はじめに
前回は、商標の出願人のランキングと件数の時系列の図を作成しました。
j-platpatからは、出願人や出願日のみならず区分の情報も取れますので、今回は区分を使った図を作りたいと思います。
なお、商標の区分とは、商品及び役務の区分のことでして、商標出願時に必須の記載内容となっております。この区分を分析しますと、この人はこの商標を使って、この分野のビジネスを始めようとしているということがわかってしまうことになります。
プログラム
データフレーム作成
まず、いつものように出願人と区分をエクスプロードしたデータフレームを生成します。
! pip install japanize-matplotlib
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.cm as cm
import japanize_matplotlib
# googleドライブの利用
from google.colab import drive
drive.mount('/content/drive')
# データの前処理
# データの読み込み(google ドライブから)
df = pd.read_excel('/content/drive/MyDrive/商標excel.xlsx')
#必要な列のみ抽出
df = df[['区分', '出願人/権利者/名義人']]
#不要語の削除(出願人/権利者)
df['出願人/権利者/名義人'] = df['出願人/権利者/名義人'].str.replace('▲', '')
df['出願人/権利者/名義人'] = df['出願人/権利者/名義人'].str.replace('▼', '')
# 欠落データを削除
df = df.dropna()
# 区分列を文字列に変換
df['区分'] = df['区分'].astype(str)
# ,で区分を分割
df['区分'] = df['区分'].str.split(',')
# ,で出願人を分割
df['出願人/権利者/名義人'] = df['出願人/権利者/名義人'].str.split(',')
# 区分と出願人をエクスプロード
df = df.explode('区分').explode('出願人/権利者/名義人')
# 「'区分'」と「'出願人'」の列でグループ化し、グループ内の要素数を数える
result = df.groupby(['区分', '出願人/権利者/名義人']).size().reset_index(name='Counts')
出願人top20の限定
次に、図示する出願人を前回の記事で抽出した20社(と人)に限定します。この部分は、前回のコードと一体化することにより、もう少しスマートなコードにできると思いますが、以後の改善点としたいと思います。
# 出願人をtop20に限定
result = result.query('`出願人/権利者/名義人` in ["小林 正英","藤田 貴男","志賀 正武","株式会社パットブレーン","酒井 俊之","大前 要","橘 和之","長谷川 芳樹","株式会社イーパテント","辻田 朋子","システム・インテグレーション株式会社","内閣府大臣官房会計課長","弁理士法人Toreru","有限会社ノア情報センター","日本弁理士会","株式会社Toreru","TechnoProducer株式会社","株式会社知財コーポレーション","正林 真之","本夛 伸介"]')
区分の置き換え
区分は9(類)や16(類)などの数字となり、そのままではわかりにくい図となりますので、区分の概要を示す用語を追記します。
# map置き換え用の辞書作成
replace_dict = {
'09': '09\n機械器具',
'16': '16\n事務用品',
'28': '28\n遊戯用具',
'35': '35\n広告',
'36': '36\n金融',
'38': '38\n電気通信',
'41': '41\n教育',
'42': '42\nソフト',
'43': '43\n飲食',
'45': '45\n法律サービス'
}
# mapメソッドを使用して区分を日本語に置き換える
result.loc[:, '区分'] = result['区分'].map(replace_dict)
散布図作成
いつもの散布図によりバブルチャート化します。
# 「'区分'」と「'分類'」の列からなる値をリスト形式に変換
x = result['区分'].tolist()
y = result['出願人/権利者/名義人'].tolist()
# 「Counts」列からなる値を元に、散布図のすべての点の大きさを示すリストを作成
sizes = [size * 30 for size in result['Counts'].tolist()]
# 「Counts」列からなる値を元に、散布図のすべての点のカウント数を示すリストを作成
nums = [num for num in result['Counts'].tolist()]
# 「出願人」列からなる値を元に、カテゴリーのリストを作成
categories = list(set(y))
# 色マップを作成
colors = cm.rainbow(np.linspace(0, 1, len(categories)))
colors = {categories[i]: colors[i] for i in range(len(categories))}
colors = [colors[item] for item in y]
# 散布図を作成
fig, ax = plt.subplots(figsize=[8,8])
ax.scatter(x, y, s=sizes, c=colors)
# 散布図にカウント数を表示
for i, txt in enumerate(nums):
ax.annotate(txt, (x[i], y[i]), textcoords="offset points", xytext=(0,0), ha='left', va='bottom')
# x 軸のラベルを設定する。
ax.set_xlabel("区分")
# y 軸のラベルを設定する。
ax.set_ylabel("出願人/権利者/名義人")
# タイトルを設定する。
ax.set_title("区分-出願人/権利者/名義人マップ")
# 図を表示
plt.show()
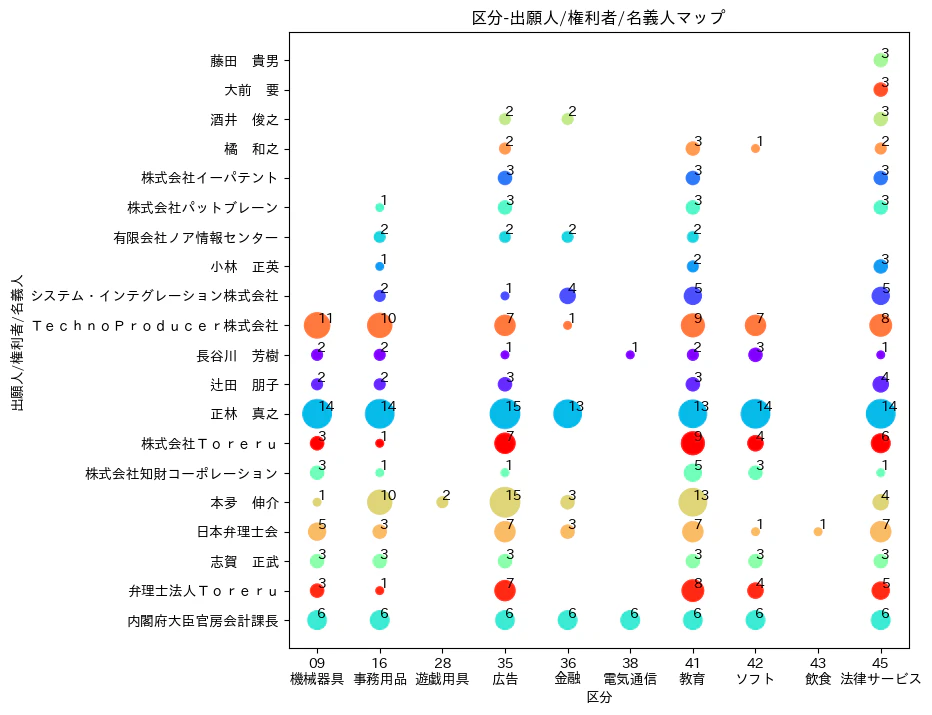
完成したバブルチャート
完成したバブルチャートは以下となります。皆さん、だいたい同じ区分に出願していることがわかります。無理に分析すれば、内閣府の課長さんが38類「電気通信」に出願していることが目立っております。
感想
今回は試しに区分と出願人との関係図を作成してみましたが、例えば、区分を縦軸にとり、出願日を横軸にとれば、区分の件数の増減から、ビジネスの流行り廃りなども分析できるかもしれません。今後はいろいろ応用してゆきたいと思います。