TL;DR
- 決定係数$R^2$は一つではない。 定義が複数あり、同じデータでも値や解釈が変わる。特に切片なし回帰(原点通過)では、定義によって負の値や1超えが起こり得る。
- Rの
summary(lm())は、切片あり→一般的定義($R^2_1$)、 切片なし→0〜1に収まる定義($R^2_7$) を採用する仕様。それっぽく良さそうな$R^2_7$に騙されやすい。 -
kvr2を使って、決定係数$R^2$の複数定義+RMSE/MAE/MSEを一括比較&可視化できる。 - $R^2$単独で判断しない:RMSE/MAEなどの複数指標と併用し確認するのが安全。
この記事を読むとわかること:
決定係数$R^2$は「一つの値」ではありません。同じデータでも定義によってまったく違う値になりえます。特に「切片なしの線形回帰モデル」では$R^2$が1を超えたり負になったりし、解釈を誤りやすい指標です。本記事ではRの
kvr2パッケージを使ってその違いを可視化します。
対象読者
- Rで線形回帰モデルを触ったことがあるレベル(
lm()を知っている)
Introduction
線形回帰モデルにおいて、決定係数$R^2$はモデルの適合度を測る最も汎用的な指標の一つですが、同時に最も誤用されやすい指標でもあります。一般に決定係数$R^2$は0~1の間の値をとると理解されており、回帰分析の結果、出力された決定係数$R^2$の値が大きければ、多くの人は「モデル(予測値)がデータ(実測値)によく適合している」と胸をなでおろすことでしょう。
しかし、その安心感には落とし穴が潜んでいる可能性があります。モデルの構造(切片の有無や変数の変換)に応じて、$R^2$は一意ではなくなり、選択した数式次第で結果の解釈が劇的に変わるからです。かつてはEXCELなどでは算出される$R^2$は0を下回るという、二乗の形式からは想像もつかない事態に遭遇することすらありました。
なぜ、統計学を学び始めた最初期に学習するであろう比較的単純(であると理解されている)な指標である決定係数$R^2$でこれほどまでに結果が食い違うのでしょうか。本記事では、決定係数$R^2$の計算ロジックの多様性と、決定係数という指標が持つ危うさを見ていきます。
本稿ではRで複数の定義の決定係数$R^2$を計算する事ができるkvr2パッケージを用いて確認していきます(という体のパッケージの紹介)。
衝撃の事実:決定係数には複数の定義が存在する
私たちが当たり前のように使っている「決定係数$R^2$」ですが、統計学の世界ではその定義は決して一様ではありません。Kvalseth(1985)は、歴史的に用いられてきた決定係数には少なくとも8種類もの異なる定義が存在することを指摘しました。私たちが普段目にしている数値は、実はこれら多数の定義のうち、ソフトウェア(やパッケージ)側が「デフォルト」として選んだ一つに過ぎません。
Kvalsethによる8つの定義は以下の通りです。
$$R_1^2 = 1 - \frac{\sum(y - \hat{y})^2}{\sum(y - \bar{y})^2}$$
$$R^2_2 = \frac{\sum(\hat{y} - \bar{y})^2}{\sum(y - \bar{y})^2}$$
$$R_3^2 = \frac{\sum(\hat{y} - \bar{\hat{y}})^2}{\sum(y - \bar{y})^2}$$
$$R_4^2 = 1 - \frac{\sum(e - \bar{e})^2}{\sum(y - \bar{y})^2}, \quad e = y - \hat{y}$$
$$R_5^2 = \text{squared multiple correlation coefficient between the regressand and the regressors}$$
$$R^2_6 = \text{Square of Pearson's correlation coefficient between observed $y$ and predicted $\hat{y}$}$$.
