
はじめに
ニッチな話題ですいません!![]() この記事はたぶん日本で5人くらいしか興味ないんじゃない?とも思いましたが自分用のメモも兼ねて書きます。
この記事はたぶん日本で5人くらいしか興味ないんじゃない?とも思いましたが自分用のメモも兼ねて書きます。
オンプレミスのミドルウエアであるWatson Explorer( 以下WEX )は最新の11.0.2からApplication Builder( 以下AB )を使ってBlumixのサービスであるWatson Discovery Service( 以下WDS )と統合できるようになっています。 (WDSについてはこちらの記事をどうぞ。) 「統合」とは具体的にはWEX/ABのデータソースにWDSが指定でき、ウイジェット上でWDSの検索結果も一緒に表示できるようになったってことです。といっても「ABって何?」という方も多いと思います。要はWEX/ABでは下記のような検索結果を集約したポータルを簡単に作れるんですが、そこにWDSの結果も簡単にはめ込める、ってことです。
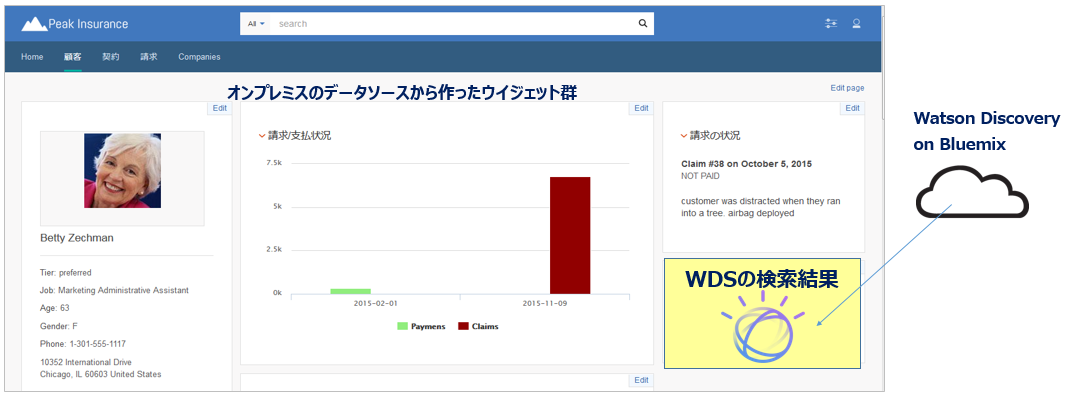
今までWDSが英語のみのサポートだったのでシカトしていましたが、先日日本語もサポートしたので、がぜん両者の統合に興味がわき、やってみました。
- 当記事は両者の統合に興味があるのでWEXやABのご紹介は割愛します
WEX/EE(FC)とWDSの違い
両方とも「コグニティブな情報検索」という意味では課題の領域は同じですが、おおざっぱに下記の違いがあります。
| 切り口 | WEX/EE(FC) | WDS |
|---|---|---|
| 実績 | 10年以上 | 2016/12~ |
| 提供形態 | オンプレミスのミドルウエア | クラウド上のサービス |
| 費用 | PAライセンス(TB課金) | Bluemix上の従量課金 |
| 謳い文句 | エンタープライズ・サーチ | (コグニティブ) ディスカバリー |
| 扱うコンテンツ | オンプレ中心 | オンプレ&クラウド+ニュース |
| 扱えるデータソース | ファイルからDBまで非常に多彩 | PDF/Word/HTML/JSON (+Crawler) |
| 想定キャパシティ | TBクラス | TBクラス |
| 自然言語処理(NLP) | WKS,CAStudio | WKS,NLU |
| AIフレーバー | NLQ,NLP,Learning to Rank, Document Classification..etc | NLQ,NLP, Relevancy Training, Passage Retrieval..etc |
| UI | Admin Console / App Builder | Discovery Toolingまたは自作 |
- 両者は基盤や仕組みが違いますし、機能面でも同じではありません。以下私見ですが、現時点ではWEXの方が機能はリッチであり、それをWDSが急速にキャッチアップしている、という感じです。
- しかし両者は競合するものでもありません。ロードマップ的には両者が連携してオンプレミスとクラウドの両方の世界をハイブリッドにカバーし、探索と発見(Explore&Discover)を行うのが最終的な目標です。
- WDSはクラウド上のサービスなので①基盤構築や管理の手間が不要 ②使い勝手が簡単で敷居が低い ③費用面でスモールスタートしやすい などの利点がある一方で、欠点として ①WEXに比して機能がまだ不足 ②クラウド上に社内文書をアップするのは不安(or 禁止) ③日本語サポートがまだFULLでない などのご懸念もあるかと思います。(WEXは利点と欠点がその反対、ですね。)
WEXとWDSの統合の利点/ユースケース
どっちがどう、という両者の比較ではなくて「WEXを既にお持ちのお客様が追加でWDSを活用する利点やユースケース」を考えます。
【注】![]() は現時点(2017/10月)は英語の場合のみに当てはまります。
は現時点(2017/10月)は英語の場合のみに当てはまります。
