この記事は以下のblog記事を機械翻訳したものです。
https://blog.langchain.com/introducing-open-swe-an-open-source-asynchronous-coding-agent/
Introducing Open SWE: An Open-Source Asynchronous Coding Agent
過去2年間で、ソフトウェアエンジニアリングにおけるAIの利用は進化してきました。最初はオートコンプリート、次にIDEの共同作業者となり、ここ数か月で、クラウドで非同期に実行される、よりエンドツーエンドの長期実行エージェントへと進化しました。
私たちは、将来的にはすべてのエージェントがこのような長期実行型、非同期型、より自律的なものになるだろうと考えています。具体的には、次のようになると考えています。
- クラウドで非同期に実行される
- ツールと直接統合される
- 長期的な時間軸でタスクを適切に計画するための十分なコンテキストを持つ
- タスクを完了する前に、自分の作業をレビューし(問題があれば修正する)
ここ数か月で、ソフトウェアエンジニアリングがこのビジョンが最初に現実になる分野であることが明らかになりました。しかし、これらの特徴を捉えるオープンソースプロジェクトはありませんでした。
そこで、私たちはOpen SWEを構築しました。これは、最初のオープンソースの非同期クラウドホスト型コーディングエージェントです。Open SWEは、GitHubリポジトリに直接接続し、GitHubのイシューやカスタムUIからタスクを委任できます。Open SWEは、チームの別のエンジニアのように動作します。コードベースを調査し、詳細な実行計画を作成し、コードを書き、テストを実行し、自分の作業をエラーがないかレビューし、完了したらプルリクエストを開きます。

Open SWEのLangGraphリポジトリへの貢献
私たちは、LangGraphなどのプロジェクトにおける独自の開発を加速するために、社内で使用しています。Open SWEリポジトリ自体でも、すでにトップコントリビューターとなっています。
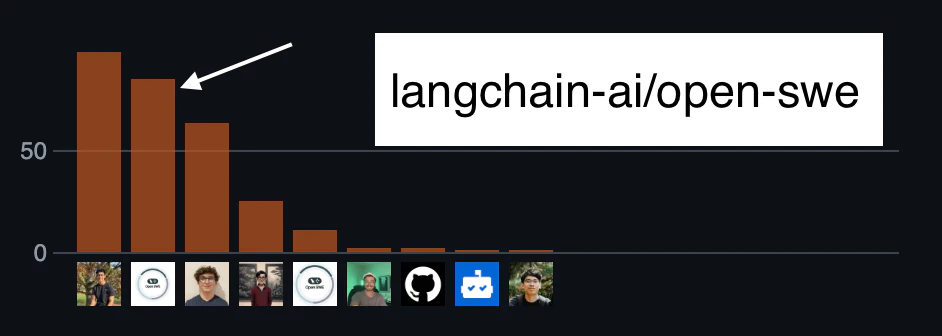
Open SWEの自身のリポジトリへの貢献
本日、コミュニティに共有できることを嬉しく思います。
使い方
ホスト版のOpen SWEを数分で開始できます。必要なのはAnthropic APIキーだけです。
- swe.langchain.comにアクセスします。
- GitHubアカウントに接続し、Open SWEがアクセスできるリポジトリを選択します。
- 設定にAnthropic APIキーを入力します。
- 新しいタスクを開始し、その進行状況を観察します!

Open SWEホームページ
始めるための場所を探している場合は、ドキュメントのexamplesページをご覧ください。
なぜOpen SWEなのか?
多くのオープンソースコーディングプロジェクトが存在します。なぜ新しいものを構築したのでしょうか?私たちは、プロンプトや使用するツールだけでなく、他の側面にも注目を集めたいと考えていました。具体的には、信頼できる方法でそれらとやり取りできるようにするために必要な全体的なフローとUXを強調したかったのです。
UI/UXは、エージェント構築において最も探求されていない分野の1つであると考えています。アプリケーションの全体的なインタラクションパターンは、その使用状況を大きく左右します。非同期エージェントという新しいアイデアを考えると、ここで探求する価値のある多くの興味深いパターンがあると思います。2つの主なポイントは、より多くの制御と深い統合です。
制御: Open SWEには、実行中にコーディングエージェントに対する制御を強化する2つの主な機能があります。作業をレビューしたり、再起動せずに軌道に戻したりするために介入できます。
