概要
Paragraphsコレクション、Paragpraphsオブジェクトを利用して段落単位で文字列を取得します。
そのほかのテーマは以下です。
- Paragraphs(i).Range.Text連続アクセス性能
- シーケンシャルアクセスはイテレートするのが圧倒的に早い
- Wordの段落とは何か?
- 行頭の黒い点(・)は何?
- Range.Textをprintすると表示がおかしくなる?
- 校閲タブ→文字カウントで取得できる統計と一致しない?
利用する文書について
Word文書が安全かどうか保証できないので適宜用意してください。
そこそこ量があり、章・節を使った構造的文書(例えば、設計書・仕様書)がほしかったので、ここではローカルにあった(Visual Studioインストールで入った)「C# Language Specification Version 5.0」(CSharp Language Specification.docx)のコピーを利用しています
今回利用するWordオブジェクト
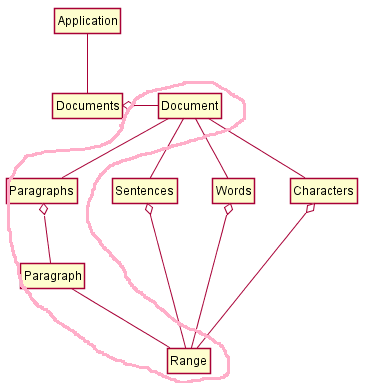
| オブジェクト名 | プロパティ/メソッド | 説明 | リンク |
|---|---|---|---|
| Document | - | Documents内の1つの文書 | msdn |
| ComputeStatistics() | 統計情報(ページ数、段落数など)を取得する | msdn | |
| Paragraphs | - | Paragraphのコレクション | msdn |
| Count | Paragraphの数 | msdn | |
| Paragraph | - | 1つの段落を表すオブジェクト | msdn |
| Range | この段落を表すRangeオブジェクトを取得 | msdn | |
| Range | - | 隣接する領域を表すオブジェクト | msdn |
| Text | Rangeのテキストを設定もしくは取得 | msdn |
コード
qtconsoleの確認結果を示していきます。
「★なんらかの処理★」部分に記述しているイメージで読んでください。
import win32com.client
# Wordを起動する : Applicationオブジェクトを生成する・・・[2]
Application=win32com.client.Dispatch("Word.Application")
# Wordを画面表示する : VisibleプロパティをTrueにする・・・[2]
Application.Visible=True
# Word文書を読み取り専用で開く : Documents.Open(ReadOnly=True)メソッドを呼ぶ・・・[7]
doc=Application.Documents.Open(
FileName=r"C:\tmp\CSharp Language Specification.docx",
ConfirmConversions=None,
ReadOnly=True)
★なんらかの処理★
# Word文書を保存せずに閉じる : Document.Close(SaveChanges=0)メソッドを呼ぶ・・・[7]
doc.Close(SaveChanges=0)
# Wordを終了する : Quitメソッドを呼ぶ・・・[2]
Application.Quit()
コメントの「・・・[n]」は記事の番号です。
段落の単位で文字列を取得する
Paragraph.Range.Textで段落のテキストを見てみます。
In [27]: for i in range(1,10):
...: print(f"{i}:" + doc.Paragraphs(i).Range.Text)
1:
2:
3:
4:
5:
6:
7:C#
8:Language Specification
9:Version 5.0
段落の単位で文字列を取得できました。
Paragraphs(i).Range.Textに連続アクセスするとだんだん重くなっていくので、テキスト取得であれば新たにRangeを作るのがいいです。
In [95]: start=doc.Paragraphs(1).Range.Start
...: end=doc.Paragraphs(10).Range.End
...: doc.Range(start,end).Text
...:
Out[95]: '\r\r\r\r\r\rC#\rLanguage Specification\rVersion 5.0\r\x0cNotice\r'
また、制御文字が入っているためprint時は置き換えが必要です。
In [96]: import re
In [97]: ctrlch = re.compile(r"[\x00-\x1F\x7F]")
In [98]: def p_range_txt(range_txt, repl=""):
...: global ctrlch
...: print(ctrlch.sub(repl, range_txt))
In [99]:
...: start=doc.Paragraphs(1).Range.Start
...: end=doc.Paragraphs(10).Range.End
...: p_range_txt(doc.Range(start,end).Text,"\n")
C#
Language Specification
Version 5.0
Notice
Paragraphs(i).Range.Text連続アクセス性能
