やりたかったこと
BigQuery で高コストなクエリを検知したい。
高コストなクエリとは
- データスキャンが多く、課金額が高いクエリ
- スロット使用量が多く、BigQuery Flat-rate の場合にプロジェクト全体のスロットを食いつぶしてしまうクエリ
できたもの

Terraform でコマンドポチーで構築できるようにしました。
やったこと
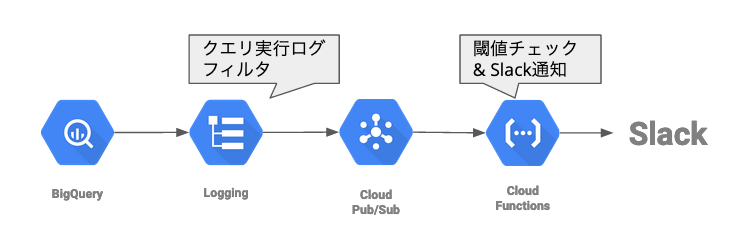
BigQueryのログを Cloud PubSub 経由で Cloud Functionsに流し、クエリの統計情報からしきい値を超えた場合にSlackに通知するようにしました。
レシピ
Terraform と Python で構築していきます。
ファイル構成
.
├── infrastructure
│ └── terraform
│ ├── main.tf
│ ├── provider.tf
│ ├── variables.tf
│ └── versions.tf
└── src
├── config.py
└── main.py
Terraform
まずは変数とプロバイダー定義。
変数定義
############
## Variables
############
variable project_id {
type = string
}
variable region {
type = string
default = "us-central1"
}
# GCP resource name prefix
variable module_name {
type = string
default = "bq-police"
}
variable slack_webhook_url {
type = string
}
Terraformプロバイダー定義
provider google {
project = var.project_id
region = var.region
version = "3.37.0"
}
BigQuery のログを受け取る Cloud PubSub と、ログを流すログシンクを設定をしていきます。
#####################
# log sink to pubsub
#####################
resource "google_logging_project_sink" "log_sink" {
name = var.module_name
destination = "pubsub.googleapis.com/${google_pubsub_topic.log_sink.id}"
filter = <<-EOF
resource.type="bigquery_resource"
protoPayload.methodName="jobservice.jobcompleted"
protoPayload.serviceData.jobCompletedEvent.eventName="query_job_completed"
EOF
unique_writer_identity = true
}
resource "google_pubsub_topic" "log_sink" {
name = var.module_name
}
resource "google_pubsub_topic_iam_member" "log_sink" {
project = google_pubsub_topic.log_sink.project
topic = google_pubsub_topic.log_sink.name
role = "roles/editor"
member = google_logging_project_sink.log_sink.writer_identity
}
BigQueryのログは様々あるのですが、ここでは実行完了したクエリの統計情報が入っているログをとりたいので、フィルターを以下のように設定しています。
resource.type="bigquery_resource"
protoPayload.methodName="jobservice.jobcompleted"
protoPayload.serviceData.jobCompletedEvent.eventName="query_job_completed"
次に、PubSub から起動するCloud Functions の設定を書いていきます。
Cloud Functions のソースコードは tfファイルからみて ../../src にまとめてあり、アーカイブでまとめてGCSバケットに配置するところも Terraform で書いています。
またSlack通知に必要な Webhook URLは、functionの環境変数に設定するようにします。
##################
# functions
##################
resource "google_storage_bucket" "deploy_bucket" {
name = "${var.project_id}-${var.module_name}-deploy"
}
data "archive_file" "local_function_source" {
type = "zip"
source_dir = "../../src"
output_path = "functions.zip"
}
resource "google_storage_bucket_object" "deploy_archive" {
name = "functions.zip"
bucket = google_storage_bucket.deploy_bucket.name
source = data.archive_file.local_function_source.output_path
}
resource "google_cloudfunctions_function" "function" {
name = var.module_name
region = "us-central1"
description = "real-time query performance and billing alert"
runtime = "python37"
available_memory_mb = 128
source_archive_bucket = google_storage_bucket.deploy_bucket.name
source_archive_object = google_storage_bucket_object.deploy_archive.name
entry_point = "run"
timeout = 60
event_trigger {
event_type = "google.pubsub.topic.publish"
resource = google_pubsub_topic.log_sink.id
failure_policy {
retry = false
