はじめに
Power BIのデータモデルでは、CS(Case Sensitivity)にしたくてもできません。大文字・小文字を区別しないのです。一方、Power Queryでは大文字・小文字を区別します。
こういった特性をふまえて、大文字・小文字を区別したい、区別せずにPower Queryで整理したいなどやりたい場合があるかと考えます。これらのCS話について、発生する注意点やリファレンス、関連ブログ等を交えて整理します。
Power BIのモデルではCSしない
関連のドキュメントはこちらです。
⚠️注意
Power BI モデルでは、現在、大文字と小文字を区別しない (またはひらがなとカタカナを区別しない) ロケールが使用されているため、"ABC" と "abc" は同等に扱われます。 "ABC" が最初にデータベースに読み込まれた場合、"Abc" のように大文字と小文字だけが異なる他の文字列は、別の値として読み込まれません。
「"ABC" と "abc" は同等に扱われます」「ABC" が最初にデータベースに読み込まれた場合、... 別の値として読み込まれません。」あたりが少しわかりにくいでしょうか。
要は最初に読み込まれた文字列の大文字・小文字に、2つめ以降の文字列は揃えられるという動きになります。
Power QueryではCSする
関連のドキュメントはこちらです。
⚠️注意
Power Query では大文字と小文字が区別されます。 重複する値を処理するときに、Power Query では、テキストの大文字と小文字が考慮されるため、望ましくない結果になる可能性があります。 回避策として、ユーザーは重複を削除する前に大文字または小文字の変換を適用できます。
例題でみていきましょう データモデルから
元データは下記のようなシンプルな2行のデータとします。
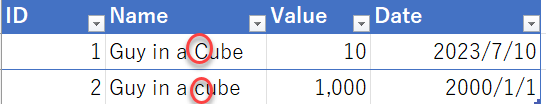
Power BIに読み込むプレビューの段階では元データのままですが
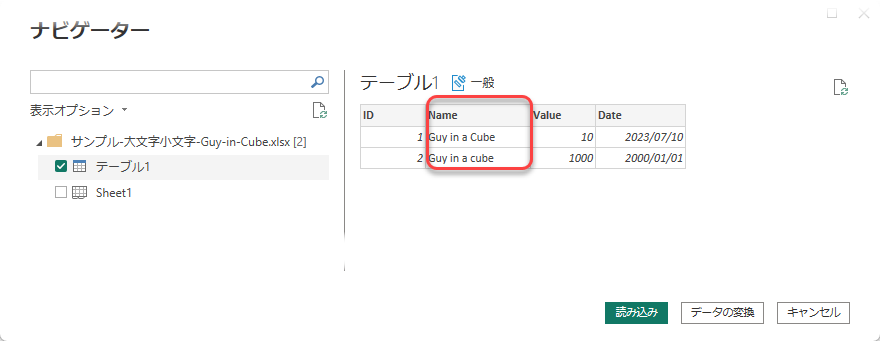
データビューでみると以下のようになります。
ID1のGuy in a Cubeに、ID2も揃えられる、ということです。
