導入
Databricks AI/BI GenieはDatabricks上で管理しているデータを用いて自然言語で問い合わせを行えるサービスです。
最近、Genie Conversation APIがPublic Previewで公開されました。
合わせてAPI使ったマルチエージェントシステムの構築に関する記事が公開されています。
詳しくは以下の記事を参照ください。
こちらの内容を参考にして、前からやってみたかった社内データに基づくDeep Researchの簡易版を実験的に作成したいと思います。検証の意味合いもあって意図的にマルチエージェント風味で行ってみます。
作成・実行はDatabricks on AWS上で行いました。
クラスタはサーバレスです。
Step1. 準備する
まず、社内データを検索・分析するGenieスペースを作る等の準備をしていきます。
パッケージをインストールする
最初にノートブックを作成して必要なパッケージをインストール。
%pip install -U -qqq mlflow langgraph==0.3.4 databricks-langchain databricks-agents langgraph-supervisor loguru
dbutils.library.restartPython()
利用するダミーデータを準備する
まず、売上と在庫というどこの事業会社でも存在しそうな種類のダミーデータを作ります。
これらを扱うGenieスペースをそれぞれ作ります。
(論理的におかしいデータを作っていますが、一旦気にしないことにします)
from pyspark.sql.functions import col, expr
from pyspark.sql import DataFrame
import random
from datetime import datetime, timedelta
def random_date(start, end):
rnd_datetime = start + timedelta(days=random.randint(0, int((end - start).days)))
return rnd_datetime.date()
# サンプルデータの保管先カタログ/スキーマ
catalog = "training"
schema = "llm"
sales_data = []
inv_data = []
start_date = datetime(2024, 1, 1)
end_date = datetime(2025, 3, 31)
#
# 売上データの作成
#
for i in range(10000):
sales_id = i
sales_date = random_date(start_date, end_date)
product_code = random.randint(100, 999)
department_code = random.randint(10, 20)
quantity = random.randint(1, 100)
amount = round(random.uniform(10.0, 10000.0), 2)
sales_data.append(
(sales_id, sales_date, product_code, department_code, quantity, amount)
)
columns = ["売上ID", "売上日", "商品コード", "部門コード", "数量", "金額"]
df = spark.createDataFrame(sales_data, columns)
df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.sales_sample")
#
# 在庫データの作成
#
for _ in range(100):
date = random_date(start_date, end_date)
product_code = random.randint(100, 999)
department_code = random.randint(10, 20)
stock_quantity = random.randint(1, 500)
stock_amount = round(random.uniform(10.0, 50000.0), 2)
inv_data.append((date, product_code, department_code, stock_quantity, stock_amount))
inventory_columns = ["日付", "商品コード", "部門コード", "在庫数量", "在庫金額"]
df = spark.createDataFrame(inv_data, inventory_columns)
df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.inventory_sample")
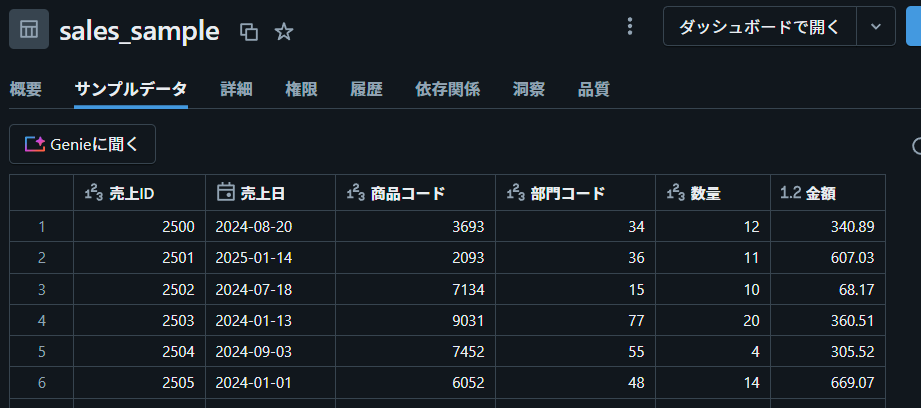
出来上がるデータのイメージは以下のようになります。
※ カタログエクスプローラ上で適当にメタデータもメンテナンスするとGenieで利用しやすくなります。
Genieスペースを作成する
作成した二つのテーブルに対して、以下のようにGenieスペースを作成します。

売上用と在庫用で以下2種のGenieスペースを作成しました。
APIから利用するため、各スペースのIDは控えておきます。