$$R_7^2 = 1 - \frac{\sum(y - \hat{y})^2}{\sum y^2}$$
$$R_8^2 = \frac{\sum \hat{y}^2}{\sum y^2}$$
またKvalseth(1985)では外れ値に対してロバストな手法として中央値($M$)を用いた$R^2_9$も提案しています。
$$R_9^2 = 1 - \left( \frac{M{|y_i - \hat{y}_i|}}{M{|y_i - \bar{y}|}} \right)^2$$
「決定係数$R^2$は相関係数の二乗である」という理解は、Kvalsethの分類では$R^2_5$に相当する定義を切り取ったものです。
この決定係数$R^2$は相関係数の二乗である =
0~1の間に収まるはずという前提は、モデルの前提条件、特に切片をゼロに固定するかどうかによって容易に崩れ去るのです。
「切片なしの線形回帰モデル」で決定係数R²の定義による違い
決定係数の定義の違いが最も顕著に現れるのが、切片をゼロに固定する「切片なしの線形回帰モデル」(原点通過モデル)です。サンプルデータセットを用いて、切片ありの線形回帰モデルと切片なしの線形回帰モデルの各定義に基づく決定係数$R^2$を比較してみます。
# サンプルデータセット Yutaka Iguchi. (2025)の例
df <- data.frame(x = c(110, 120, 130, 140, 150, 160, 170, 180, 190, 200),
y = c(180, 170, 180, 170, 160, 160, 150, 145, 140, 145))
res <- lm(y ~ x, df)
これらの決定係数$R^2$を各定義に基づいて計算してみます。
決定係数の各定義での計算にはkvr2パッケージを用います。kvr2パッケージはCRANに登録されているのでinstall.packages()でインストールすることができます。
install.packages("kvr2")
インストールできたらlibrary()でパッケージを呼び出して、決定係数$R^2$を計算してみます。
kvr2には各定義式に基づいて指定したモデルの決定係数$R2$を計算するr2()がありますが、今回はモデルを一つ与えると、切片ありの線形回帰モデルと切片なしの線形回帰モデルの各定義の基づいた決定係数$R^2$を計算し、併せてKvalthes(1985)の論文中示された定義式に基づいた$RMSE$、$MAE$、$MSE$を計算するcomp_model()を用いて比較します。
なお、Kvalthes(1985)では$MSE$の計算で自由度の調整を行っているため、perfomanceパッケージなどで計算できる現在一般に用いられている$MSE$とは値がやや異なることに注意が必要です。
library("kvr2")
res_comp <- comp_model(res)
res_comp
model | R2_1 | R2_2 | R2_3 | R2_4 | R2_5 | R2_6
-------------------------------------------------------------------------
with intercept | 0.8976 | 0.8976 | 0.8976 | 0.8976 | 0.8976 | 0.8976
without intercept | -8.2183 | 4.3883 | 4.0856 | -7.9156 | 0.8976 | 0.8976
