シリーズ一覧はこちら。
導入
RAPTORという検索用のベクトルデータ構築・検索手法があることを知りましたので、実装・動作検証してみます。
検証はDatabricks on AWSで行いました。
DBRは14.3ML、クラスタのインスタンスタイプはg4dn.xlargeを利用しています。
RAPTORとは何?
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrievalの頭文字でRAPTORらしい)は、RAGシステムの精度を向上させるために、文書検索を正確に行えるようにするための文書構築・検索手法です。
論文はこちら。
こちらのサイトでも日本語で解説されています。
雑な私の理解で言うと、以下のような感じ。
※ 詳しくは上記記事を読まれた方が良いと思います。
- RAGにおける精度改善には、文書検索の正確性が重要
- 一方で、長大な文書をチャンク化してベクトル検索する手法では、取得される文書だけだと意味が細切れになり、文書全体の意味を捉えて回答できない可能性がある
- RAPTORはチャンク化したテキストを類似の意味を持つものでグループ化(クラスタリング)し、その要約文書を新たなチャンクとして生成する
- 要約から作られたチャンクをさらに再帰的にクラスタリング・要約し、最終的に全体としての要約チャンクを作る
- 要約作成したチャンクを含めてベクトル化し、RAGにおける検索は要約チャンク含めて対象にする
これによって細分化された文章だけでなく、より広範な文章を要約した内容も検索対象となり、より適切な検索結果を得られる、という考え方だと認識しています。
今回はLangChainのクックブックとして紹介されている以下のNotebookを魔改造簡易化してウォークスルーしてみます。
処理の流れとしては、上記Notebookに掲載されている下記画像のような流れとなります。

Step1. パッケージインストール
LangChain等の各種パッケージをインストール。
RAPTOR内の要約処理にLLMを利用しますが、推論エンジンにExLlamaV2を利用するため、あわせてそちらを利用するためのパッケージもインストールします。
%pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cu118
%pip install ninja
%pip install -U flash-attn --no-build-isolation
# ExLlamaV2のインストール
%pip install https://github.com/turboderp/exllamav2/releases/download/v0.0.19/exllamav2-0.0.19+cu118-cp310-cp310-linux_x86_64.whl
# LangChain等の最新化
%pip install -U langchain langchain-chroma lm-format-enforcer
%pip install umap-learn langchain_community tiktoken
dbutils.library.restartPython()
Step2. サンプル文書の準備
検索対象の文書データを以下のWikipediaから取得します。
import requests
def get_wikipedia_page(title: str):
"""
Retrieve the full text content of a Wikipedia page.
:param title: str - Title of the Wikipedia page.
:return: str - Full text content of the page as raw string.
"""
# Wikipedia API endpoint
URL = "https://ja.wikipedia.org/w/api.php"
# Parameters for the API request
params = {
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
}
# Custom User-Agent header to comply with Wikipedia's best practices
headers = {"User-Agent": "tutorial/0.0.1"}
response = requests.get(URL, params=params, headers=headers)
data = response.json()
# Extracting page content
page = next(iter(data["query"]["pages"].values()))
return page["extract"] if "extract" in page else None
full_document = get_wikipedia_page("葬送のフリーレン")
取得した文書を、簡易日本語テキストスプリッタを使ったチャンク分割します。
from typing import Any
import requests
from langchain.schema import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
class JapaneseCharacterTextSplitter(RecursiveCharacterTextSplitter):
"""句読点も句切り文字に含めるようにするためのシンプルなスプリッタ"""
def __init__(self, **kwargs: Any):
separators = ["\n\n", "\n", "。", "、", " ", "", "==="]
super().__init__(separators=separators, **kwargs)
# split it into chunks
text_splitter = JapaneseCharacterTextSplitter(chunk_size=400, chunk_overlap=80)
texts_split = text_splitter.split_text(full_document)
texts_split
['『葬送のフリーレン』(そうそうのフリーレン)は、山田鐘人(原作)、アベツカサ(作画)による日本の漫画。『週刊少年サンデー』(小学館)にて、2020年22・23合併号より連載中。\n2021年に第14回マンガ大賞および第25回手塚治虫文化賞新生賞を、2023年に第69回小学館漫画賞受賞。',
(中略)
'== 脚注 ==\n\n\n=== 注釈 ===\n\n\n=== 出典 ===\n\n\n== 外部リンク ==\n漫画\n『葬送のフリーレン』 原作:山田鐘人/作画:アベツカサ | 少年サンデー\n『葬送のフリーレン』公式 (@FRIEREN_PR) - X(旧Twitter)\nテレビアニメ\nアニメ『葬送のフリーレン』公式サイト\n『葬送のフリーレン』アニメ公式 (@Anime_Frieren) - X(旧Twitter)\n葬送のフリーレン - マッドハウス - アニメ制作会社公式サイト']
チャンクの数は129個となりました。
len(texts_split)
## 129
Step3. 埋め込みモデル/LLMの準備
埋め込みモデル