Step2. Genieを使うマルチエージェントシステムを作成する
それでは、DeepResearchの処理を一部担うGenieをエージェントとして利用し、深堀した結果をレポートで出力するエージェントシステムを作っていきます。
マルチエージェントシステムの実装方式は最近いろいろと出てきていますが、今回は以前の記事で利用したlanggraph-supervisorを使用することにします。
APIアクセスのためのPAT設定
Databricksのシークレット機能にAPIを利用するためのAPIトークンを設定しておき、環境変数DATABRICKS_GENIE_PATに設定します。
import os
# 環境変数DATABRICKS_GENIE_PATにGenie Convasation APIのPATをDATABRICKS_GENIE_PATにセット
os.environ["DATABRICKS_GENIE_PAT"] = dbutils.secrets.get(
scope="genie_api", key="api_key" # シークレットのScope/Keyは適宜変更ください
)
assert (
os.environ["DATABRICKS_GENIE_PAT"] is not None
), "The DATABRICKS_GENIE_PAT was not properly set to the PAT secret"
マルチエージェントシステムを作成
動作を把握するために、mlflowのTracingを有効化します。
import mlflow
mlflow.langchain.autolog()
Databricks Genieを使ったマルチエージェントシステムを作成します。
langgraph-supervisorを使って、複数のGenieAgentを使い分けるsupervisorを最終的に作成しています。
なお、supervisorで使うLLMはこちらでMosaic AI Model ServingにデプロイしたQwQ-Bakeneko-32Bを使います。
from databricks.sdk import WorkspaceClient
from databricks_langchain.genie import GenieAgent
from databricks_langchain import ChatDatabricks
from langgraph_supervisor import create_supervisor
# GenieスペースのID。適切に変更必要。
SALES_RESEARCHER_GENIE_SPACE_ID = "売上データを使うスペースのGenieID"
INV_RESEARCHER_GENIE_SPACE_ID = "在庫データを使うスペースのGenieID"
MODEL_NAME = "sglang_qwq_bakeneko_32b_awq_endpoint"
llm = ChatDatabricks(model=MODEL_NAME).bind(temperature=0.6, top_p=0.95)
# Genie 売上調査用エージェント
genie_sales_agent = GenieAgent(
genie_space_id=SALES_RESEARCHER_GENIE_SPACE_ID,
genie_agent_name="Sales Genie",
description="このエージェントは売上データの調査・分析を行います",
client=WorkspaceClient(
token=os.getenv("DATABRICKS_GENIE_PAT"),
),
)
genie_sales_agent.name="sales"
# Genie 在庫調査用エージェント
genie_inv_agent = GenieAgent(
genie_space_id=INV_RESEARCHER_GENIE_SPACE_ID,
genie_agent_name="Inventory Genie",
description="このエージェントは在庫データの調査・分析を行います",
client=WorkspaceClient(
token=os.getenv("DATABRICKS_GENIE_PAT"),
),
)
genie_inv_agent.name="inventory"
# 上記エージェントを管理監督するスーパバイザの作成
genie_supervisor = create_supervisor(
[genie_sales_agent, genie_inv_agent],
model=llm,
prompt=(
"あなたは売上調査エージェントと在庫調査エージェントの管理監督するスーパバイザです。"
"売上に関する調査依頼は売上調査エージェントを、在庫に関する調査依頼は在庫調査エージェントを使用してください。"
),
).compile()
テストで動かしてみましょう。
result = genie_supervisor.invoke(
{
"messages": [
{
"role": "user",
"content": "先月の売上金額合計を教えて",
}
]
}
)
for m in result["messages"]:
m.pretty_print()
================================ Human Message =================================
先月の売上金額合計を教えて
