概要
ScrapyでWord VBA リファレンス([列挙体][enumerations-word])をmarkdown(.md)にします。
後半はscrapy shellでWord VBA リファレンスの解析で調べたことの記録です。
参考
- Scrapy 1.5 documentation
- クローラ作成に必須!XPATHの記法まとめ - Qiita
- ScrapyによるWebスクレイピング - Qiita
- Scrapy入門(1)~Scrapy入門(4)- Qiita
動機
Wordの列挙体を直値で指定したいのでマクロ(以降「名前」)と値の関係を知りたい。
Scrapy(scrapy shell/crawl)でなんとかしてみる。
[列挙体 (Word) - msdn][enumerations-word]

目標
Markdownのテーブルでまとめたい。
イメージ
WdAlertLevel 列挙
| 名前 | 値 | 説明msdn_ja-jp | 説明msdn_en-us |
|---|---|---|---|
| wdAlertsAll | -1 | すべてのメッセージ ボックスと警告を表示します。エラーをマクロに返します。 | All message boxes and alerts are displayed; errors are returned to the macro. |
| wdAlertsMessageBox | -2 | メッセージ ボックスのみを表示します。エラーをトラップし、マクロに返します。 | Only message boxes are displayed; errors are trapped and returned to the macro. |
| wdAlertsNone | 0 | 警告やメッセージ ボックスを表示しません。マクロでメッセージ ボックスを検出した場合、既定値を選択し、マクロを続行します。 | No alerts or message boxes are displayed. If a macro encounters a message box, the default value is chosen and the macro continues. |
処理概要
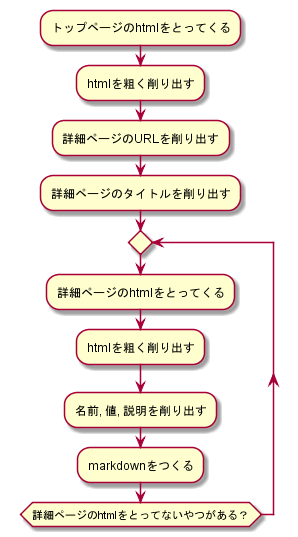
コード - scrapy shell
> scrapy shell --nolog https://msdn.microsoft.com/ja-jp/vba/vba-word
# htmlを粗く削り出す
res = response.xpath(r"//div[@class='tocLevel']/a[contains(@title, ' 列挙')]")
# 詳細ページのURLを削り出す
urls = res.xpath(r"@href").extract()
# 詳細ページのタイトルを削り出す
titles = res.xpath(r"@title").extract()
## デバッグ用
# urls = urls[20:21] #ループ内でfetchする個数を限定する。[20:21]は、https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word
# titles = titles[20:21] #urlsに合わせて調整する。[20:21]は、WdCalendarType 列挙
# 詳細ページのhtmlをとってないやつがあるだけループ
for url,title in zip(urls,titles):
#詳細ページのhtmlをとってくる
fetch(url)
#名前, 値, 説明を削り出す
##htmlをtdで削りとる
res = response.xpath("//table//td")
##tdで削りとった直後に3つずつにわける
tds = [res[i:i+3] for i in range(0,len(res),3)]
##各tdを解析結果はdictionary型md_tdに格納。md_tdはリスト型md_tdsに格納
md_tds = []
for td in tds:
##各tdを解析結果を格納するdict
md_td ={}
##名前を削り出す
name = td[0].xpath("descendant::text()").extract()[1]
md_td.update({"name":name})
##値を削り出す
value = td[1].xpath("descendant::text()").extract()[1]
md_td.update({"value":value})
##日本語版(span data-ttu-id)の説明を削り出す
dscpt_jp = td[2:].xpath("descendant::span[@data-ttu-id]//text()").extract()
dscpt_jp = " ".join(dscpt_jp)
md_td.update({"description_jp":dscpt_jp})
##英語版(span data-stu-id)の説明を削り出す