}
}
environment_variables = {
SLACK_WEBHOOK_URL = var.slack_webhook_url
}
depends_on = [
google_storage_bucket_object.deploy_archive
]
}
Cloud Functions
最後に、しきい値を超えたらSlackに通知するCloudFunctionsのコードを書いていきます。
main.py と config.py の2ファイルで、処理とアラート閾値設定を分けています。
main.py のほとんどはログのパース処理で、あとはSlackへのポスト処理です。
run関数はCloudFunctionsのエントリーポイントとなっていて、PubSub からの event を受け取れるように引数が設定されています。
import os
import base64
import json
import config
from datetime import datetime
import urllib.request
def is_alert(log_dict, threshold):
total_slot_ms = int(log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics'].get('totalSlotMs', '0'))
total_processed_bytes = int(log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics'].get('totalProcessedBytes', '0'))
total_billed_bytes = int(log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics'].get('totalBilledBytes', '0'))
if total_slot_ms > threshold['total_slot_ms']:
return True
if total_processed_bytes > threshold['total_processed_bytes']:
return True
if total_billed_bytes > threshold['total_processed_bytes']:
return True
return False
def parse_alert_job_info(log_dict, threshold):
user_email = log_dict['protoPayload']['authenticationInfo']['principalEmail']
total_slot_ms = int(log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics'].get('totalSlotMs', '0'))
total_processed_bytes = int(log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics'].get('totalProcessedBytes', '0'))
total_billed_bytes = int(log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics'].get('totalBilledBytes', '0'))
creation_time = log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics']['createTime']
end_time = log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobStatistics']['endTime']
job_id = log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobName']['jobId']
project_id = log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobName']['projectId']
location = log_dict['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobName']['location']
job_result_url = f'https://console.cloud.google.com/bigquery?project={project_id}&j=bq:{location}:{job_id}&page=queryresults'
total_processed_bytes_gb = total_processed_bytes / 1000 / 1000 / 1000
total_billed_bytes_gb = total_processed_bytes / 1000 / 1000 / 1000
creation_time_dt = datetime.strptime(creation_time, '%Y-%m-%dT%H:%M:%S.%f%z')
end_time_dt = datetime.strptime(end_time, '%Y-%m-%dT%H:%M:%S.%f%z')
duration_dt = end_time_dt - creation_time_dt
duration_seconds = duration_dt.total_seconds()
alert_job_info = f"JobId: <{job_result_url}|{project_id}:{location}.{job_id}>" + "\n" + \
f"TotalSlotMs: {total_slot_ms} (AlertThreshold: {threshold['total_slot_ms']})" + "\n" + \
f"TotalProcessedBytes: {total_processed_bytes_gb:.02f}GB (AlertThreshold: {threshold['total_processed_bytes']/1000/1000/1000/1000}TB)" + "\n" + \
f"TotalBilledBytes: {total_billed_bytes_gb:.02f}GB (AlertThreshold: {threshold['total_billed_bytes']/1000/1000/1000/1000}TB)" + "\n" + \
f"DurationTime: {duration_seconds}sec" + "\n" + \
f"UserEmail: {user_email}"
return alert_job_info