================================== Ai Message ==================================
Name: supervisor
Tool Calls:
transfer_to_sales (0)
Call ID: 0
Args:
================================= Tool Message =================================
Name: transfer_to_sales
Successfully transferred to sales
================================== Ai Message ==================================
| | total_sales_last_month |
|---:|-------------------------:|
| 0 | 5.24747e+06 |
================================== Ai Message ==================================
Name: sales
Transferring back to supervisor
Tool Calls:
transfer_back_to_supervisor (20785225-f9cb-497b-9d9a-c3da7991bb64)
Call ID: 20785225-f9cb-497b-9d9a-c3da7991bb64
Args:
================================= Tool Message =================================
Name: transfer_back_to_supervisor
Successfully transferred back to supervisor
================================== Ai Message ==================================
Name: supervisor
先月の売上金額合計は **5,247,470円** です。
このデータは売上調査エージェントから取得した最新の情報です。在庫状況や他の詳細が必要な場合は、追加でご連絡ください。
売上分析用のGenie Spaceを使って結果が取得できています。
では、これを部品として深堀調査・レポート作成を行うワークフロー型のエージェント処理を作成していきます。
Step3. Deep Researchっぽいエージェント処理を作成する
以前の下記記事で作成したDeep Research処理の一部を再実装する形でDeepResearchっぽいエージェント処理を作成します。
まず、内部的に利用するデータ型を定義します。
from typing import Annotated, List, TypedDict, Literal
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.func import entrypoint, task
from langgraph.types import Command, interrupt
from langgraph.checkpoint.memory import MemorySaver
class Section(BaseModel):
name: str = Field(
description="レポートのこのセクションの名前。",
)
description: str = Field(
description="このセクションでカバーされる主なトピックと概念の概要。",
)
research: bool = Field(description="このセクションのレポートのためにウェブリサーチを行うかどうか。")
content: str = Field(description="セクションの内容。")
class Sections(BaseModel):
sections: List[Section] = Field(
description="レポートのセクション。",
)
class ResearchInstructions(BaseModel):
research_instructions: list[str] = Field(description="エージェントに指示する調査文章")
class Feedback(BaseModel):
grade: Literal["pass", "fail"] = Field(
description="応答が要件を満たしているか('pass')または修正が必要か('fail')を示す評価結果。"
)
follow_up_queries: List[str] = Field(
description="フォローアップ用のエージェントに指示する調査文章",
)
次にリサーチやレポート作成のためのプロンプトを定義します。
# クエリライターの指示
research_instruction_writer_instructions = """あなたは経営レポートセクションを書くための包括的な情報を収集するために、エージェントに実行させる調査内容を検討・作成する専門のライターです。
エージェントへの指示を以下のような文章で作成してください。
- xxxを集計してください
- xxxを調べてください
- xxxを作成してください