dscpt_en = td[2:].xpath("descendant::span[@data-stu-id]//text()").extract()
dscpt_en = " ".join(dscpt_en)
md_td.update({"description_en":dscpt_en})
##md_tdをリスト型md_tdsに格納
md_tds.append(md_td)
#markdownをつくる
import re
jp_url = url
us_url = re.sub(r"/ja-jp/",r"/en-us/", jp_url)
s = f"\n##{title}\n"\
+ f"\n"\
+ f"|名前|値|説明[msdn_ja-jp]({jp_url})|説明[msdn_en-us]({us_url})|\n"\
+ f"|:---|:---|:---|:---|\n"
for md_td in md_tds:
s+="|{}|{}|{}|{}|\n".format(md_td["name"], md_td["value"], md_td["description_jp"], md_td["description_en"])
s += "\n"
print(s)
コード - spider(scrapy crawl)
1.プロジェクト作成
> scrapy startproject word_vba
2.spider作成
作成したプロジェクトのspidersフォルダにword_vba_enum_spider.pyを配置。中身は以下。
# -*- coding: utf-8 -*-
import scrapy
import re
def gen_markdown_text(title, jp_url, us_url, md_tds):
s = f"\n##{title}\n"\
+ f"\n"\
+ f"|名前|値|説明[msdn_ja-jp]({jp_url})|説明[msdn_en-us]({us_url})|\n"\
+ f"|:---|:---|:---|:---|\n"
for md_td in md_tds:
s+="|{}|{}|{}|{}|\n".format(md_td["name"], md_td["value"], md_td["description_jp"], md_td["description_en"])
s += "\n"
return s
def gen_markdown_table_dic(td):
md_td ={}
name = td[0].xpath("descendant::text()").extract()[1]
md_td.update({"name":name})
value = td[1].xpath("descendant::text()").extract()[1]
md_td.update({"value":value})
dscpt_jp = td[2].xpath("descendant::span[@data-ttu-id]/text()").extract()
dscpt_jp = " ".join(dscpt_jp)
dscpt_en = td[2].xpath("descendant::span[@data-stu-id]/text()").extract()
dscpt_en = " ".join(dscpt_en)
md_td.update({"description_jp":dscpt_jp, "description_en":dscpt_en})
return md_td
class WordVbaEnumSpider(scrapy.Spider):
name = "word_vba_enum"
allowed_domains = ["msdn.microsoft.com"]
custom_settings = {
"DOWNLOAD_DELAY": 1.5,
}
def start_requests(self):
urls = [
"https://msdn.microsoft.com/ja-jp/vba/vba-word",
]
with open("word_vba_enum.md", "w", encoding='utf-8') as f:
f.write("")
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
res = response.xpath(r"//div[@class='tocLevel']/a[contains(@title, ' 列挙')]")
urls = res.xpath(r"@href").extract()
titles = res.xpath(r"@title").extract()
# urls = urls[20:21] #ループ内でfetchする個数を調整する。[20:21]は、https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word
# titles = titles[20:21] #urlsに合わせて調整する。[20:21]は、WdCalendarType 列挙
for url,title in zip(urls, titles):