Paragraphs(i).Range.Textにfor i in range(1,1000)でアクセスしたらあまりにも遅かったので時間を計ってみました。(遅すぎるので1000では計測してません。)
for i in range(1,1000):
d.Paragraphs(i).Range.Text
下記のtest_speed()関数を%timeitで時間計測してみます。
In [70]: def test_speed(d,n=1):
...: for i in range(1,n+1):
...: d.Paragraphs(i).Range.Text
In [74]: %timeit -n1 -r1 test_speed(doc,100)
12 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
n=100個のときt=12secでした。
n=100,200,300,400,500と変えていったときのtをプロットしてみます。
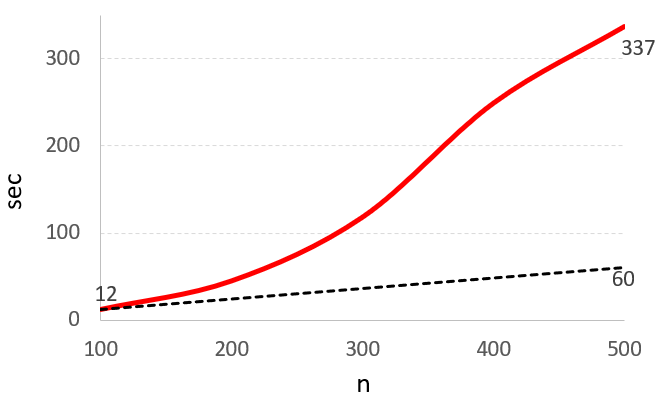
※黒い点線はn=100個のときt=12secからの期待値。
残念なことにn=500個のときt= 337sec。
近似曲線は
y = 0.0017x^2 - 0.0907x + 1.0217
になりました。
x=1000とすると、1604secで26.7minになってしまいますね。
100個ごと(dvsr個ごと)にParagrahをまとめたあとループする関数を作ってみました。
※test_speed3~4は省略
def test_speed5(doc,n=100,dvsr=100):
q, m = divmod(n, dvsr)
start_end = [(1+dvsr*i, dvsr+dvsr*i) for i in range(0,q+1)]
start_end += [] if m==0 else [(1+dvsr*(q+1), m+dvsr*(q+1))]
for start,end in start_end:
r_start = doc.Paragraphs(start).Range.Start
r_end = doc.Paragraphs(end).Range.End
r = doc.Range(r_start,r_end)
for i in range(1,r.Paragraphs.Count+1):
r.Paragraphs(i).Range.Text
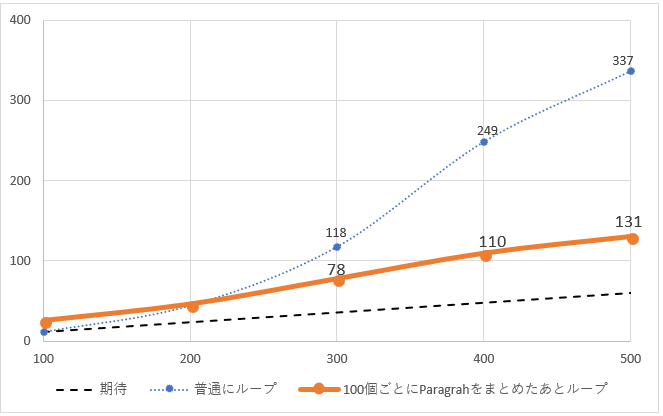
近似曲線は、
y = 5E-06x^2 + 0.2721x - 4.08
になりました。
二次の項が抑えられたのでほぼ線形に近くなりました。
x=1000で273sec(約4.5分)でそこそこ現実的な値になってきましたので実測してみます。
In [126]: %timeit -n1 -r1 test_speed5(doc,n=1000,dvsr=100)
2min 55s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
近似曲線からの予測より40sec程度早くなりました。
複数Paragraphのテキストを取得するならDocument.Range()メソッドで,Paragraphをまとめて新たなRangeを作り、そのRangeでループするのがいいと思います。なお、まとめる数は25個がよさそうです。
(25個あたりに最適な値がありそうです)
# 25個がベストスコア
In [128]: %timeit -n1 -r1 test_speed5(doc,n=500,dvsr=25)
58.9 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
In [127]: %timeit -n1 -r1 test_speed5(doc,n=500,dvsr=10)
1min 26s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
In [129]: %timeit -n1 -r1 test_speed5(doc,n=500,dvsr=20)
1min ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
In [125]: %timeit -n1 -r1 test_speed5(doc,n=500,dvsr=50)
1min 15s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
In [130]: %timeit -n1 -r1 test_speed5(doc,n=500,dvsr=100)
2min 4s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
シーケンシャルアクセスはイテレートするのが圧倒的に早い
for ~ in でWordのコレクションから値が取り出せることに今更気が付きました。
グラフ化するまでもなく、シーケンシャルアクセスはイテレートするのが圧倒的に早いです。
In [201]: def test_speed6(d,n=1):
...: for i,p in enumerate(d.Paragraphs):
...: p.Range.Text
...: if i>=n:
...: break
In [202]: %timeit -n1 -r1 test_speed6(doc,1000)
15 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
Wordの段落とは何か?
