はじめに
たまたまDatabricksのサービングモデルを見ていたら埋込モデルとしてdatabricks-qwen3-embedding-0-6bが新たにホスティングされていることに気づきました。
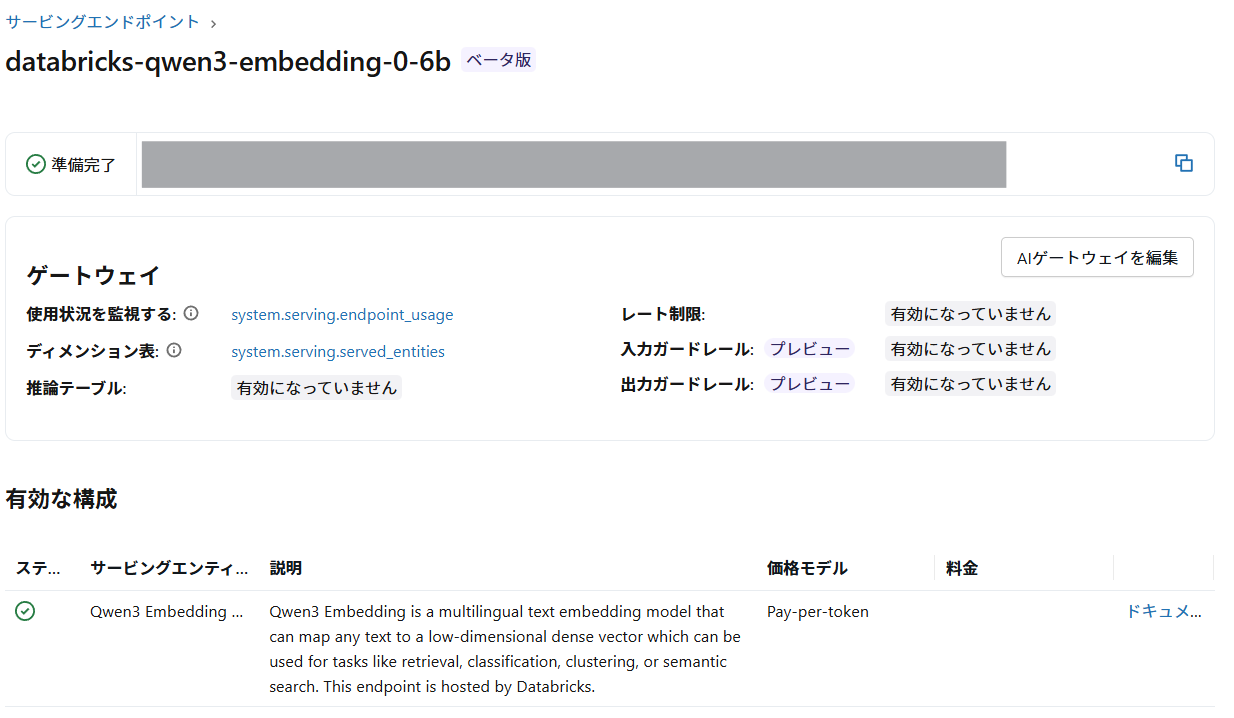
ひとまず触ってみたので検証結果を記載します。
2026年1月31日現在、まだ公式ドキュメントにも記載がなさそうで、公開取り消しや変更がある可能性があります。
なお、画面表記を見るにまだベータサービスのようです。
検証はDatabricks Free Editionで行いました。
Qwen3 Embeddingとは
Qwen3 Embeddingは、アリババ(Alibaba)のQwenチームが開発した多言語対応 (日本語含む) の高性能な埋め込みモデルシリーズです。
Apache 2.0で公開されているオープンウェイトモデルで、HuggingFace等で公開されています。
Qwen3 Embeddingは0.6B、4B、8Bとパラメータサイズ違いで複数公開されていますが、今回Databricksでホスティングされているは名前から見て0.6Bだと思います。
とりあえず触ってみる その1
モデルサービング画面から日本語文字列でクエリを実行してみます。
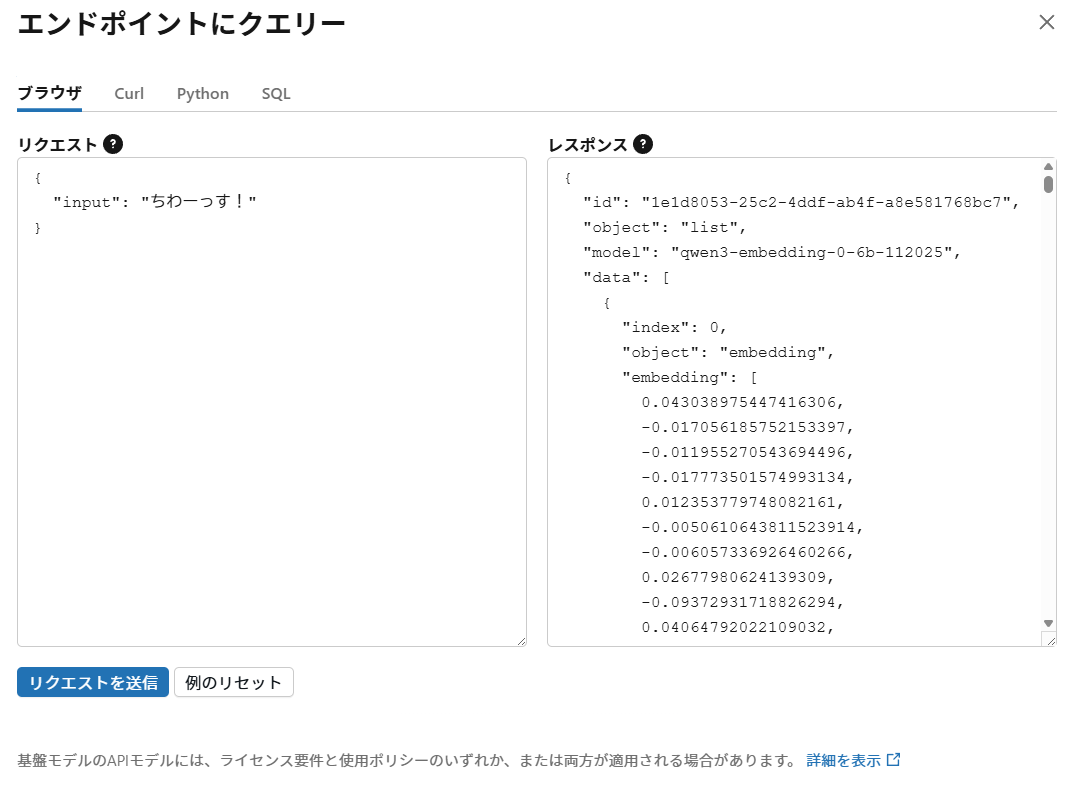
ベクトルに変換できます。ただ、日本語非対応の埋め込みモデルでも変換自体はできるので、適切に変換できているかはここではわかりません。
とりあえず触ってみる その2
というわけで、以下の記事で利用する埋め込みモデルをdatabricks-qwen3-embedding-0-6bに入れ替えてベクトルインデックスを作成してみます。
ベクトルインデックス作成部分のコードは以下のように変更しました。
(ベクトル化するカラムも日本語要約列を指定するようにしています)
import time
def exists_index(client, index_name):
indexes = client.list_indexes(vs_endpoint)
vector_indexes = indexes.get("vector_indexes")
if not vector_indexes:
return False
for index in vector_indexes:
if index.get("name") == index_name:
return True
return False
def wait_for_deletion(client, index_name):
for _ in range(10):
if not exists_index(client, index_name):
return
time.sleep(2)
raise Exception("Timeout waiting for index deletion")
try:
client = VectorSearchClient()
# VectorIndexがすでに存在している場合は削除
if exists_index(client, f"{catalog}.{schema}.{index_name}"):
print(f"index {catalog}.{schema}.{index_name} is already existing.")