![]() コンテンツの適材適所配置(+ハイブリッド検索)
コンテンツの適材適所配置(+ハイブリッド検索)
コンテンツの置き場所の観点では、オンプレミスのデータはオンプレミスに置き、クラウド上で発生したデータはクラウド上に置いておくのが(移動しなくて済むので) 一番楽です。それらを場所を意識せずにハイブリッドに検索できれば、更に楽です。
![]() コンテンツのオフロード
コンテンツのオフロード
オンプレミスのデータはストレージの費用や管理の手間・コストがかかります。一般にデータは増えていく一方ですので、一部をクラウド上にオフロードすることでコストを抑えられます。WEXのライセンスはTB課金なので、「そろそろ一杯..」になりそうな場合の追加投資を抑える選択肢にもなるでしょう
![]()
![]() ニュース・コンテンツの利用
ニュース・コンテンツの利用
Watson Discovery Newsを使って自社製品の評判やお客様企業に関する最新ニュースなどを入手して、オンプレのデータと一緒にABの画面に表示できます
![]()
![]() NLUによるエンリッチメントと分析・集計
NLUによるエンリッチメントと分析・集計
WDSを使うとコンテンツに対するセンチメントなどNLUエンリッチメントのメタデータを入手できます。それらメタデータを使ってダッシュボード上に分析や集計チャートなどを描画することが簡単にできます。
WEXとWDSの統合のしくみ
下記がWEX/ABとWDS間の統合の仕組みの絵です
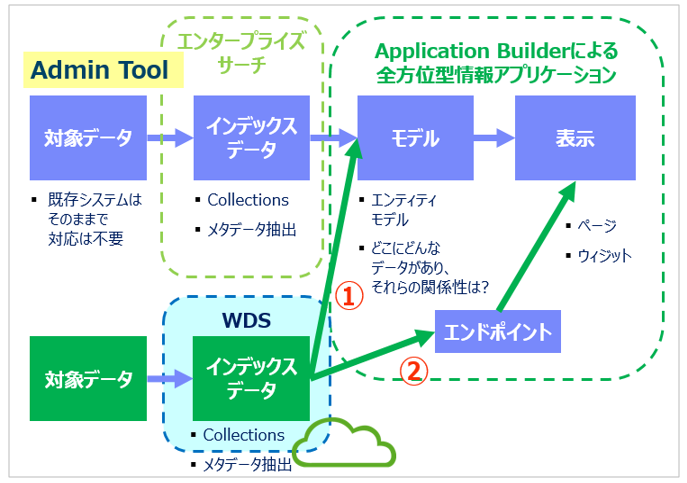
- 上の段の流れは通常のWEX/ABの仕組みです。WEXではオンプレミスのデータをクロールしてインデックスを作成します。通常のエンタープライズ・サーチではこれを検索して終わり、ですがABのアプリケーションの場合はそのインデックス(Collection)をデータソースとして、更にエンティティやアソシエーションなら成る論理モデル(RDBでのERモデルのようなもの)を定義します。その論理モデルをベースにウイジェットを開発してパネルに配置していく流れとなります。
- WEX/AB-WDS統合での開発は上記の従来の流れをほぼそのまま踏襲できます。従来はデータソースはオンプレミスに構築したインデックス(Collection)でしたが、WDS統合の場合は代わりのデータソースとしてクラウド上のWDSのインデックス(Collection)を定義すればいいだけです。モデルの定義やウイジェットの開発、QueryAPIを使えること等はほぼ同じですし、WDSの照会API(REST)も意識不要です。ゆえにWEX/ABに慣れた方ならスムースに開発できます。(上図①の流れ)
- ただ、①の流れは簡単でいいのですが、現時点ではWDSの一部機能利用に制約があり、生憎WDSの最新機能(例えばPassageなど)をフルに活用できません。その場合は自分でエンドポイントを定義して自力でWDSに対してREST要求を出すこともできます。自力でAPIのパラメーターを組み立ててREST要求を発行しますので、WDSの最新の機能をフルに利用できます。(上図②の流れ)
WEX 11.0.2でのWDS統合の制約事項
Watson Discovery Services as Application Builder Data Sourcesに機能制約の記載があります。実際にWEX/ABのログを確認したらWEX/ABがWDSに対して発行する要求のAPIのVERSIONは2016-12-01でした。よって、WDS本体は2017年の精力的に機能追加が続いているものの、それらの新機能は残念ながらWDS統合(前項①の流れ)では利用できません。(まあ新機能っても、日本語がフルサポートになってからでいいんじゃない、とも思いますが。いずれにせよ先々の拡張をお楽しみに!ということで)
やってみた
