本記事は、TUNA-JP Advent Calendar 2023 の19日目になる。
ただし、TUNA-JP Advent CalendarなのにTanzu要素はメインではなく、TKG使ってるくらいな点はご容赦を。。。
先日のVMware ExploreでVMware(現Broadcom)はPrivate AIに注力すると発表しており、リファレンスアーキテクチャとしてVMware Cloud Foundation上にRayやKubeflowを載せたものを公開している。
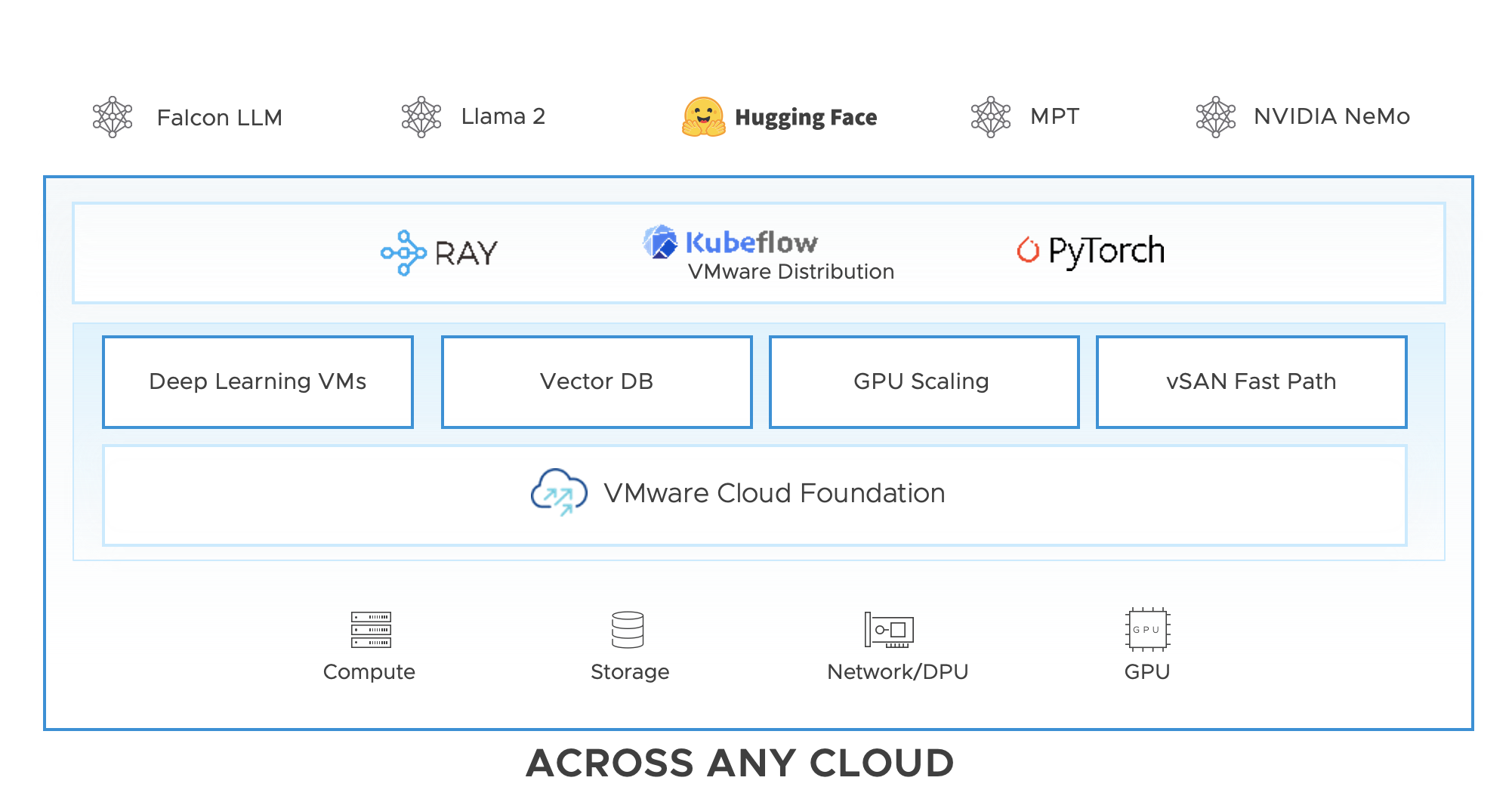
(Ray Integration with Kubeflow on vSphereより引用)
そういう流行りに乗っかって、過去にRayとKubeflowについていくつか試してメモ化してきた。
- KubeflowをTanzu Mission Controlでインストールして使ってみる
- Tanzu Kubernetes Grid上でllama.cppをサクッと使う
- Ray ClusterをvSphere上にRay CLIでデプロイする
ただ、上記のメモではRayとKubeflowは分かれていたが、ここではこれらを統合させて使ってみる。
元ネタはRay Integration with Kubeflow on vSphereというブログとなる。
なお今回の記事ではRayとは何か、Kubeflowとは何か、については特に触れていないので、必要であれば他の人の記事等を参照して欲しい。
今回のゴール
ここでのゴールは元ネタの記事の以下の図を実現する。
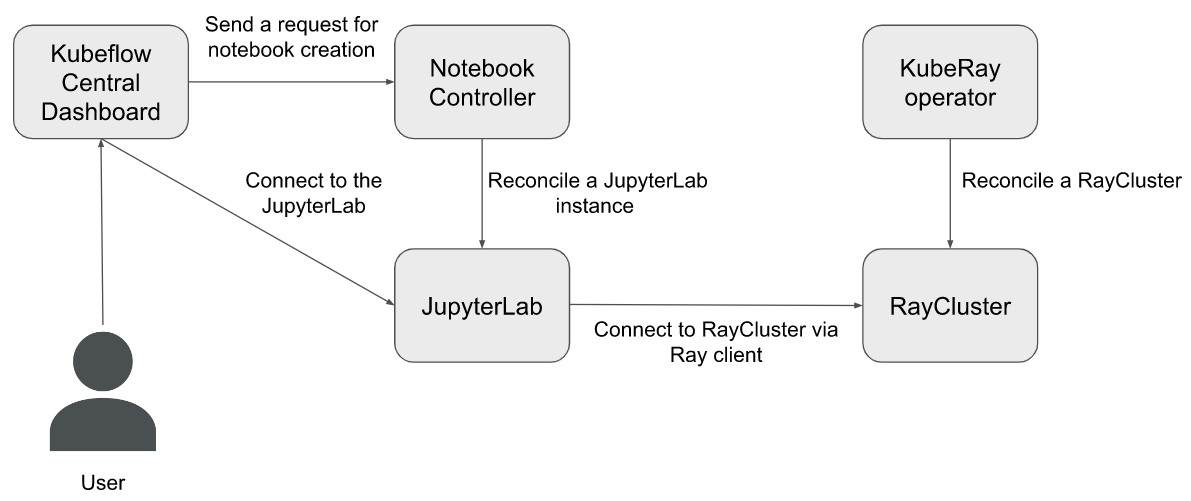
こちらの図はvSphereが提供する、MLエンジニアやデータサイエンティストにとって望ましい開発環境とのことなので、これを作って作成手順などを確認する。
前提
KubeflowとRayを連携させる前提として、以下が終わっているものとする。
- KubeflowをTKG上で構築済み
- 作業端末にはHelmをインストール済み
なお、TKGノードにはGPUは含まないものとする。(含んでいてもいいけど、ここでは使わない)
Kubeflowの構築はTMCで構築したが、他のやり方でも多分問題ない。
検証
元ネタの記事にrun.shという自動構築・設定スクリプトが配布されているが、今回は挙動確認のために使わずに構築・設定する。
なお、このスクリプトを使う人は以下の点に注意。
- 失敗した場合の戻しの処理はない
- GPUを使わない場合は先頭の
rayclusterwithgpuをfalseにする必要あり - GPUを使う場合、Ray ClusterのWorkerとなるPodの
requestsがCPU8、メモリ32Gと大きい点に注意 - Integration設計がKubeflowのリコンサイルで最大5分しか持たない
KuberayとRayクラスタの構築
RayのKubernetes版であるKuberayをHelmでインストールする。
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm install kuberay-operator kuberay/kuberay-operator --version 0.5.0 --create-namespace -n ray
なお、バージョンを指定せずに新しいものを使ってみたが、Rayクラスタの起動に失敗したのでrun.shに書いてあったバージョンを指定している。