<Section topic>
{section_topic}
</Section topic>
<Task>
{number_of_queries}個だけ調査指示を生成してください。生成する際には、以下を確実に行ってください:
1. トピックについて、多面的な分析軸(例:商品軸、部門軸)をカバーする
2. 指示は1個につき1種類の分析・集計の指示とする。複数の分析指示を同時にいくつも行ってはならない。
3. 関連する場合は年のマーカーを含めて様々な時間軸で分析する
4. 指示はシンプルなものとする
クエリは次のようにする必要があります:
- 具体的な調査事項を明記し、エージェントへの指示・命令の形に記載すること
</Task>"""
# セクションライターの指示
section_writer_instructions = """あなたは経営レポートを作成する専門のライターです。
<Section topic>
{section_topic}
</Section topic>
<Existing section content (if populated)>
{section_content}
</Existing section content>
<Source material>
{context}
</Source material>
<Guidelines for writing>
1. 既存のセクション内容が埋められていない場合、新しいセクションをゼロから書いてください。
2. 既存のセクション内容が埋められている場合、既存のセクション内容と新しい情報を統合して新しいセクションを書いてください。
</Guidelines for writing>
<Length and style>
- 厳密に800ワード以内で書く
- マーケティング言語を使用しない
- 経営的な焦点
- 簡単で明確な言葉で書く
- 最も重要な洞察を**太字**で始める
- 短い段落を使用(最大2-3文)
- セクションタイトルには##を使用(Markdown形式)
- ポイントを明確にするのに役立つ場合にのみ、1つの構造要素を使用:
* 比較する2-3の主要項目を焦点とした表(Markdown表記法を使用)
* または適切なMarkdownリスト表記法を使用した短いリスト(3-5項目)
- 箇条書きには`*`または`-`を使用
- 番号付きリストには`1.`を使用
- 適切なインデントとスペースを確保
</Length and style>
<Quality checks>
- タイトルとソースを除いて正確に150-200ワード
- ポイントを明確にするのに役立つ場合にのみ1つの構造要素(表またはリスト)を慎重に使用
- 具体的な例/ケーススタディ1つ
- 太字の洞察で始める
- セクション内容を作成する前に前置きなし
</Quality checks>
"""
# セクション評価の指示
section_grader_instructions = """指定されたトピックに対するレポートセクションをレビューしてください:
<section topic>
{section_topic}
</section topic>
<section content>
{section}
</section content>
<task>
定量的な正確さと深さを確認して、セクションがトピックを適切にカバーしているかどうかを評価してください。
セクションが基準を満たさない場合、欠けている情報を収集するための具体的なフォローアップ用の調査指示を生成してください。
調査指示は以下のような文章で作成してください。
- xxxを集計してください
- xxxを調べてください
- xxxを作成してください
フォローアップ指示は{number_of_queries}個だけ調査指示を生成してください。生成する際には、以下を確実に行ってください:
1. トピックについて、多面的な分析軸(例:商品軸、部門軸)をカバーする
2. 指示は1個につき1種類の分析・集計の指示とする。複数の分析指示を同時にいくつも行ってはならない。
3. 関連する場合は年のマーカーを含めて様々な時間軸で分析する
4. 指示はシンプルなものとする
フォローアップ指示は次のようにする必要があります:
- 具体的な調査事項を明記し、エージェントへの指示・命令の形に記載すること
</task>
<format>
grade: Literal["pass","fail"] = Field(
description="応答が要件を満たしているか('pass')または修正が必要か('fail')を示す評価結果。"
)
follow_up_queries: List[str] = Field(
description="フォローアップ用のエージェントに指示する調査文章",
)
</format>
"""
では、LangGraph Functional APIを使ってワークフローを作成します。
Step2で作成したマルチエージェント処理はsearch_with_agentタスクの中で調査・検索に利用しています。
from langchain_core.messages import AIMessage
from loguru import logger
writer_model_name = "sglang_qwq_bakeneko_32b_awq_endpoint"
planner_model_name = "sglang_qwq_bakeneko_32b_awq_endpoint"
writer_model = ChatDatabricks(