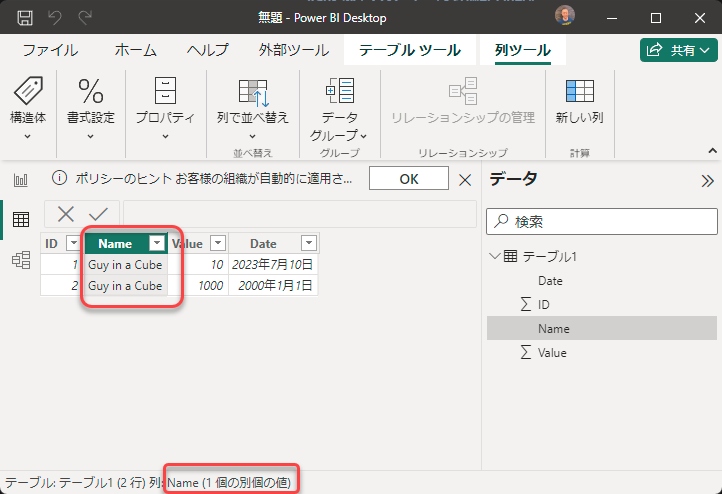
ステータスバーを見ると「1個の別個の値」となっています。
最初に読み込んだ表記に合わせられた1個の値になった、ということです。
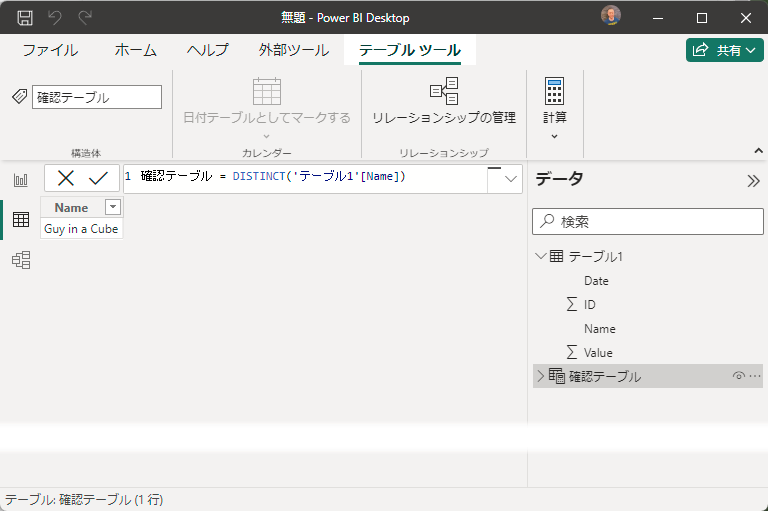
念のための確認で、新しいテーブルで、Name列でDistinctしても一意になっています。
Japan CSS Support Power BI Blogの記事でも例示が参考になります。
例題をPower Queryで「重複の削除」しても名寄せできない
例題では2行のごく簡単な例ですが、大文字・小文字が混じっているカラムがより多く混じっている場合で、ディメンションテーブルを意図する文字列にしたい、という場合はどうすればよいでしょうか。
まずは、単純に「重複の削除」してみます。
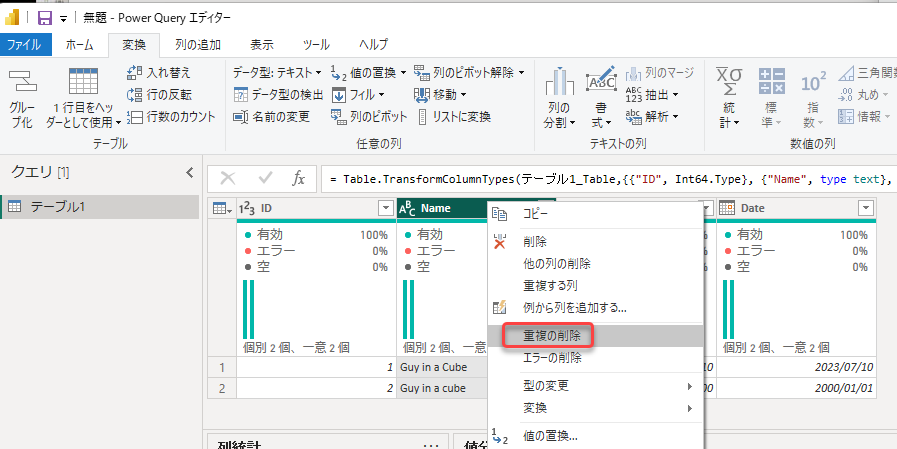
Power Queryでは大文字・小文字を区別しますので、重複の削除、Table.Distinctを実行しても結果は変わりません。