![]() 以降は細かい手順になりますのでWEXのApp Builderのご経験がない方には「???」かもしれません。かといってApp Builderの解説まで入れるのは焦点がボケますので、申しわけありませんが細かい解説は割愛します。「やる機会があったらちゃんと読む」程度にお留めおき下さい。
以降は細かい手順になりますのでWEXのApp Builderのご経験がない方には「???」かもしれません。かといってApp Builderの解説まで入れるのは焦点がボケますので、申しわけありませんが細かい解説は割愛します。「やる機会があったらちゃんと読む」程度にお留めおき下さい。
「やってみた」シナリオ
記事「Watson Discovery Serviceが日本語対応したので、触ってみた【やってみた】編」で英語環境で4つのサンブルHTML(内容はIBMのプレス・リリースの短縮版)文書をアップロードして検索しました。その環境をそのまま使います。(今回はNLUエンリッチメントの結果も使いたいので英語のCollectionを選択しました)
このWDSのコレクションをWEX/ABと統合して、プレスリリース記事のタイトルやメタデータをWEX/ABのウィジェットに表示してみます。
1. WDS上のコンテンツの準備
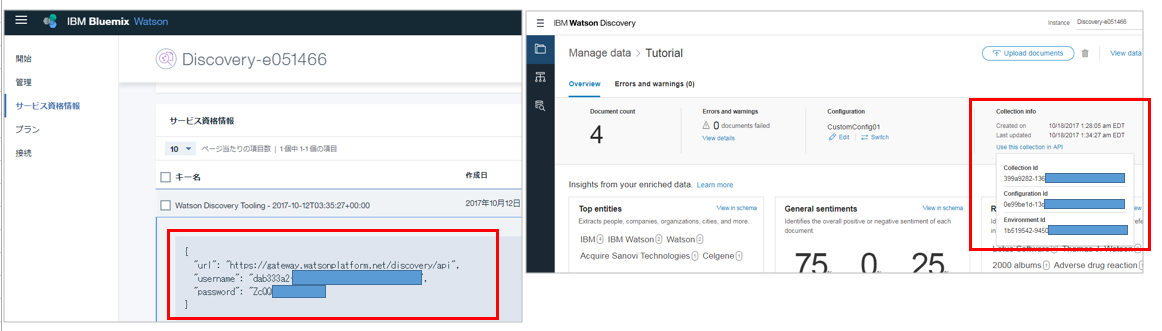
これは上の記事で済んでいるものとします。WEX/ABからWDSへアクセスするためにはWDSの以下の情報が必要です。各々、以下の画面からメモ/コピペしておきます。
① API Endpoint / ユーザーID / パスワード
② Environment ID と Collection ID
2. データソースの定義(WEX/AB)
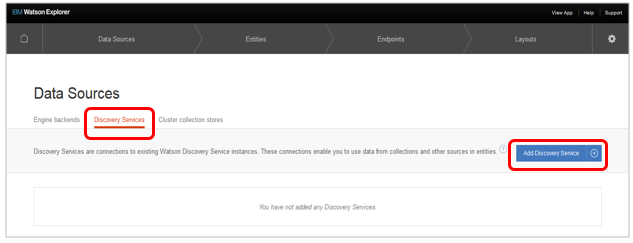
- ABの「DataSoures」-「Discovery Services」のタブで「Add Discovery Source」ボタン
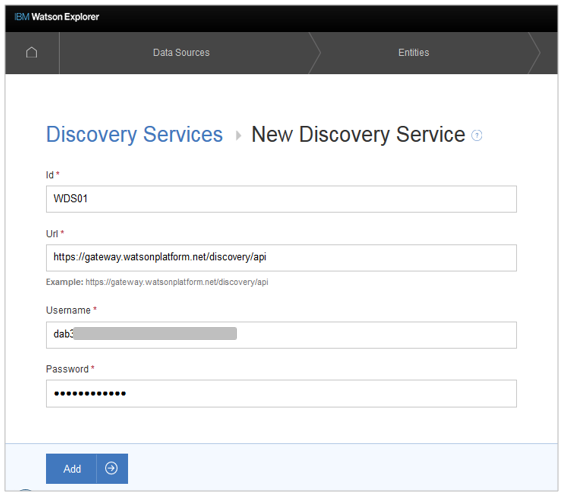
- IDは任意の名前
- Url/Username/PasswordはWDSの認証情報から
- 「Add」ボタン
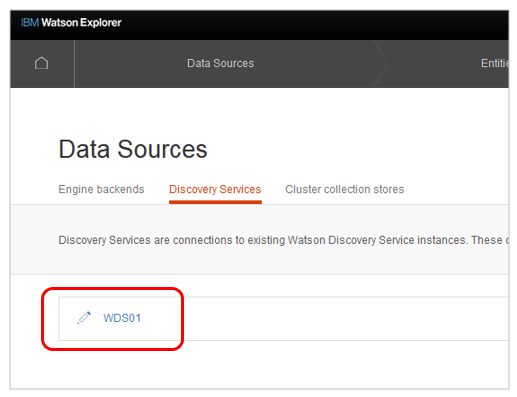
- WDSのサービスがバックエンドとして定義できました
3. 論理モデル(エンティティ)の定義(WEX/AB)
エンティティはWDSのCollectionに相当します。
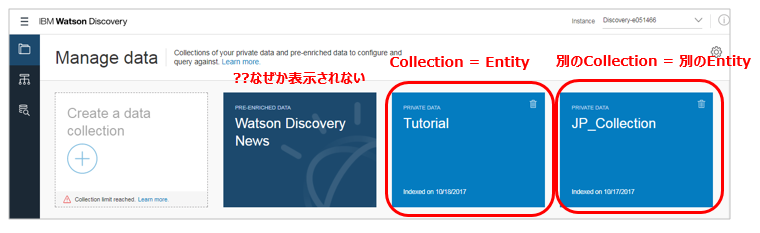
- WDSでは今、2つのCollectionを定義しています。今回は”Tutorial”を使います
Watson Discovery Newsはなぜかエンティティとして選択できません(聞いたら当件は認識してるそうなので、そのうち修正されると思います。まあ今は英語ニュースしかないので、利用する場面も限られると思いますが)
![]() (2017/12/05追記) 上記Discovery Newsが選択できない問題はWEX 11.0.2のFixpack 2で修正されたそうです。
(2017/12/05追記) 上記Discovery Newsが選択できない問題はWEX 11.0.2のFixpack 2で修正されたそうです。
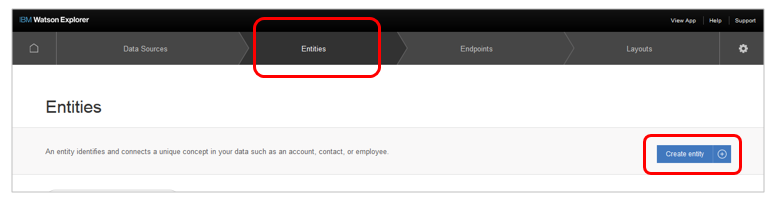
- ABの「Entity」タブで「Create entity」ボタン
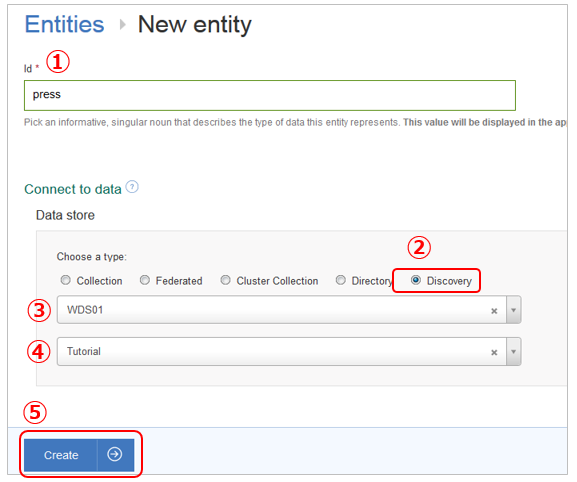
- ① お好きな名前を付けます
- ② 「Discovery」を選択
- ③ バックエンドは先程定義したWDS01を選択
- ④ リストボックスから「Tutorial」を選択(ここでなぜかNewsが選べません)
- ⑤ 「Create」ボタン
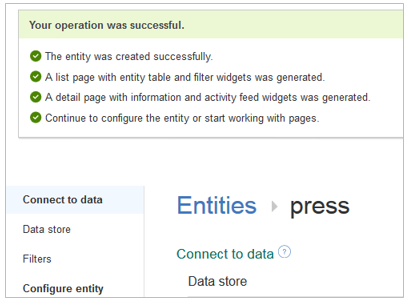
定義できました。他のエンティティとリレーション(アソシエーション)が必要なら更に追加定義しますが、今回は1つのCollectionだけにしますので、最低限のモデル定義はこれで完了です。