def post_slack(alert_text):
headers = {
'Content-Type': 'application/json',
}
message_text = config.SLACK_ALERT_MESSAGE_TEXT
message_attachments_fields = [
{
'title': 'Alert JobInfo',
'value': alert_text,
'short': False
},
{
'title': 'Hint',
'value': '<https://cloud.google.com/bigquery/docs/best-practices-performance-overview | BigQueryベストプラクティス - クエリパフォーマンスの最適化の概要>',
'short': False
},
]
payload = {
'icon_emoji': config.SLACK_ICON_EMOJI,
'username': config.SLACK_USERNAME,
'text': message_text,
'channel': config.SLACK_CHANNEL,
'attachments': [
{
'fallbac': 'fallback',
'color': 'danger',
'fields': message_attachments_fields
},
],
}
req = urllib.request.Request(config.SLACK_WEBHOOK_URL, json.dumps(payload).encode(), headers)
with urllib.request.urlopen(req) as res:
body = res.read().decode('utf-8')
print(f'Slack incomming-webhook response:{body}')
def run(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
alert_threshold = {
'total_slot_ms': config.SLOT_ALERT_THRESHOLD,
'total_processed_bytes': config.PROCESSED_BYTE_ALERT_THRESHOLD,
'total_billed_bytes': config.BILLED_BYTE_ALERT_THRESHOLD,
}
message = json.loads(base64.b64decode(event['data']).decode('utf-8'))
if is_alert(message, alert_threshold):
alert_text = parse_alert_job_info(message, alert_threshold)
post_slack(alert_text)
閾値設定部分。SlackのWebhookはCloudFunctionsに設定された環境変数から読み込みます。
import os
SLACK_WEBHOOK_URL = os.environ['SLACK_WEBHOOK_URL']
SLACK_ICON_EMOJI = ':male-police-officer:'
SLACK_USERNAME = 'bq-police'
SLACK_CHANNEL = 'your-slack-channel'
SLOT_ALERT_THRESHOLD = 600000 # 10min Slots
BILLED_BYTE_ALERT_THRESHOLD = 1*1000*1000*1000*1000 # 1TB
PROCESSED_BYTE_ALERT_THRESHOLD = 1*1000*1000*1000*1000 # 1TB
SLACK_ALERT_MESSAGE_TEXT = 'Query Alert!!'
SLACK_ALERT_MESSAGE_TEXT を変更して、冒頭のイメージ画像のような通知にカスタマイズできます。
デプロイ
コードが書けたら terraform でGCPにアップロードします。
環境変数にデプロイ先のGCPプロジェクトIDとSlackのWebhook URLを埋め込みます。
cd infrastructure/terraform
terraform init
export TF_VAR_project_id=<your GCP Project ID>
export TF_VAR_slack_webhook_url=<your Slack Webhhok URL>
terraform plan -out planfile
terraform apply planfile
閾値について
課金額のアラートを変更したい場合は BILLED_BYTE_ALERT_THRESHOLD を変更します。BigQuery オンデマンド料金はクエリのデータスキャン量 1TB あたり $5 なので、予算に合わせて設定しましょう。
スロットの消費量で通知したい場合は、SLOT_ALERT_THRESHOLDを変更します。処理するデータ量が多ければスロット消費も増える傾向にあるので、PROCESSED_BYTE_ALERT_THRESHOLDも合わせて変更すると良いです。
スロットについてはこちら。
https://cloud.google.com/bigquery/docs/slots
ご自身の環境にあった閾値を見つけるのは難しいです。ジョブの統計情報から実際に実行時間が長いクエリなどを分析し、検知したかったクエリのスロット消費量から経験則的に閾値を探っていくと良いと思います。
ジョブの統計情報は BigQuery の INFORMATION_SCHEMA から取得することができます。
https://cloud.google.com/bigquery/docs/information-schema-jobs
また、BigQuery のクエリパフォーマンス最適化については公式ドキュメントにいくつかプラクティスが掲載されています。
https://cloud.google.com/bigquery/docs/best-practices-performance-overview
所感
- BigQueryのログ、めちゃくちゃ情報が入っていていいですね。監視しがいがある。
- BigQueryスロットの閾値設計の難易度が高い。何がどうなったらスロットを無駄に使ってしまうのか、Slotmsの単位とモニタリング結果の解釈が難しい。
- 定常的にデータスキャンやスロット消費が多いクエリでも、「この分析クエリが出す効果は半端ないししゃーなし」みたいな例外クエリをアラートから除外とかしないと狼アラートになる。
- クエリの中身を解析してクエリヒントを通知してもいいかも。とはいえクエリチューニングのヒントをバシッと出すのは難しい。
-
CROSS JOIN使うなとか、サブクエリ内でORDER BYするな、くらいなら正規表現で検出してアラートメッセージに添えられると思う。
-