以下の記事で作成した、Databricks Model Serving登録済みの埋め込みモデルをLangChain経由で呼び出す準備をします。
詳細は以下を参照ください。
Databricks Model Servingを利用しない場合は、以下の記事のようにtransformersの埋め込みモデルも利用可能です。適切な方法を選択してください。
from langchain_community.embeddings import DatabricksEmbeddings
endpoint_name = "bge_m3_endpoint "
embd = DatabricksEmbeddings(endpoint=endpoint_name)
LLM
次に、要約に使うLLMをExllamaV2を使ってロードします。
(こちらもLangChainのChatModelが利用できれば他のモデルでもOKです。)
LangChain + LM Format Enforcerを利用するために、下記記事で作成したカスタムクラスを利用します。
モデルは以下をダウンロードして利用しました。
from exllamav2_json_chat import ChatExllamaV2Model
model_path = "/Volumes/training/llm/model_snapshots/models--bartowski--Meta-Llama-3-8B-Instruct-special-tokens-exl2--8_0/"
model = ChatExllamaV2Model.from_model_dir(
model_path,
cache_max_seq_len=8192,
cache_4bit=True,
low_mem=True,
max_new_tokens=512,
temperature=0.0,
top_p=0.5,
system_message_template="<|start_header_id|>system<|end_header_id|>\n\n{}<|eot_id|>",
human_message_template="<|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
)
Step4. RAPTOR処理用の関数定義
ここが今回のポイントです。
RAPTOR処理用の関数群を定義します。
基本的に元Notebookの内容そのままです。
私の雑な理解だと、以下のような流れで処理されます。
- チャンクを埋め込みモデルを使ってベクトル化、その後UMAPを使って次元削減
- 次元削減したベクトルデータを基にGaussian Mixture Models (GMMs)を用いてクラスタリング
- クラスタリングされたチャンク群をLLMを使って要約
- 各クラスタの要約結果を新たなチャンクとして、処理を繰り返し
from typing import Dict, List, Optional, Tuple
import numpy as np
import pandas as pd
import umap
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from sklearn.mixture import GaussianMixture
RANDOM_SEED = 224 # Fixed seed for reproducibility
### --- Code from citations referenced above (added comments and docstrings) --- ###
def global_cluster_embeddings(
embeddings: np.ndarray,
dim: int,
n_neighbors: Optional[int] = None,
metric: str = "cosine",
) -> np.ndarray:
"""
Perform global dimensionality reduction on the embeddings using UMAP.
Parameters:
- embeddings: The input embeddings as a numpy array.
- dim: The target dimensionality for the reduced space.
- n_neighbors: Optional; the number of neighbors to consider for each point.
If not provided, it defaults to the square root of the number of embeddings.
- metric: The distance metric to use for UMAP.
Returns:
- A numpy array of the embeddings reduced to the specified dimensionality.
"""
if n_neighbors is None:
n_neighbors = int((len(embeddings) - 1) ** 0.5)
return umap.UMAP(
n_neighbors=n_neighbors, n_components=dim, metric=metric
).fit_transform(embeddings)
def local_cluster_embeddings(
embeddings: np.ndarray, dim: int, num_neighbors: int = 10, metric: str = "cosine",
) -> np.ndarray:
"""
Perform local dimensionality reduction on the embeddings using UMAP, typically after global clustering.
Parameters:
- embeddings: The input embeddings as a numpy array.
- dim: The target dimensionality for the reduced space.
- num_neighbors: The number of neighbors to consider for each point.
- metric: The distance metric to use for UMAP.
Returns:
- A numpy array of the embeddings reduced to the specified dimensionality.
"""
return umap.UMAP(
n_neighbors=num_neighbors, n_components=dim, metric=metric
).fit_transform(embeddings)
def get_optimal_clusters(
embeddings: np.ndarray, max_clusters: int = 50, random_state: int = RANDOM_SEED
) -> int:
"""
Determine the optimal number of clusters using the Bayesian Information Criterion (BIC) with a Gaussian Mixture Model.