4. WEX/ABでJSONをどう扱うか?
![]() 【ココ、ややこしいけど重要です!】
【ココ、ややこしいけど重要です!】
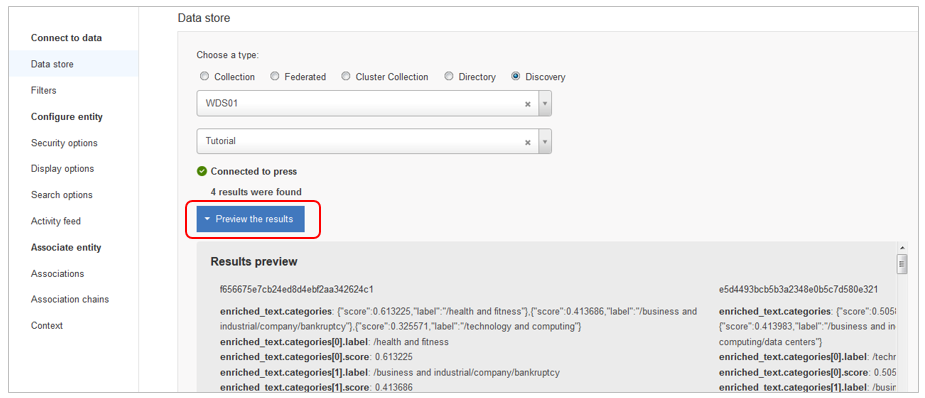
- Entity定義パネルで「Preview Results」ボタンを押します
- すると、WDS内に格納された文書と、そのJSON表現が見られます。(この表現はあとでフィールドを選択する時に重宝します)
ここで重要なポイントです。実はWEXのインデックス・レコードの構造はファイルでもDBでもフラットな構造(
=フィールド名の物差しを当てればフィールドの値が特定できる)が基本です。たとえば下記はWEXの通常のFast Indexの定義例ですが、JSONのようなフィールドの階層関係や繰り返しは表現できません。
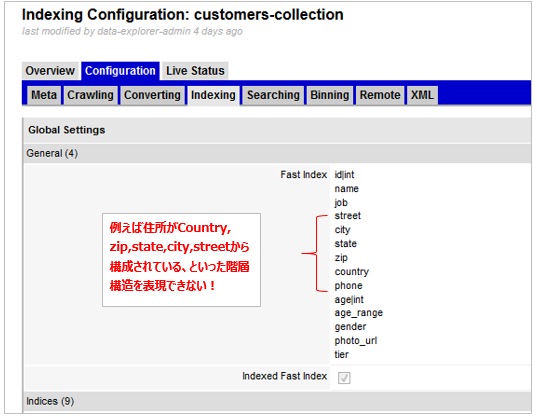
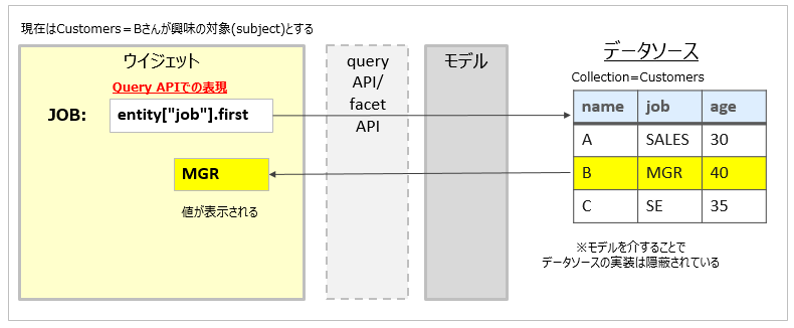
階層関係や繰り返しのあるデータは、取り込み時にConverterでレコードを分割するなどして事前に階層関係や繰り返しを解消しておく必要があります。ABではフラットな構造を前提にQueryAPIやFacetAPIという独自のAPI構文を使って(モデルを介して)レコードのフィールドにアクセスします。(例えば、現在選ばれたエンティティのjobフィールドの値を表示したければ、subject["job"].firstとか entity["job"].firstなどど表現します。)
しかし、WDSからの検索結果のレスポンスはJSONであり、データに階層関係や繰り返しがあります。これをABでどう扱い、どう値を抜き出せばよいでしょうか?
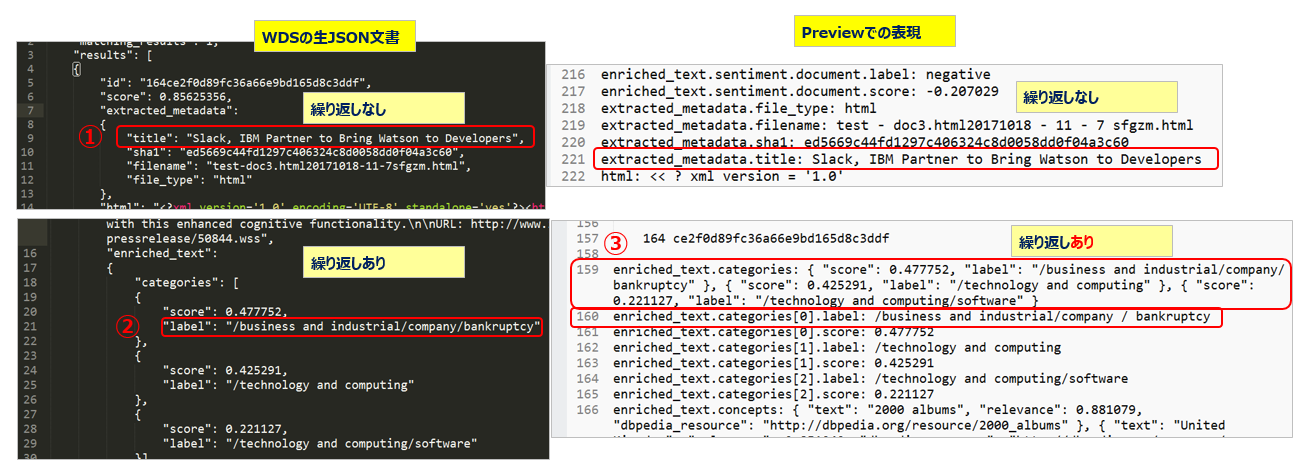
- 上記はWDSに格納された文書の例です。左側は生データのJSON、右側は同じ個所をEntitiyのPreviewで表示した際の内容を掲載しています
- WDSのレスポンスはJSONで普通に繰り返しや階層関係がありますが、実は右側のPreviewの表示は「このデータを取りたいんなら、ABではこう書けばいいよ!」と教えてくれている便利機能です。
- 例えば①の記事のタイトルの値を取りたいならフィールドの表現は extracted_metadata.titleとなります
- ②の繰り返し要素の1つ目のlabelの値を取りたいなら enriched_text.categories[0].label と書けばいいです
- しかし繰り返し回数が不定の場合に個々のフィールドの値を入手するにはどうすればいいでしょうか。そこで③のパターンになるのですが、ちょっと要注意です。もしQuery APIでenriched_text.categoriesと書いた場合は中に繰り返しを含む以下のようなJSONのARRAYが戻りますが、生憎、QueryAPIでJSONのARRAYはそのまま扱えません。(ので、ちょっとひと手間必要になりますが、簡単ですからご安心ください。後でご紹介します)
{ "score": 0.584786, "label": "/business and industrial/company/bankruptcy" },
{ "score": 0.437815, "label": "/society/dating" },
{ "score": 0.288638, "label": "/art and entertainment/movies and tv/comedies" }
要はWEX/ABでモデルを介してWDSのJSONデータを扱う際の基本的な考え方は下記です。
- 繰り返しが無い場合はQuery APIでA.B.Cという階層表現を使って直接フィールド値を入手できる