yield response.follow(url, callback=self.parse_detail, meta={"title":title})
def parse_detail(self, response):
tds = response.xpath("//table//td")
tds = [tds[i:i+3] for i in range(0,len(tds),3)]
md_tds = [gen_markdown_table_dic(td) for td in tds]
us_url = re.sub(r"/ja-jp/",r"/en-us/",response.url)
md_text = gen_markdown_text(response.meta["title"],response.url,us_url,md_tds)
with open("word_vba_enum.md", "a", encoding='utf-8') as f:
f.write(md_text)
print(md_text)
3.spiderの確認
> scrapy list
word_vba_enum
4.scrapy crawlの実行
> scrapy crawl word_vba_enum
5.結果
処理が終わると、word_vba_enum.mdができています。
以降はWord VBA リファレンスのhtmlの解析
下調べ - htmlソース解析
[列挙体][enumerations-word]のhtmlをテキストエディタで見ます。
詳細ページのURL
詳細ページのURLをとってくる方法を下調べしておきます。
<div class="tocLevel">と<a>~</a>あたりからとれそうです。

詳細ページのテーブル
詳細ページのテーブルの構造を調べておきます。
tableタグからとれそうです。
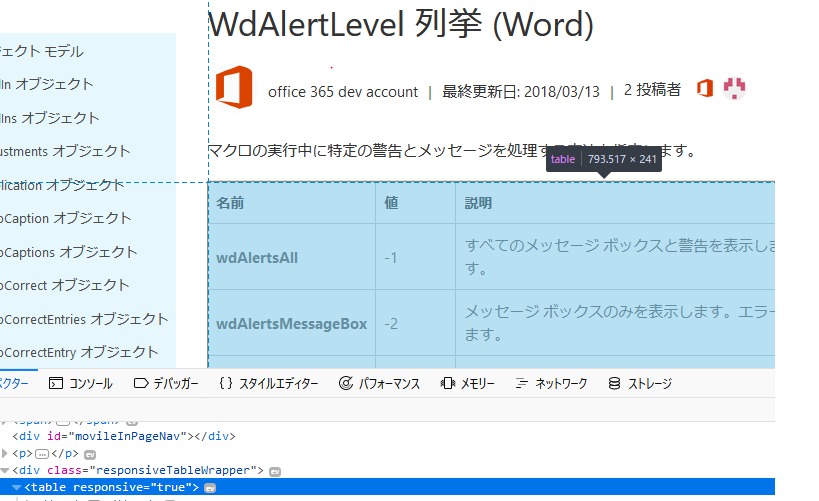
なお、このテーブルの構造で若干ハマりました。
scrapy shellで詳細調査
調査の順番はほとんど処理概要と同じです。
トップページのhtmlをとってくる
scrapy shellの起動時パラメータに[URL][top_url]をわたすとhtmlをとってこれます。
> scrapy shell --nolog https://msdn.microsoft.com/ja-jp/vba/vba-word
htmlを粗く削り出す
htmlソースにあった
<div class="tocLevel">...<a href="https://..." title="XXX 列挙">XXX 列挙</a>...</a>
から
<a href="https://..." title="XXX 列挙">XXX 列挙</a>
を削り出します。
In [1]: res=response.xpath(r"//div[@class='tocLevel']/a[contains(@title, ' 列挙')]")
In [2]: res.extract()
Out[2]:
['<a href="https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdalertlevel-enumeration-word" title="WdAlertLevel 列挙">WdAlertLevel 列挙</a>',
'<a href="https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdalignmenttabalignment-enumeration-word" title="WdAlignmentTabAlignment 列挙">WdAlignmentTabAlignment 列挙</a>',
...
# htmlソースのgrep(' 列挙')と個数が一致したのでOKとしておく。
In [3]: len(res)
Out[3]: 351
詳細ページのURLを削り出す
@hrefを削り出します。
In [5]: res.xpath(r"@href").extract()
Out[5]:
['https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdalertlevel-enumeration-word',
'https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdalignmenttabalignment-enumeration-word',
...
In [8]: urls=res.xpath(r"@href").extract()
In [9]: len(urls)
Out[9]: 351
詳細ページのタイトルを削り出す
@titleを削り出す。
In [10]: res.xpath(r"@title").extract()
Out[10]:
['WdAlertLevel 列挙',
'WdAlignmentTabAlignment 列挙',
...