Parameters:
- embeddings: The input embeddings as a numpy array.
- max_clusters: The maximum number of clusters to consider.
- random_state: Seed for reproducibility.
Returns:
- An integer representing the optimal number of clusters found.
"""
max_clusters = min(max_clusters, len(embeddings))
n_clusters = np.arange(1, max_clusters)
bics = []
for n in n_clusters:
gm = GaussianMixture(n_components=n, random_state=random_state)
gm.fit(embeddings)
bics.append(gm.bic(embeddings))
return n_clusters[np.argmin(bics)]
def GMM_cluster(embeddings: np.ndarray, threshold: float, random_state: int = 0):
"""
Cluster embeddings using a Gaussian Mixture Model (GMM) based on a probability threshold.
Parameters:
- embeddings: The input embeddings as a numpy array.
- threshold: The probability threshold for assigning an embedding to a cluster.
- random_state: Seed for reproducibility.
Returns:
- A tuple containing the cluster labels and the number of clusters determined.
"""
n_clusters = get_optimal_clusters(embeddings)
gm = GaussianMixture(n_components=n_clusters, random_state=random_state)
gm.fit(embeddings)
probs = gm.predict_proba(embeddings)
labels = [np.where(prob > threshold)[0] for prob in probs]
return labels, n_clusters
def perform_clustering(
embeddings: np.ndarray,
dim: int,
threshold: float,
) -> List[np.ndarray]:
"""
Perform clustering on the embeddings by first reducing their dimensionality globally, then clustering
using a Gaussian Mixture Model, and finally performing local clustering within each global cluster.
Parameters:
- embeddings: The input embeddings as a numpy array.
- dim: The target dimensionality for UMAP reduction.
- threshold: The probability threshold for assigning an embedding to a cluster in GMM.
Returns:
- A list of numpy arrays, where each array contains the cluster IDs for each embedding.
"""
if len(embeddings) <= dim + 1:
# Avoid clustering when there's insufficient data
return [np.array([0]) for _ in range(len(embeddings))]
# Global dimensionality reduction
reduced_embeddings_global = global_cluster_embeddings(embeddings, dim)
# Global clustering
global_clusters, n_global_clusters = GMM_cluster(
reduced_embeddings_global, threshold
)
all_local_clusters = [np.array([]) for _ in range(len(embeddings))]
total_clusters = 0
# Iterate through each global cluster to perform local clustering
for i in range(n_global_clusters):
# Extract embeddings belonging to the current global cluster
global_cluster_embeddings_ = embeddings[
np.array([i in gc for gc in global_clusters])
]
if len(global_cluster_embeddings_) == 0:
continue
if len(global_cluster_embeddings_) <= dim + 1:
# Handle small clusters with direct assignment
local_clusters = [np.array([0]) for _ in global_cluster_embeddings_]
n_local_clusters = 1
else:
# Local dimensionality reduction and clustering
reduced_embeddings_local = local_cluster_embeddings(
global_cluster_embeddings_, dim
)
local_clusters, n_local_clusters = GMM_cluster(
reduced_embeddings_local, threshold
)
# Assign local cluster IDs, adjusting for total clusters already processed
for j in range(n_local_clusters):
local_cluster_embeddings_ = global_cluster_embeddings_[
np.array([j in lc for lc in local_clusters])
]
indices = np.where(
(embeddings == local_cluster_embeddings_[:, None]).all(-1)
)[1]
for idx in indices:
all_local_clusters[idx] = np.append(
all_local_clusters[idx], j + total_clusters
)
total_clusters += n_local_clusters
return all_local_clusters
### --- Our code below --- ###
def embed(texts):
"""
Generate embeddings for a list of text documents.
This function assumes the existence of an `embd` object with a method `embed_documents`
that takes a list of texts and returns their embeddings.
Parameters:
- texts: List[str], a list of text documents to be embedded.
Returns:
- numpy.ndarray: An array of embeddings for the given text documents.
"""
text_embeddings = embd.embed_documents(texts)
text_embeddings_np = np.array(text_embeddings)
return text_embeddings_np
def embed_cluster_texts(texts):
"""
Embeds a list of texts and clusters them, returning a DataFrame with texts, their embeddings, and cluster labels.