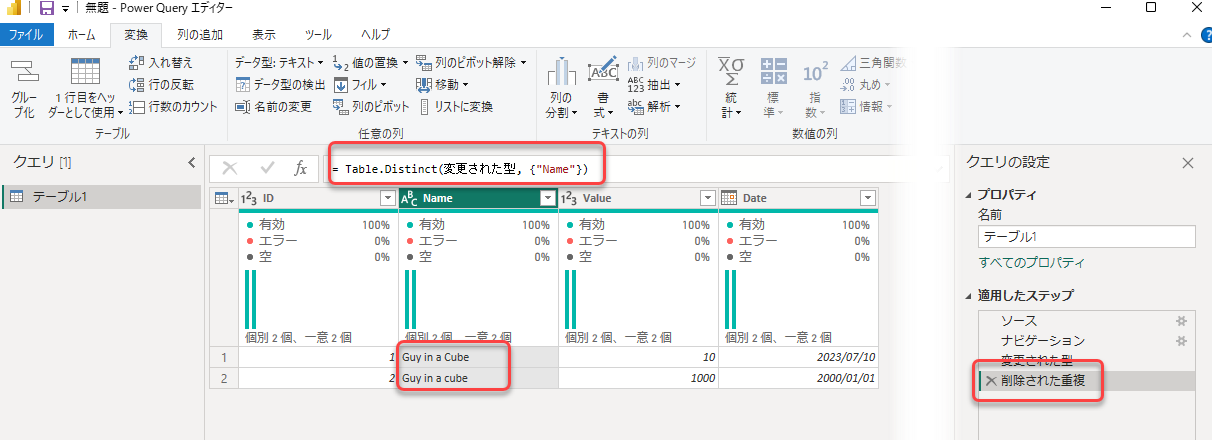
Power Queryの段階で名寄せするには
今の例のCubeやcubeが混じっているのは表記揺れだ、ディメンションテーブルのような一意な項目を作りたい、大文字・小文字を区別したくない、という場合はどうすればよいでしょうか?
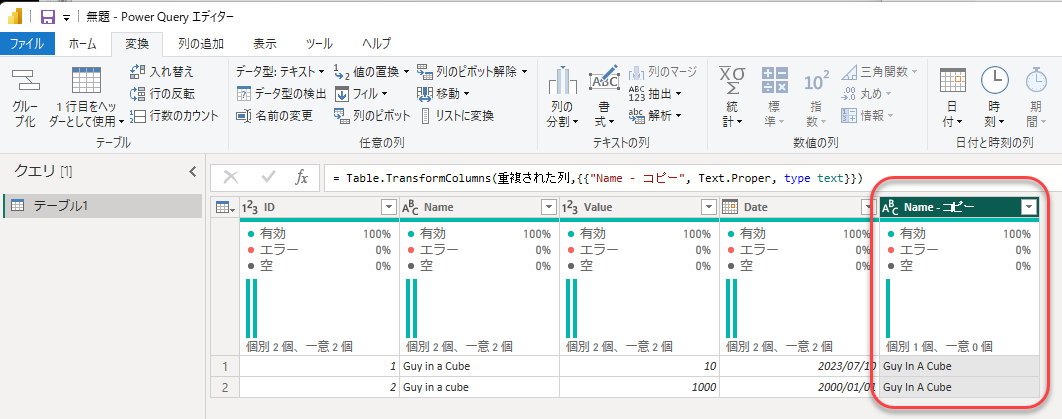
一例を示します。まずは、大文字、小文字を同じルールで統一した列を作ります。
まずはName列の重複した列を作ります。
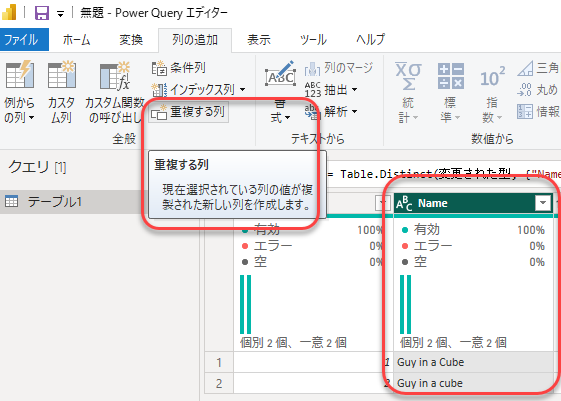
各単語の先頭文字を大文字にします(全部大文字、全部小文字でもOKですかね)
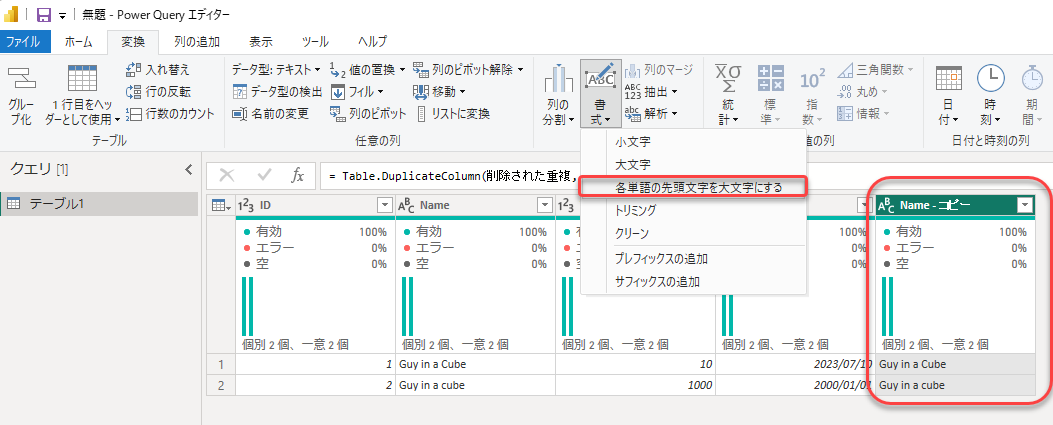
結果は以下のように同じ文字にそろいました。
Power Queryのグループ化を活用しよう
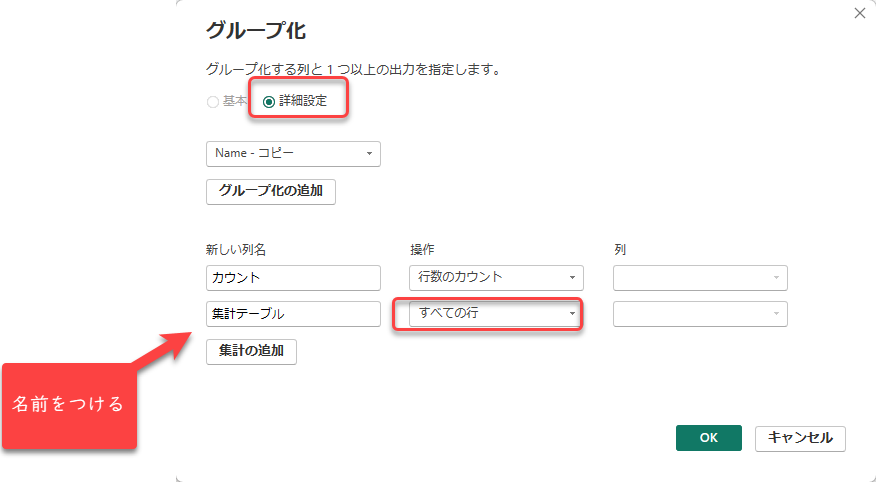
