1. はじめに
こんにちは、天パです。👨🏻🦱
ミドルウェア更新も、放っておくと髪の毛みたいに絡まります。
Apache のようなミドルウェア更新は、
作業だけ見ればそこまで複雑ではありません。
- 更新候補を確認する
- 検証環境で試す
- 本番環境へ反映する
- 問題があれば切り戻す
ただ、実務で本番環境が単一サーバ構成だと話が変わります。
更新中にサービス停止が発生しやすいため、
利用者影響を避ける目的で夜間対応になりがちです。
夜間に人が待機し、手順書を見ながら更新し、
失敗したらその場で切り戻す。
この運用は、担当者にも組織にも負荷が大きいです。
そこで個人環境で、
「冗長構成にしてローリング更新を組めば、
ダウンタイムなしでミドルウェア更新できるのか」
「夜間対応をやめる方向に寄せられるのか」
を実装まで試してみました。
リポジトリはこちらです。
https://github.com/tenpa7188/zero-downtime-update-orchestrator
2. 作ったもの
Apache の更新を題材に、
LB 配下の Web サーバを 1 台ずつ切り離しながら更新する構成を作りました。
流れは次のようなイメージです。
バージョンアップ候補を検知(cron)
-> GitHub Issue の自動作成 / Slack 通知
-> dev dry-run
-> dev rolling update
-> prod dry-run
-> production 承認
-> prod rolling update
-> 必要なら rollback
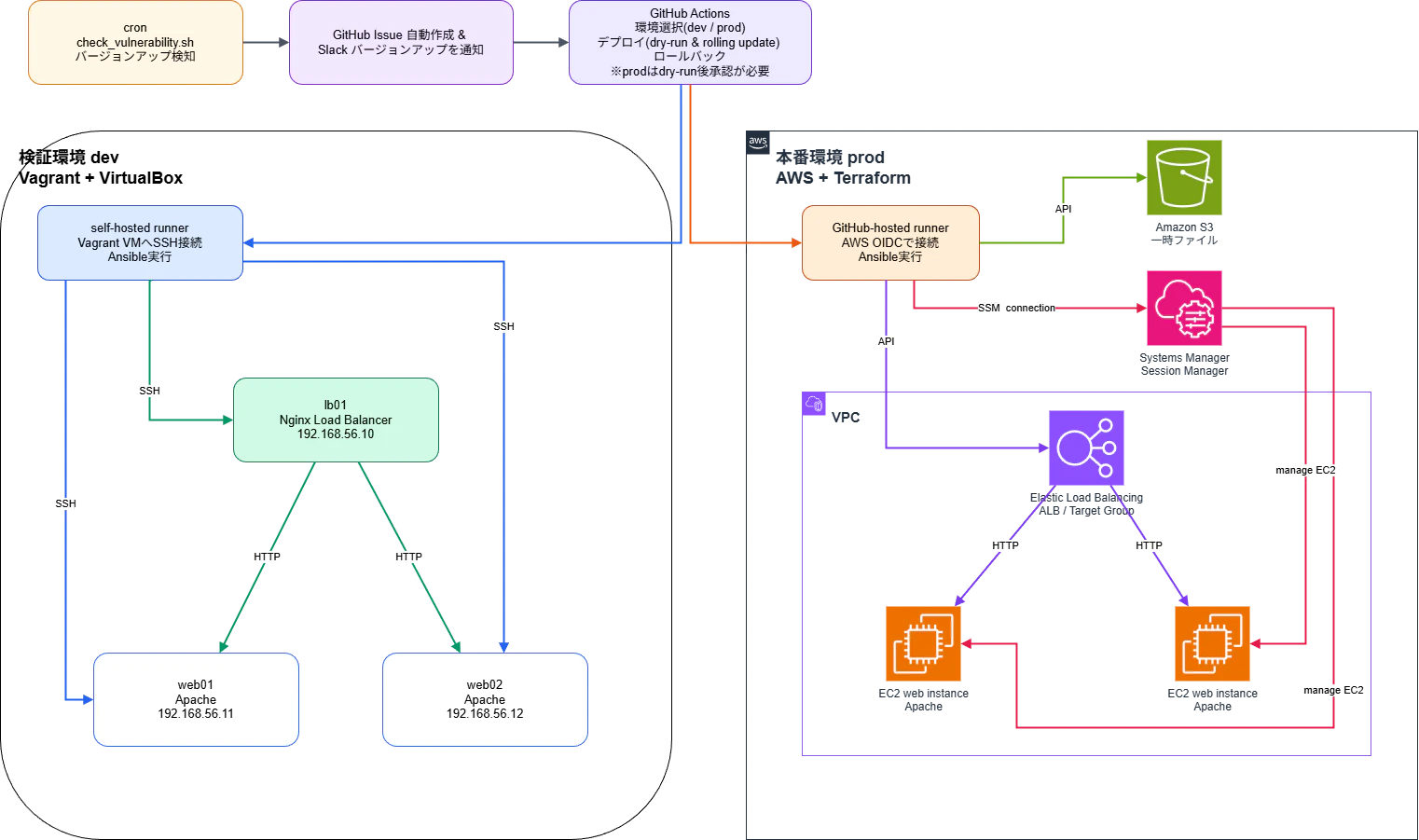
構成図は次のようになります。
実務では VM 環境を触ることが多いため、
検証は VM、
本番相当環境は AWS(学習のため)
という特殊な環境になっています。
技術スタックは次の通りです。
| 領域 | 技術 | 用途 |
|---|---|---|
| 構成管理 | Ansible | Apache 更新、LB 制御、ヘルスチェック、切り戻し |
| ローカル検証 | Vagrant + VirtualBox |
lb01、web01、web02 の疑似マルチホスト環境 |
| 本番相当環境 | Terraform + AWS | VPC、EC2、ALB、IAM、S3 などの IaC 管理 |
| CI/CD | GitHub Actions | dry-run、deploy、承認、rollback |
| LB | Nginx / AWS ALB | dev は Nginx、prod は ALB |