- 繰り返しがあっても「最初」など位置が決まっているならA.B[0].Cなどの表現で直接フィールド値を入手できる
- 繰り返しで回数が決められない場合はひと手間かければよい
5. WEX/ABの画面遷移と初期設定
WEX/ABの基本的な画面の遷移は以下のようになります。
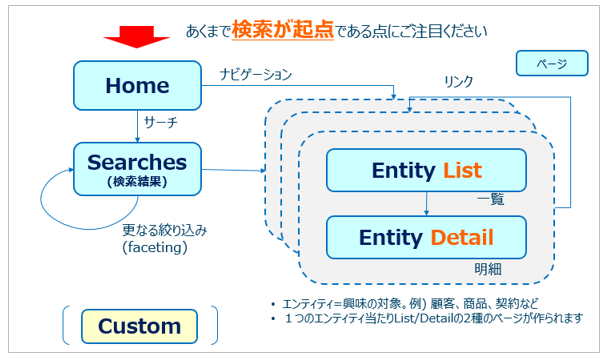
- HOMEパネルでの検索を起点に検索結果を絞り込んでいきます
- Entity Listは各文書の一覧表示、Entity Detailは特定の文書の明細を表示します。
ナビゲーションの設定
何かと便利なのでHome画面に「プレス記事」エンティティへのナビゲーションを設定しておきます。
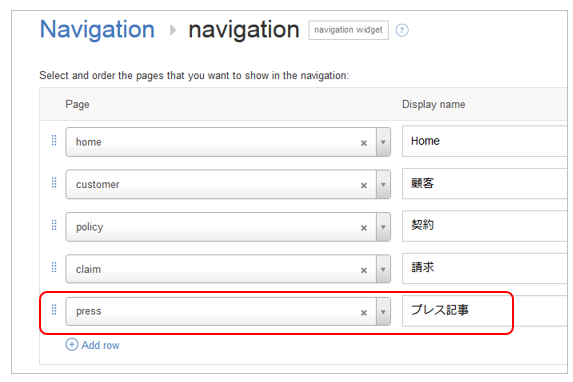
結果、検索のホーム画面にナビゲーションが表示されます。

プレス記事(エンティティ)一覧のタイトルの設定
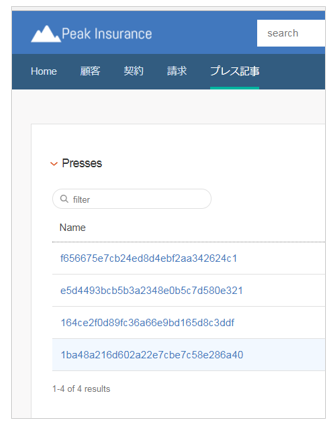
デフォルトだとWDSの文書のIDが表示されますが、意味がわかりません。プレスリリースのタイトルを表示するように変更します。(ここでPreviewが活用できます。Entityの「Display Options」のTitleを extracted_metadata.titleに設定します。
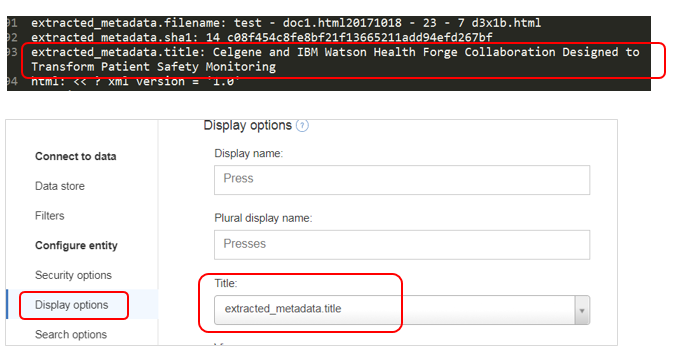
ここで今のうちにSearch Optionの「Searchable」をONにします。(デフォルトはOFF) これを漏らすと当該エンティティは検索の対象になりません。
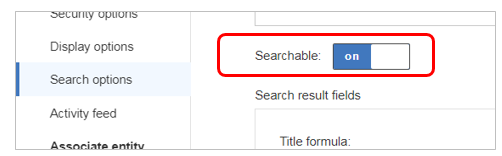
保存後、ブラウザーをリロードすると期待した通りになっています。
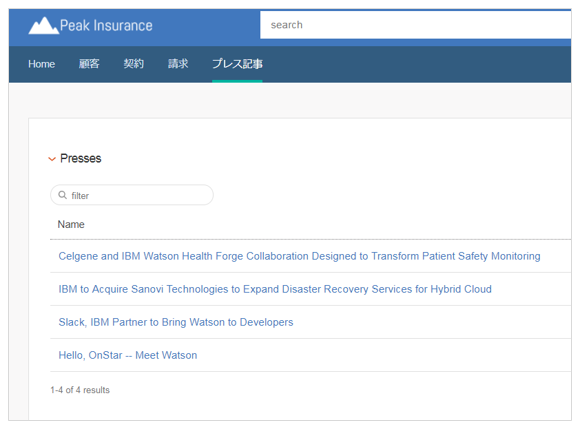
タイトルはリンクになっており、クリックすると明細(Entity_Details)ページ表示されます。ただし今はタイトル以外は何も表示されません。
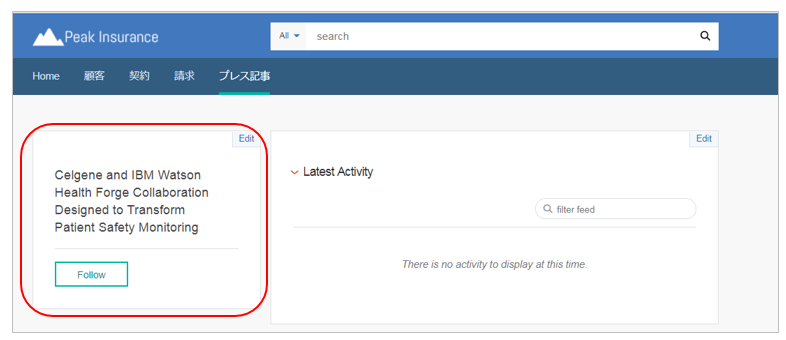
6. ウィジェットの作成(WEX/AB)
ウイジェットとは画面内の表示枠(ポートレット)です。ウイジェットにデータを表示する場合はQueryAPIの形式で表示したいフィールドを指定すれば、自動的にモデルを介してデータが取得され、表示されます。表示形式の変換など行いたい場合はRubyの構文で行えます。
プレス記事一覧(Entity List)の設定
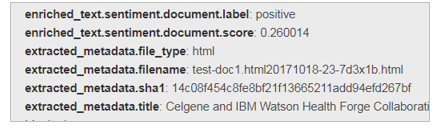
一覧にタイトル以外も表示させます。ここは1行=1文書に該当するので、1文書で複数回繰り返すようなフィールドを表示するのは向いていません。Previewを見て、センチメントとスコア、ファイル名を表示させることにします。
- 一覧のウイジェットの右上「Edit」ボタンでEntityListの編集パネルを開きます
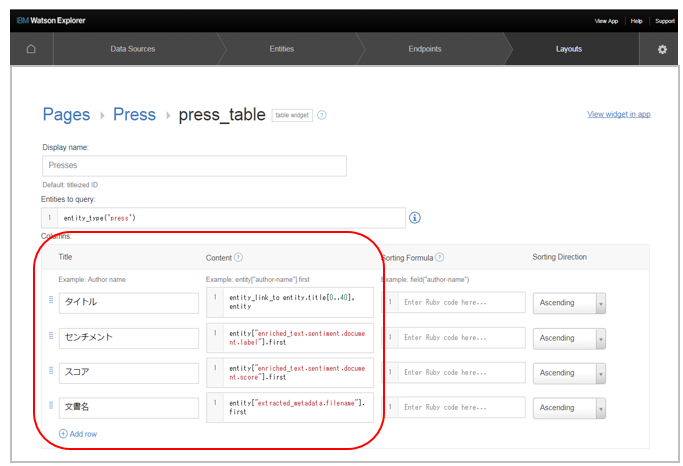
- columnsでAdd Rowして、以下を指定します(ここでもさっきの「Preview」でデータを見ながら書くべきJSON表現を調べられます)
| Title | Content |
|---|---|
| タイトル | entity_link_to entity.title[0..40], entity |
| センチメント | entity["enriched_text.sentiment.document.label"].first |