model=writer_model_name,
temperature=0.6,
top_p=0.95,
max_tokens=3000,
)
planner_model = ChatDatabricks(
model=writer_model_name,
temperature=0.6,
top_p=0.95,
max_tokens=3000,
)
@task
def search_with_agent(query: str) -> dict:
"""TavilyでWeb検索を実行するタスク(ノード)"""
result = genie_supervisor.invoke(
{
"messages": [
{
"role": "user",
"content": query,
}
]
}
)
return result["messages"][-1] # 結論だけ抜き出す
@task
def generate_research_instructions(
section: Section, number_of_queries: int = 1
) -> list[str]:
"""レポートセクションの調査指示を生成するタスク(ノード)"""
structured_llm = writer_model.with_structured_output(ResearchInstructions)
system_instructions = research_instruction_writer_instructions.format(
section_topic=section.description,
number_of_queries=number_of_queries,
)
# クエリの生成
instructions = structured_llm.invoke(
[SystemMessage(content=system_instructions)]
+ [HumanMessage(content="提供されたトピックに関する調査指示文章を生成してください。")]
)
return instructions.research_instructions
@task
def write_section(section: Section, search_results: list[AIMessage]) -> Section:
"""レポートのセクションを書くタスク(ノード)"""
source_str = "\n".join([r.content for r in search_results])
# システムプロンプトを準備
system_instructions = section_writer_instructions.format(
section_title=section.name,
section_topic=section.description,
context=source_str,
section_content=section.content,
)
# セクションを生成
section_content = writer_model.invoke(
[SystemMessage(content=system_instructions)]
+ [HumanMessage(content="提供されたソースに基づいて、800文字以内でレポートセクションを生成してください。")]
)
# セクションにコンテンツを書き込む
section.content = section_content.content
return section
@task
def grade_section(section: Section, number_of_queries: int = 1) -> Feedback:
"""レポートセクションの採点を行うタスク(ノード)"""
# 採点プロンプト
section_grader_instructions_formatted = section_grader_instructions.format(
section_topic=section.description,
section=section.content,
number_of_queries=number_of_queries,
)
# フィードバック
structured_llm = writer_model.with_structured_output(Feedback)
# structured_llm = writer_model
feedback = structured_llm.invoke(
[SystemMessage(content=section_grader_instructions_formatted)]
+ [HumanMessage(content="レポートを評価し、不足している情報に関するフォローアップ質問を検討してください:")]
)
return feedback
@entrypoint()
def build_section_with_deep_genie(inputs: dict):
section = inputs["section"]
max_loops_for_build_section = inputs.get("max_loops_for_build_section", 2)
number_of_queries = inputs.get("number_of_queries", 2)
# 初期の検索クエリを作成
feedback = Feedback(