model | R2_7 | R2_8 | R2_9 | RMSE | MAE | MSE
-----------------------------------------------------------------------------
with intercept | 0.9992 | 0.9992 | 0.9308 | 4.4687 | 3.9212 | 24.9621
without intercept | 0.9303 | 0.9303 | -9.0197 | 42.3976 | 37.1211 | 1997.2882
---------------------------------
Note: Some R2 values exceed 1.0 or are negative, indicating that these definitions may be inappropriate for the no-intercept model.
値を確認すると分かる通り、切片ありの線形回帰モデル(with intercept)では決定係数に各定義間で差がないまたは僅かな差にとどまっていますが、切片なしの線形回帰モデル(without intercept)では1を超えるまたは0を下回る決定係数$R^2$が計算されています。
なぜ、切片なしの線形回帰モデルでは定義式によっては1を超えるまたは0を下回る決定係数$R^2$が計算されるでしょうか。kvr2には計算されたcomp_model()で計算された切片ありの線形回帰モデルと切片なしの線形回帰モデルの決定係数$R^2$などの値と実測値と予測値を可視化する関数があるので合わせて確認してみます。
plot(res_comp)
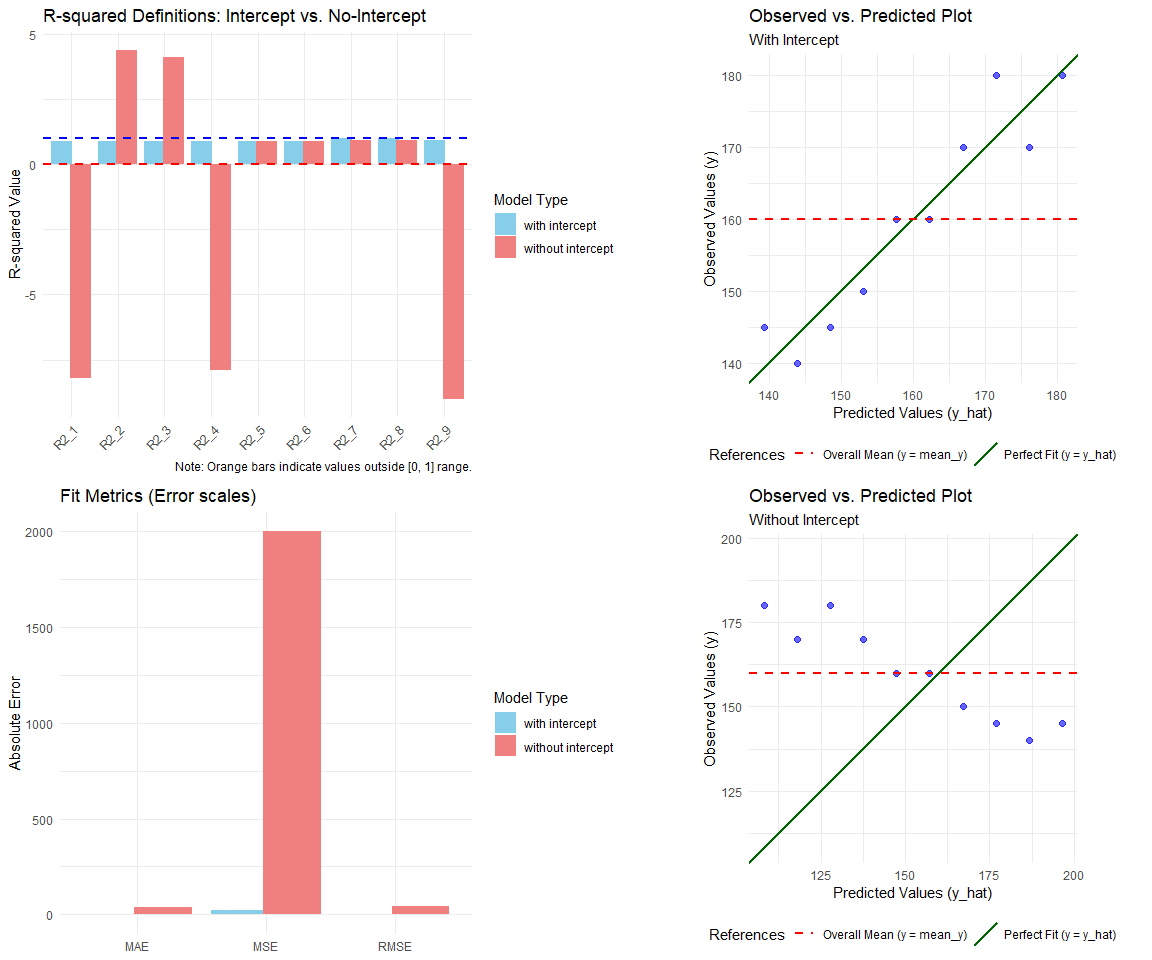
左側は各決定係数$R^2$などを示しています。右側では切片ありの線形回帰モデル(上段)と切片なしの線形回帰モデル(下段)の実測値と予測値の乖離を見て取ることができます。理想的なモデルであれば緑のラインに概ね沿って予測値と推測値のばらつきが少ない状態となります。
切片ありの線形回帰モデルでは緑のラインに沿って予測値と推測値がまとまってますが、切片なしの線形回帰モデルでは緑のラインよりも実測値の平均値である赤いラインのほうが当てはまりが良さそうだということが視覚的に確認できます。
さて可視化された結果を見ることからも明らかですが、Motulsky(2003)らが指摘するように、決定係数が負になるのは「データの平均値を通る水平な直線(予測能力ゼロのモデル)」よりも、その回帰式を使った予測の方が精度が悪い状態を意味しています。
ここで興味深い現象が発生します。例えば、切片なしの線形回帰モデルが明らかに不適切なデータ(切片が有意にゼロではないデータ)に対して負や1を超える決定係数$R^2$が出力される場合には「モデルが著しく不適切なのでは?」と気づくきっかけがありますが、$R^2_7$のように、不適切なモデルでも有り得そうな決定係数$R^2$が出力された場合には、出力された決定係数$R^2$だけを見ると一見当てはまりの良さそうなモデルだとみなしてしまう誤解が発生してしまう可能性があります。このとき、$RMSE$などのその他の指標で比較すると、実際には不適合であることが多く決定係数$R^2$にのみ依存して当てはまりの良さを考えるのは不適切です。
さて、ここまで見てきてソフトウェア(パッケージ)が採用している決定係数$R^2$の定義式により値が大きく異なることが確認できましたが、自分自身が利用している統計ツールの決定係数$R^2$の定義式とその性質は理解しているでしょうか?