print(f"Delete current index: {catalog}.{schema}.{index_name}")
client.delete_index(
index_name=f"{catalog}.{schema}.{index_name}",
endpoint_name=vs_endpoint,
)
wait_for_deletion(client, f"{catalog}.{schema}.{index_name}")
print(f"Deleted index {catalog}.{schema}.{index_name}")
# Indexの作成
index = client.create_delta_sync_index_and_wait(
endpoint_name=vs_endpoint,
source_table_name=f"{catalog}.{schema}.{source_table}",
index_name=f"{catalog}.{schema}.{index_name}",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_model_endpoint_name="databricks-qwen3-embedding-0-6b",
embedding_source_column="summarized_body",
columns_to_sync=[
"id",
"body_head_8000",
"created_at",
"updated_at",
"title",
"url",
"organization_url_name",
"summarized_body",
"en_summarized_body",
"author_id",
"author_name",
"tag_names",
"imported_at",
],
)
except Exception as e:
# 手抜き。ちゃんと実装すること。
print(e)
pass
こちらで作成したインデックスを使って、Playgroundから利用してみます。
「データブリックス」とカタカナ表記で聞いてみました。
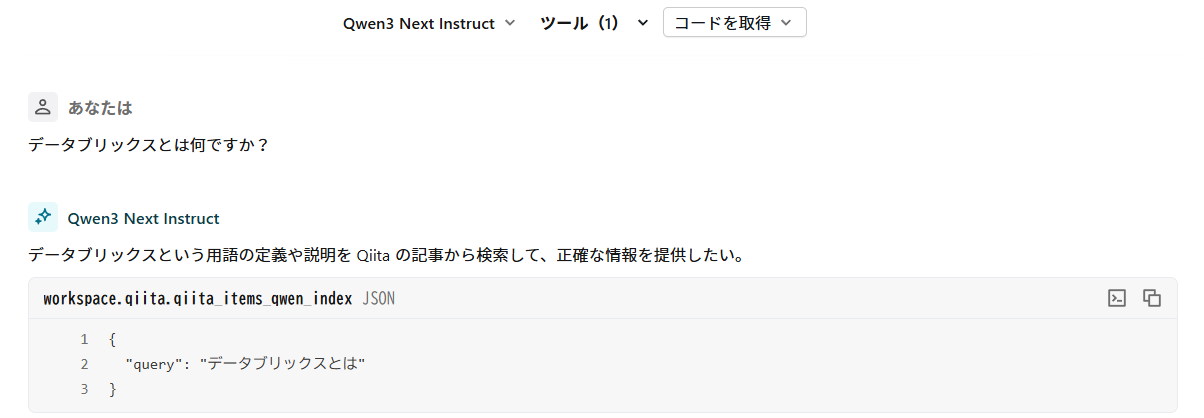
概ね適切な内容が検索されて回答が作られました。

他にもクエリを試してみていますが、概ね日本語の検索もうまくいっているように思います。
まとめ
Databricksで新しくホストされたdatabricks-qwen3-embedding-0-6b埋め込みモデルを利用しました。
これまでDatabricks上では英語埋め込みモデルしかホスティングされておらず、日本語を使いたいときはruri-v3やembeddinggemmaなどのカスタムエンドポイントを用意する必要がありましたが、これで容易に非英語でのベクトル化もできるようになりました。
ますますベクトルストアの使い勝手が上がるので助かります。
とはいえ、以下の記事によればQwen Embedding 0.6Bはそこまで日本語性能は高くないようなので気を付ける必要があります。
やはりここはruri-v3などの日本語特化埋め込みモデルもオフィシャルにホスティングして欲しいところ。
データブリックス・ジャパンの皆様、是非よろしくお願いします!(人任せ)