概要
仕事でAthenaを利用する機会が出てきたため自分の環境でも触ってみたいと思います。
以前に作成した自分のブログのCloudfrontのログが使えそうでしたので、それを解析してみます。
この記事はそのメモやまとめです。
すでに設定済みの項目がいくつかある。
試行錯誤しながらやったので、手順として不要かもしれない。あくまでメモ用。
概要と用語
まずはAmazon Athenaについて理解します。
公式ドキュメントには
Amazon Athena は、標準 SQL を使用して Simple Storage Service (Amazon S3) 内のデータを直接、シンプルに分析できるようにするインタラクティブなクエリサービスです。Athena はサーバーレスなので、インフラストラクチャをセットアップしたり管理したりする必要がなく、実行するクエリやクエリに必要なコンピューティングに基づいて料金を支払うことができます。Athena を使用して、ログを処理し、データ分析やインタラクティブなクエリを実行します。Athena は自動的にスケールされ、並列して複数のクエリが実行されるため、大きなデータセットや複雑なクエリを扱う場合でもすばやく結果が得られます。
ふむふむ。要はs3に対してSQLでクエリをかけられるということですね。
blackbeltも見えてみましょう
正直すごく難しいと感じたので概要部分程度の把握です。
用語はこちらの記事を参考にしました。ふわっとですが用語は掴めたような気がします。
作成してみる
主に以下の2つの記事を参考に、cloudfrontの標準ログに対してクエリをかけられるようにしたいと思います。
ログは見た感じ現状のログと差分がありそうですので、公式ドキュメントも参考にします。(標準ログファイルフィールド)
ただ、SQLでテーブル作成する際のクエリを
を参考に書き換えます。
出来上がったコード
###### s3 ######
resource "aws_s3_bucket" "s3_athena_for_cloudfront" {
bucket = "inugami-techlab-hugo-athena"
}
# オブジェクト所有者を「バケット所有者の強制」にすることでACLの無効化
resource "aws_s3_bucket_ownership_controls" "s3_athena_for_cloudfront" {
bucket = aws_s3_bucket.s3_athena_for_cloudfront.id
rule {
object_ownership = "ObjectWriter"
}
}
# パブリックアクセスをブロック
resource "aws_s3_bucket_public_access_block" "s3_athena_for_cloudfront" {
bucket = aws_s3_bucket.s3_athena_for_cloudfront.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
# バージョニング設定
resource "aws_s3_bucket_versioning" "s3_athena_for_cloudfront" {
bucket = aws_s3_bucket.s3_athena_for_cloudfront.id
versioning_configuration {
status = "Enabled"
}
}
# s3側での暗号化
resource "aws_s3_bucket_server_side_encryption_configuration" "s3_athena_for_cloudfront" {
bucket = aws_s3_bucket.s3_athena_for_cloudfront.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
# lifecycleの設定
resource "aws_s3_bucket_lifecycle_configuration" "s3_athena_for_cloudfront" {
bucket = aws_s3_bucket.s3_athena_for_cloudfront.id
rule {
id = "cloudfront_log"
status = "Enabled"
expiration {
days = 1095
}
transition {
## オブジェクトが作成されてからSTANDARD_IAに移行するまでの日数。
days = 30
storage_class = "STANDARD_IA"
}
transition {
days = 90
storage_class = "GLACIER"
}
noncurrent_version_expiration {
noncurrent_days = 365
}
noncurrent_version_transition {
noncurrent_days = 30
storage_class = "STANDARD_IA"
}
noncurrent_version_transition {
noncurrent_days = 60
storage_class = "GLACIER"
}
abort_incomplete_multipart_upload {
days_after_initiation = "7"
}
}
}
###### athena ######
resource "aws_athena_workgroup" "s3_athena_for_cloudfront" {
name = "s3_athena_for_cloudfront"
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = false
result_configuration {
output_location = "s3://${aws_s3_bucket.s3_athena_for_cloudfront.id}/athena-result/"
}
}
}
## データベース作成
resource "aws_athena_database" "s3_athena_for_cloudfront" {
name = "s3_athena_for_cloudfront"
bucket = aws_s3_bucket.s3_cloudfront_log.bucket
}
## データベース内にテーブルを作成する
data "template_file" "create_table_sql" {
template = file("${path.module}/create-table.sql.tpl")
vars = {
athena_database_name = aws_athena_database.s3_athena_for_cloudfront.id
athena_table_name = "cloudfront_logs"
log_bucket_name = aws_s3_bucket.s3_cloudfront_log.id
}
}
resource "aws_athena_named_query" "create_table" {
name = "Create table"
description = "テーブルを作成"
workgroup = aws_athena_workgroup.s3_athena_for_cloudfront.id
database = aws_athena_database.s3_athena_for_cloudfront.id
query = data.template_file.create_table_sql.rendered
}
CREATE EXTERNAL TABLE IF NOT EXISTS s3_athena_for_cloudfront.cloudfront_logs (
`date` DATE,
time STRING,
location STRING,
bytes BIGINT,
request_ip STRING,
method STRING,
host STRING,
uri STRING,
status INT,
referrer STRING,
user_agent STRING,
query_string STRING,
cookie STRING,
result_type STRING,
request_id STRING,
host_header STRING,
request_protocol STRING,
request_bytes BIGINT,
time_taken FLOAT,
xforwarded_for STRING,
ssl_protocol STRING,
ssl_cipher STRING,
response_result_type STRING,
http_version STRING,
fle_status STRING,
fle_encrypted_fields INT,
c_port INT,
time_to_first_byte FLOAT,
x_edge_detailed_result_type STRING,
sc_content_type STRING,
sc_content_len BIGINT,
sc_range_start BIGINT,
sc_range_end BIGINT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION 's3://(cloudfront_logのバケット)/'
TBLPROPERTIES ( 'skip.header.line.count'='2' )
出来上がったリソースの確認
まずはワークグループの確認です。
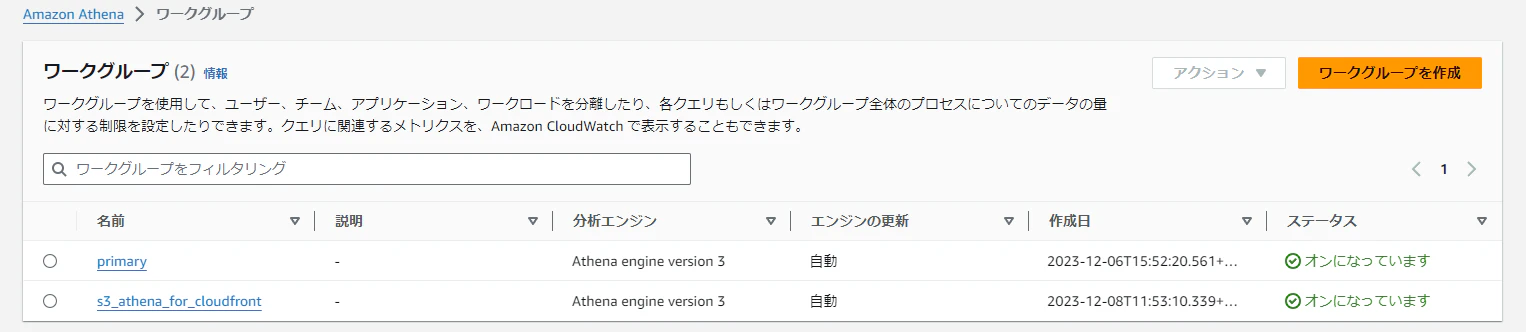
クエリエディタのワークグループで上記のワークグループを選択します。
データベースも出来上がっていました。