This function combines embedding generation and clustering into a single step. It assumes the existence
of a previously defined `perform_clustering` function that performs clustering on the embeddings.
Parameters:
- texts: List[str], a list of text documents to be processed.
Returns:
- pandas.DataFrame: A DataFrame containing the original texts, their embeddings, and the assigned cluster labels.
"""
text_embeddings_np = embed(texts) # Generate embeddings
cluster_labels = perform_clustering(
text_embeddings_np, 10, 0.1
) # Perform clustering on the embeddings
df = pd.DataFrame() # Initialize a DataFrame to store the results
df["text"] = texts # Store original texts
df["embd"] = list(text_embeddings_np) # Store embeddings as a list in the DataFrame
df["cluster"] = cluster_labels # Store cluster labels
return df
def fmt_txt(df: pd.DataFrame) -> str:
"""
Formats the text documents in a DataFrame into a single string.
Parameters:
- df: DataFrame containing the 'text' column with text documents to format.
Returns:
- A single string where all text documents are joined by a specific delimiter.
"""
unique_txt = df["text"].tolist()
return "--- --- \n --- --- ".join(unique_txt)
def embed_cluster_summarize_texts(
texts: List[str], level: int
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
Embeds, clusters, and summarizes a list of texts. This function first generates embeddings for the texts,
clusters them based on similarity, expands the cluster assignments for easier processing, and then summarizes
the content within each cluster.
Parameters:
- texts: A list of text documents to be processed.
- level: An integer parameter that could define the depth or detail of processing.
Returns:
- Tuple containing two DataFrames:
1. The first DataFrame (`df_clusters`) includes the original texts, their embeddings, and cluster assignments.
2. The second DataFrame (`df_summary`) contains summaries for each cluster, the specified level of detail,
and the cluster identifiers.
"""
# Embed and cluster the texts, resulting in a DataFrame with 'text', 'embd', and 'cluster' columns
df_clusters = embed_cluster_texts(texts)
# Prepare to expand the DataFrame for easier manipulation of clusters
expanded_list = []
# Expand DataFrame entries to document-cluster pairings for straightforward processing
for index, row in df_clusters.iterrows():
for cluster in row["cluster"]:
expanded_list.append(
{"text": row["text"], "embd": row["embd"], "cluster": cluster}
)
# Create a new DataFrame from the expanded list
expanded_df = pd.DataFrame(expanded_list)
# Retrieve unique cluster identifiers for processing
all_clusters = expanded_df["cluster"].unique()
print(f"--Generated {len(all_clusters)} clusters--")
# Summarization
template = """これは葬送のフリーレンに関するWikipediaの内容です。以下のドキュメントの詳細なサマリを400字以内で日本語出力してください。出だしの文は不要です。
ドキュメント:
{context}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model.bind(stop=["<|eot_id|>"]) | StrOutputParser()
# Format text within each cluster for summarization
summaries = []
for i in all_clusters:
df_cluster = expanded_df[expanded_df["cluster"] == i]
formatted_txt = fmt_txt(df_cluster)
summaries.append(chain.invoke({"context": formatted_txt}))
# Create a DataFrame to store summaries with their corresponding cluster and level
df_summary = pd.DataFrame(
{
"summaries": summaries,
"level": [level] * len(summaries),
"cluster": list(all_clusters),
}
)
return df_clusters, df_summary
def recursive_embed_cluster_summarize(
texts: List[str], level: int = 1, n_levels: int = 3
) -> Dict[int, Tuple[pd.DataFrame, pd.DataFrame]]:
"""
Recursively embeds, clusters, and summarizes texts up to a specified level or until
the number of unique clusters becomes 1, storing the results at each level.
Parameters:
- texts: List[str], texts to be processed.
- level: int, current recursion level (starts at 1).
- n_levels: int, maximum depth of recursion.
Returns:
- Dict[int, Tuple[pd.DataFrame, pd.DataFrame]], a dictionary where keys are the recursion
levels and values are tuples containing the clusters DataFrame and summaries DataFrame at that level.