| 本番相当接続 | AWS SSM | SSH ポートを開けずに Ansible を実行 |
dev は Vagrant VM と Nginx LB、
prod 相当は AWS EC2 と ALB です。
環境は違いますが、更新の中核になる Ansible playbook は共通にしています。
3. ローリング更新の考え方
単一サーバ構成では、
ミドルウェア更新は「この 1 台を止めるかどうか」の話になりがちです。
一方で、冗長構成にできるなら、
サービス全体を止めるのではなく、
対象サーバだけを LB から外して更新できます。
今回の Ansible playbook では、更新の流れを次のように固定しました。
1. 対象 Web サーバを LB から切り離す
2. Apache を指定バージョンへ更新する
3. systemd と HTTP でヘルスチェックする
4. 対象 Web サーバを LB に戻す
5. 次の Web サーバへ進む
中核になるのは serial: 1 と any_errors_fatal: true です。
該当コード
- name: ローリング更新
hosts: web
serial: 1
any_errors_fatal: true
pre_tasks:
- name: LB からサーバを切り離す
ansible.builtin.include_role:
name: lb_control
vars:
lb_control_action: drain
roles:
- apache
post_tasks:
- name: 動作確認
ansible.builtin.include_role:
name: healthcheck
- name: LB にサーバを組み込む
ansible.builtin.include_role:
name: lb_control
vars:
lb_control_action: restore
serial: 1 で 1 台ずつ更新し、
any_errors_fatal: true で失敗時に後続の更新を止めます。
1 台目でヘルスチェックに失敗しているのに、
2 台目、3 台目へ進むのは避けたいので、
ここはかなり大事なガードです。
4. GUI だけで更新作業を進められるようにした
今回、Ansible による自動化と GitHub Actions の CI/CD を組んだことで、
基本的なバージョンアップ対応は GitHub の画面操作だけで進められる形になりました。
サーバに SSH して手順書どおりにコマンドを打つのではなく、
GitHub Actions の Deploy workflow を画面から実行します。
