はじめに
私はIoT.kyotoというIoTに関するサービス(こんなサービス)の開発をしている開発者の一人です。
IoT.kyotoというサービスがリリースされて早2年近く経ちました。そんな中でIoTで扱うデータとどうすれば仲良くなれるのかを日々模索していく中感じていることと、最近データ量について考えることが多くなってきたので、いろんな視点から考えてみようと思います。
※ 私の経験則で書いている部分もありますので、記事全般的に異論は認めます。
※ 結果的にSORACOMとAWS推しの記事になってしまいましたがご了承ください…
プロトコル
私が携わっているIoT案件ではAWS上にデバイスからのセンサーデータを溜め込むことがほとんどなのですが、デバイスからセンサーデータをAWSに送信する際にかならず何かしらのプロトコルを通らなければいけません。代表的なプロトコルについて見ていこうと思います。
HTTP
一番代表的なプロトコルだと思います。
とあるURLに対してリクエストを送信して、そのBodyにセンサーのデータなどを持たせます。
APIGatewayのエンドポイントに直接リクエストを送信したりだったりとか、Fluentdにデータを食わせて、SORACOMFunnelやBeamのエンドポイントにリクエストを送信したりだとかしていますね。
また、AWSのサービスのエンドポイントに直接リクエストを送信しようとなると、基本的にHTTPSで待ち受けているので、認証情報をHeaderに乗っけないといけません。なので、一気にデバイス側のハードルが高くなってしまいます。そんなときにSORACOMさんのサービスを活用すれば、SORACOMまでは閉域網で通信を行い、認証情報はSORACOM側で付与してくれるので、デバイス側のハードルを一気に下げてくれます。
HTTPRequestBodyの上限は基本的にリクエストを受け取る側で設定されているものではないのかなと思ってます。(違ったらごめんなさい)
ちなみにBodyが大きすぎると 413 Payload Too Large というレスポンスが返ってきます。
MQTT
デバイスからの上り通信、デバイスへの下り通信ができます。
送信することを Publish 、受信することを Subscribe といいます。
あるトピックでSubscribeしている状態に対して、同じトピックにPublishするとデータが届くといった感じです。
AWSIoTを使ってMQTT通信をすることが多いです。AWSIoTのメッセージブロガー MQTT バージョン 3.1.1 を基準として開発されていますが、仕様通りになっていない部分もあるので注意が必要です。(参考サイト)
MQTTの最大メッセージサイズは 256MB となっています。
これ以上のメッセージをPublishする場合は分割して送信しなければいけません。
詳しい仕様はこちら
DB
データを溜め込むDBの負荷について考えていこうと思います。
AWSには Amazon DynamoDB というNoSQLDBがあります。RDBMSに比べて秒単位でのデータの保存、取得、編集に向いています。
今回はDynamoDBのRead/Writeキャパシティについて考えていくことにします。
Read/Writeキャパシティとは?