- Human in the loop(人間介入): Open SWEが計画を生成すると、中断し、計画を承認、編集、削除、または変更を要求する機会を与えます。何か見落としていますか?掘り下げ続けるように指示するだけで、タスクの計画プロセスを再開します。
- Double texting(ダブルテキスト): ほとんどのコーディングエージェントは、実行中に新しいリクエストやフィードバックを受け入れません。Open SWEはその制約に悩まされることはありません。製品仕様を変更したり、新しい機能を追加したり、軌道から外れたりした場合でも、メッセージを送信するだけで、それをアクティブセッションにスムーズに統合します。
深く統合: Open SWEは、GitHubアカウントとリポジトリに直接統合されているため、他の開発者と同じようにタスクを割り当て、コードのコンテキストを与えることができます。開発者はすでにGitHubで生活しているため、新しい製品を学ぶ必要はありません。Open SWEでは、新しいタスクごとに追跡イシューが与えられます。このイシューは、セッション全体を通してステータスアップデート、実行計画などで更新されます。タスクが完了すると、プルリクエストが自動的に開かれ、追跡イシューにリンクされます。
また、GitHubから直接実行をトリガーすることもできます。
- (例:
open-swe-auto)というラベルをGitHubイシューに追加するだけで、Open SWEが作業を開始します。完了すると、プルリクエストが開かれ、レビューの準備が整います。既存のプロセスに適合し、人間のチームメンバーのように動作します。
これらの2つの主要な柱に加えて、人間とOpen SWEのインタラクションパターンではなく、Open SWEがどのように実行され、どのように機能するかに焦点を当てている他の2つのコンポーネントに焦点を当てました。
- 隔離されたサンドボックスで実行: すべてのタスクは、安全な隔離されたDaytonaサンドボックスで実行されます。各Open SWEセッションに独自のサンドボックスが与えられるため、悪意のあるコマンドを心配する必要はなく、Open SWEが望む任意のシェルコマンドを実行できます。これにより、すべてのコマンドに対して人間の承認を必要とせずに、より迅速に進むことができます。
- クラウドで非同期に実行: クラウドネイティブアーキテクチャにより、Open SWEはローカルリソースを消費することなく、複数のタスクを並行して実行できます。午前中にタスクのリストを割り当てて、午後にPRのセットに戻ってくることができます。
- コミットする前に計画とレビュー: 多くのエージェントは、すぐにコードに飛び込み、CIパイプラインを壊す間違いにつながることがよくあります。Open SWEは、PlannerとReviewerという専用のコンポーネントを備えたマルチエージェントアーキテクチャを使用します。まず、プランナーはコードベースを調査して堅牢な戦略を立てます。コードが書かれたら、Reviewerは生成されたコードを品質、正確性、完全性の観点からチェックし、PRを開く前に問題を修正します。これにより、より効果的に実行可能なコードを書き、レビューサイクルを減らすことができることがわかりました。
考慮事項: Open SWEは、複雑で長期実行のタスクに適しています。ただし、小さなワンライナーのバグ修正や簡単なスタイル更新の場合、このアーキテクチャは最適ではありません。このようなタスクでは、エージェントは計画とレビューの段階をスキップして、すぐに実行できる必要があります。現在、まさにそのようなバージョンを実装しています。これはローカルでCLI経由で実行され、よりエージェント的であり、計画が必要かどうか、コードをレビューする必要があるかどうかを選択できます。これを行うと、Open SWEは、簡単なワンライナーのスタイル修正から、完全にスクラッチから製品の実装まで、あらゆるエンジニアリングタスクのためのワンストップショップになります。
仕組み:エージェントアーキテクチャ
