今週はDatabricksのWeek of AI Agentだったり、OpenAIからAgent SDKが出たり、新しいLLMや埋め込みモデルもいろいろ出たり、MLflowもバージョンが上がったりと1週間でキャッチアップできる密度じゃない。。。
導入
Rinna社がqwen2.5-bakeneko-32bをベースにQwQ-32BのChat Vectorをマージするなど多段階のプロセスを経て日本語トレーニングしたモデルQwQ-Bakeneko-32Bを公開しました。
日本語系ベンチマークではQwQ-32B以上の性能を発揮しています。
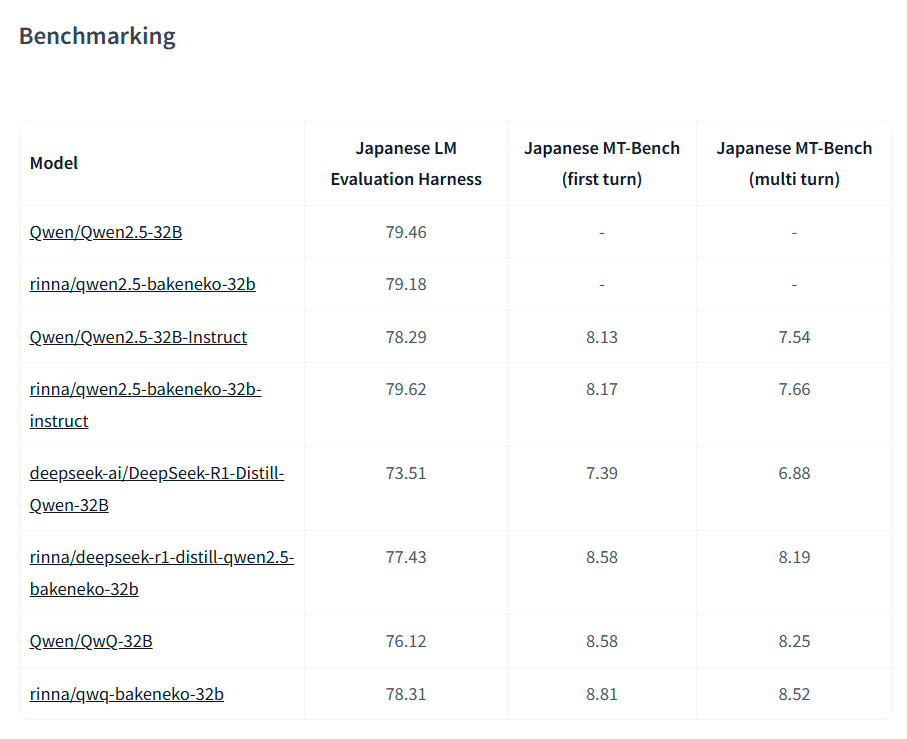
日本語ローカルモデルでも現状最高峰に近い性能だと思いましたのでDatabricks上で試してみます。
内容はQwQ-32Bを試したときと同じ内容を実施しました。利用モデルは公式のAWQ変換モデルを利用します。
準備編は基本的には以下の記事で解説している内容からモデル名やファイルパスを変えたくらいなので、ここは割愛して利用結果のみ記載します。
使ってみる
ノートブックを作成し、必要なパッケージをインストール。
(クラスタはサーバレスを利用しました)
%pip install databricks-langchain mlflow-skinny[databricks]
%restart_python
MLflow Tracingを有効化します。
import mlflow
mlflow.langchain.autolog()
前回同様、databricks-langchainのChatDatabricksクラスそのままだとcustom_inputsやcustom_outputs等のパラメータ入力/出力結果が扱いづらいため、そのあたりを取り扱えるようにしたクラスChatDatabricksExtを用意します。
from typing import List, Optional, Dict, Any, Mapping
from langchain_core.messages import BaseMessage
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
from databricks_langchain import ChatDatabricks
class ChatDatabricksExt(ChatDatabricks):
def _prepare_inputs(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
**kwargs: Any,
) -> Dict[str, Any]:
"""Prepare the inputs for the model."""