インストールに成功すると、Operator Podが起動する。
$ kubectl get pod -n ray
NAME READY STATUS RESTARTS AGE
kuberay-operator-6bf887b5fb-kgfqb 1/1 Running 0 6m36s
次にRayクラスタを作成する。
ここではHelmで作成しているが、kind: RayClusterを自作しても問題ない。
helm install raycluster kuberay/ray-cluster --set image.tag=2.2.0-py38-cpu -n ray --version 0.5.0 --set service.type=LoadBalancer
--set service.type=LoadBalancerをつけているが、クラスタ外からrayCLIなどで叩きたい等の要望がなければ外してOK。今回の検証でも利用しない。
その他、設定を変更したい場合はvalues.yamlの仕様を確認するとよい。
起動すると、HeadとWorkerが1台ずつ起動する。
$ kubectl get raycluster -n ray
NAME DESIRED WORKERS AVAILABLE WORKERS STATUS AGE
raycluster-kuberay 1 1 ready 2m11s
$ kubectl get pod -n ray
NAME READY STATUS RESTARTS AGE
kuberay-operator-7fc785cbbd-4vqm9 1/1 Running 0 3m16s
raycluster-kuberay-head-st895 1/1 Running 0 2m28s
raycluster-kuberay-worker-workergroup-dn72h 1/1 Running 0 2m28s
KuberayとKubeflowの連携
Kubeflow側に、Kubeflowの中で/ray-cluster/を参照した場合にRayクラスタのServiceを参照するようVirtualServiceを設定する。
(Kubeflowインストール時にIstioもインストールされており、VirtualServiceリソースが使えるようになっている)
cat << EOF | kubectl apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ray-cluster-virtual-service
namespace: kubeflow
spec:
gateways:
- kubeflow-gateway
hosts:
- '*'
http:
- match:
- uri:
prefix: /ray-cluster/
rewrite:
uri: /
route:
- destination:
host: raycluster-kuberay-head-svc.ray.svc
port:
number: 8265
EOF
KubeflowのダッシュボードのサイドバーにRayへのリンクを追加するために、ConfigMapを修正する。
ただし、普通にConfigMapを修正してもkapp-controllerにより元に戻されてしまうため、Overlayする形でSecretとして差し込む。
まずはOverlayする内容を確認するために、変更後のConfigMapを作成する。