"""
results = {} # Dictionary to store results at each level
# Perform embedding, clustering, and summarization for the current level
df_clusters, df_summary = embed_cluster_summarize_texts(texts, level)
# Store the results of the current level
results[level] = (df_clusters, df_summary)
# Determine if further recursion is possible and meaningful
unique_clusters = df_summary["cluster"].nunique()
if level < n_levels and unique_clusters > 1:
# Use summaries as the input texts for the next level of recursion
new_texts = df_summary["summaries"].tolist()
next_level_results = recursive_embed_cluster_summarize(
new_texts, level + 1, n_levels
)
# Merge the results from the next level into the current results dictionary
results.update(next_level_results)
return results
Step5. RAPTORによるチャンクデータ作成
では、Step4.で定義した関数を使ってRAPTORによる新たなチャンクデータ生成を行います。
実行前に、GMMsの処理がロギングされないようにmlflowのautologgingを無効化。
import mlflow
mlflow.autolog(disable=True)
では、実行。今回は3階層のチャンクとなるようにします。
# Build tree
leaf_texts = texts_split
results = recursive_embed_cluster_summarize(leaf_texts, level=1, n_levels=3)
--Generated 17 clusters--
--Generated 4 clusters--
--Generated 1 clusters--
出力メッセージから、129個あったチャンクは最初に17個のクラスタでグループ化されたことがわかります。
その後、各クラスタごとに要約文書が作成され、その要約文書がさらに4個にクラスタリング・要約という流れとなります。
生成された要約文書を確認してみましょう。
import pandas as pd
# 1回目のクラスタリング要約文書
display(pd.DataFrame(results[1][1]))
# 2回目のクラスタリング要約文書
display(pd.DataFrame(results[2][1]))
# 最終の要約文書
display(pd.DataFrame(results[3][1]))
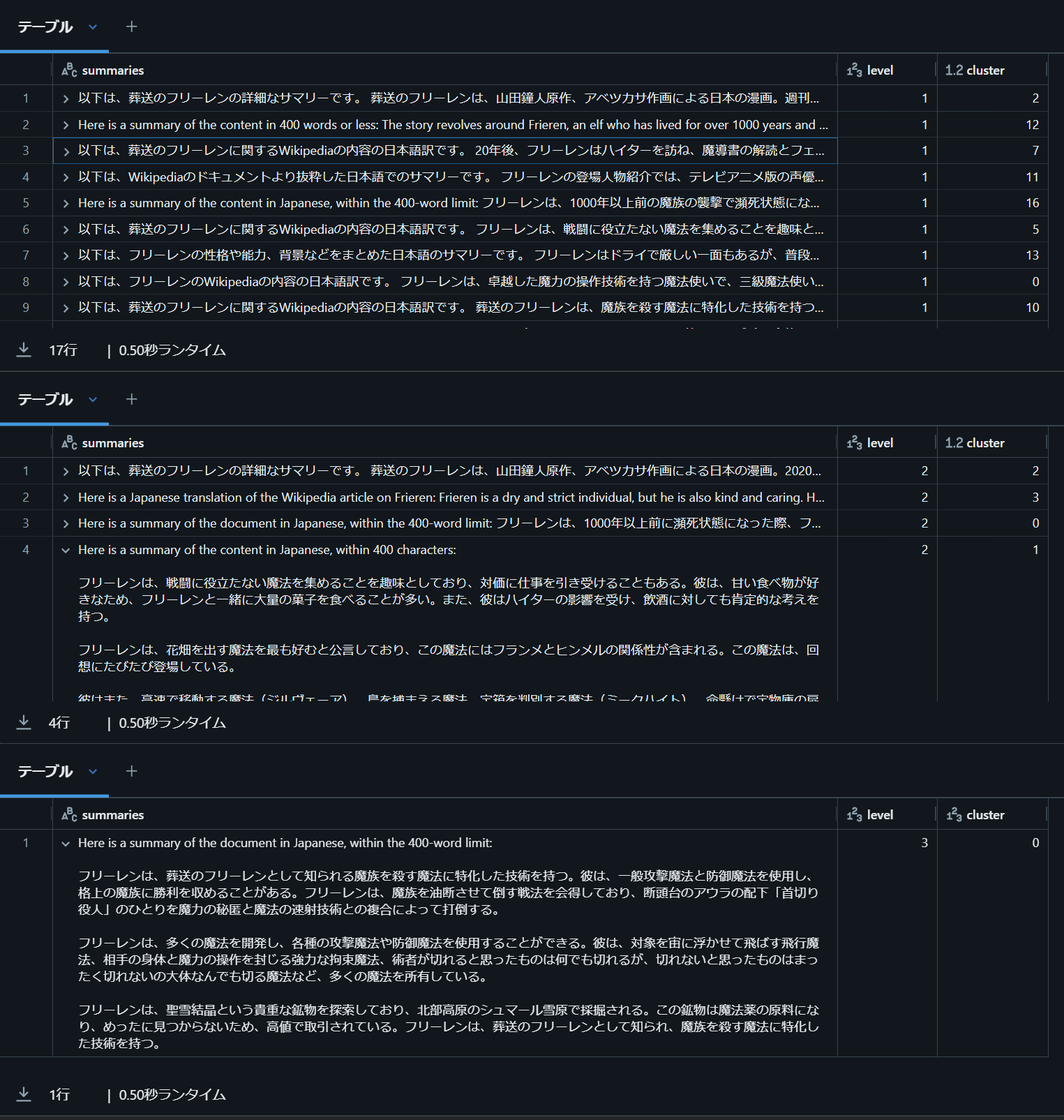
一部、英語のものもありますが、なんとなく要約された文書ができているようです。
このあたりはプロンプトを詰めて、よりよい要約文書ができるようにした方がよいですね。今回は割愛します。
Step6. ベクトルストア/Retrieverの作成
RAPTORを使って作成したチャンクを用いてベクトルストアを作成します。
from langchain_community.vectorstores import Chroma
# 元文書から作成した詳細なチャンクデータをコピー
all_texts = leaf_texts.copy()
# 要約で生成したチャンクを、all_textsに追加
for level in sorted(results.keys()):
summaries = results[level][1]["summaries"].tolist()
all_texts.extend(summaries)
# Chromaを使ってベクトルストアを作成
vectorstore = Chroma.from_texts(texts=all_texts, embedding=embd)
# 10件の類似文書を検索するRetrieverを取得
retriever = vectorstore.as_retriever(search_type="mmr", search_kwargs={"k": 10})
これでRAPTORを使ったRetrieverを準備することができました。
Step7. 検索してみる
では、検索してみましょう。
from pprint import pprint
relevant_docs = retriever.get_relevant_documents("ザインはどういった性格の人間?")
pprint(relevant_docs)