In [11]: titles=res.xpath(r"@title").extract()
In [12]: len(titles)
Out[12]: 351
詳細ページのhtmlをとってくる
zip(titles,urls)のループ内でfetchする。
response.urlでhtmlをとってこれたかを見る。
In [36]: for t,u in zip(titles,urls):
...: fetch(u)
...: print(response.url)
...: break #安定動作が確認できるまで一つに限定する
...:
https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdalertlevel-enumeration-word
htmlを粗く削り出す
//table//tdを削り出します。
In [45]: for t,u in zip(titles,urls):
...: fetch(u)
...: res = response.xpath("//table//td")
...: print(len(res))
...: break #安定動作が確認できるまで一つに限定する
...:
9
In [46]: res.extract()
Out[46]:
['<td style="text-align:left"><span data-ttu-id="ff9c2-108"><strong>wdAlertsAll</strong></span><span class="sxs-lookup"><span data-stu-id="ff9c2-108"><strong>wdAlertsAll</strong></span></span></td>',
'<td style="text-align:left"><span data-ttu-id="ff9c2-109">-1</span><span class="sxs-lookup"><span data-stu-id="ff9c2-109">-1</span></span></td>',
'<td style="text-align:left"><span data-ttu-id="ff9c2-110">すべてのメッセージ ボックスと警告を表示します。エラーをマクロに返します。</span><span class="sxs-lookup"><span data-stu-id="ff9c2-110">All message boxes and alerts are displayed; errors are returned to the macro.</span></span></td>',
名前, 値, 説明を削り出す
tdのtext(名前, 値, 説明)を削り出します。
rev.1_初版
descendant::text()とすれば削り出せそうです。
In [52]: for t,u in zip(titles,urls):
...: fetch(u)
...: res = response.xpath("//table//td")
...: print(res.xpath(r"descendant::text()").extract())
...: break #安定動作が確認できるまで一つに限定する
...:
['wdAlertsAll',
'wdAlertsAll',
'-1',
'-1',
'すべてのメッセージ ボックスと警告を表示します。エラーをマクロに返します。',
'All message boxes and alerts are displayed; errors are returned to the macro.',...
予想外に重複したデータが出現しています。
Tooltipの英文も隠された形で入ってるようです。

・・・日本語版は「名前」が怪しい(↓)のでこれはこれで使えます。
[WdColorIndex 列挙 (Word)-msdn][wdcolorindex-enumeration-word]
rev.2_余計なデータをフィルタリング
rev.1のリストの内容を見てみると↓になっています。太字を使います。。
| index | リストの内容 | リストの値 |
|---|---|---|
| 0 | 名前(日) | wdAlertsAll |
| 1 | 名前(英) | wdAlertsAll |
| 2 | 値(日) | -1 |
| 3 | 値(英) | -1 |
| 4 | 説明(日) | すべてのメッセージ... |
| 5 | 説明(英) | All message boxes and alerts... |
| 6 | 名前(日) | wdAlertsMessageBox |
| 7 | 名前(英) | wdAlertsMessageBox |
| 8 | 値(日) | -2 |
| 9 | 値(英) | -2 |
| 10 | 説明(日) | メッセージ ボックスのみを... |
| 11 | 説明(英) | No alerts or message boxes are displayed... |
※ 残りのデータは省略
周期的なのでindexを6で割った余りでデータをフィルタリングできそうです。
リスト内包表記の中でif i%6 in [1,3,4,5]とします。
In [80]: values=[]
...: for t,u in zip(titles,urls):
...: fetch(u)
...: res = response.xpath("//table//td")
...: values=[v for i,v in enumerate(res.xpath(r"descendant::text()").extract()) if i%6 in [1,3,4,5]]
...: break #安定動作が確認できるまで一つに限定する
In [81]: values
Out[81]:
['wdAlertsAll',
'-1',
'すべてのメッセージ ボックスと警告を表示します。エラーをマクロに返します。',
'All message boxes and alerts are displayed; errors are returned to the macro.',
'wdAlertsMessageBox',
'-2',...
フィルタリングできました。
rev.3_データのまとめ直し
valuesのリストが一次元なのでデータ(wdAlertsMessageBox, -2, ..)がリスト内にフラットにならんでしまっています。
↓のような2次元の表にします。
| values[ i ][ j ] | j=0 | j=1 | j=2 | j=3 |
| i=0 | wdAlertsAll | -1 | すべてのメッセージ... | All message boxes and alerts... |
| i=1 | wdAlertsMessageBox | -2 | メッセージ ボックスのみを... | Only message boxes are displayed... |
| i=2 | wdAlertsNone | 0 | 警告やメッセージ ボックスを... | No alerts or message boxes are displayed.. |
「[リストをn個ずつのサブリストに分割 (Python)-おぎろぐはてブロ][split-list-into-sublist]」を使ってリスト内包表記でやってみます。
values=[values[i:i+4] for i in range(0,len(values),4)]が
In [82]: values=[]
...: for t,u in zip(titles,urls):
...: fetch(u)
...: res = response.xpath("//table//td")
...: values=[v for i,v in enumerate(res.xpath(r"descendant::text()").extract()) if i%6 in [1,3,4,5]]
...: values=[values[i:i+4] for i in range(0,len(values),4)]
...: break #安定動作が確認できるまで一つに限定する
In [83]: print("values[i][j]")
...: for i in range(3):
...: for j in range(4):
...: print(f"values[{i}][{j}]={values[i][j]}")
...:
values[i][j]
values[0][0]=wdAlertsAll
values[0][1]=-1
values[0][2]=すべてのメッセージ ボックスと警告を表示します。エラーをマクロに返します。
values[0][3]=All message boxes and alerts are displayed; errors are returned to the macro.