実行手順としては、次のようになります。
4.1 バージョンアップ候補を検知する
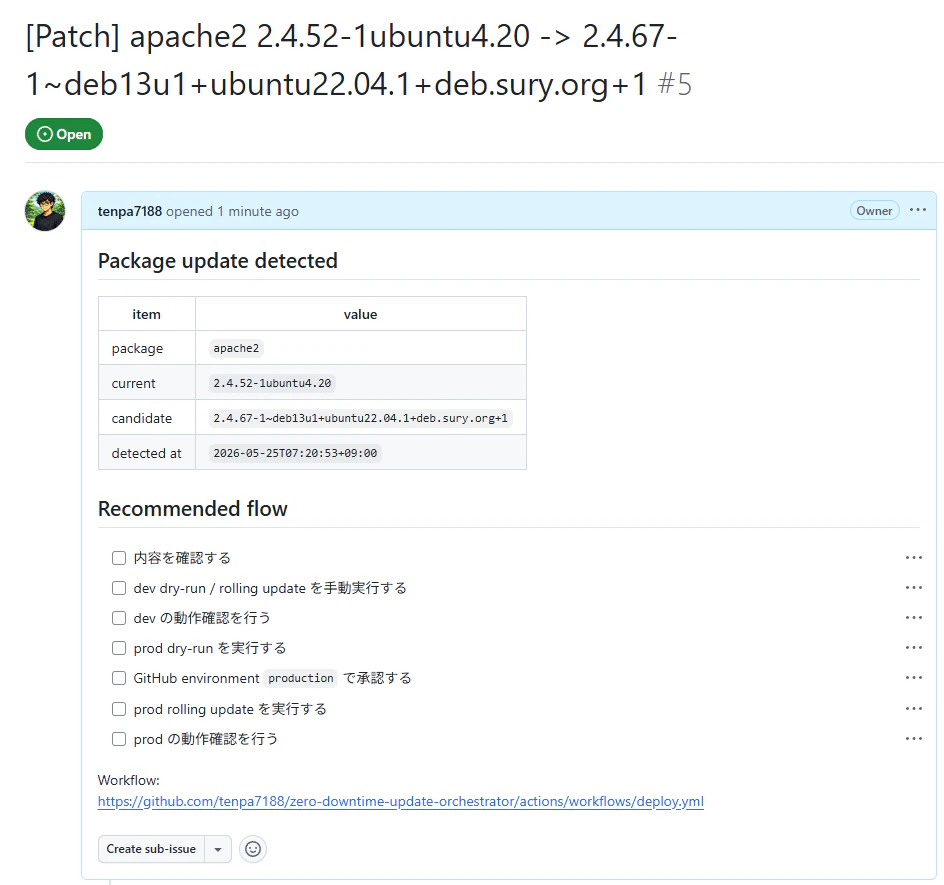
バージョンアップ候補を検知すると、
GitHub Issue を自動作成し、Slack に通知します。

Slack 通知から対象の Issue を開く導線を想定しています。
Issue ではチェックボックスで進行状況を見える化し、
GitHub Actions workflow のリンクから手動実行画面へ遷移する想定です。
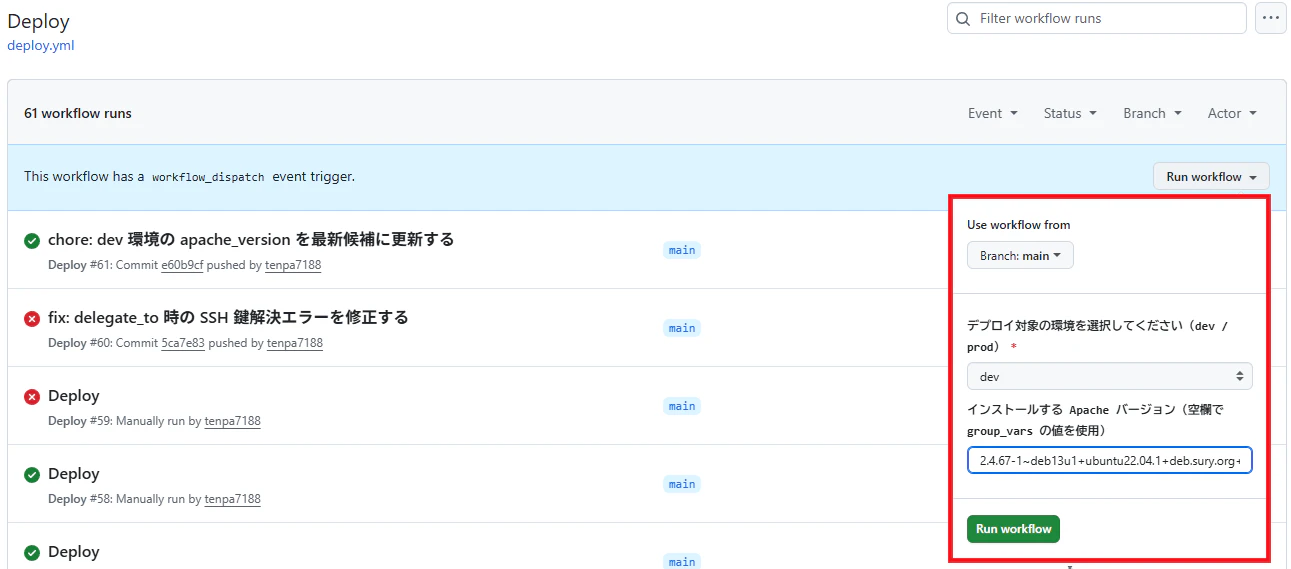
4.2 GitHub Actions から手動実行する
手動実行時は、対象環境と Apache のバージョンを入力します。
environment: dev / prod
apache_version: 更新したい Apache バージョン
その後の流れは GitHub Actions 側で進みます。
dry-run
-> prod の場合は production 承認
-> deploy
-> inventory の apache_version を同期
切り戻しも Rollback workflow から実行できます。
切り戻し先の Apache バージョンを入力すると、
通常のローリング更新と同じ流れで戻します。
これにより、作業者が直接サーバ上でコマンドを打つ場面を減らし、
実行ログも GitHub Actions に残せるようになりました。
完全自動にしないのも意識した点です。
特に prod は dry-run 後に production environment の承認を挟み、
人間が確認してから反映する形にしています。
5. バージョンアップ検知は起点作りに止める
scripts/check_vulnerability.sh では、
代表 Web サーバ上で対象パッケージの現行バージョンと最新バージョンを比較します。
デフォルトの対象は apache2 です。
更新候補がある場合は、GitHub Issue を作成し、
Slack に通知します。
ただし、この時点で deploy workflow は起動しません。
更新候補を検知する
-> Issue / Slack で知らせる
-> 内容を確認する
-> GitHub Actions の GUI から dry-run / deploy を進める
脆弱性対応は急ぎたい一方で、
検知した瞬間に更新まで走らせるのはまだ怖いです。
今は、検知は作業の起点作りにとどめています。
6. 今回の構成で意識したこと