[Document(page_content='アイゼンから「とんでもない戦士になる」と言わしめるほどの素質の持ち主で、フェルンからは化け物かと疑われるほどの膂力と頑強さをもつ。男性に免疫がないフェルンからは無意識な恐れを抱かれ、自身も女性の扱いが苦手な一方で、互いに憎からぬ感情を抱いており、不機嫌になったフェルンに謝罪したり、デートのように連れ歩いたりするさまから、ザインからは「もう付き合っちゃえよ」などと漏らされている。男性の象徴に対する評価は芳しくなく、「服が透けて見える魔法」で自身の下半身を見たフェルンからは「ちっさ」と漏らされて傷つく場面がある。好物は自身の誕生日にアイゼンがふるまってくれるハンバーグ。\nザイン (Sein)\n声 - 中村悠一、川井田夏海(幼少期)'),
Document(page_content='ザイン (Sein)\n声 - 中村悠一、川井田夏海(幼少期)\nアルト森林近くの村に住んでいた僧侶。フリーレンを除いたパーティーでは最年長で、酒・タバコ・ギャンブル・年上のお姉さんといった俗なものを愛好する破戒僧であるが、シュタルクが罹った、蛇から媒介され脳が数時間で溶けて死ぬという不治の毒を一瞬で治療するほどの技能をもつ。'),
Document(page_content='アイゼン (Eisen)\n声 - 上田燿司\nドワーフ族出身の戦士。エルフほどではないが人間よりははるかに長命で、ヒンメルやハイターの死後も容姿の変化があまり見られない。非常に頑強な肉体をもち、過去に竜を昏倒させるほどの猛毒の矢を受けても平気でいたり、自由落下程度ならどんな高さから落ちても無傷な姿を見せた際はハイターを驚かせた。魔族からも「人類最強の戦士」として名を知られるほどだが、本人は「俺より強いやつが皆先に死んだだけ」と自らを評する。フリーレンとの再会時も超人ぶりを発揮する一方で、肉体は着実に細く老化しつつあり、ヒンメルの死後にフリーレンから再度同行を請われた際は「もう斧を振れる歳じゃない」と拒否する。'),
Document(page_content='Here is a Japanese translation of the Wikipedia article on Frieren:\n\nFrieren is a dry and strict individual, but he is also kind and caring. He values magic books highly and can be reckless at times. As an elf who has lived for over 1,000 years, he has difficulty communicating with humans and other short-lived species. He has a strong hatred for demons and will not hesitate to kill them without hesitation.\n\nHe trusts powerful mages and likes talented individuals, but he is not fond of everyday magic or peaceful magic. He has deep affection for his disciples and remembers their personalities and favorite magic techniques clearly.\n\nFrieren possesses immense magical power, as evidenced by his ability to easily defeat Mahat, a golden land mage, and dismiss Frans as a failure. He is a disciple of Frans and is an elf, characterized by his long lifespan. Elves have a tendency to lose interest in romantic emotions and reproduction, which may lead to extinction.\n\nIn addition, Frieren is a skilled mage who passed the third-level mage exam at the age of 15, making him the youngest mage to do so. Zenze praised him, saying "I\'ve never seen a mage like you, even among those who are older." He was scouted by big mage Zeerie, who saw his potential and became his mentor. Frieren has many talents, including magic concealment, rapid casting, and large-scale attack magic, as well as super-long-range shooting skills.