以前「Kong Gatewayの通信の遅延箇所をJaegerで確認する」でJaegerを使ってKong Gatewayを通過したリクエストのトレースを確認し、こちらの記事で実際にKong内で遅延があった場合のトレースを確認した。
Prometheus Pluginのメトリクスを使っても同じようなことが出来るので、今回はGrafanaで確認してみる。
前提
以下が用意されているものとする。
- Prometheus/Grafanaが構築済み
- Kong Gatewayが構築済み
- Kong GatewayにPrometheus Pluginが導入済み
- カスタムプラグイン検証時のサンプルアプリとプラグイン設定が残っている
構築方法についてはそれぞれここでは触れないが、以下参考記事となる。
Prometheus Pluginのメトリクスの前提知識
「Kong Prometheus Pluginで非Promethus対応のサービスのメトリクスを取得する」でPrometheus Pluginを有効化している場合はレイテンシに関するメトリクスが取得できるようになる。
以下の3つのメトリクスがレイテンシの調査に利用できる。
-
kong_kong_latency_ms_{bucket|count|sum}:Kong内のレイテンシ -
kong_request_latency_ms_{bucket|count|sum}:Clientがリクエストを送信してからレスポンスを受け取るまでのレイテンシ(全体的なレイテンシ) -
kong_upstream_latency_ms_{bucket|count|sum}:Kongがupstreamのサービスにリクエストを発行してからレスポンスを受け取るまでのレイテンシ
Prometheusではヒストグラムというメトリクスの分布や頻度を確認する型が用意されており、以下の情報がメトリクスで提供される。
-
_bucket:指定された範囲の値のセット。パーセンタイルで使用することが多い。 -
_count:観測した回数 -
_sum:合計値
絵にするとこんな感じ。
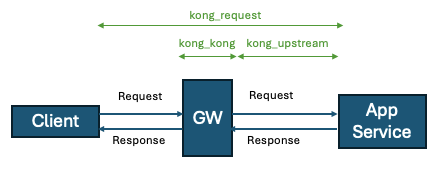
これを上手く使えばJaegerなしでもある程度はレイテンシを確認できる。
注意点として、メトリクスにPodの情報は含まれないため、Node障害などで特定のPodで遅いとかがあった場合、このメトリクスだけでは判断が難しい。
そういった場合は別のメトリクスを参照する必要がある。
Grafana Dashboardの作成
Kong Gatewayのダッシュボードはこちら(ID:7427)で提供されているが、汎用的なダッシュボードで検証目的にはあまり向かないので、ここでは検証用のダッシュボードを作成する。
Grafanaにログインし、Dashboards->New->New dashboardでダッシュボード作成画面を開き、+ Add visualizationでdata sourceにPrometheusを選択する。
まず、個別にレイテンシが分かるよう、1つずつパネルを作成する。
パネル1: kong_request_latency_ms
- 目的:リクエスト全体のレイテンシ確認
- クエリ:
rate(kong_request_latency_ms_sum{route=~"nginx.*"}[1m]) / rate(kong_request_latency_ms_count{route=~"nginx.*"}[1m]) - 設定:時系列グラフ(Time serires) ※デフォルトのまま
パネル2:kong_kong_latency_ms
- 目的:Kong内のレイテンシ確認
- クエリ:
rate(kong_kong_latency_ms_sum{route=~"nginx.*"}[1m]) / rate(kong_kong_latency_ms_count{route=~"nginx.*"}[1m]) - 設定:時系列グラフ(Time serires) ※デフォルトのまま
パネル3:kong_upstream_latency_ms
- 目的:Kongとupstream(アプリが提供するサービス)とのレイテンシ確認
- クエリ:
rate(kong_upstream_latency_ms_sum{route=~"nginx.*"}[1m]) / rate(kong_upstream_latency_ms_count{route=~"nginx.*"}[1m]) - 設定:時系列グラフ(Time serires) ※デフォルトのまま
PromQLの雑な補足:
~=は正規表現でnginx.*に一致するRouteを抽出し、[1m]で1分間のデータを対象とし、rateで増加率を計算する。
rate(xxx_sum) / rate(xxx_count)でその時点のレイテンシが確認できる。
これで以下のような感じで各レイテンシが可視化できる。

縦軸を見るとkong_upstream_latency_msだけレイテンシが小さく他はレイテンシが大きくなっているので、全体的なレイテンシが悪くなっていて、Kong内に原因があることがこれから読み取れる。
また今回ここでは設定しないが、しきい値などの設定をすればより異常な状態が確認しやすくなる。
上記ではそれぞれのメトリクスを別のパネルとして表示したが、これだと縦軸が揃っていないため、どれくらい差があるのか視覚的に分かりづらい。
そのため、最後にkong_request_latency_msを除外して積み上げ式のグラフで割合表示してみる。
パネル4:Rate
- 目的:各メトリクスの比率を確認
- クエリ1:
rate(kong_kong_latency_ms_sum{route=~"nginx.*"}[1m]) / rate(kong_kong_latency_ms_count{route=~"nginx.*"}[1m]) - クエリ2:
rate(kong_upstream_latency_ms_sum{route=~"nginx.*"}[1m]) / rate(kong_upstream_latency_ms_count{route=~"nginx.*"}[1m]) - 設定:時系列グラフ(Time serires)、Stacking: 100%
カスタムプラグインが有効だと差が激しいので、途中でカスタムプラグインを止めてメトリクスを計測した結果がこちら。

最初はkong_upstream_latency_msがほぼなく、Kong内でやたら時間が掛かっているのが読み取れる。また途中からkong_upstream_latency_msの割合が増えてきて、Kong Gateway内の何かしらの問題が解消されたことが想像できる。
まとめ
Prometheus/Grafanaでも通信が遅延している事自体は確認できた。
ただ、やはりトレーシングと比べて粒度は粗く、例えばどのプラグインで遅くなっているか、とかまでは分からない。
一方でトレーシングのように毎回ここのトレースを確認しなくても問題が発生していることが簡単に確認できるので、通常運用時にはGrafanaで確認するのが良さそうである。
Observabilityの監視は基本的にログ、メトリクス、トレーシングの組み合わせなので、原則に従いメトリクスで検知した後はトレーシングで詳細を確認する、といった具合に上手いこと棲み分けて使うことを推奨する。