大量保存されるという最悪の事態になります。
ログイン状態(Cookie)は一定時間で失効します。ブラウザは自動で更新しますが、APIクライアント側は古い情報を持ち続けます。
解決策: 1件処理するごとに、ブラウザの最新ログイン情報をAPIクライアントにも渡し直す仕組みを入れました。
# 1件処理する前に、ブラウザの最新ログイン情報をAPIクライアントへ同期
sp.set_cookies(await ctx.cookies())
これにより、ブラウザが自動更新したログイン情報がAPIクライアントにも常に反映されます。
5. 途中で止まっても安全に再開できる設計
1,178件の処理が途中でエラー終了した場合、最初からやり直しでは時間の無駄です。そこで2つの仕組みを入れました。
処理済みはスキップ: SharePointにすでにフォルダーが存在する件は自動的に飛ばします。
SKIP_EXISTING = True # 処理済みの件をスキップする
特定の件だけ再処理: 失敗した件番号だけを指定して再実行できます。
RETRY_IDS = ["GE-0312", "GE-0487"] # この2件だけ再処理する
「500件処理して501件目でクラッシュしたとき、501件目から再開できる」というのは、大量処理の自動化では地味に重要な設計です。
6. Power Automate と比べてどうだったか
今回の要件では、Power Automate よりも Python + Playwright の方が相性が良い結果になりました。
| Power Automate | Python + Playwright | |
|---|---|---|
| 向いているケース | 少量処理・簡単な業務自動化 | 大量処理・複雑な操作 |
| 実行中 | ❌ PCが占有される | ✅ バックグラウンド実行 |
| 進捗確認 | ❌ 完了後に問題が見つかりやすい | ✅ ログでリアルタイム確認 |
| PDF化 | ❌ レイアウト崩れが発生しやすい | ✅ 画面そのまま出力 |
| エラー時 | △ 再実行が少し面倒 | ✅ 続きから再開可能 |
| 導入ハードル | ✅ GUI中心で始めやすい | △ Python環境が必要 |
| 生成AIとの相性 | △ フロー相談が難しい | ✅ コードをそのまま相談可能 |
結論:
件数が少なく、PDF化が不要な業務なら Power Automate は今でも十分強力です。
一方で、「大量処理 × PDF化 × 再実行性」 が必要な今回のケースでは、Pythonの方が相性が良いと感じました。
7. 結果
- GE 708件・TE 470件、合計1,178件のPDFと添付ファイルをSharePointへ格納完了
- スクリプト完成までの時間:約30分(Claude Codeで実装)
- 実行時間:約3時間(GEとTEを並列実行)
- Power Automateでの実装:GE・TE合わせてクラウドフロー・デスクトップフロー計4本を約3日かけて構築 → それでも限界に
| Power Automate | Python + Claude Code | |
|---|---|---|
| 実装にかかった時間 | 約3日(フロー4本) | 約30分 |
| 全件処理の実行時間 | 未完(断念) | 約3時間 |
おわりに
「ローコードツールで無理なら、コードで書く」という選択は、思ったよりハードルが下がっています。
生成AIに「何をしたいか」を伝えると土台を作ってくれるので、Pythonの経験が少なくても取り組みやすくなっています。「全部自分で書く」ではなく「AIと一緒に作る」という感覚です。
同じような課題を抱えている方の参考になれば幸いです。
最後まで読んでいただきありがとうございました!