\n\nAs a child, Frieren learned magic from Mahat in the Golden Land and became fascinated with magic. He is always calm and cooperative, with excellent insight and strategic thinking, but also has a hot-headed side that makes him want to fight when his magic runs out.\n\nFrieren became a first-class mage of the Continental Magic Association, but Zeerie teased him, calling him "a cowardly young man." However, Zeerie recognizes Frieren\'s strength and says, "It\'s a shame that someone with such great talent doesn\'t leave any achievements behind before dying." Frieren refused to engage in a duel with Zeerie, saying it would be a waste of time.'),
Document(page_content="Here is a summary of the content in 400 words or less:\n\nThe story revolves around Frieren, an elf who has lived for over 1000 years and is part of a group of heroes who defeated the demon king. After the death of her friend Himmel, Frieren decides to travel the world to learn more about humans and magic. She meets various characters, including Fern, a strong warrior with a complex personality, Sein, a priest who is also a bit of a troublemaker, and Eisen, a dwarf warrior who is extremely strong.\n\nAs Frieren travels, she reflects on her past and her relationships with her friends, particularly Himmel. She realizes that she never really got to know him as a person and is filled with regret. Throughout her journey, Frieren encounters various magical creatures and learns new spells, but she also faces challenges and dangers along the way.\n\nMeanwhile, back in their hometown, the other members of the hero party are dealing with their own struggles. Fern is struggling to come to terms with his feelings towards women, while Sein is trying to balance his love of luxury with his duties as a priest. Eisen, meanwhile, is grappling with his own mortality and the fact that he is no longer as strong as he once was.\n\nThroughout the story, Frieren's character is developed through her interactions with these characters and her own reflections on her past. The story explores themes of friendship, regret, and self-discovery, and features a unique blend of fantasy and adventure elements."),
Document(page_content='底なし沼にはまり動けなくなっていたところをフリーレンに助けられる。少年時代から冒険者となることにあこがれていたが、10年前に親友の「戦士ゴリラ」が先に旅立ってからも、兄への配慮から村にとどまり、友の帰りを待ち続けていた。その真意を知った兄から叱責されて、フリーレンの仲間に加わる。旅中では大人の立場としてフェルンとシュタルクの仲を取り持つこともあり、もう互いに二人が付き合うべきではないかと悩んだりする。探す友が交易都市テューアに向かったことを知ると、彼を追いかけるため一行から離脱。のちにフリーレンがメトーデから僧侶枠として同行しようかと聞かれた際は、「このパーティーの僧侶の席は(ザインのために)空けておきたいから」と断っている。'),