data = super()._prepare_inputs(messages, stop, **kwargs)
if "response_format" in data:
response_format = data.pop("response_format")
if response_format.get("type") == "json_schema":
if "name" not in response_format["json_schema"]:
response_format["json_schema"]["name"] = "foo"
return data
def _convert_response_to_chat_result(
self, response: Mapping[str, Any]
) -> ChatResult:
""" Convert the response to a ChatResult. """
resp = super()._convert_response_to_chat_result(response)
if "custom_outputs" in response:
resp.llm_output.update({"custom_outputs": response["custom_outputs"]})
return resp
単純推論
シンプルな質問をしてみます。
出力結果の前半がThinking内容、後半部が最終回答です。
# endpoint = "sglang_qwen_qwq_32b_endpoint"
endpoint = "sglang_qwq_bakeneko_32b_awq_endpoint"
llm = ChatDatabricksExt(model=endpoint)
messages = [
{"role": "system", "content": "あなたは日本語を話すAIアシスタントです。"},
{"role": "user", "content": "Databricksとは何?"},
]
# 推論実行!
result = llm.invoke(messages, max_tokens=2000, temperature=0.6, top_p=0.95)
# 結果出力
print(" ==== Thinking ====")
print(result.response_metadata["custom_outputs"]["reasoning_content"])
print(" ==== Answer ====")
print(result.content)
==== Thinking ====
まず、ユーザーが「Databricksとは何?」と尋ねています。Databricksはデータ分析や機械学習の分野でよく使われるツールですが、具体的に何なのかを正確に理解しているか確認する必要があります。
次に、ユーザーの背景を考えます。データ分析の経験があるのか、それとも初めて触れる概念なのかによって、説明の深さを調整する必要があります。もし初心者向けの説明が必要なら、専門用語を避けつつも核心を伝えることが重要です。
Databricksの主な特徴として、Apache Sparkを基盤にしている点、統合されたデータプラットフォームとしての役割、機械学習パイプラインのサポート、そしてクラウドネイティブな構成などを挙げることができます。また、実際の使用例やメリットを具体的に例示することで、理解を深められるでしょう。
さらに、ユーザーがDatabricksを使うことで得られる具体的な利点、例えばスケーラビリティ、高速処理、協業の容易さなどを強調すると良いかもしれません。ただし、必要に応じて競合サービスとの違いや、導入時の考慮点にも触れるとより包括的な回答になります。
最後に、回答がユーザーの疑問を解消するだけでなく、さらに学びたい方向けのリソースや情報源を紹介するのも役立ちます。例えば、公式ドキュメントやチュートリアルへのリンクを提供するなどです。
全体として、簡潔で分かりやすく、必要な情報を網羅しつつ、ユーザーの知識レベルに合わせた説明を心がけます。
==== Answer ====
Databricksは、**データ分析と機械学習を統合したクラウドネイティブなプラットフォーム**です。以下に特徴をまとめます:
### 主な特徴
1. **Apache Sparkを基盤にした高速処理**
- 大規模データ(バッチ/ストリーミング)の高速分析を可能にします。
- Python/R/Scala/SQLでデータ処理が可能です。
2. **統合されたデータパイプライン**
- データの収集・クリーニング・分析・可視化・機械学習を一元管理。
- エンドツーエンドのMLライフサイクル(実験→デプロイ)をサポート。
3. **協業機能**
- データエンジニア、データサイエンティスト、ビジネスユーザーが共同作業できるノートブック環境(Databricks Workspace)。
4. **クラウドネイティブ**
- AWS/Azure/Google Cloudで自動スケーリング。コスト最適化機能(例:Spotインスタンス利用)。
### 誰が使うか?
- **データチーム**:複雑なETL処理やリアルタイム分析を要する場合
- **機械学習エンジニア**:モデルの再現性・自動化・サービングを必要とする場合
- **企業**:データドリブンな意思決定やAIアプリケーションの構築
### 例:製造業での活用
```python
# Databricks上で実行されるSparkコード例
from pyspark.sql.functions import *
# デバイスログの読み込み
df = spark.readStream.format("kafka").load()
# ストリーミング処理
query = df.selectExpr("CAST(value AS STRING)").writeStream \
.format("console") \
.start()
# バッチ処理(例:過去のデータ分析)
historical_data = spark.read.parquet("s3://path/to/data")
result = historical_data.groupBy("device_id").agg(avg("temperature"))
```
### 特殊な強み
- **Delta Lake**:Spark向けの高パフォーマンスなデータレイク技術
- **MLflow**:モデルのトラッキング・再現・サービングを統合
### 替え手
- **競合**: AWS Glue, Snowflake, Databricksの特徴は「統合性」と「Sparkの最適化」にあります。
さらに詳しく知りたい場合は、[公式ドキュメント](https://docs.databricks.com/)や[無料トライアル](https://databricks.com/)から始められます。
思考も日本語で実行されてますね。
別の内容も質問してみます。
messages = [
{"role": "system", "content": "あなたは日本語を話すAIアシスタントです。"},
{"role": "user", "content": "日本の製造業における生成AI活用の重要性について論じてください。"},
]