values[1][0]=wdAlertsMessageBox
values[1][1]=-2
values[1][2]=メッセージ ボックスのみを表示します。エラーをトラップし、マクロに返します。
values[1][3]=Only message boxes are displayed; errors are trapped and returned to the macro.
...
データをまとめ直して表形式にできました。
rev.4_分割された説明文の統合
予想外のデータ
breakを外して通してみたところ、「WdCalendarType 列挙 (Word)-msdn」でうまく動作しないケースに遭遇しました。
In [11]: fetch("https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word")
In [12]: res = response.xpath("//table//td")
...: values=[v for i,v in enumerate(res.xpath(r"descendant::text()").extract()) if i%6 in
...: [1,3,4,5]]
...: values=[values[i:i+4] for i in range(0,len(values),4)]
...:
In [13]: values
Out[13]:
...
['wdCalendarTranslitEnglish', '8', '英語 (音訳)。', 'English transliterated.'],
['Gregorian calendar with English month and day names transliterated to the Arabic script.',
'Unsupported.',
'wdCalendarTranslitFrench',
'wdCalendarTranslitFrench'],
...
['Gregorian calendar with English month and day names transliterated to the Arabic script.', 'Unsupported.', 'wdCalendarTranslitFrench', 'wdCalendarTranslitFrench'],の部分、「名前」が最後に入っていて、最初に「説明(日、英)」が来ています。
wdCalendarTranslitEnglishあたりをフィルタ/二次元化前のデータで確認してみます。
In [11]: fetch("https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word")
In [16]: res = response.xpath("//table//td")
...: values=res.xpath(r"descendant::text()").extract()
...:
In [17]: values
Out[17]:
...
'wdCalendarTranslitEnglish',
'wdCalendarTranslitEnglish',
'8',
'8',
'英語 (音訳)。',
'English transliterated.',
'英語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。',
'Gregorian calendar with English month and day names transliterated to the Arabic script.',
'サポートされていません。',
'Unsupported.',
'wdCalendarTranslitFrench',
'wdCalendarTranslitFrench',
...
res.xpath(r"descendant::text()").extract()でとれるリストは以下のようになる・・・と考えていました。。。
[...,
'wdCalendarTranslitEnglish',
'wdCalendarTranslitEnglish',
'8',
'8',
'英語 (音訳)。英語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。サポートされていません。',
'English transliterated. Gregorian calendar with English month and day names transliterated to the Arabic script. Unsupported.',
...
・・・甘かったようです。
このリストだと「説明(日、英)」がどこで切れるのか予想できません。
「xpath("//table//td")とxpath("descendant::text()"))ではダメ→考え直し」です。
XPath再検討(1/2)
立ち戻ってxpath("//table//td")を見直してみます。
In [18]: res = response.xpath("//table//td")
...: res.extract()
...:
Out[18]:
...
'<td style="text-align:left"><span data-ttu-id="57641-128"><strong>wdCalendarTranslitEnglish</strong></span><span class="sxs-lookup"><span data-stu-id="57641-128"><strong>wdCalendarTranslitEnglish</strong></span></span></td>',
'<td style="text-align:left"><span data-ttu-id="57641-129">8</span><span class="sxs-lookup"><span data-stu-id="57641-129">8</span></span></td>',
'<td style="text-align:left"><span data-ttu-id="57641-130">英語 (音訳)。</span><span class="sxs-lookup"><span data-stu-id="57641-130">English transliterated.</span></span><span data-ttu-id="57641-131">英語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。</span><span class="sxs-lookup"><span data-stu-id="57641-131">Gregorian calendar with English month and day names transliterated to the Arabic script.</span></span><span data-ttu-id="57641-132">サポートされていません。</span><span class="sxs-lookup"><span data-stu-id="57641-132">Unsupported.</span></span></td>',
...