Open SWEは、シーケンシャルに動作する3つの特殊なLangGraphエージェントを使用します。Manager、Planner、Programmer(Reviewerサブエージェントを含む)。
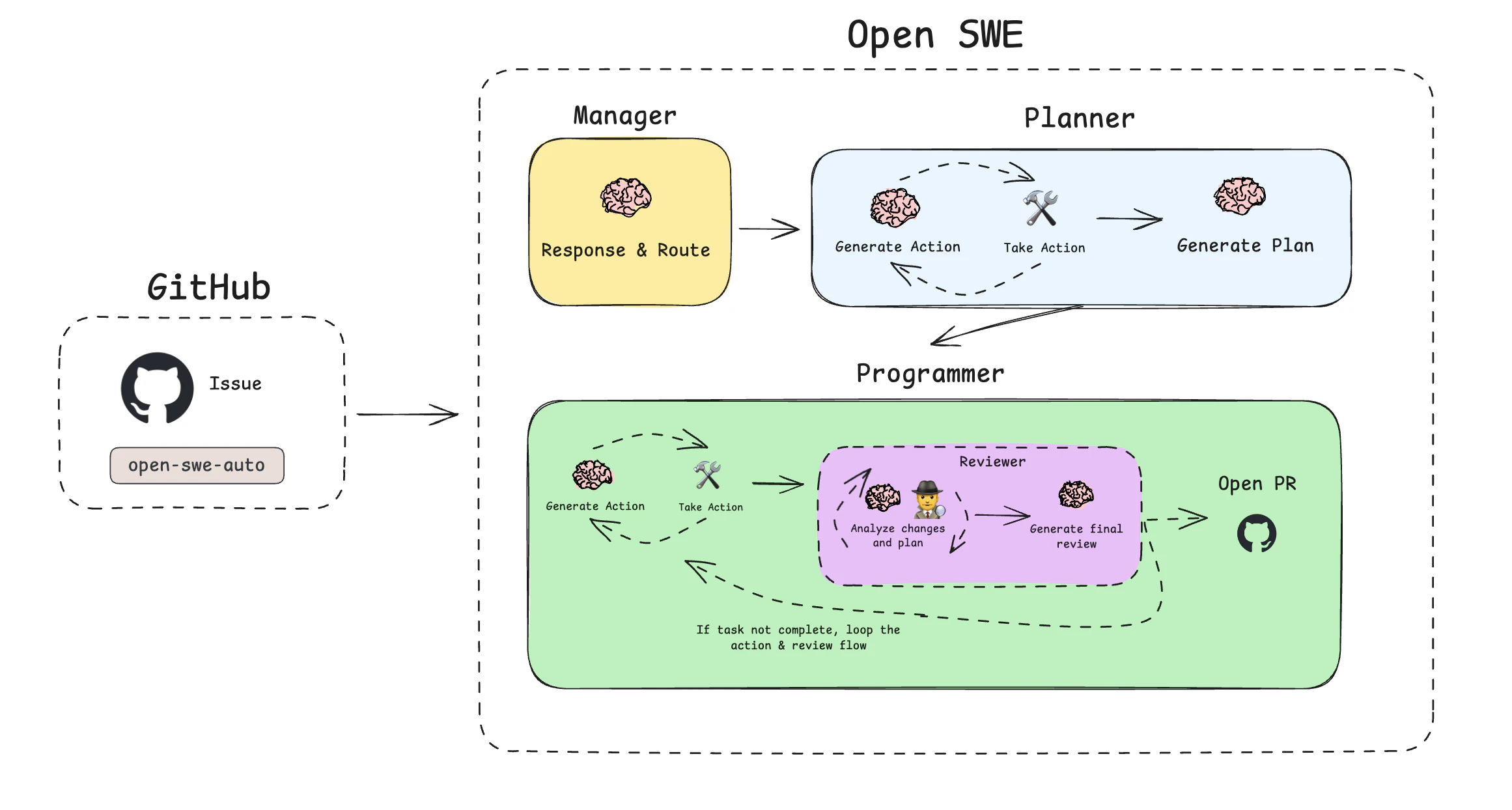
- Manager: このグラフはエントリーポイントです。ユーザーインタラクションを処理し、タスクをルーティングします。タスクを作成すると、状態を初期化し、Plannerに制御を渡します。
- Planner: 単一のコード行が書かれる前に、Plannerはリクエストを分析し、ファイルを表示して検索することでコードベースを調査し、詳細なステップバイステップの実行計画を作成します。デフォルトでは、これは、計画を編集、承認、またはフィードバックを提供する機会を与えられる手動レビューステップが必要です。ただし、大胆な場合は、このステップをスキップできます。
- Programmer & Reviewer: 計画が承認されると、Programmerはサンドボックス内の各ステップを実行します。これには、コードの記述、テストの実行、ドキュメントのWeb検索が含まれます。Programmerがタスクを完了すると、Reviewerに引き継ぎ、生成されたコードを品質、正確性、完全性の観点から分析します。問題が見つかった場合、Reviewerは別の反復のためにフィードバックとともにタスクをProgrammerに送信します。このアクション-レビューループは、コードが完璧になるまで続行されます。
Reviewerが作業を承認すると、Open SWEは最終的な結論を生成し、プルリクエストを開き、タスクを完了としてマークします。
使用した技術:LangGraphとLangGraph Platform
Open SWEはLangGraph上に構築されており、ワークフローの各ステップに対するより多くの制御を可能にします。Open SWEは、それぞれ独自のステートと一意の入力/出力を持つ4つのエージェントを介して動作します。LangGraphを使用することで、すべてのエージェントの呼び出しを簡単に調整し、いつでもそのステートを管理し、エッジケースのエラーを処理できます。LangGraphフレームワークに加えて、Open SWEはLangGraph Platform (LGP)にデプロイされています。LGPは、長時間実行されるエージェント(これらのエージェントは、1時間実行されることもあります)、組み込みの永続性(人間の介入機能の強化)、および必要に応じて数百のエージェント実行をキックオフできるオートスケールのために特別に設計されています。
LangSmithで洗練
Open SWEは、複雑なマルチエージェントシステムです。このシステムが役立つ結果を生み出すようにするために、最も大きな課題は、コンテキストエンジニアリングでした。ツールを使用するための正しい指示はありましたか?正しいコンテキストを取得していましたか?これらの指示を変更した場合、パフォーマンスはどう変わりますか?まずコンテキストエンジニアリングをデバッグし、次にコンテキストエンジニアリングの変更を評価するために、主要なAIオブザーバビリティおよび評価プラットフォームであるLangSmithを使用しました。
オープンソースで拡張可能
Open SWEは、すぐに強力なツールとして構築されましたが、コミュニティの基盤としての可能性に最も興奮しています。プロジェクト全体がオープンソースであり、LangGraph上に構築されており、拡張するように設計されています。
リポジトリをフォークし、プロンプトをカスタマイズし、内部APIの新しいツールを追加したり、チームの特定のニーズに合わせてエージェントのコアロジックを変更したりできます。 開発者ドキュメントは、独自のバージョンを設定およびデプロイするための詳細なガイドを提供します。
人間とエージェントの間の協調的なソフトウェア開発の未来を構築するための最初の大きな一歩として、Open SWEを考えています。