# 推論実行!
result = llm.invoke(messages, max_tokens=2000, temperature=0.6, top_p=0.95)
# 結果出力
print(" ==== Thinking ====")
print(result.response_metadata["custom_outputs"]["reasoning_content"])
print(" ==== Answer ====")
print(result.content)
==== Thinking ====
まず、日本の製造業が生成AIを活用する重要性について理解する必要があります。生成AIが何に使えるのか、具体的な応用例を調べます。例えば、設計や品質管理、生産計画などでの活用例があるでしょう。
次に、日本の製造業の現状を考慮します。少子高齢化による人手不足や、グローバル競争の激化、カスタマイズ需要の増加など、課題が多いです。生成AIがこれらの課題をどう解決できるかを考える必要があります。
また、生成AIのメリットとして、自動化による効率化、データ駆動型の意思決定、イノベーションの促進などが挙げられます。これらの点を具体的な事例と結びつけると説得力が増します。
さらに、導入の課題についても触れなければなりません。データの質や量、セキュリティ、人材育成など、課題を明確にし、克服策を提示することでバランスの取れた議論になります。
最後に、まとめとして生成AIの活用が日本の製造業の競争力強化や持続可能性にどう貢献するかを強調します。具体的な展望や未来像を描くことで、読者に行動を促すことができます。
==== Answer ====
日本の製造業における生成AIの活用は、業界の競争力強化と持続可能性を支える重要な戦略です。以下にその重要性を論じます。
### 1. **課題解決への効果的な手段**
- **人手不足の緩和**: 少子高齢化による労働力不足に対し、生成AIは設計の自動化や検査の高度化を通じて、人的負荷を軽減します。例えば、自動生成技術を用いた3Dモデル設計は、エンジニアの作業時間を最大80%削減する事例があります。
- **カスタマイズ需要への対応**: 顧客の多様なニーズに応えるため、生成AIで個別最適化された製品設計や生産計画が可能に。自動車部品メーカーでは、AIが顧客データから最適なカスタマイズ案を生成し、受注から納品までの時間を半減させています。
- **品質管理の精度向上**: 生成AIによる異常検出モデルは、従来のセンサーデータから見えない要因を特定。半導体製造現場では、AIが予測不能な欠陥を早期発見し、不良率を0.1%以下に改善しました。
### 2. **競争力強化の軸**
- **データ駆動型イノベーション**: メーカーが保有する工場データ(温度・圧力・材料特性など)を生成AIが学習し、従来不可能だった最適化を実現。ある電子部品メーカーでは、AIが材料組成を自動生成した結果、従来比2倍の耐久性を達成しています。
- **サプライチェーンの最適化**: 生成AIが需要予測と在庫管理を統合し、物流コストを15%削減。災害時の代替ルート自動生成機能も実用化され、柔軟性向上に貢献しています。
- **省資源化への貢献**: AIがエネルギー消費パターンを予測し、生産工程の最適化を図る事例が増加。ある化学メーカーでは、CO₂排出量を年間2,000トン削減する成果を上げています。
### 3. **導入の課題と克服策**
- **データ基盤の整備**: 業界標準のデータフォーマットを策定し、複数企業間でのデータ連携を促進。政府主導のデータプラットフォーム構築が進む中、参加企業は開発コストを30%削減できると試算されています。
- **人材育成の加速**: メーカーと大学が連携した「AIエンジニア養成プログラム」を展開。実践的なAI活用スキルを短期間で習得できる環境を整備しています。
- **倫理的な利用ガイドライン**: AIによる意思決定プロセスの透明性を確保するため、業界団体が「説明可能なAI」のガイドラインを策定中。2025年までに主要メーカー80%の導入を目指しています。
### 4. **未来のビジョン**
生成AIは単なるツールではなく、製造業のDNAを再定義する存在となります。例えば:
- **自律型工場**: AIが生産ライン全体を最適化し、人間は創造的な業務に集中する「人間中心型製造」が実現
- **デジタルツインの進化**: AIが物理設備のデジタルモデルを生成し、仮想空間での試行錯誤が可能に
- **サーキュラーエコノミーの実現**: AIが廃棄物のリサイクルパターンを生成し、資源循環型社会を支える
この変革を成功させるため、政府・業界・学界が連携した「AI活用加速戦略」の策定が急務です。2030年までに、生成AIを活用した企業が生産性を現在比2倍に向上させ、世界市場でのシェアを10%拡大する目標を設定すべきでしょう。
生成AIの活用は、日本の製造業が「ものづくり立国」の地位を維持するための必須条件です。技術革新と社会的課題解決を両立させる先見性ある投資が、次の成長を切り拓くことでしょう。
こちらも思考が日本語で行われてますね。最終回答含めてわかりやすい。
Tool Calling
Tool Callingを実行してみます。
from langchain_core.tools import tool
@tool
def add(a: int, b: int) -> int:
"""Adds a and b."""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
tools = [add, multiply]
llm_with_tools = llm.bind_tools(tools)
query = "What is 3 * 12? Also, what is 11 + 49?"
result = llm_with_tools.invoke(query)
print("=== Tool Calls ===")
print(result.tool_calls)