テキストエディタでソースをよく見てみると、

となっていて、
span data-ttu-id → 日本語版のデータ
span data-stu-id → 英語版のデータ
と推測できます。
これを使って削り取ってみます。
In [11]: fetch("https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word")
# span data-ttu-id → 日本語版のデータ
In [19]: res = response.xpath("//table//td")
...: res.xpath("descendant::span[@data-ttu-id]/text()").extract()
...:
Out[19]:
[...
'8',
'英語 (音訳)。',
'英語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。',
'サポートされていません。',
'9',
'(音訳) をフランス語します。',
'フランス語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。',
'サポートされていません。',
...]
# span data-stu-id → 英語版のデータ
In [20]: res = response.xpath("//table//td")
...: res.xpath("descendant::span[@data-stu-id]/text()").extract()
...:
Out[20]:
[...
'8',
'English transliterated.',
'Gregorian calendar with English month and day names transliterated to the Arabic script.',
'Unsupported.',
'9',
'French transliterated.',
'Gregorian calendar with French month and day names transliterated to the Arabic script.',
'Unsupported.',
...]
日本語版と英語版をわけて削り取れましたが「名前」が出てきません。
どうやら名前だけ<strong>がついておりタグの深さが違うので、
xpath("descendant::span[@data-stu-id]/text()")
↓
xpath("descendant::span[@data-stu-id] // text()")
としないとダメなようです。以降では別の取り方をするので特に問題になりません。
また、「説明」の間に「値」が入ってしまい、結局切れ目がわかりません。
もう少し検討が必要です。
XPath再検討(2/2)
もう少しソースを見てると「名前、値、説明それぞれの<td>~</td>のなかに、data-ttu-idとdata-stu-idの両方がある」に気がつきます。
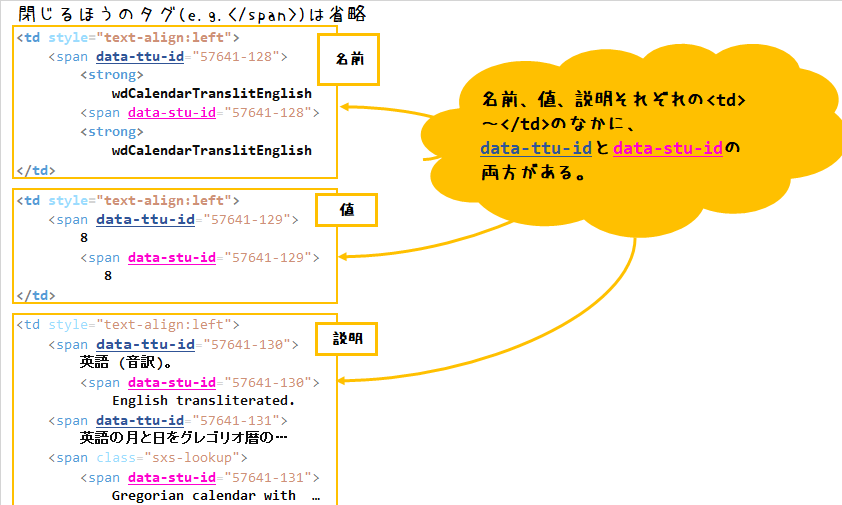
つまり、「名前」、「値」、「説明」と明確にわけたいなら、
そもそも「名前、値、説明」を<td>~</td>で削りとった直後に分けておかないといけない
ことになります。
tdで削りとった直後にわけてみます。表の列は3つなので3つで決め打ちでわけて大丈夫なはずです。
In [11]: fetch("https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word")
# tdで削りとった直後に3つにわける
In [28]: res = response.xpath("//table//td")
...: tds = [res[i:i+3] for i in range(0,len(res),3)]
...: tds
...:
Out[28]:
# tdが3つずつにわけられている
[[<Selector xpath='//table//td' data='<td style="text-align:left"><span data-t'>,
<Selector xpath='//table//td' data='<td style="text-align:left"><span data-t'>,
<Selector xpath='//table//td' data='<td style="text-align:left"><span data-t'>],
...