テーブルのスループットのことです。各キャパシティを調整しないと、キャパシティを超えた処理を受け付けなくなり、データを読み込み/書き込みができなくなってしまいます。(参考サイト)
各テーブルにキャパシティをオートスケールするように設定することができますが、オートスケール後の数値が反映されるまで数分かかります。瞬時に変更がかかるというわけではありません。また、キャパシティを下げる回数には上限があり基本的に1日に4~8回しか下げる操作を行うことができません。ですのでDynamoDBのスループットは可能な限り、十分な値を設定しておくのが無難かと思います。
オートスケールどれくらいで適用されるのか、ちょっと試してみた
KinesisDataStreams → Lambda → DynamoDB というルートで約800件×3のテキストデータを投げてみました。どれくらいでオートスケールが適用されるのかを見たいと思います。
↓データを送信した時のWriteキャパシティの遷移。赤線がキャパシティの数値、青線が実際の書き込み量↓
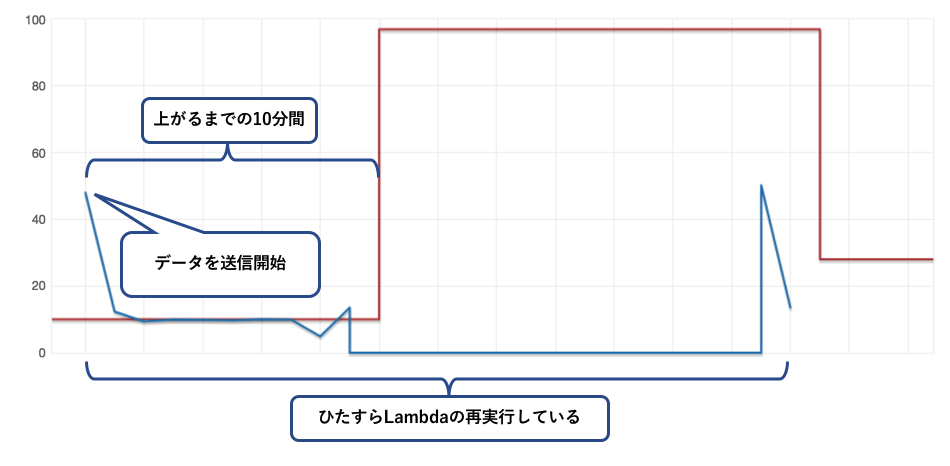
左端の送信し始めた時にオートスケールのトリガーが実行され、実際にキャパシティの値が上がるまで約10分かかっていました。
その間KinesisDataStreamsがデータを保持してくれているので、Lambdaからerrorがcallbackで返されると保持しているデータで再度Lambdaを実行しています。
KinesisDataStreamsがいなければ、Lambdaで実行が失敗するとデータが欠落することになります。DBのキャパシティ不足でのエラーや、予期せぬデータが投げられて来たときのエラーの影響で正常なデータを欠落させないという対応が必要です。
その他サービス
デバイスからデータを送信するのに、例えば送信経路に SORACOM のサービスを使ったり、AWS側のデータを取得してからの経路につかうサービスを使ったりします。よく使っているサービス等について考えていこうと思います。
SORACOM Funnel
株式会社ソラコムのサービスの一つ。
以下抜粋。 (https://soracom.jp/services/funnel/)
SORACOM Funnel(以下、Funnel) は、デバイスからのデータを特定のクラウドサービスに直接転送するクラウドリソースアダプターです。
Funnel でサポートされるクラウドサービスと、そのサービスの接続先のリソースを指定するだけで、データを指定のリソースにインプットすることができます。
アダプターを利用して各クラウドサービスにデータを転送してくれます。
また前述にも書きましたが、SORACOMコンソールでAWSのクレデンシャルを登録しておくと、AWSへの認証情報(SigV4)生成してHTTPヘッダーに付与してくれます。
センサー側にクレデンシャル等の情報を持たなくても済むので、デバイスを紛失してもクレデンシャル情報が漏れることはありません。
また、クレデンシャル情報が変更(アクセスキー等の書き換え)されたとしても、SORACOMのコンソール画面で変更するだけで良いので、運用面でも効率化を測れます。
ちなみにFunnel側でデータ量(リクエストの文字数)の制限があるようで、実証実験の結果、 80万バイト(≒800KB)までだそうです。
SORACOM Beam
こちらもSORACOM社のサービスの一つ。
以下抜粋。 (https://soracom.jp/services/beam/)
SORACOM Beam(以下、Beam)は、IoT デバイスにかかる暗号化等の高負荷処理や接続先の設定を、クラウドにオフロードできるサービスです。
Beam を利用することによって、クラウドを介していつでも、どこからでも、簡単に IoT デバイスを管理することができます。
大量のデバイスを直接設定する必要はありません。
私の場合の話になるのですが、Funnelとの使い分けは バイナリデータを扱うか否か という点です。
基本的にHTTPでリクエストを送信する都合上、Funnelにバイナリを投げつけることは現時点(2018/03/12時点)ではできません。