kubectl get configmap centraldashboard-config -n kubeflow -o jsonpath='{.data.links}' > current.json
new_item='{
"type": "item",
"link": "/ray-cluster/",
"text": "Ray on vSphere",
"icon": "book"
}'
cat current.json | jq '.menuLinks |= map(if .link == "/pipeline/#/artifacts" then ., '"$new_item"' else . end)' > updated.json
kubectl get configmap centraldashboard-config -n kubeflow -o jsonpath='{.data.settings}' > settings.json
kubectl create configmap centraldashboard-config --from-file=links=updated.json --from-file=settings=settings.json -n kubeflow --dry-run=client -o yaml > update-cm.yaml
次にkapp-controllerがOverlayするための準備をする。
公式手順はOverlays with PackageInstallに記載がある。
ざっくり、仕組みは以下となっている。
- Overlayしたい内容を
Secretとして作成する -
PackageInstallオブジェクトのannotationにext.packaging.carvel.dev/ytt-paths-from-secret-name.0に作成したSecret名を記載する - 5分間隔くらいでPollingしているkapp-controllerが
Secretを参照し、Overlayを実施する
ということで、最初にOverlayするYAMLを作成する。
先程作成したupdate-cm.yamlを元に、以下のようなSecretを作成・Applyする。
OverlayのSecret(クリックすると表示)
cat << EOF | kubectl apply -n my-packages -f -
apiVersion: v1
kind: Secret
metadata:
name: my-overlay-secret
stringData:
update-for-ray.yml: |
#@ load("@ytt:overlay", "overlay")
#@overlay/match by=overlay.subset({"kind":"ConfigMap", "metadata":{"name":"centraldashboard-config"}}),expects="1+"
---
data:
#@overlay/match missing_ok=True
links: |
{
"menuLinks": [
{
"type": "item",
"link": "/jupyter/",
"text": "Notebooks",
"icon": "book"
},
{
"type": "item",
"link": "/tensorboards/",
"text": "Tensorboards",