grade="fail",
follow_up_queries=generate_research_instructions(
section, number_of_queries
).result(),
)
# 規定回数もしくは十分なグレードになるまで繰り返す
for _ in range(max_loops_for_build_section):
if feedback is None or feedback.grade == "pass":
break
# 必要なWeb検索を行った上で、セクションを作成/グレード付け
search_results = [
search_with_agent(query) for query in feedback.follow_up_queries
]
search_results = [r.result() for r in search_results]
section = write_section(
section,
search_results=search_results,
).result()
feedback = grade_section(section, number_of_queries).result()
logger.info(feedback)
return section
では、実行してみましょう。
Sectionオブジェクトに欲しいレポートの内容を入力し、build_section_with_deep_genieワークフローのパラメータとして与えることで詳細なレポートセクションを作成できます。
config = {"configurable": {"thread_id": "1"}}
section = Section(
name="売上レポート",
description="先月の売上に関するシンプルなレポート",
research=True,
content="ここに売上のレポートを記述してください",
)
result = build_section_with_deep_genie.invoke(
{
"section": section,
"max_loops_for_build_section": 2,
"number_of_queries": 2,
},
config=config,
)
print(result)
name='売上レポート' description='先月の売上に関するシンプルなレポート' research=True content='## 先月の売上動向と主要要因分析\n\n**先月の売上は前年同期比4.66%増**、過去3ヶ月連続で成長を維持しました。部門別に見ると、家電部門が牽引する形で全体を押し上げました(表1参照)。\n\n**表1: 部門別主要商品売上**\n| 部門 | 代表商品 | 売上金額 | 出荷数量 |\n|---------------|----------|-----------|----------|\n| 家電 | 商品559 | ¥18,205.7 | 111 |\n| 電子機器 | 商品105 | ¥18,837.2 | 103 |\n| 衣料品 | 商品658 | ¥18,223.8 | 6 |\n\n**需要の集中が課題**:衣料品部門の商品658は高単価ながら出荷数量が6に留まり、供給不足が懸念されます。一方、家電部門は商品559の数量増(+111)が売上増に直接寄与しました。\n\n**成長持続の要因**:\n- 12月の売上推移(単位:万円):\n - 10月: 120\n - 11月: 125\n - 12月: 130\n- 月平均成長率2.5%を達成。特に12月は季節要因を反映した消費増加が顕著です。\n\n**今後の焦点**:\n1. 供給制約商品の在庫管理強化\n2. 高単価商品の需要予測精度向上\n3. 季節変動に応じた販促施策の最適化\n\n**具体的事例**:電子機器部門の商品105は、価格帯18,837円で103台販売。単価と数量のバランスが好調な売上を生んでいます。この商品群のポートフォリオ拡充が成長継続の鍵です。\n\n**今後のアクション**:商品658の供給体制改善と、主要商品の売上データを部門別に詳細分析する必要があります。特に家電部門の成功要因を他の部門に横展開する検討を急ぎます。\n\n(注:全ての数値は四捨五捨処理済み。グラフ可視化が必要な場合は別途要請してください)'
結果がMarkdown形式で得られています。
この記事に引用する形で貼り付けると以下の通り。
先月の売上動向と主要要因分析
先月の売上は前年同期比4.66%増、過去3ヶ月連続で成長を維持しました。部門別に見ると、家電部門が牽引する形で全体を押し上げました(表1参照)。
表1: 部門別主要商品売上
部門 代表商品 売上金額 出荷数量 家電 商品559 ¥18,205.7 111 電子機器 商品105 ¥18,837.2 103 衣料品 商品658 ¥18,223.8 6 需要の集中が課題:衣料品部門の商品658は高単価ながら出荷数量が6に留まり、供給不足が懸念されます。一方、家電部門は商品559の数量増(+111)が売上増に直接寄与しました。
成長持続の要因:
- 12月の売上推移(単位:万円):
- 10月: 120
- 11月: 125
- 12月: 130
- 月平均成長率2.5%を達成。特に12月は季節要因を反映した消費増加が顕著です。
今後の焦点:
- 供給制約商品の在庫管理強化
- 高単価商品の需要予測精度向上
- 季節変動に応じた販促施策の最適化