これで、Name-コピー列でグループ化することができ、その行の中で特定の列のルールを持って、絞ることにします。
まずは、Date列が最新である、ID1の表記に合わすことにしたとしましょう。
グループ化のドキュメントはこちらです。
「1 つ以上の列でグループ化する操作を実行する」をまずは行います。
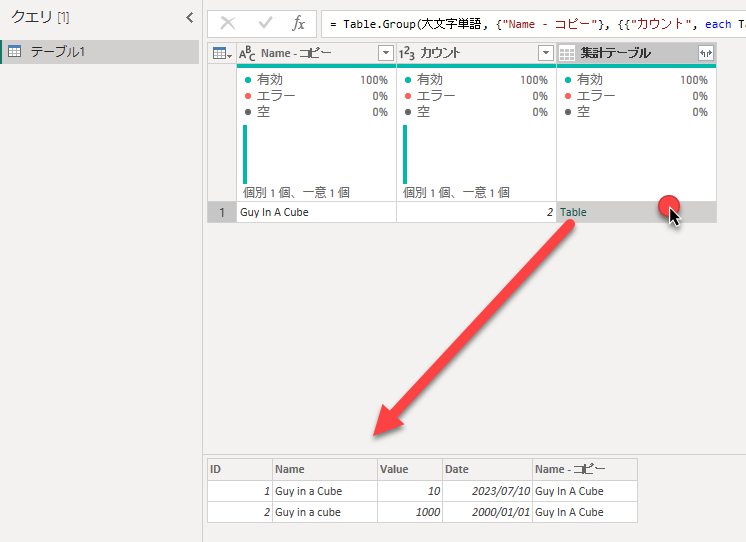
集計テーブル列のTableの空きスペースをクリックすると下部にグループ化された中身が見られます。
次はドキュメントの「最も売れている製品の情報を抽出する」の要領で、カスタム列を追加し、最新の日付のデータを取り出します。
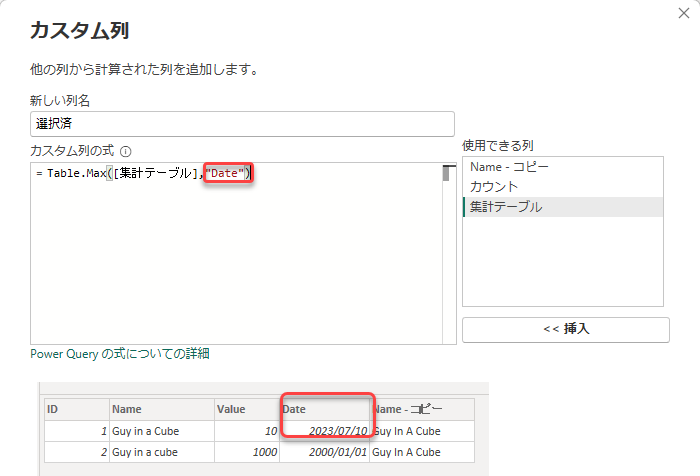
実行後の選択済列の中身を見ると、ID1が選ばれたことがわかります。
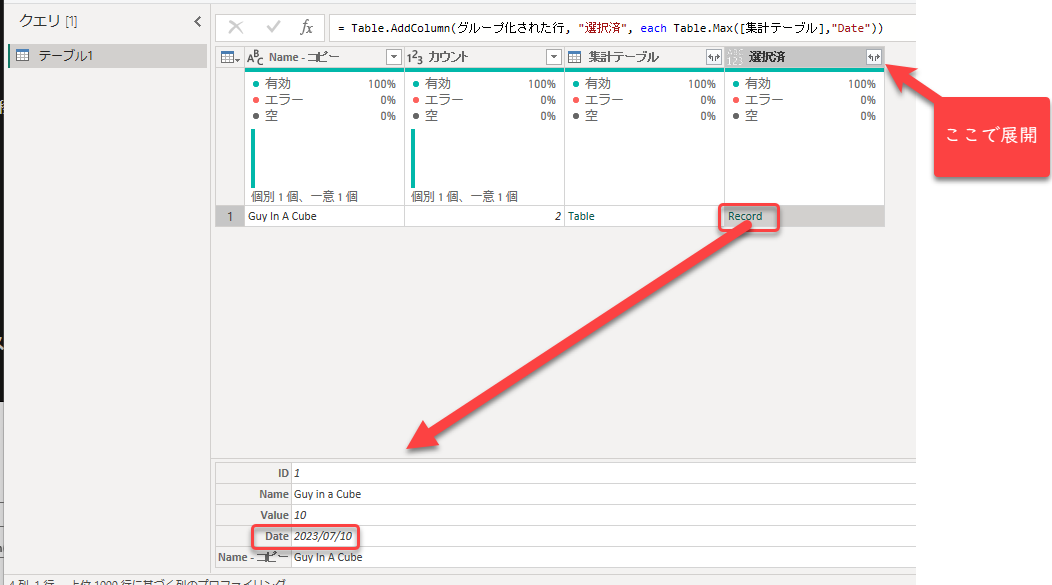
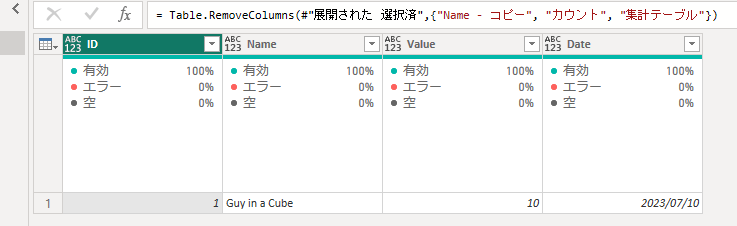
列を展開して、不要な列を削除すると以下の結果を得ることができます。