| スコア | entity["enriched_text.sentiment.document.score"].first |
| 文書名 | entity["extracted_metadata.filename"].first |
※ContentはRubyコードとして評価されます。タイトルが長いので40バイトで切り捨てました
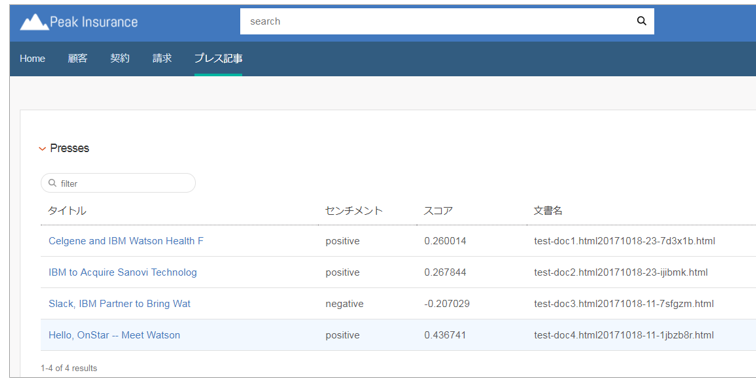
- 画面をリロードすると期待通りの形で表示されました。
これで一覧は完成です。 WDSのAPIを一切意識せずに簡単にデータが取得できました !
プレス記事の明細(Entity Details)の設定
一覧から任意の記事を選択して明細画面を表示します。次にウイジェット右上の「Edit」ボタンで編集画面を表示します。
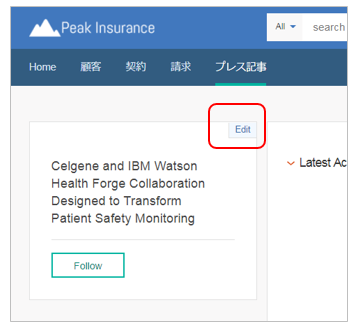
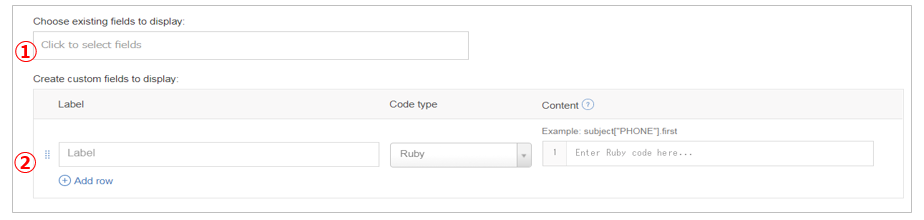
- ここではプレス記事の文書のうち、ウィジェットに表示したいフィールドを設定します
- 単にそのまま表示するだけなら①のリストボックスから選択するのが簡単です
- しかし「不定回の繰り返し」のあるフィールドは②の方でerbのカスタムコードで簡単なロジックを書きます。(「お作法」的な決まりきったコードです)
- ご参考までに、繰り返しのあるフィールドを無理に①に指定するとjsonがそのまま表示されてしまいます。(下記参照)
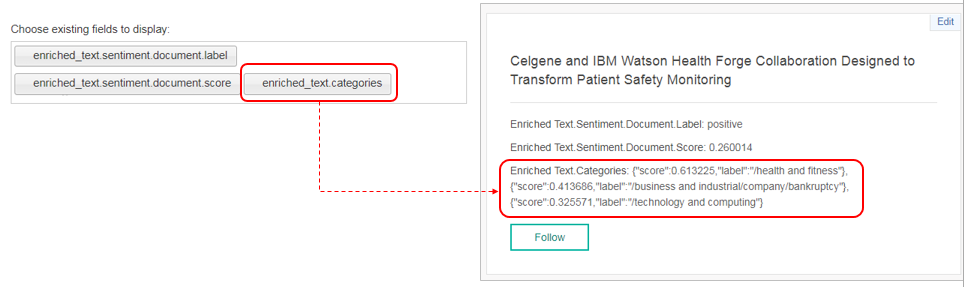
- 不定回の繰り返しのあるフィールドは以下のようにERBのロジックでループして処理します。これはABでは「定石」のパターンです。①と②は同じことを違う書き方で書いています。
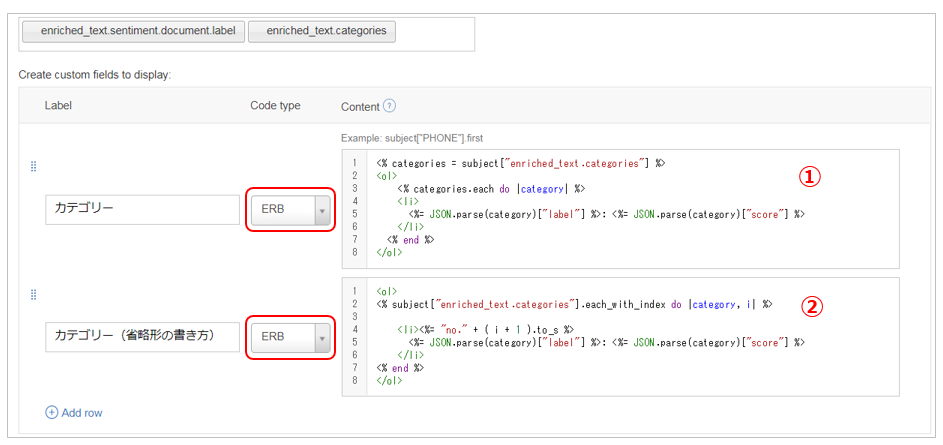
①の書き方
enriched_text.categoriesを一旦 categoriesという変数に配列で格納します。次にループ中で配列の各要素をJSON.parseでJSONに変換し、そのキーから値(バリュー)を入手しています。それらをHTMLのリストタグで挟みます。
<% categories = subject["enriched_text.categories"] %>
<ol>
<% categories.each do |category| %>
<li>
<%= JSON.parse(category)["label"] %>: <%= JSON.parse(category)["score"] %>
</li>
<% end %>
</ol>
②の書き方
ほぼ①の書き方と同じですが、若干行数が少なくなってます。要はここはERBとして評価されるので、その範囲でならどんな書き方をしてもいい、ということです。(①と②でolタグの位置が違うことにご注意ください)
<ol>
<% subject["enriched_text.categories"].each_with_index do |category, i| %>
<li><%= "no." + ( i + 1 ).to_s %>
<%= JSON.parse(category)["label"] %>: <%= JSON.parse(category)["score"] %>
</li>
<% end %>
</ol>
上記を表示すると以下のようになります。
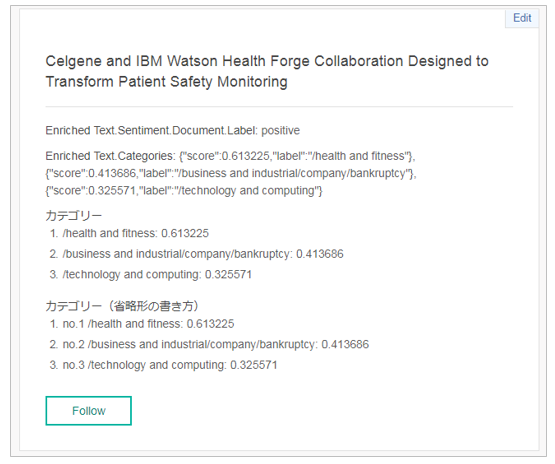
これで繰り返しのない場合、ある場合の両方の書き方がわかりました。あとはPreviewを見ながらWDSの文書中で表示したいフィールドを適宜選択して同じように書けばいいだけです。割と簡単ですよね?