Paragraphs(1)~(6)の何も出てないところをもう少し調べてみます。
In [28]: doc.Paragraphs(1).Range.Text
Out[28]: '\r'
In [29]: for i in range(1,7):
...: s = doc.Paragraphs(i).Range.Text.encode("utf-8").hex()
...: print(f"{i}:" + s)
1:0d
2:0d
3:0d
4:0d
5:0d
6:0d
'\r'(0x0d,キャリッジリターン)でした。
Paragraphsと画面は以下のイメージで対応してます。

WordでEnterキー押したときに出てくる マークは'\r'だったんですね。
マークは'\r'だったんですね。
Wordの段落(Paragprahオブジェクト)は「Enterキーを押した箇所で区切られる領域」といえそうです。
行頭の黒い点(・)は何?
よく見てみるとParagprah(9)の下の行頭に黒い点(・)があります。

これ何でしょうか?
Paragprah(10)にあると思うので出力してみます。
In [42]: doc.Paragraphs(10).Range.Text
Out[42]: '\x0cNotice\r'
'\x0c Notice \r'と読めます。
次ページの最初に「Notice」があります。

'\x0c'はASCIIコードのForm Feed(改ページ)です。
'\x0c'が黒い点そのものでしょうか?
この黒い点についてもう少し調べてみると、
この「・」は、[改ページ位置の自動修正]が設定されている段落の先頭に表示されます。
・・・略・・・
[次の段落と分離しない]チェック
[段落を分割しない]チェック
[段落前で改ページする]チェック
のいずれかがOnになっている段落で「・」が表示されます
ということがわかります。
「Notice」の[改ページ位置の自動修正]は・・・
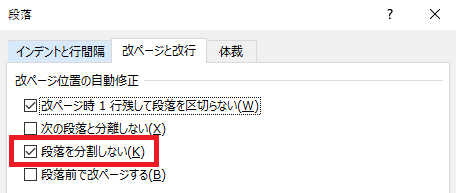
「段落を分割しない」にチェックが入ってました。※チェックを外すと黒い点が消えます。
行頭の黒い点(・)は、[改ページ位置の自動修正]の設定によってページ区切りが段落内にあることを示していたようです。また、ページ区切りは'\x0c'だとわかりました。
Range.Textをprintすると表示がおかしくなる?
In [47]: doc.Paragraphs(10).Range.Text
Out[47]: '\x0cNotice\r'
print(doc.Paragraphs(10).Range.Text)をしてみると・・・
のように'\x0c'(改ページ)をプリントした時点で画面がクリアされてしまいます。
そこで制御文字を置き換えてprintする関数p_range_txt()を作ります。
In [52]: import re
...: ctrlch = re.compile(r"[\x00-\x1F\x7F]")
...: def p_range_txt(range_txt, repl=""):
...: global ctrlch
...: print(ctrlch.sub(repl, range_txt))
In [53]: p_range_txt(doc.Paragraphs(10).Range.Text)
Notice
In [54]: p_range_txt(doc.Paragraphs(10).Range.Text, "??")
??Notice??
'\r'
制御文字全体を"\n"で置き換えておけばとりあえずは問題ないかと。
In [102]: p_range_txt(doc.Paragraphs(10).Range.Text,"\n")
Notice
In [103]:
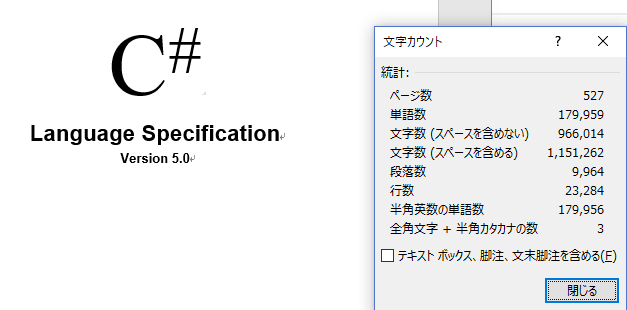
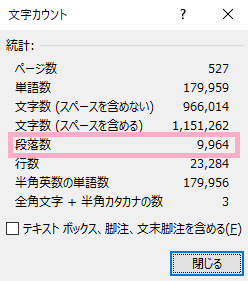
校閲タブ→文字カウントで取得できる統計と一致しない?