もし、ID2のcubeが小文字を選択したく、そのルールをValueがMaxなもの、としたい場合
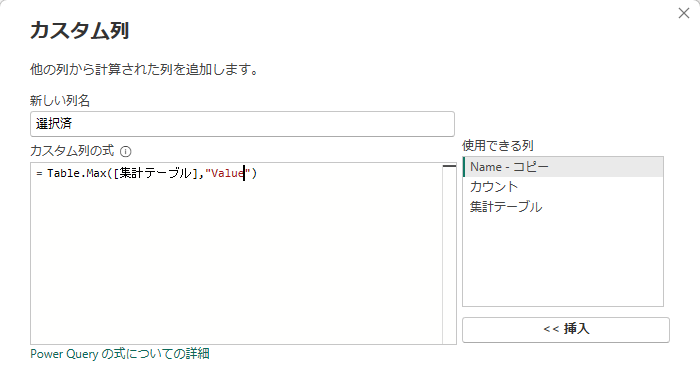
と変更することにより
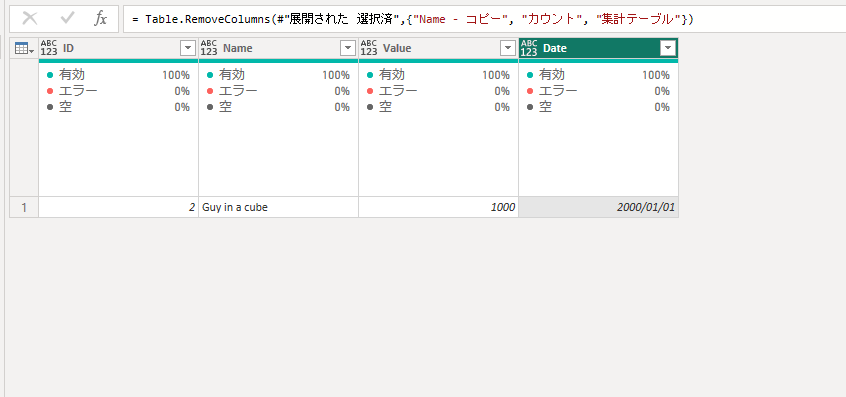
こちらの結果が得られます。Table.Maxのところは、Talbe.Min他その他のルールで置き換えなど適時応用可能かと考えます。
(補足)Table.GroupでComparer.OrdinalIgnoreCase オプションの活用
@PowerBIxyz さんにコメントで教わりました)。上記のようにName列のコピーを作り、大文字・小文字をそろえなくても、Name列自体でグループ化するときに、大文字・小文字関係なくグループ化することが、Table.Groupの最後のオプションにあります。Comparer.OrdinalIgnoreCaseです。
Table.Group(削除された重複, {"Name"}, {{"集約行テーブル", each _, type table [ID=nullable number, Name=nullable