Rの組み込みパッケージであるstatsでlm()をsummary()で結果を確認したときに用いられる決定係数$R^2$の定義式については関数のヘルプドキュメントに次のように記載があります。
r.squared
$R^2$, the ‘fraction of variance explained by the model’,
$$R^2 = 1 - \frac{\sum(R_i^2)}{\sum(y_i- y^*)^2}$$where $y^*$ is the mean of $y_i$ if there is an intercept and zero otherwise.
つまり、切片ありの場合には$R^2_1$で計算していて、切片なしの場合には$R^2_7$で計算されているとわかります。今回の切片なしの線形回帰モデルをlm(y ~ x - 1, df)として作成しsmmary()で結果を確認すると決定係数$R^2$はkvr2で計算した$R^2_7$と一致します。
# 切片なしの線形回帰モデル
model_no_int <- lm(y ~ x - 1, df)
summary(model_no_int)
Call:
lm(formula = y ~ x - 1, data = df)
Residuals:
Min 1Q Median 3Q Max
-51.539 -28.179 7.682 47.163 71.903
Coefficients:
Estimate Std. Error t value Pr(>|t|)
x 0.98270 0.08965 10.96 1.66e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 44.69 on 9 degrees of freedom
Multiple R-squared: 0.9303, Adjusted R-squared: 0.9226
F-statistic: 120.2 on 1 and 9 DF, p-value: 1.658e-06
今回のkvr2の計算結果でもそうである通り、$R^2_7$は負の値になることはありません。この切片の有無で決定係数$R^2$の定義式が変わる挙動についてはCRANのFAQに詳細が書かれていますが、決定係数$R^2$が負の値を取らないようにとのCRANの親切心によるもののようです。
さて、上記のsummary()で出力された結果を一見して、このモデルが不適切であると判断することは容易でしょうか?xのp値も悪くないですし、決定係数もまぁまぁいいかなというラインです。ここだけ見るとまぁまぁ良いモデルなのではと思います。
ただし、よく見ると残渣が大きいように見えます。ここで、Rのstatsパッケージの線形回帰モデルの決定係数$R^2$は切片なしの線形回帰モデルの場合には必ず0~1値を取る$R^2_7$の定義になることを理解していれば、ひょっとしてこの残渣の大きさは……ということから$RMSE$の確認を行うことができると思います。あるいは、決定係数$R^2$の危うさを理解したうえで$RMSE$などのその他の指標の確認を必ず行うというワークフローになると思います。
今回のサンプルデータは2変量の単純なデータなのでデータをプロットして切片あり(青)と切片なし(赤)の線形回帰モデルを描画してみます。
library("ggplot2")
ggplot(df, aes(x, y)) +
geom_point() +
lims(x = c(0, 200), y = c(0, 200)) +
geom_smooth(method = "lm", formula = y ~ x, se = FALSE, fullrange = TRUE) +
geom_smooth(method = "lm", formula = y ~ x - 1, se = FALSE, fullrange = TRUE, color = "red")
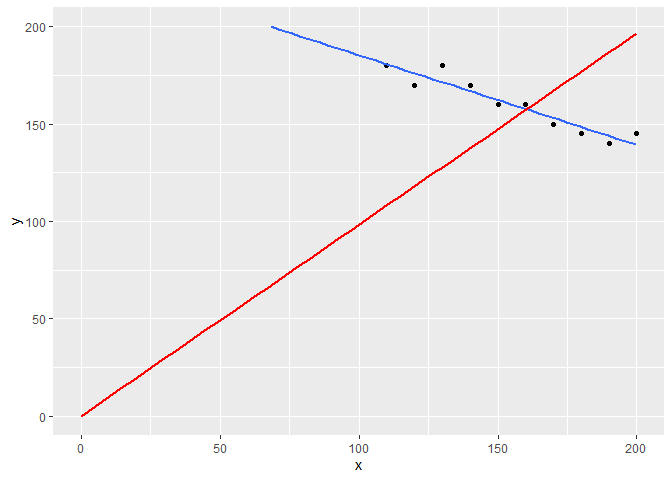