7. 検索してみる(WEX/AB)
全文検索
これでプレス記事のエンティティの一覧と明細の定義ができたので早速検索してみます。HOMEで「IBM」を検索します。
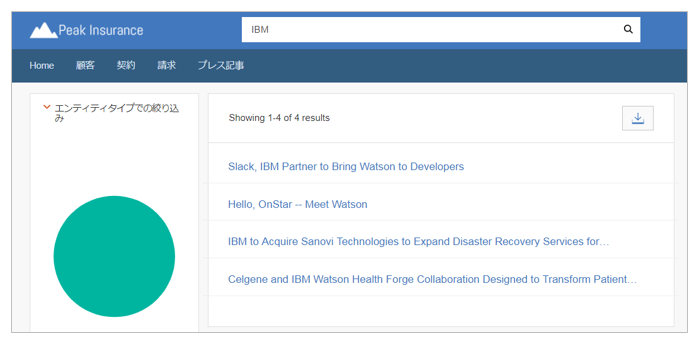
- 結果、4件=全文書がヒットしました。文書はIBMのプレス記事が元なので当然といえば当然ですが、実際の文書には本文やエンリッチ結果など色々なフィールドがあります。普通のキーワード検索では「いずかのフィールドにIBMという文字があればヒット」とみなしていることがわかります。
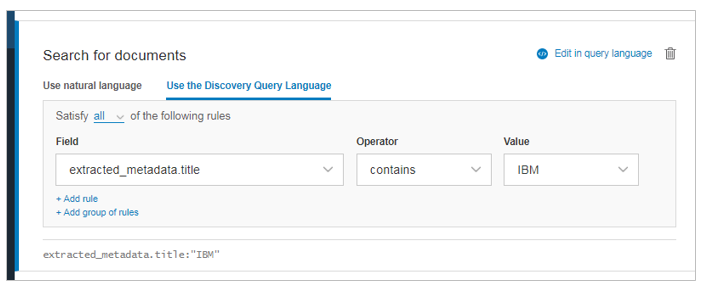
対象フィールドを指定した検索
WEXおよびWDSでは「フィールド名:値」の形式で検索対象のフィールド範囲を限定できます。ためしに「タイトルにIBMを含む」文書を検索します。検索キーワードとしては「extracted_metadata.title:IBM」です。
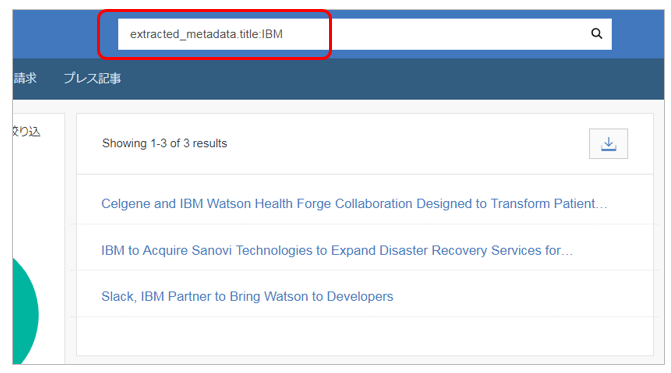
- 今度は3件になりました。対象フィールドの限定がうまく効いていることがわかります。
WEX/ABではDQLを利用
WDSの照会の構文は以下の2種類がありますがWEX/ABではDQLを使っているようです。
| 種類 | Query Collectionのquery=パラメーター |
|---|---|
| Discovery Query Language | query= |
| Natural Language Query | natural_language_query= |
WEX/ABがWDSに対し実際にどのようなREST要求を投げているか、はログ /opt/ibm/WEX/AppBuilder/wlp/usr/servers/AppBuilder/logs/messages.logなどをみるとわかります。以下は例。
[10/20/17 0:18:58:125 JST] 000001b7 okhttp3.OkHttpClient I --> GET https://gateway.watsonplatform.net/discovery/api/v1/environments/1b519542-9450-4316-ac21-xxxxxxxxxxxx/collections/xxxxxxxx-136a-490d-ac5f-yyyyyyyyyyyy/query?query=IBM&aggregation=[term(cxo.entity_title),term(country).term(state).term(city)]&count=10&offset=0&return=_id&version=2016-12-01 http/1.1
[10/20/17 0:18:58:741 JST] 000001b7 okhttp3.OkHttpClient I <-- 200 OK https://gateway.watsonplatform.net/discovery/api/v1/environments/1b519542-9450-4316-ac21-xxxxxxxxxxxx/collections/xxxxxxxx-136a-490d-ac5f-yyyyyyyyyyyy/query?query=IBM&aggregation=[term(cxo.entity_title),term(country).term(state).term(city)]&count=10&offset=0&return=_id&version=2016-12-01 (615ms, unknown-length body)
6. エンドポイントの利用(WEX/AB)
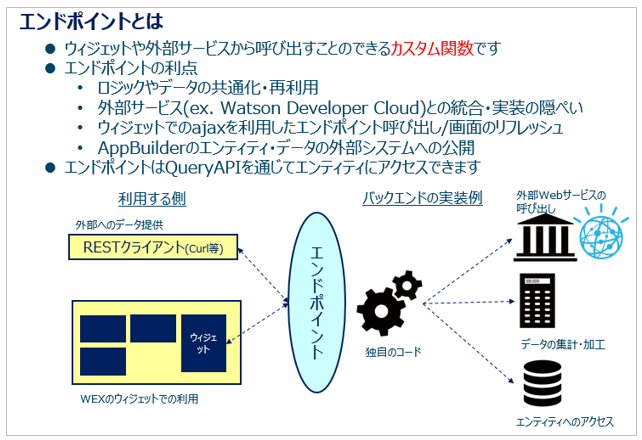
ABでのエンドポイントとは、要は様々なウィジェットから「共通で呼び出せるカスタム関数」で、Rubyで実装します。業務的な計算や形式の変換、外部WEBサービスの呼び出しなど様々な用途があります。