ここで作成したクエリを実行して上記データベースにテーブルを作成します。
「保存したクエリ」→terraform経由で作成したクエリを選択
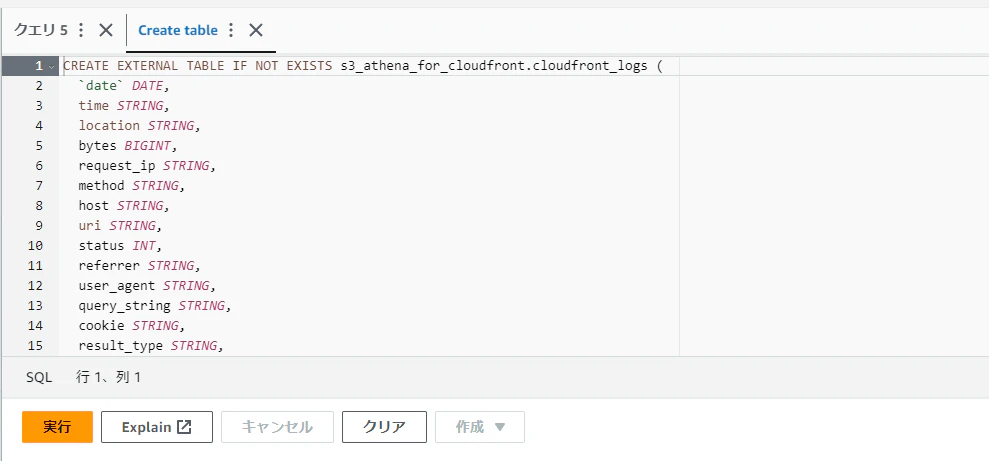
このまま実行するとテーブルが作成されました。

テストしてみる
では実際にcloudfrontのログに対してクエリを実行させてみたいと思います。
「テーブル」→「…」→「テーブルをプレビュー」を実行させます。
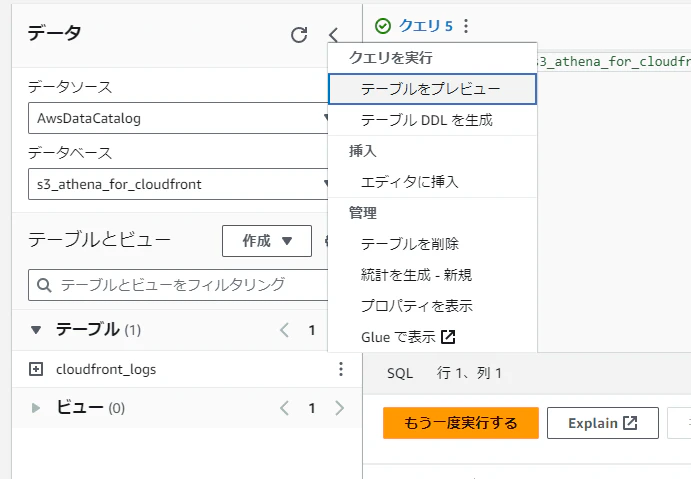
そうすると
SELECT * FROM "s3_athena_for_cloudfront"."cloudfront_logs" limit 10;
のようなクエリが発行されクエリ結果が表示されれば大丈夫そうです。

終わりに
本当に触りの部分だけですが初めてAthenaを触りました。
次はクエリをもうちょっといじって直近のログだけ抽出とかやってみたいですね。