その場合にBeamを利用してAPIGateway経由でKinesisDataStreamsなりLambdaなりに投げつけます。
(私も記事を書いてますので参考までに)
BeamもFunnelのようにデータ量の制限があるのかなと思って実験して見たのですが、約10MBの画像データを投げつけたところBeamは問題なく受け取ったので、特に気にしなくてもいいのかなーと勝手に思ってます。
Amazon Kinesis Data Streams
ストリームデータをAWSの他サービスへ流してくれる優れもの。
シャードという単位でデータ処理を分割して流してくれます。また、データを最大1週間保持してくれますので、一度のエラーでデータが欠落することはありません。
ただ、思わぬところで後のLambda処理がこけて、ひたすら再実行を繰り返し、DynamoDBのキャパシティを食いつぶしていた。なんて事件もありましたが…
Amazon API Gateway
RESTフルなAPIの受け口となるサービス。
APIGatewayのエンドポイントに対してGETやPOSTなどのリクエストごとに、設定することができます。後の処理にLambdaを実行させることでテーブルの操作を行ったり、S3に格納したりすることができます。
AWSのサービスなので基本的にHTTPSで待ち受けています。なので認証情報(SigV4)を生成しなければいけませんが、OSを積んでいないなどの非力なデバイスでは認証情報を生成することができないなどの制約があります。その場合APIGatewayにAPIキーを生成して有効化しておきます。そのキーをヘッダーに埋め込んで認証することも可能です。( 注:AWS側からは非推奨とアナウンスされています )
ちなみにAPIGatewayにはPayload上限というものがあり、一度のリクエストで受け取ることができるPayloadは10MBまでとなっています。
AWS IoT
MQTTを利用してデバイスとのやりとりをする場合に利用します。 (AWSIoT自身はHTTPのプトロコルも対応しています。)
デバイスごとに証明書を発行・紐つけすることができ、その証明書ベースで認証させることができます。
デバイスからのPublishを受け取ったトピックごとに、後の処理を仕分けることができます。またAWSIoT経由でデバイスにメッセージを送信することもできます。
AWS Lambda
このサービスは超優秀なサービスです!(贔屓目ですが…)
基本的にデバイスから受け取ったデータを、DBに格納するための加工をする段階で使います。
言語がNode.jsだったり、Pythonだったり、最近ではGoにも対応しました。
ただ気をつけないといけないのが、Lambdaで様々なことができるあまりに、一つのLambdaに様々な役割を持たせてしまうことです。
Lambdaはなるべく小さな単位のタスクをさせておく方が処理が単純化しますし、デバックのしやすさにも繋がります。
またLambdaの最大実行時間が5分となっているので、それ以上かかりそうな処理は物理上できません。そういう意味でも一つのLambdaで複雑かつ様々な処理を持たせるべきではないと思っています。
さいごに少しだけデータ量の話をしましょう
IoTのデータ処理については前述に書いたようなことを毎日考え、模索している状態です。
そんな中、最近よく気になるようになってきたのが、データ量の話です。
データ量は直接通信量などにも絡んできますので、お客様も敏感になる点ではないかなと思います。
今までは基本的にストリームデータを扱ってきましたので、1回のメッセージ量は対したことないのが一般的でしたし、そういうパターンが多いのではないかなと思います。
ですがその一方で、一度に数百、数千件のデータを送信してくるというデバイスもあります。
前述にも書きましたが、データを処理する中で利用するプロトコルやサービスにはデータ量の制限が設けられていることが多いです。
単純にいつも通りの方法で実装していると、このような制限に引っかかってくることがあったりするので、一概に決まったパターンで実装できるとは限りません。
上記の制限に気づいたのも、実証している中で見つけたものが多くあります。
デバイスやセンサーごとに個性があるので、それぞれの実証実験が必要なのではないかなと思います。
ではまた!