# 中身を具体的にみてみる
## span data-ttu-id → 日本語版のデータ
In [30]: for td in tds:
...: print(td.xpath("descendant::span[@data-ttu-id]//text()").extract())
...
## [0]:名前, [1]:値, [2~]:説明になっている。OK
['wdCalendarTranslitEnglish', '8', '英語 (音訳)。', '英語の月と日をグレゴリオ暦のカレンダー名 がアラビア語のスクリプトを作成する (音訳)。', 'サポートされていません。']
['wdCalendarTranslitFrench', '9', '(音訳) をフランス語します。', 'フランス語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。', 'サポートされていません。']
...
## span data-ttu-id → 英語版のデータ
In [31]: for td in tds:
...: print(td.xpath("descendant::span[@data-stu-id]//text()").extract())
...
## [0]:名前, [1]:値, [2~]:説明になっている。OK
['wdCalendarTranslitEnglish', '8', 'English transliterated.', 'Gregorian calendar with English month and day names transliterated to the Arabic script.', 'Unsupported.']
['wdCalendarTranslitFrench', '9', 'French transliterated.', 'Gregorian calendar with French month and day names transliterated to the Arabic script.', 'Unsupported.']
['wdCalendarUmalqura', '13', 'Um-al-Qura calendar.']
['wdCalendarWestern', '0', 'Western.', 'Corresponds to the Gregorian calendar.']
...
日本語版、英語版を分けることができ、[0]:名前, [1]:値, [2~]:説明になって切れ目がわかるようになりました。
[2~]:説明は、tdを[2:]でスライスして、" ".join()で結合できます。
In [11]: fetch("https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word")
In [28]: res = response.xpath("//table//td")
...: tds = [res[i:i+3] for i in range(0,len(res),3)]
In [38]: for td in tds:
...: #tdを[2:]でスライス
...: dscrpt = td[2:].xpath("descendant::span[@data-ttu-id]//text()").extract()
...: #" ".join()で結合
...: dscrpt = " ".join(dscrpt)
...: print(dscrpt)
...
英語 (音訳)。 英語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。 サポートされていません。
(音訳) をフランス語します。 フランス語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。 サポートされていません。
...
以上から、名前, 値, 説明の削り出しには、3つのXPathを使えばよいことになります。
| XPath | 説明 |
|---|---|
| xpath("descendant::text()") | 名前もしくは値の削り出し |
| xpath("descendant::span[@data-ttu-id]//text()") | 日本語版の説明の削り出し |
| xpath("descendant::span[@data-stu-id]//text()") | 英語版の説明の削り出し |
実装
各tdを解析した結果はdictionary型md_tdに格納して、md_tdはリスト型md_tdsに格納するようにしました。md_tdは「markdown用に解析したtd」の意味です。
md_tdsの構造イメージ
| ['name'] | ['value'] | [''description_jp'] | ['description_en'] | |
| md_tds[0] | 'wdCalendarArabic' | '1' | 'イスラム暦です。' | 'Arabic Hijri calendar.' |
| md_tds[1] | 'wdCalendarHebrew' | '2' | 'ヘブライ太陰暦です。' | 'Hebrew Lunar calendar.' |
| ... | ... | ... | ... | ... |
# 念のためフェッチしておく
In [11]: fetch("https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word")
# フェッチしたらres = response.xpath("//table//td")を作っておく
In [19]: res = response.xpath("//table//td")
In [40]: #詳細ページのURLを削り出す
...: urls = res.xpath(r"@href").extract()
...: #詳細ページのタイトルを削り出す
...: titles = res.xpath(r"@title").extract()
...:
...: urls = urls[20:21] #ループ内でfetchする個数を限定する。[20:21]は、https://msdn.micro
...: soft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word
...: titles = titles[20:21] #urlsに合わせて調整する。[20:21]は、WdCalendarType 列挙