このリポジトリでやりたかったのは、
単に Ansible で Apache を更新することではありません。
夜間対応が必要になりがちな運用を、
構成と自動化でどこまで変えられるかを試すことでした。
そのため、次の点を意識しています。
- 単一サーバ構成で発生しやすい停止前提の運用課題を出発点にする
- 冗長構成とローリング更新で、夜間対応を減らせるかを実装で確かめる
- dry-run と production 承認を挟み、本番反映を段階化する
- 失敗時に後続サーバへ進まないようにする
- 切り戻しも通常更新と同じ仕組みに載せる
- GUI 操作で進められるようにし、作業ログを GitHub Actions に残す
インフラ運用では、
「コマンドを知っている」だけでは足りない場面が多いです。
どの構成なら止めずに更新できるのか。
どこまで自動化し、どこに人間の承認を残すのか。
失敗したときにどう止め、どう戻すのか。
その判断を、できるだけリポジトリ上に残すようにしました。
7. 現時点の未対応と今後の課題
まだ最小構成なので、未対応のことも多いです。
- 更新対象は Apache のみ
- 現時点ではバージョンアップ候補の検知のみで、脆弱性自体の検出はできていない
- CVE 情報や深刻度とパッケージ更新候補を突き合わせる処理は未対応
- 複数ミドルウェアが対象になった場合の処理順序や承認フローは未対応
- 監視、メトリクス、アプリケーション疎通確認は今後の拡張余地がある
- 実際の単一サーバ本番環境を冗長化する場合は、セッション管理なども別途考慮が必要
特に次に考えたいのは、
「更新候補がある」ではなく
「どの脆弱性に対して、どの更新が必要なのか」まで見えるようにすることです。
また、Apache 以外のミドルウェアも対象にするなら、
ミドルウェアごとの更新手順、依存関係、切り戻し方法を整理する必要があります。
ここは今後の課題です。
8. まとめ
単一サーバ構成では、
ミドルウェア更新が夜間対応になりがちです。
ただ、それをずっと人の頑張りだけで支えるのはつらいです。
今回は個人環境で、
冗長構成とローリング更新を組めば、
夜間停止を前提にしない運用へ寄せられるのかを試しました。
Ansible で LB 切り離し、Apache 更新、ヘルスチェック、復帰を自動化し、
GitHub Actions から dry-run、承認、deploy、rollback を実行できるようにしています。
まだ完成形ではありませんが、
ミドルウェア更新を「夜間に手作業で頑張るもの」から、
「構成と CI/CD で制御するもの」へ寄せるための土台は作れたと思います。