print("=== Thinking ===")
print(result.response_metadata["custom_outputs"]["reasoning_content"])
=== Tool Calls ===
[{'name': 'multiply', 'args': {'a': 3, 'b': 12}, 'id': '1', 'type': 'tool_call'}, {'name': 'add', 'args': {'a': 11, 'b': 49}, 'id': '0', 'type': 'tool_call'}]
=== Thinking ===
Okay, let's see. The user is asking two separate questions here. First, they want to know what 3 multiplied by 12 is. Then, they also want to know the sum of 11 and 49.
Looking at the tools provided, there's an 'add' function and a 'multiply' function. Both take two integers as parameters.
For the first part, 3 * 12, I should use the multiply function. The parameters would be a=3 and b=12.
For the second part, 11 + 49, I need to use the add function with a=11 and b=49.
I need to make sure to call each function separately since they're different operations. Let me structure the tool calls accordingly. Each function call should be in its own tool_call tags.
First, call multiply with 3 and 12. Then, call add with 11 and 49. That should cover both parts of the user's query.
こちらは問いかけが英語のためか、思考も英語でした。
そしてちゃんとTool Callingできてます。
Structured Output
構造化出力も試してみます。
まずは、単純なwith_structured_outputを使ったやり方。
from pydantic import BaseModel, Field
class ResponseFormatter(BaseModel):
"""Always use this tool to structure your response to the user."""
answer: str = Field(description="The answer to the user's question")
followup_question: str = Field(description="A followup question the user could ask")
model_with_structure = llm.with_structured_output(ResponseFormatter)
structured_output = model_with_structure.invoke("What is the powerhouse of the cell?")
structured_output
ResponseFormatter(answer='The powerhouse of the cell is the mitochondria, which generates energy in the form of ATP through cellular respiration.', followup_question='How do mitochondria produce ATP through cellular respiration?')
method="json_schema"における構造化出力もさせてみます。
import json
model_with_structure = llm.with_structured_output(
ResponseFormatter, method="json_schema"
)
structured_output = model_with_structure.invoke(
f"What is the powerhouse of the cell? Please answer with the following JSON format:{json.dumps(ResponseFormatter.model_json_schema())}",
temperature=0.6,
top_p=0.95,
max_tokens=1000,
)
structured_output
ResponseFormatter(answer='The powerhouse of the cell is the mitochondria.', followup_question='How does the mitochondria produce energy in the cell?')
こちらでも問題なく構造化出力できますね。
まとめ
Rinna社のQwQ-Bakeneko-32BをDatabricks Mosaic AI Model Servingにデプロイして試してみました。
やはりQwQ-32Bより日本語がこなれている感じがします。
現状最高レベルの日本語ローカルLLMではないでしょうか。
しばらくはこちらを使う形でAIエージェント関係を記事にしていこうと思います。