text, Value=nullable number, Date=nullable date]}},null,Comparer.OrdinalIgnoreCase)
Name列でグループ化できました。
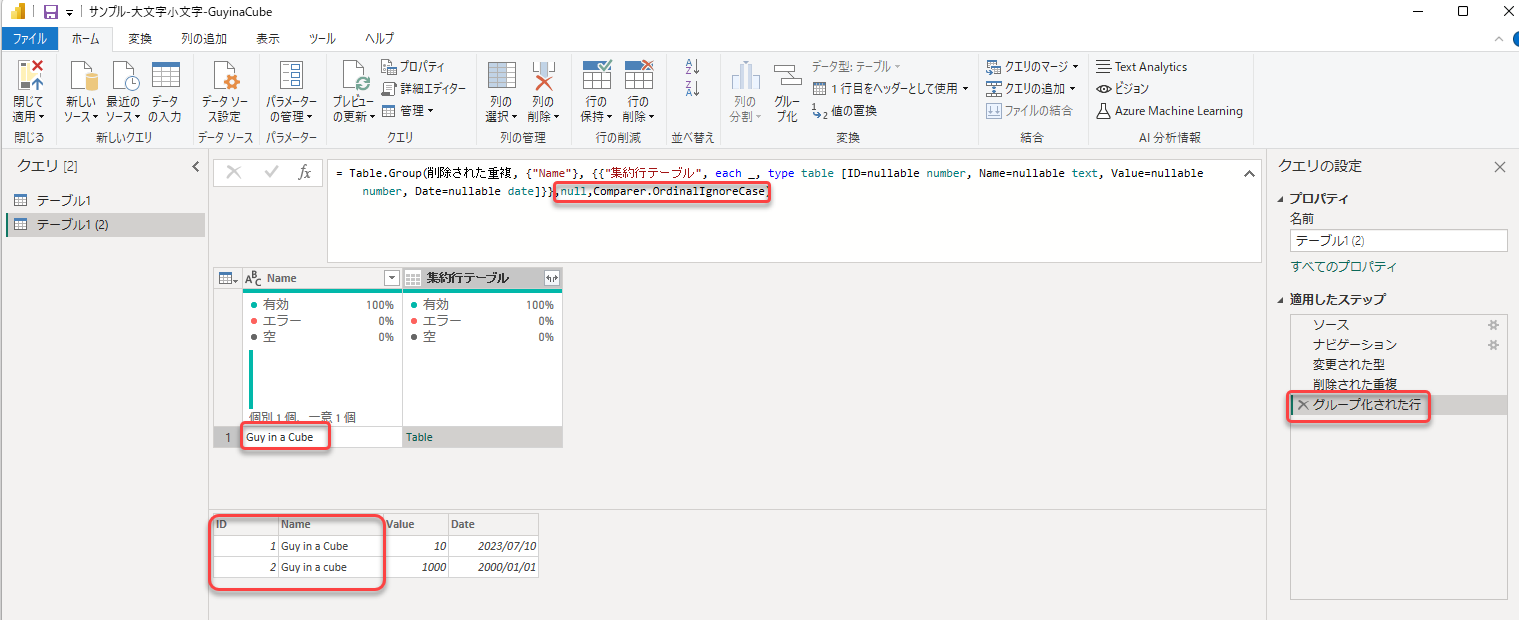
こちらのほうがステップがすっきりと減りますね。
@PowerBIxyz さん、ご指摘いただきありがとうございます(いつも感謝しております)。
データモデルで大文字・小文字を区別したい例
ゼロ幅スペースを足す対応案が従前のブログで紹介されています。
@PowerBIxyz さんのブログでは、ゼロ幅スペースをID数分足して、ユニークにする方法が、
Japan CSS Support Power BI Blog では、小文字だったらゼロ幅スペースを足す方法が
あります。どうしても大文字・小文字を区別したいんだ、という時は参考にされるとよいでしょう。
おわりに
メモを残さないと、自分でもわからなくなりやすい、ということで書きました。製品知識を正しく理解することは大事ですね。