今回はプレス記事の明細画面向けにDiscoveryに対して特定の1文書を要求する処理をエンドポイントで実装してみます。(既に6. ウィジェットの作成(WEX/AB)で見たように、同じことをもっと簡単にできるので、このユースケースではあまり意味はありませんが、まあ技術的なご紹介ってことで)
大きくは
①エンドポイントを作る
②ウイジェットでエンドポイントを使う
の2段階になります。
①エンドポイントを作る

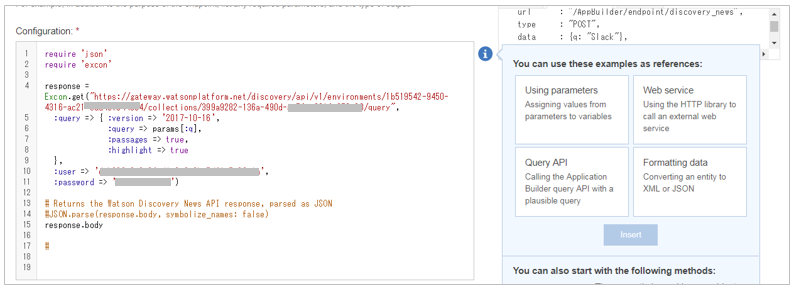
- こんな感じでrubyのコードを書きます。Discoveryのquery search collectionのAPIを自分で呼び出します。検索のキーワードは外部からパラメーターで受け取ります。
require 'json'
require 'excon'
# Request with latest API version/ passages / highlight
response = Excon.get("https://gateway.watsonplatform.net/discovery/api/v1/environments/1b519542-9450-4316-ac21-xxxxxxxxxxxx/collections/xxxxxxxx-136a-490d-xxxxxxxxxxxx/query",
:query => { :version => '2017-10-16',
:query => params[:q],
:passages => true,
:highlight => true
},
:user => 'xxxxxxxx-0a6f-41a9-9e6b-xxxxxxxxxxxx',
:password => 'xxxxxxxxxxxx')
# Returns the Watson Discovery News API response, parsed as JSON
response.body
#
ちなみに同画面でエンドポイントをテストすることもできます。
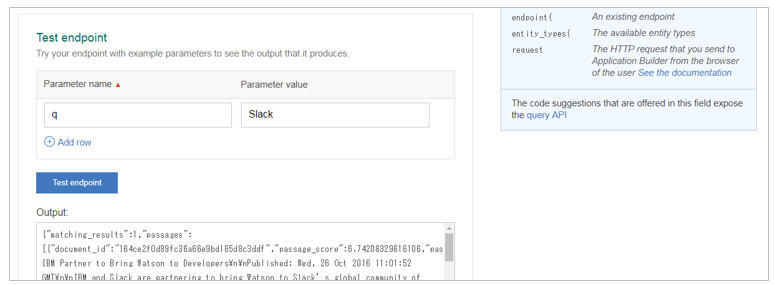
きちんとDiscoveryから結果が返れば成功です。保存します。
②ウイジェットでエンドポイントを使う
Entity_DetailsのウイジェットでERBの中からエンドポイントを呼び出します。
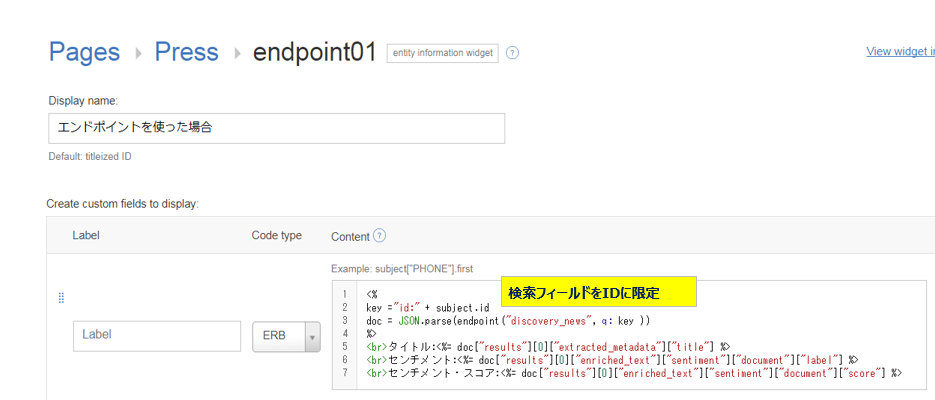
- Entity_Detailsページでは選択された文書(のキーのようなもの)がsubjectとして設定されているので、subject.idで文書のidを入手します
- Discoveryに照会を投げる際は、結果を一意にするために**id:**xxxxxxxxと検索対象のフィールドを文書idのみに限定しています。
- エンドポイントを呼び出してレスポンスをJSONに変換したら、あとはHTML+erbで自由にデータをウイジェット上に表示できます
<%
key ="id:" + subject.id
doc = JSON.parse(endpoint("discovery_news", q: key ))
%>
<br>タイトル:<%= doc["results"][0]["extracted_metadata"]["title"] %>
<br>センチメント:<%= doc["results"][0]["enriched_text"]["sentiment"]["document"]["label"] %>
<br>センチメント・スコア:<%= doc["results"][0]["enriched_text"]["sentiment"]["document"]["score"] %>
結果、以下のように表示されました
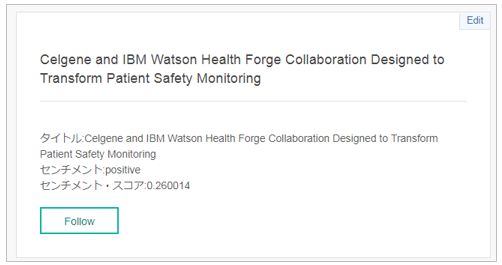
- ちなみに、ABのエンドポイントは上記のように「自分でREST要求を出す」ので、他のWatsonサービスでも世間一般のWebサービスでも、なんでも呼び出して結果を入手/表示できます
以上です。(しつこいですが、ニッチな話題ですいませんでした)