"icon": "assessment"
},
{
"type": "item",
"link": "/volumes/",
"text": "Volumes",
"icon": "device:storage"
},
{
"type": "item",
"link": "/kserve-endpoints/",
"text": "Models",
"icon": "kubeflow:models"
},
{
"type": "item",
"link": "/katib/",
"text": "Experiments (AutoML)",
"icon": "kubeflow:katib"
},
{
"type": "item",
"text": "Experiments (KFP)",
"link": "/pipeline/#/experiments",
"icon": "done-all"
},
{
"type": "item",
"link": "/pipeline/#/pipelines",
"text": "Pipelines",
"icon": "kubeflow:pipeline-centered"
},
{
"type": "item",
"link": "/pipeline/#/runs",
"text": "Runs",
"icon": "maps:directions-run"
},
{
"type": "item",
"link": "/pipeline/#/recurringruns",
"text": "Recurring Runs",
"icon": "device:access-alarm"
},
{
"type": "item",
"link": "/pipeline/#/artifacts",
"text": "Artifacts",
"icon": "editor:bubble-chart"
},
{
"type": "item",
"link": "/ray-cluster/",
"text": "Ray on vSphere",
"icon": "book"
},
{
"type": "item",
"link": "/pipeline/#/executions",
"text": "Executions",
"icon": "av:play-arrow"
}
],
"externalLinks": [],
"quickLinks": [
{
"text": "Upload a pipeline",
"desc": "Pipelines",
"link": "/pipeline/"
},
{
"text": "View all pipeline runs",
"desc": "Pipelines",
"link": "/pipeline/#/runs"
},
{
"text": "Create a new Notebook server",
"desc": "Notebook Servers",
"link": "/jupyter/new?namespace=kubeflow"
},
{
"text": "View Katib Experiments",
"desc": "Katib",
"link": "/katib/"
}
],
"documentationItems": [
{
"text": "Getting Started with Kubeflow",
"desc": "Get your machine-learning workflow up and running on Kubeflow",