...:
...: #詳細ページのhtmlをとってないやつがあるだけループ
...: for url,title in zip(urls,titles):
...: #詳細ページのhtmlをとってくる
...: fetch(url)
...:
...: #名前, 値, 説明を削り出す
...: ##htmlをtdで削りとる
...: res = response.xpath("//table//td")
...: ##tdで削りとった直後に3つずつにわける
...: tds = [res[i:i+3] for i in range(0,len(res),3)]
...:
...: ##各tdを解析結果はdictionary型md_tdに格納。md_tdはリスト型md_tdsに格納
...: md_tds = []
...: for td in tds:
...: ##各tdを解析結果を格納するdict
...: md_td ={}
...:
...: ##名前を削り出す
...: name = td[0].xpath("descendant::text()").extract()[1]
...: md_td.update({"name":name})
...:
...: ##値を削り出す
...: value = td[1].xpath("descendant::text()").extract()[1]
...: md_td.update({"value":value})
...:
...: ##日本語版(span data-ttu-id)の説明を削り出す
...: dscpt_jp = td[2:].xpath("descendant::span[@data-ttu-id]//text()").extract()
...: dscpt_jp = " ".join(dscpt_jp)
...: md_td.update({"description_jp":dscpt_jp})
...:
...: ##英語版(span data-stu-id)の説明を削り出す
...: dscpt_en = td[2:].xpath("descendant::span[@data-stu-id]//text()").extract()
...: dscpt_en = " ".join(dscpt_en)
...: md_td.update({"description_en":dscpt_en})
...:
...: ##md_tdをリスト型md_tdsに格納
...: md_tds.append(md_td)
...:
...: print(md_tds)
...:
[...
{'name': 'wdCalendarTranslitEnglish',
'value': '8',
'description_jp': '英語 (音訳)。 英語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。 サポートされていません。',
'description_en': 'English transliterated. Gregorian calendar with English month and day names transliterated to the Arabic script. Unsupported.'},
{'name': 'wdCalendarTranslitFrench',
'value': '9',
'description_jp': '(音訳) をフランス語します。 フランス語の月と日をグレゴリオ暦のカレンダー名がアラビア語のスクリプトを作成する (音訳)。 サ ポートされていません。',
'description_en': 'French transliterated. Gregorian calendar with French month and day names transliterated to the Arabic script. Unsupported.'},
...]
うまくデータを構築できました。
markdownを作る
- reを使ってmsdnのen-usのURLを作る
- md_tdsのdictからデータを取り出して文字列化する
だけなので特にハマるところはないと思います。
...前半は「名前,値,説明を削り出す_rev.4」と同じ
...: import re
...: jp_url = url
...: us_url = re.sub(r"/ja-jp/",r"/en-us/", jp_url)
...: s = f"\n##{title}\n"\
...: + f"\n"\
...: + f"|名前|値|説明[msdn_ja-jp]({jp_url})|説明[msdn_en-us]({us_url})|\n"\
...: + f"|:---|:---|:---|:---|\n"
...:
...: for md_td in md_tds:
...: s+="|{}|{}|{}|{}|\n".format(md_td["name"], md_td["value"], md_td["description_jp"], md_td["description_en"])
...: s += "\n"
...: print(s)
## WdCalendarType 列挙
|名前|値|説明[msdn_ja-jp](https://msdn.microsoft.com/ja-jp/vba/word-vba/articles/wdcalendartype-enumeration-word)|説明[msdn_en-us](https://msdn.microsoft.com/en-us/vba/word-vba/articles/wdcalendartype-enumeration-word)|
|:---|:---|:---|:---|
|wdCalendarArabic|1|イスラム暦です。|Arabic Hijri calendar.|
|wdCalendarHebrew|2|ヘブライ太陰暦です。|Hebrew Lunar calendar.|
...
PlantUMLソース
@startuml scrapy_flow
:トップページのhtmlをとってくる;
:htmlを粗く削り出す;
:詳細ページのURLを削り出す;
:詳細ページのタイトルを削り出す;
repeat
:詳細ページのhtmlをとってくる;
:htmlを粗く削り出す;
:名前, 値, 説明を削り出す;
:markdownをつくる;
repeat while (詳細ページのhtmlをとってないやつがある?)
@enduml