Paragraphs.Countを使って、Paragprahオブジェクトの数を調べてみます。
In [19]: doc.Paragraphs.Count
Out[19]: 10449
よく見ると、「さっきの統計の段落数と違う」と気がつきます。
なぜでしょうか?
Hey, Scripting Guy! Word 文書の文と段落の数を数える方法はありますか
たとえば、次の抜粋 (アンダースコアはそれぞれ Enter キーを押した箇所を示しています) には、段落がいくつあると思いますか。
段落 1。_
_
段落 2。_
_
段落 3。_ご想像のとおり、答えは "場合による" です。
ComputeStatistics メソッドを使用して段落数を計算した場合(略)、Word では、ここに 3 つの段落があると認識します。
しかし、Paragraphs コレクションを使用する場合 (略)、Word では、この文書に 5 つの段落があると認識されます。
というのも、この場合、Word では Enter キーを押した回数を数えているだけだからです。(略)
実際、Enter キーを 5 回押したことが、Paragraphs コレクションに 5 つの項目が含まれている理由です。
統計側の段落数は空行を無視しているようです。
統計と同じ値を取得する場合は, Document.ComputeStatistics()を利用します
Document.ComputeStatistics Method - msdn
Syntax
expression . ComputeStatistics( Statistic , IncludeFootnotesAndEndnotes )
|名前|必須 / 省略可能|説明|
|:---|:---|:---|:---|
|Statistic|必須|計算する統計量。WdStatistic列挙のいずれか|
|IncludeFootnotesAndEndnotes|省略可能|True:テキストボックス, 脚注, 文末脚注を含める(デフォルト=False|
| 名前 | 値 | 説明msdn_ja-jp | 説明msdn_en-us |
|---|---|---|---|
| wdStatisticCharacters | 3 | 文字数 | Count of characters. |
| wdStatisticCharactersWithSpaces | 5 | スペースを含めた文字数 | Count of characters including spaces. |
| wdStatisticFarEastCharacters | 6 | アジア言語の文字数 | Count of characters for Asian languages. |
| wdStatisticLines | 1 | 行数 | Count of lines. |
| wdStatisticPages | 2 | ページ数 | Count of pages. |
| wdStatisticParagraphs | 4 | 段落数 | Count of paragraphs. |
| wdStatisticWords | 0 | 単語数 | Count of words. |
実際に取得してみます。
# ページ数 wdStatisticPages
In [90]: doc.ComputeStatistics(Statistic=2)
Out[90]: 527
# 単語数 wdStatisticWords
In [91]: doc.ComputeStatistics(Statistic=0)
Out[91]: 179959
# 文字数(スペースを含めない) wdStatisticCharacters
In [92]: doc.ComputeStatistics(Statistic=3)
Out[92]: 966014
# 文字数(スペースを含める) wdStatisticCharactersWithSpaces
In [93]: doc.ComputeStatistics(Statistic=5)
Out[87]: 1151262
# 段落数 wdStatisticParagraphs
In [93]: doc.ComputeStatistics(Statistic=4)
Out[93]: 9964
# 段落数 wdStatisticParagraphs
In [94]: doc.ComputeStatistics(Statistic=1)
Out[94]: 23284
# 全角文字・半角カタカナの数 wdStatisticFarEastCharacters
In [95]: doc.ComputeStatistics(Statistic=6)
Out[95]: 3
統計と同じ値が取得できました。
半角英数の単語数はWdStatistic列挙に対応する値がないので、
半角英数の単語数 = 単語数 - 全角文字・半角カタカナの数
で計算しているようです。
関連
Python(pywin32)でWordを操作する[1] - Wordオブジェクトモデル
Python(pywin32)でWordを操作する[2] - Wordを起動/終了する
Python(pywin32)でWordを操作する[3] - 新規ドキュメント作成
Python(pywin32)でWordを操作する[4] - 文字列を入力/取得/削除する
Python(pywin32)でWordを操作する[5] - ドキュメントをファイルに保存する、Wordのオプション変更
Python(pywin32)でWordを操作する[6] - 特定のタイトルが付いているウィンドウの操作
Python(pywin32)でWordを操作する[7] - 既存文書を開く/閉じる(Documents.Open(), Document.Close())
Python(pywin32)でWordを操作する[8] - 段落単位の文字列取得, 統計(ページ数, 段落数,etc)取得