"link": "https://www.kubeflow.org/docs/started/getting-started/"
},
{
"text": "MiniKF",
"desc": "A fast and easy way to deploy Kubeflow locally",
"link": "https://www.kubeflow.org/docs/distributions/minikf/"
},
{
"text": "Microk8s for Kubeflow",
"desc": "Quickly get Kubeflow running locally on native hypervisors",
"link": "https://www.kubeflow.org/docs/distributions/microk8s/kubeflow-on-microk8s/"
},
{
"text": "Kubeflow on GCP",
"desc": "Running Kubeflow on Kubernetes Engine and Google Cloud Platform",
"link": "https://www.kubeflow.org/docs/gke/"
},
{
"text": "Kubeflow on AWS",
"desc": "Running Kubeflow on Elastic Container Service and Amazon Web Services",
"link": "https://www.kubeflow.org/docs/aws/"
},
{
"text": "Requirements for Kubeflow",
"desc": "Get more detailed information about using Kubeflow and its components",
"link": "https://www.kubeflow.org/docs/started/requirements/"
}
]
}
#@overlay/match missing_ok=True
settings: |-
{
"DASHBOARD_FORCE_IFRAME": true
}
EOF
次にKubeflowのPackageInstallオブジェクトのannotationを更新する。
kubectl patch pkgi --type merge -p "{\"metadata\":{\"annotations\":{\"ext.packaging.carvel.dev/ytt-paths-from-secret-name.0\":\"my-overlay-secret\"}}}" kubeflow -n my-packages
これで準備OKなので、kapp-controllerが更新するのを待つ。
待ちきれない人は以下を実行してリコンサイルを促すとよい。
kubectl patch app --type merge -p "{\"spec\":{\"paused\": true}}" kubeflow -n my-packages
リコンサイルが終わると、Kubeflowにリンクが追加され、リンクをクリックすればRayのダッシュボードが見えるはずだ。
istio-ingressgatwayのExternal-IPを参照し、Kubeflowを開く。