Document(page_content='ハイター (Heiter)\n声 - 東地宏樹\n人間出身の僧侶。戦災孤児で、ヒンメルとは同郷の幼なじみ。魔王討伐後は聖都の司教となり、偉大な僧侶として人々の尊敬を集めた。穏やかで明るい性格だが、お酒が大好きな生臭坊主。大酒飲みであったにも関わらず、ヒンメルの死後も20年以上に渡り生き続けるなど人間としてはかなりの長寿を保った。ただし、晩年は体調を崩したこともあって酒を絶った様子である。\n最晩年、戦災孤児であるフェルンを引き取り、訪ねてきたフリーレンにちょっとした計略をしかけてフェルンを彼女の弟子として託すことで、自分の死後の悩みを解決した。かつては自身が孤児だったことから、孤児院の復興資金をみずから捻出したこともあった。その存在は、フェルンにとって「育ての親」として死後も大切なものとなっている。ザインからも、ハイターは自分と違って優しく頼りがいのある理想的な大人だったと評される。'),
Document(page_content='以下は、葬送のフリーレンに関するWikipediaの内容の日本語訳です。\n\n20年後、フリーレンはハイターを訪ね、魔導書の解読とフェルンの教育を依頼した。4年後、フリーレンとフェルンは、高齢のハイターの最期を看取った後、諸国をめぐる旅に出た。フリーレンたちは、アイゼンの助力を受けて、フランメの手記を入手した。この手記には、オレオールという死者の魂と対話できる場所があることが記されていた。\n\nフリーレンは、新たな目的を持って北方を目指し、アイゼンの弟子であるシュタルクや、行方不明の親友との再会を望む僧侶ザインを加えた。フェルンは、9歳から19歳までの間に魔法を学び、ハイターの弟子となった。彼女は、時間感覚が人間とかけ離れており、魔法以外の生活水準が低過ぎるため、フリーレンやシュタルクからは恐れられていた。\n\nザインは、10年前に親友の「戦士ゴリラ」が先に旅立って以来、兄への配慮から村にとどまっていた。しかし、真意を知った兄から叱責されて、フリーレンの仲間に加わった。旅中では、フェルンとシュタルクの仲を取り持つこともあったが、もう互いに二人が付き合うべきではないかと悩んだりすることもあった。\n\nまた、ザインは、家族を魔族に殺された過去やドワーフ族独特の死生観の影響からか、かつてはヒンメルとともに歩んだちゃらけた旅の道行きを「くだらない」と切って捨てることもあったが、魔王討伐後は仲間思いの一面を見せており、オレオールでフリーレンとヒンメルが再会できることを願っていた。'),
Document(page_content='シュタルクとの共闘により神技のレヴォルテと対峙、重傷を負いながらも死闘を制す。傷はメトーデの回復魔法によって治癒する。\nゼンゼ\n声 - 照井春佳\n一級魔法使いの女性で、ゼーリエの側近のひとり。一級魔法使いの第二次試験の試験官を務める。受験者同士の争いや無碍に死傷者が出ることを好まない自称・平和主義者であるが、受験者全員での一体的な協力・共闘を合格の重要な鍵とするような内容の試験を実施するため、過去に担当した4回の試験では一人の合格者も出していなかった。それゆえに今回担当した試験では、突出した実力者であるフリーレンが受験したために課題を突破され、逆に多過ぎる数の合格者を出したことでゼーリエの介入を招く。'),
Document(page_content='フリーレンたちが受験した一級魔法使いの三次試験では急きょ試験官を務め、直感により受験者に合否を下す。これまで数多く人間の弟子を取ったが、皆ゼーリエの足元にも及ばないまま先立っていったとのこと。\nゲナウ\n声 - 新垣樽助\n魔法都市オイサーストの一級魔法使いの男性で、第一次試験の試験官を務める。一級魔法使いの価値を重んじて受験者に過酷な試験を課し、多くの死傷者が出ても悪びれる様子はまったくない。常より不敵で冷徹な言動が目立つ。\nゼーリエから北部高原の魔族討伐を命じられメトーデと行動をともにし、故郷が魔族に滅ぼされたさまを目の当たりにした。攻防とも強力な黒金の翼を操る魔法(ディガドナハト)を使い、魔法使いながら接近戦を得意とする。\nシュタルクとの共闘により神技のレヴォルテと対峙、重傷を負いながらも死闘を制す。傷はメトーデの回復魔法によって治癒する。\nゼンゼ\n声 - 照井春佳')]
最初に作成したチャンクだけではなく、要約で生成されたチャンクも検索結果としてひっかかりました。
このように、分断されない意味を含んだチャンクを取得できる、というのがRAPTORのメリットです。
・・・ただ、今回の例だとイマイチですね。
もともとWikipediaはある程度構造化された文書なので、適切に構造化された形でチャンク化するほうがいいと思いますし、今回のケースだとParent Child Retrieverのような親子関係をもって中規模なチャンクを取得するほうがよい結果を生むのではないかと思います。
まとめ
結果としてあまりいい例を作れませんでしたが、事前に要約チャンクを作って検索精度を向上するという工夫は応用が利きそうな手法だと思います。
うまくユースケースにはまれば、検索精度の向上につながりそうだと感じました。