切片なし(赤)の線形回帰モデルの場合、データに対して明らかに当てはまりが悪そうなのは一目瞭然です。今回の例は2変量の単純な人工のサンプルデータによるものだったので簡単に不適切だとわかりましたが、実際の分析では複数の値を複雑に組み合わせながら分析を行っていると思います。そうしたときでも決定係数$R^2$の性質を理解して分析することができれば、適切な分析に一歩近づくのではないかと思います。
追加:決定係数R²の罠
さて、決定係数$R^2$の視点をデータの「当てはまりの良さ」を示す指標という観点から少し拡張して考えてみます。
決定係数$R^2$が高いからといって、必ずしもデータの「当てはまり」が良いとは限りません。松本・酒井(1989)のシミュレーションは、決定係数の座標軸に対する依存性を指摘しています。
データの分布を楕円として捉えたとき、楕円の「細長さ(形状)」が全く同じであっても、その楕円が座標軸に対してどのような「角度」で位置しているかによって、$R^2$は激変します。
- 楕円状のデータが座標軸に対して45度付近の傾きを持つとき、$R^2$は最大化されます。
- $R^2$の本質は「$y$軸方向の分散」を基準とした適合度です。そのため、楕円が水平(0度付近)に近づくと、$y$軸方向の分散自体が小さくなるため、残差がどれほど小さくても$R^2$は低く算出されてしまいます。
つまり、$R^2$は純粋な「当てはまりの良さ」の指標ではなく、「$y$軸の広がりに対する相対的な評価」に過ぎません。
まとめ:多角的な指標でモデルの当てはまりの良さを見極める
決定係数$R^2$は非常に直感的で便利な指標ですが、これまで見てきた通り、定義の違いや幾何学的な座標依存性をはらんでいます。$R^2$という数値一つでモデルの良し悪しを判断するのは、極めて危険な行為です。
信頼できる解析を行うためには、決定係数$R^2$のみによらず多角的な評価が不可欠です。
-
絶対的なエラー指標の併用:
$RMSE$(平均平方二乗誤差)や$MAE$(平均絶対誤差)などによって、具体的な予測誤差の大きさを把握する。 -
視覚的診断:
観測値と予測値のプロットを確認し、数値の背景にあるデータの挙動を捉える。
「当てはまりの良さ」の正体は、数式一つで語れるほど単純ではありません。あなたが次に回帰分析を行うとき、そのモデルの「当てはまりの良さ」を自信を持って説明できますか?
大AI時代において統計量の計算結果の出力や表面的な意味の確認は比較的容易になってきていますが、そんな時代にこそ統計量の背景にある数理的理解がより重要であると思います。数理的理解を欠いた分析は砂上の楼閣となる可能性があります。数字の裏側にあるロジックを理解することこそが、データの本質を見極める第一歩となります。
参考文献
Kvalseth, T. O. (1985) Cautionary Note about $R^2$. The American
Statistician, 39(4), 279-285. DOI:
10.1080/00031305.1985.10479448
Yutaka Iguchi. (2025) Differences in the Coefficient of Determination
$R^2$: Using Excel, OpenOffice, LibreOffice, and the statistical
analysis software R. Authorea. December 23, DOI:
10.22541/au.176650719.94164489/v1
Motulsky H. and Christopoulos A. (2003) Fitting models to biological
data using linear and nonlinear regression, pp.34-35, GraphPad Software
Inc., San Diego CA.
松本和幸 酒井英昭.(1989)
〔ノート〕回帰分析で通常使用される決定係数の再検討,
財務省財務総合政策研究所 編. フィナンシャル・レビュー (15),
財務省財務総合政策研究所, 1990-03, 10.11501/2879292.