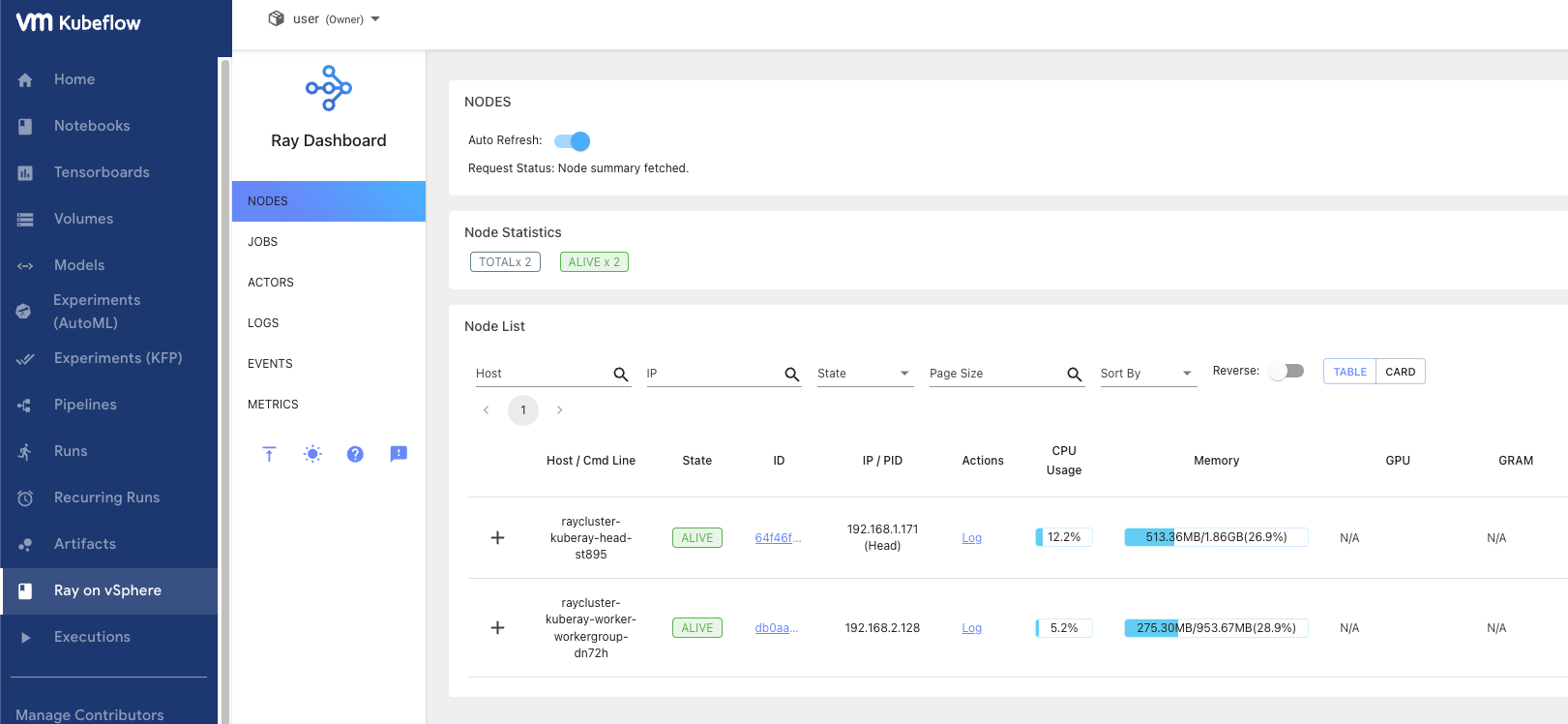
左サイドバーにRay on vSphereという項目が追加され、Ray Dashboardが参照できるようになった。
これでインフラ担当者としては開発者にKubeflowとRayが統合された環境を渡せる状態となった。
Jupyter Notebookをデプロイして、Rayクラスタ上でワークロードを実行する
ここからは開発者視点で、Jupyter Notebookをデプロイして、Rayクラスタ上でワークロードを実行してみる。
なお、ワークロードとなるサンプルコードはこちらの記事で使ったものを利用している。
サンプルコードの説明等はそちらの記事を参照してほしい。
Kubeflowのダッシュボードの左サイドバーからNotebooksを選択し、New Notebookをクリックする。
作成画面では以下のように設定した。
-
Name:ray-test -
Image:kubeflownotebookswg/jupyter-tensorflow-cuda-full:v1.6.0 -
CPU:2 -
Memory:8G -
Data volumes:10G
数分待つと環境の払い出しが終わって以下のような画面になるので、CONNECTをクリックしてJupyter Notebookにアクセスする。
メニューバーからFile->New->Notebookで新規にNotebookを作成し、rayCLIをインストールする。
pip install 'ray[default]'
サンプルコードをダウンロードする。
! wget https://raw.githubusercontent.com/ray-project/ray/master/doc/yarn/example.py
なお、サンプルコードではノードを4台要求しているが、今回構築したRayクラスタはHeadとWorkerがそれぞれ1台デプロイされた構成であるため、サンプルコードは待ち状態で動かなくなってしまう。
KubeRayを使った場合、設定次第でオートスケールすることが可能だが、今回はオートスケールは目的としていないため、待つノードの台数を2に変更して進める。
! sed -i "s/wait_for_nodes(4)/wait_for_nodes(2)/g" example.py
rayCLIを実行する。アドレスに、RayクラスタのHeadのServiceを指定する。
! RAY_ADDRESS='http://raycluster-kuberay-head-svc.ray.svc:8265' ray job submit --working-dir . -- python example.py
RayクラスタのPod名が表示された。
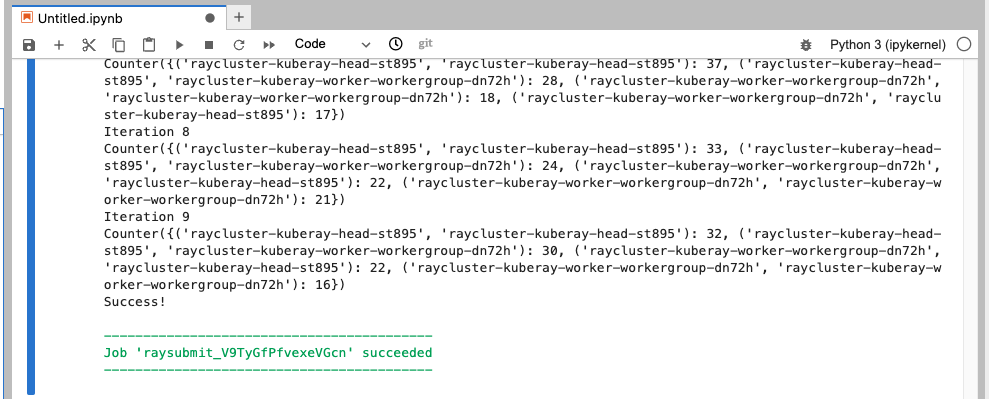
これによりRayクラスタ上でコードが実行できたことが確認できた。
まとめ
vSphere Machine Learning ExtensionのKubeflowとKubeRayを組み合わることで、ML開発者はUIから開発環境(Jupyter Notebook)を簡単にデプロイ出来るようになり、かつ実行環境(Ray)も用意せずに使える世界が実現できる見込みを得た。
開発環境という意味ではVMware(現Broadcom)はTanzu Application Platformもあるが、こちらと将来的に連携するのかとか今後の発展を期待したいところである。