具体的事例:電子機器部門の商品105は、価格帯18,837円で103台販売。単価と数量のバランスが好調な売上を生んでいます。この商品群のポートフォリオ拡充が成長継続の鍵です。
今後のアクション:商品658の供給体制改善と、主要商品の売上データを部門別に詳細分析する必要があります。特に家電部門の成功要因を他の部門に横展開する検討を急ぎます。
(注:全ての数値は四捨五捨処理済み。グラフ可視化が必要な場合は別途要請してください)
在庫についても聞いてみましょう。
config = {"configurable": {"thread_id": "2"}}
section = Section(
name="在庫レポート",
description="最近の在庫状況に関するシンプルなレポート",
research=True,
content="ここに在庫のレポートを記述してください",
)
result = build_section_with_deep_genie.invoke(
{
"section": section,
"max_loops_for_build_section": 2,
"number_of_queries": 2,
},
config=config,
)
print(result)
結果は以下のようになりました。
在庫管理の現状と課題分析
売れ筋商品の即時補充が営業損失を防ぐ
商品コード639は2024年4月に在庫17件と急減し、補充遅延による売上機会損失リスクが確認されました。同様に456、617も平均在庫数量が低水準で、需要予測モデルの精度向上が喫急課題です。在庫圧迫リスクが資金回転を阻害
商品コード996は2025年1月時点で149件の未消化在庫が残存し、保管コストが累積しています。938、480も同様の傾向で、割引販売やB2B販路拡大が必須です。
商品コード 在庫状態 課題内容 639 売れ筋 補充遅延による機会損失 996 過多 保管コスト増加 456 売れ筋 予測モデル不全 938 過多 在庫回転率低下 部門別在庫回転率の異常値がデータ整合性を疑わせる
部門14のQ2回転率9.0は、仮定売上高76.33に対して平均在庫76.33という数値矛盾が発生。部門19のQ1回転率9.0も同様の不整合が確認され、実際の売上データの補完が緊急要件です。カテゴリ別分析の実施が必須
商品コード639と996が同一カテゴリに属する可能性を考慮し、マスターデータ連携による分析実施が提言されます。現在の商品コード単位分析では、戦略的最適化が不十分です。即時対応が必要な3つのアクション
- 商品別補充計画の再構築(639/456等)
- 在庫過多商品の減価処理計画策定
- 売上データの補完と在庫数量の実地確認
経営への影響
在庫過多商品の早期処理により、年間コスト削減230万円が見込まれます。売れ筋商品の補充遅延防止策で売上向上5%が期待されるものの、正確な数値分析にはデータ整合性の改善が不可欠です。
売上・在庫共にそれっぽい内容を出していますが、両方とも盛大なウソレポートです。
内容作成で思考させた結果、推論的なレポートを作ってしまっているように思います。
別途GPT-4oでも行ってみましたが、こちらは正しい内容をシンプルに出してくれたので、モデルを適切に使い分ける必要がありそうです。
いろいろ考察
ほぼ感想文ですが、実装してみて思ったことをツラツラ書いておきます。
Genieを組み込んだエージェント処理
- 使い勝手は良さそう。量的情報を正確に返してくれるためWeb検索などのエージェントとも組み合わせて使ったり、今回のように複数のGenieスペースエージェントと連携したり、というところで面白いことができそう。
- GenieスペースはDatabricksのUI上で作り込みもできるので、ここでしっかり品質を満たせられれば様々な再利用ができそうです
- Genieは答えられない問いがきたときはシンプルに回答しない傾向があるので、クセを抑えながら使う必要がありそう
実用性
- 今回ぐらいの実装だと実利用はまだ難しそうな印象。ハルシネーション対応も必要ですし、回答内容をプロンプトでもっとコントロールするべきかな。Genieへの問い合わせ内容生成もまだまだ工夫できそう。
- モデルによっては構造化出力が不安定なときもあったりしますし、入力コンテキストサイズの制限なども対応する必要がありますね。
- そもそも今回のような経営レポートは固定観点での分析を行うことが多いので、分析の方向性を絞る対応もいるなど実アプリを考えるとやることが結構多いですね。
- というか、このケースだと素直にGenieだけ使えばいいのでは。。。
マルチエージェントってどう?
- 正直なところ、今回のユースケース・実装だとマルチエージェントである必要はない(というか、今回の利用の仕方はマルチエージェントとは呼べないのでは)と考えています。シンプルにツール呼び出しの制御+ワークフローで事足りそうなので。
- とはいえ、エージェントの連携で問題解決をする考え方は実装レベルでもシンプルな構造を作ることが出来そうですし、適用幅は思ったより広げてもいいのかなと思いました。ただ、まだ個人的知見の不足を感じています。
まとめ
Databricks Genieをエージェントとして利用し、Deep Researchを構築する試験実装を行ってみました。
アイディアとしては珍しいものではないですが、ちゃんと作れば実用性の高いものになる気がしています。
こういうのが普及すると私の仕事は少し楽になるはずなんですが笑
しかし、AIエージェント関連は発展めざましいこともあって楽しいですね。
引き続きアイディアを形にしていってみたいと思います。